今天,NVIDIA 宣布發布 Early Access ( EA )的 cuFFTMp 。 cuFFTMp 是 cuFFT 的多節點、多進程擴展,使科學家和工程師能夠在 exascale 平臺上解決具有挑戰性的問題。
FFTs ( Fast Fourier Transforms )廣泛應用于分子動力學、信號處理、計算流體力學( CFD )、無線多媒體和機器學習等領域。有了 cuFFTMp , NVIDIA 現在不僅支持單個系統中的多個 GPU ,還支持跨多個節點的多個 GPU 。
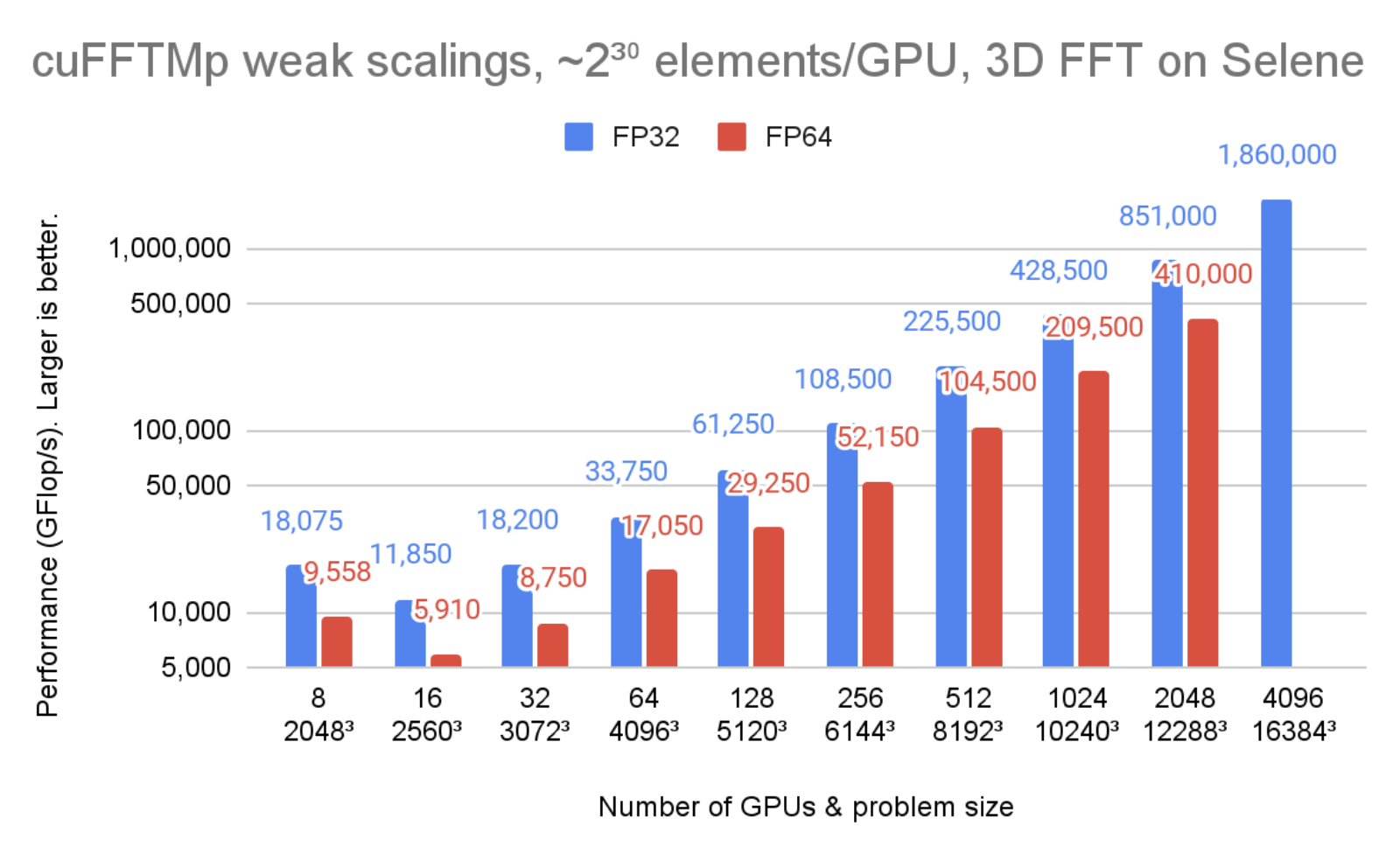
圖 1 顯示, cuFFTMp 達到 1.8 PFlop / s 以上,超過該規模轉換峰值機器帶寬的 70% 。
在圖 2 中,問題大小保持不變,但 GPU 的數量從 8 增加到 2048 。可以看到, cuFFTMp 成功地擴展了問題,將單精度時間從 8 GPU ( 1 個節點)的 78ms 提高到 2048 GPU ( 256 個節點)的 4ms 。
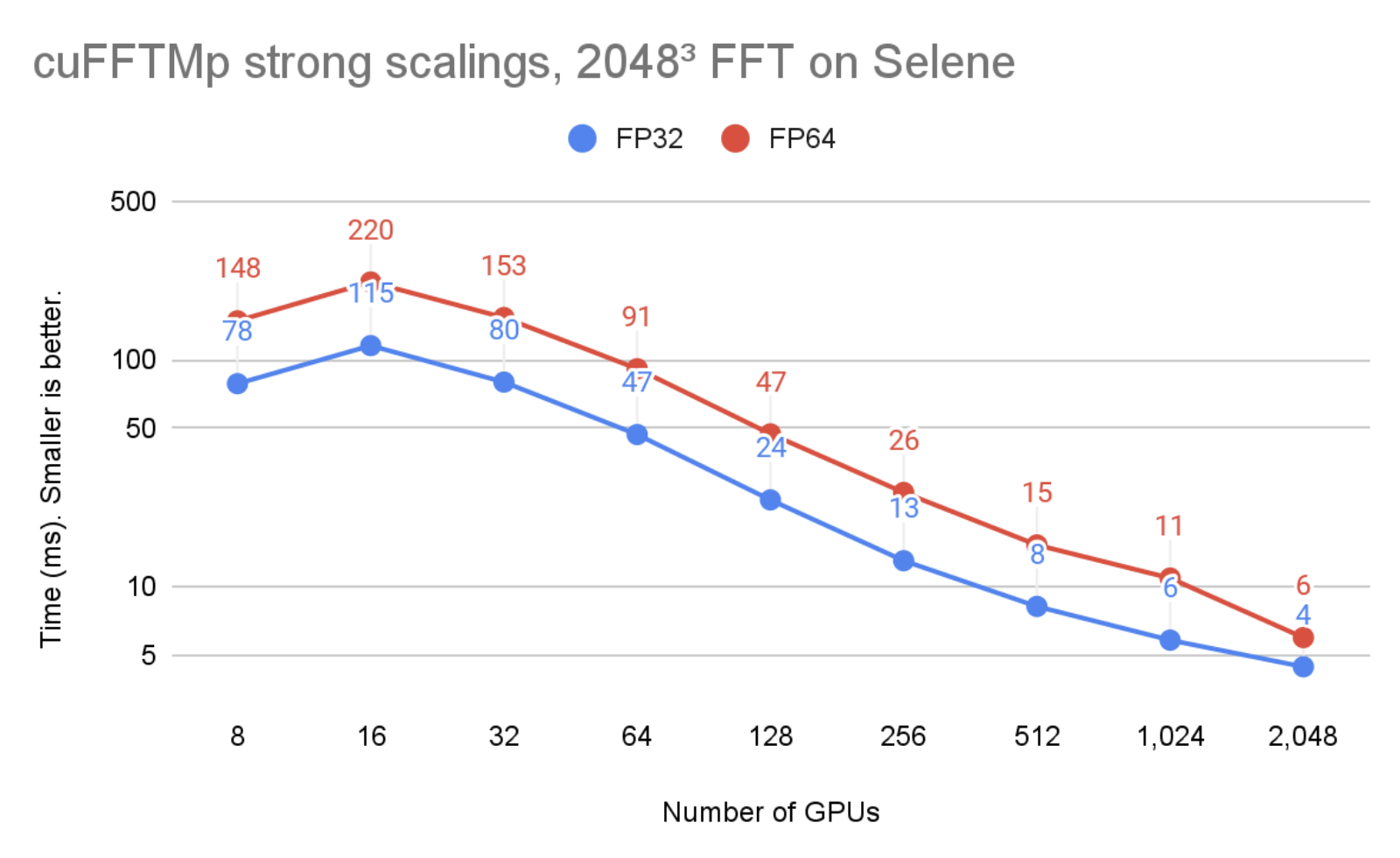
