
AI 在規模、復雜性和多樣性方面的快速增長推動了對 大型語言模型 (LLM) 訓練性能的不斷需求。要提供出色的性能,需要能夠在整個數據中心規模上高效地訓練模型。這是通過技術堆棧的每一層 — 包括芯片、系統和軟件 — 的卓越工藝來實現的。
我們的 NVIDIA NeMo 框架 是一個端到端的云原生框架,旨在構建、自定義和部署生成式 AI 模型。它整合了一系列先進的并行技術,以實現大規模 LLM 的高效訓練。
實際上,NeMo 支持 NVIDIA 最近在 MLPerf 訓練 行業標準基準測試中提交的出色 GPT-3 1750 億參數性能數據,每個 H100 GPU 可實現高達 797 TFLOPS 的性能。此外,在 NVIDIA 提交的最大規模測試中,使用了前所未有的 10752 個 H100 Tensor Core GPU,實現了創紀錄的性能和近線性的性能擴展。
今天,NVIDIA 宣布即將在 1 月發布的 NeMo 框架將包含一系列優化和新功能。這些功能將顯著提升 NVIDIA AI Foundations 模型的性能,包括 Llama 2、NeMo Megatron-3 以及其他 LLM,并擴展了對 NeMo 模型架構的支持。此外,它還提供了一種急需的并行技術,使得在 NVIDIA AI 平臺上訓練各種模型變得更加容易。
將 Lama 2 70B 預訓練和監督式微調速度提升高達 4.2 倍
Lama 2 是一種熱門的開源大型語言模型,最初由 Meta 開發。最新版本的 NeMo 包含許多可提高 Lama 2 性能的改進。與在 A100 GPU 上運行的上一個 NeMo 版本相比,在 H200 GPU 上運行的最新 NeMo 版本可將 Lama 2 的預訓練和監督式微調性能提高 4.2 倍。
第一個改進是添加了模型優化器狀態的混合精度實現。這降低了模型容量需求,并將與模型狀態交互的操作的有效內存帶寬提高了 1.8 倍。
旋轉位置嵌入 (RoPE) 運算(許多近期 LLM 架構采用的先進算法)的性能也得到了提升。此外,Swish-Gated Linear Unit (SwiGLU) 激活函數的性能也得到了優化,在現代 LLM 中,該函數通常可取代高斯誤差線性單元 (GELU).
最后,Tensor Parallelism 的通信效率得到大幅提升,并且針對 Pipeline Parallelism 的通信塊大小進行了調整。
總的來說,這些改進基于 GPU 上的 Tensor Core 利用率,NVIDIA Hopper 架構使得每個 H200 GPU 能夠實現高達 836 TFLOPS 的性能,適用于 Lama 2 70B 的預訓練和監督式微調。