圖 1 和圖 2 在 Selene 集群上運行。 Selene 由 NVIDIA DGXA100 和 NVSwitch ( 300 GB / s / GPU ,雙向)以及 Mellanox Infiniband HDR ( 200 GB / s / node ,雙向)組成,每個節點 8xA100-80GB 。使用 nvcr 提供的 CUDA 11.4 和 NVIDIA HPC SDK 21.9 Docker 容器 進行測試。 io / NVIDIA / nvhpc:21.9-runtime-cuda11 。 4-ubuntu20 。 04.GPU 應用程序時鐘設置為最大值。
性能和可擴展性
由于MPI_Alltoallv類型的全局集體通信,分布式 3D FFT 以通信受限而聞名。MPI_Alltoallv是分布式 FFT 的主要瓶頸,因為與高計算能力相比,節點間帶寬較低,而且all_to_all類型通信的加速器感知 MPI 實現在質量上各不相同。
cuFFTMp 使用 NVSHMEM ,這是一個基于 OpenSHMEM 標準的新通信庫,通過提供內核啟動的通信,為 NVIDIA GPU 設計。 NVSHMEM 創建一個全局地址空間,其中包含集群中所有 GPU 的內存。從 CUDA 內核內部執行通信可以實現細粒度遠程數據訪問,從而降低同步成本,并利用 GPU 中的大規模并行性來隱藏通信開銷。
通過使用 NVSHMEM , cuFFTMp 獨立于 MPI 實現的質量,這是至關重要的,因為不同 MPI 的性能可能會有很大差異。有關更多信息,請參閱 關于高性能系統 FFT 庫基準測試的中期報告。第三章 。
圖 3 顯示,隨著 GPU 的數量增加一倍, cuFFTMp 能夠保持大約 75% 的峰值。
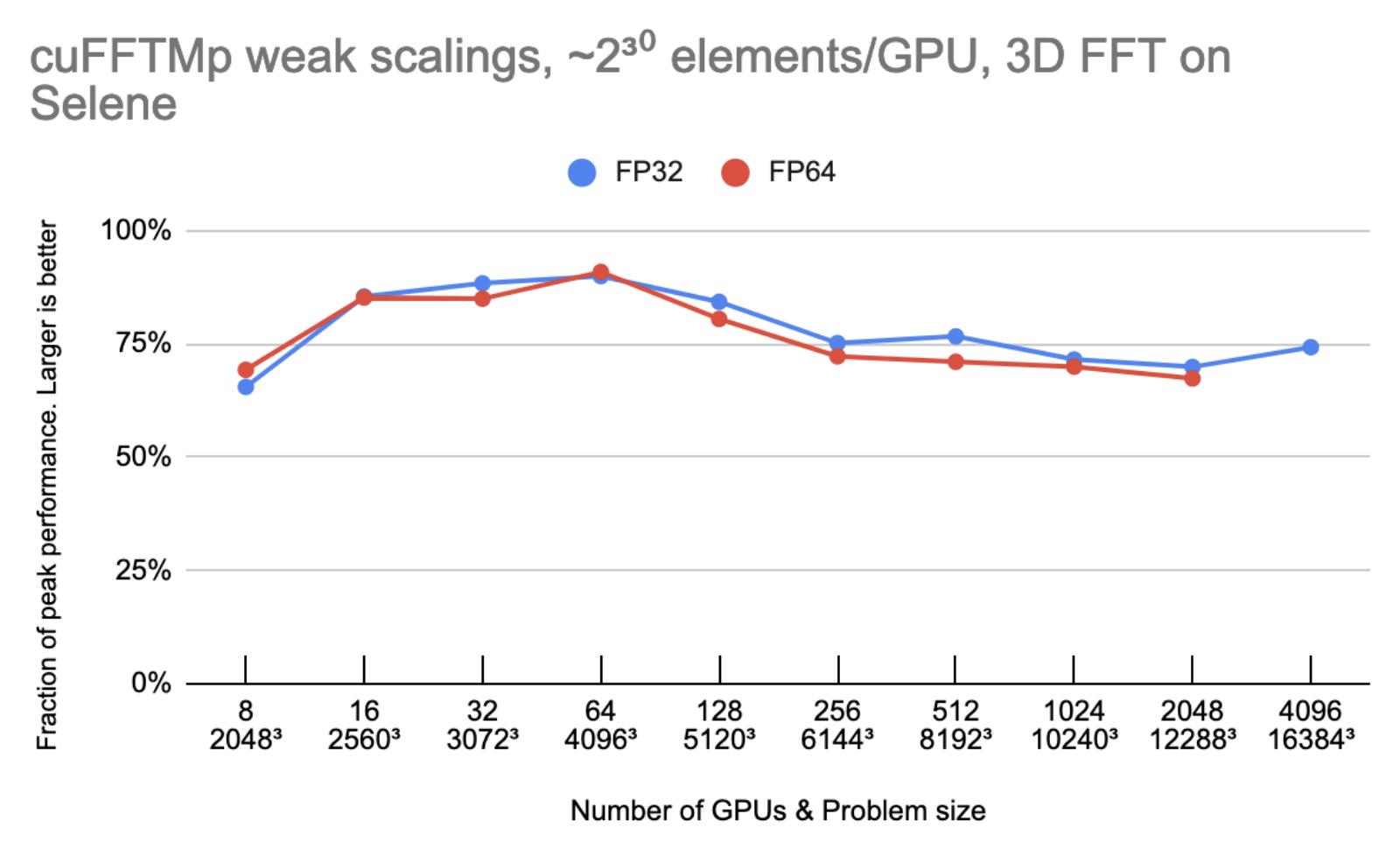
峰值性能是使用 2000 GB / s / GPU 的雙向全局內存帶寬, 300 GB / s / GPU 的雙向 NVLink 帶寬和 25 GB / s / GPU 的 Infiniband 帶寬。
設 N 為 1D 變換大小, G 為 GPU 的個數。每個 GPU 都擁有 N 3/ G 元素(每個元素 8 或 16 字節),模型假設 N 3/ G 元素在全局內存中被讀/寫六次,并且 N 3 G 2元素從每個 GPU 發送一次到其他 GPU 。在 4096 GPU 上,非 InfiniBand 通信所花費的時間不到總時間的 10% 。
MPI 可移植性和多體系結構支持
如前所述, cuFFTMp 的性能不依賴于 MPI 實現。為了便于攜帶, cuFFTMp 要求啟動 MPI ,并管理 CPU 上的數據分發。
目前, TMP 靜態鏈接到 NVSHMEM 。 NVSHMEM 使用一個小型 MPI “引導插件”( NVSHMEM _ bootstrap _ MPI.so ),它是使用 MPI 構建的,并在運行時自動加載。此引導程序針對 HPC SDK 中包含的 OpenMPI 版本。對于依賴于另一個 MPI 實現的用戶應用程序, EA 包包括幫助程序腳本,用于構建針對不同 MPI 的引導程序。
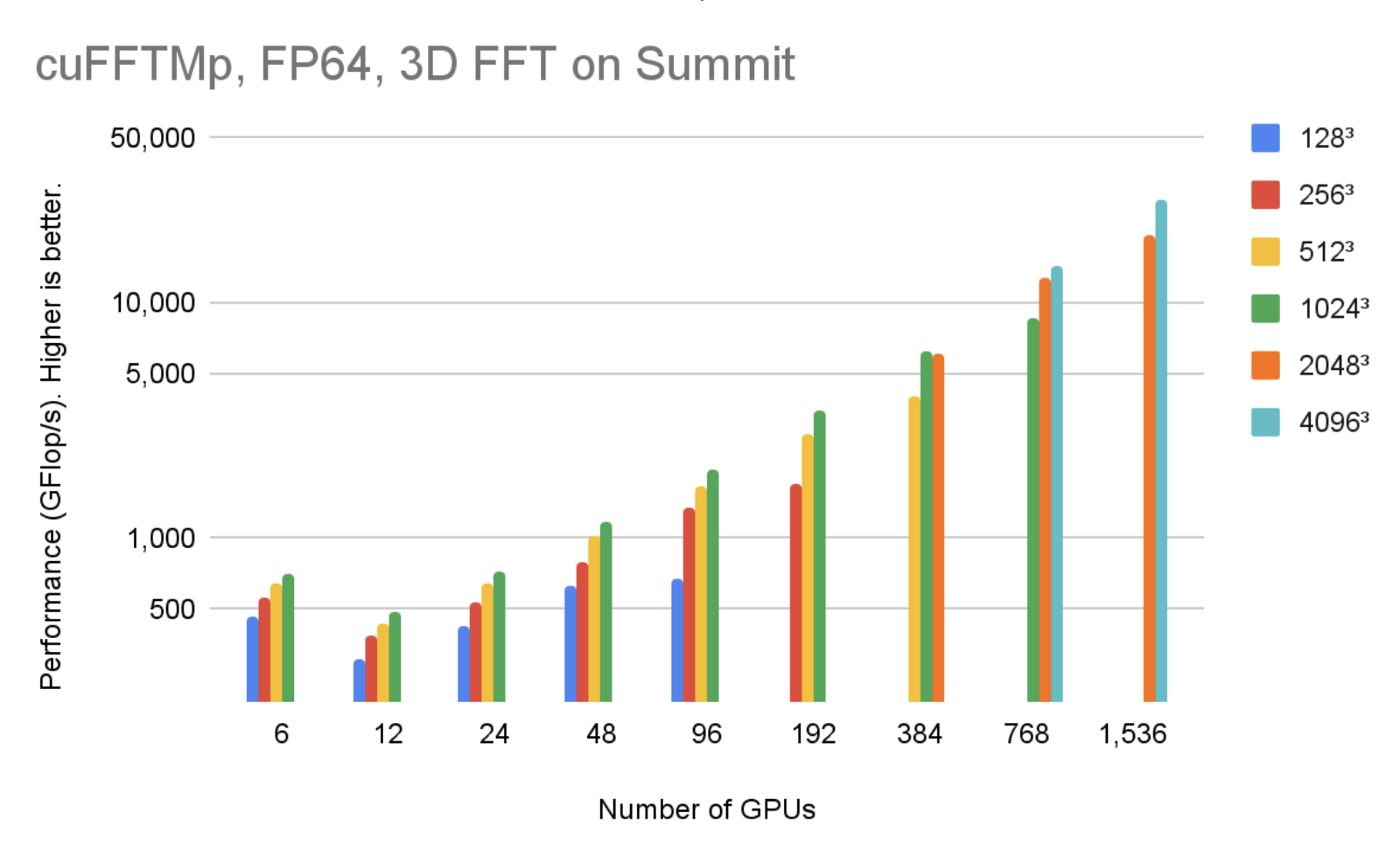
cuFFTMp 同時支持 Linux x86 _ 64 和 IBM POWER 體系結構。您可以下載不同體系結構的 EA 包。圖 4 顯示,在 256 個節點中使用 1536V100 GPU , cuFFTMp 可以達到 50Tflop / s 以上,轉換 40963復雜的數據點,僅占 Summit 系統的 5% 。
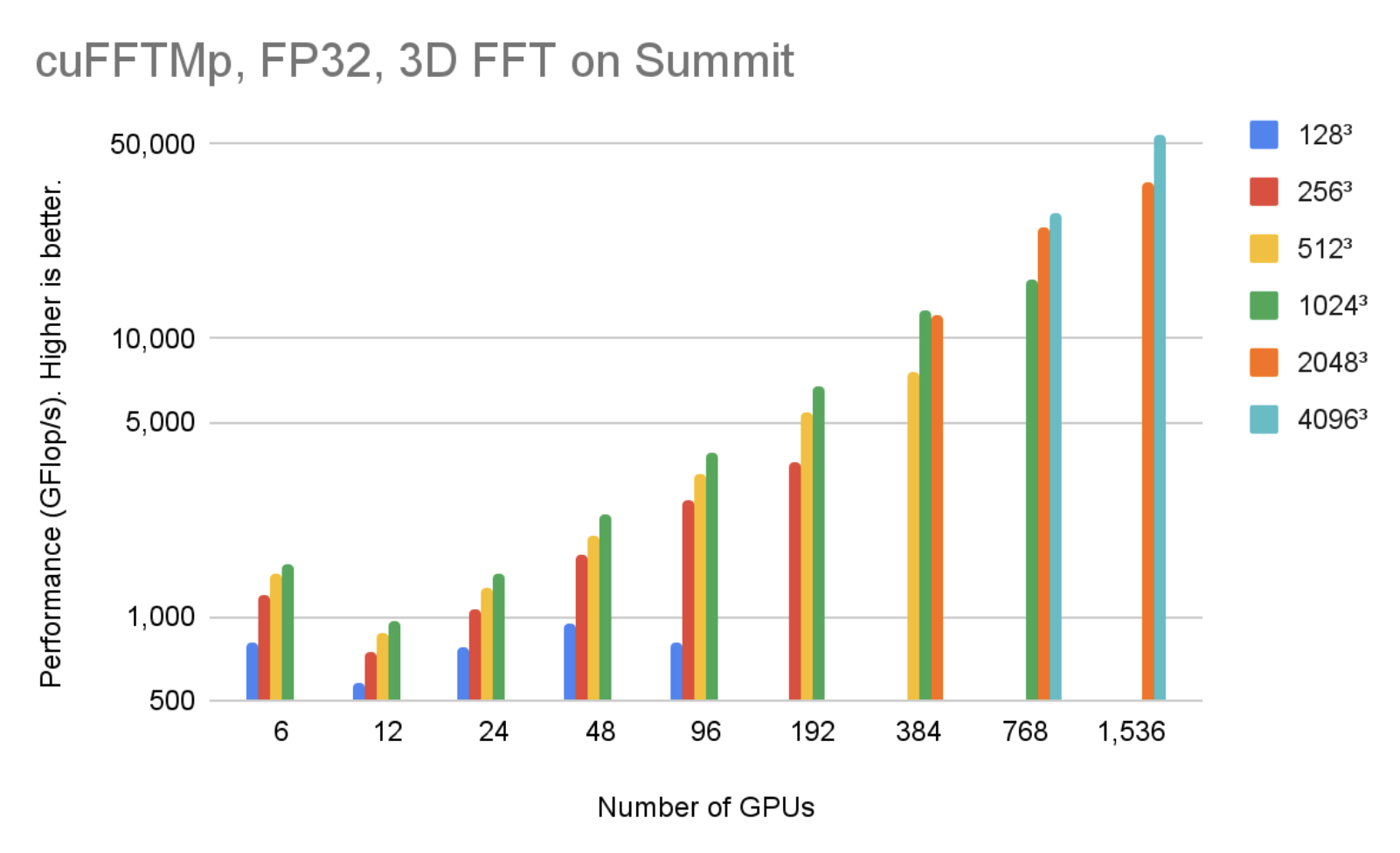
圖 5 顯示,在 256 個節點中使用 1536V100 GPU 時, cuFFTMp 可以達到 4096 個以上的 TFlop / s3復雜的數據點,僅占 Summit 系統的 5% 。
輕松過渡到 TMP
cuFFTMp 只是當前多 GPU cuFFT 庫的擴展。大多數現有的多 GPU 函數適用于 TMP 。作為一個分布式多進程庫, cuFFTMp 要求 MPI 被引導(“啟動”),并期望數據分布在 MPI 進程之間。下表顯示了將應用程序從使用 multi- GPU cuFFT 轉換為 cuFFTMp 所需的代碼。
| Multi-GPU, single-process cuFFT | cuFFTMp |
|---|---|
#include <cufftXt.h> |
#include <cufftMp.h> |
| // host buffer h_f size NX*NY*NZ | // host buffer h_f size my_NX*NY*NZ |
| cufftHandle plan_c2c; cufftCreate(&plan_c2c); |
|
|
for (auto i = 0; i < NGPUS; ++i) |
cufftMpAttachComm(plan, CUFFT_COMM_MPI, MPI_COMM_WORLD) |
|
size_t worksize; |
|
| ? | MPI_Finalize(); |
Slab 、 pencil 和 block 分解是多維 FFT 算法中用于跨節點并行計算的數據分布方法的典型名稱。 cuFFTMp EA 僅支持優化的 slab ( 1D )分解,并提供輔助功能,例如 cufftXtSetDistribution 和 cufftMpReshape ,以幫助用戶從任何其他數據分發重新分發到 cuFFTMp 的 slab 數據分發。
CufftMP EA 包包括 C ++和 Fortran 示例,覆蓋了一系列用例: C2C 、 R2C / C2R 、不同的計劃共享工作空間,以及從一個分布到另一個分布的數據或在 GPU 上重新分布。 cuFFTMp 使用 EA 包中包含的 HPC SDK 21.7 +編譯器和包裝器,為 Fortran 應用程序提供全面支持。
客戶體驗:湍流模擬
cuFFTMp 使科學家能夠研究具有挑戰性的流體湍流問題 物理學中最古老的懸而未決的問題 。
為了了解湍流行為,印度海得拉巴塔塔基礎研究所( TFRI )的一個研究團隊開發了 Fluid3D ,這是一個 CFD 軟件包,使用偽譜方法對 Navier-Stokes 方程進行直接數值模擬( DNS )。通過將 Fluid3D 移植到 cuFFTMp 和 CUDA ,該團隊現在可以在幾個小時內模擬數千個 GPU 上更高的雷諾數流動,這是使用 MPI CPU 版本不可能完成的任務。
在圖 6 中,湍流由不同尺度的漩渦組成,能量從大尺度的運動轉移到小尺度。模擬和理解大型 DNS 運行中最小湍流結構的各向同性行為非常重要。

DNS 是提高對湍流理解的關鍵工具,偽譜方法因其計算效率和準確性而被廣泛使用。
湍流模擬的挑戰是需要獲得高雷諾數( Re )。為了保持計算穩定性, Re 數受到網格分辨率的限制,即 Re 2.25 N 3,其中 N 是每個維度中的網格點數量。因此,模擬高 Re 數湍流需要數值分辨率,計算成本可能會很高,甚至會讓人望而卻步。
表 1 顯示了最大 Re 數所需的網格分辨率以及模擬所需的內存。
| Grid resolution | Simulated Reynolds number | Memory requirement (GB) |
| 10243 | 199.2 | 88 |
| 20483 | 316.2 | 704 |
| 40963 | 501.9 | 5,632 |
| 81923 | 796.8 | 45,056 |
| 122883 | 1044.1 | 152,064 |
| 163843 | 1264.8 | 360,448 |
Fluid3D 在傅里葉空間中使用二階指數時間步進法。模擬通常集成在數萬個時間步上,每個時間步計算九個 3D FFT 。 FFT 主導整個仿真運行時。每個時間步長的壁面時間是衡量數值實驗特定結構的求解時間是否合理的一個重要指標。
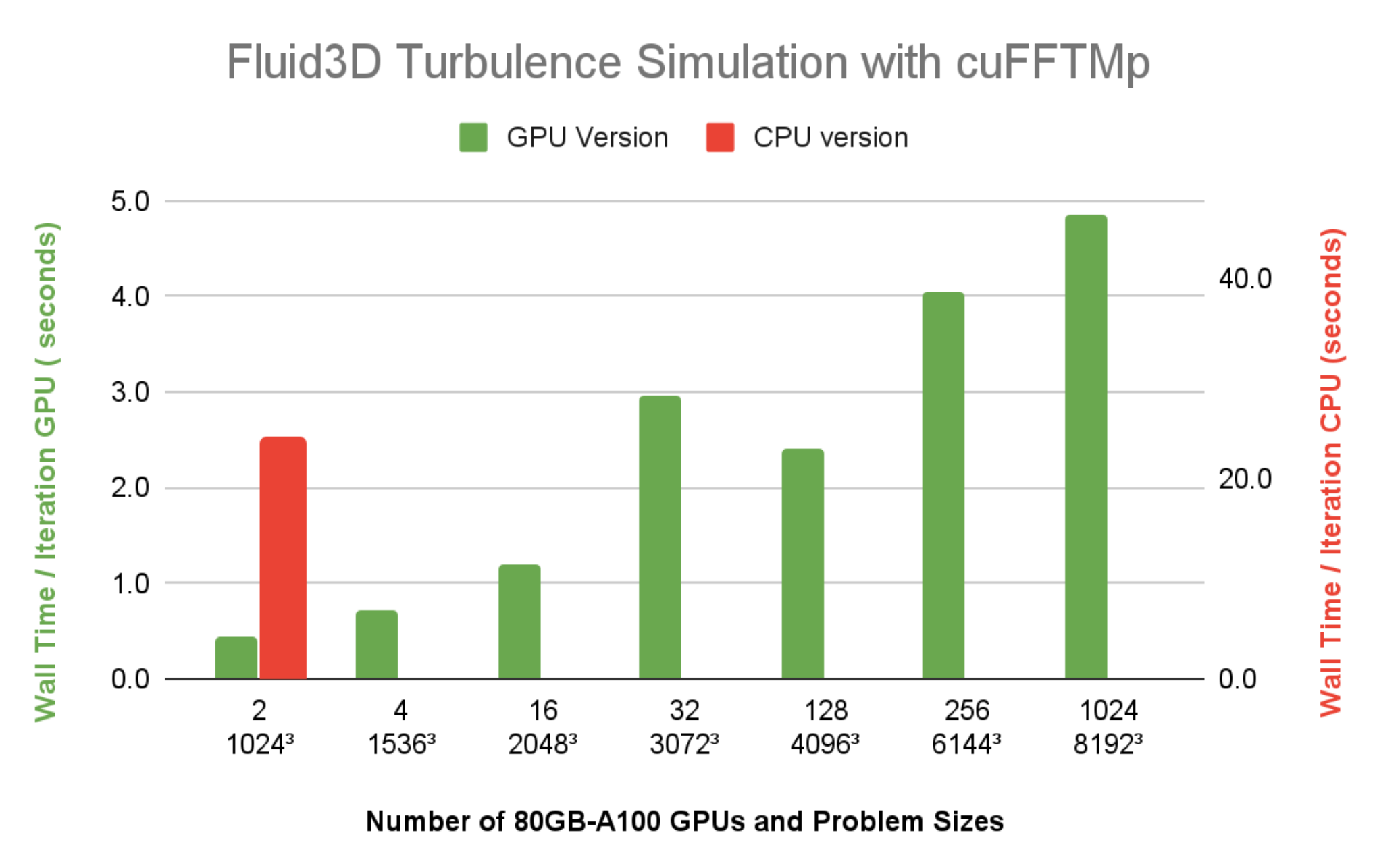
圖 7 顯示了 Fluid3D 的每個時間步的壁時間小于 5 秒,分辨率為 81923,在 Selene 上使用 1024 個 A100 GPU ( 128 個節點)。帶有 FFTW-MPI 的 CPU 版本,每次迭代需要 23.9 秒,分辨率為 10243在單個 64 核 CPU 節點上使用 64 MPI 列組的問題大小。與同樣 1024 小時的墻時間相比3問題大小使用兩個 A100 GPU ,很明顯 Fluid3D 從 CPU 節點到單個 A100 的加速比超過 20 倍。
開始使用 cuFFTMp
有興趣嘗試使用 cuFFTMp 將應用程序轉換為在多個節點上運行嗎?請轉到 cuFFTMp EA 的入門頁面。下載 cuFFTMp 后,玩一下示例代碼,看看它們與 multi- GPU 版本有多相似,以及它們如何在多個節點上擴展。
我們繼續致力于改進 cuFFTMp ,包括添加批處理 API ,以及數據壓縮以最小化通信。如果您有任何問題或新功能請求,請聯系產品經理 Matthew Nicely 。
致謝
特別感謝印度海得拉巴塔塔基礎研究所的 Prasad Perlekar 團隊為我們提供多相湍流代碼 Fluid3D ,并成為 cuFFTMp 的第一個采用者。
我們還感謝 NVIDIA 的整個 NVSHMEM 團隊對 cuFFTMp 開發的支持。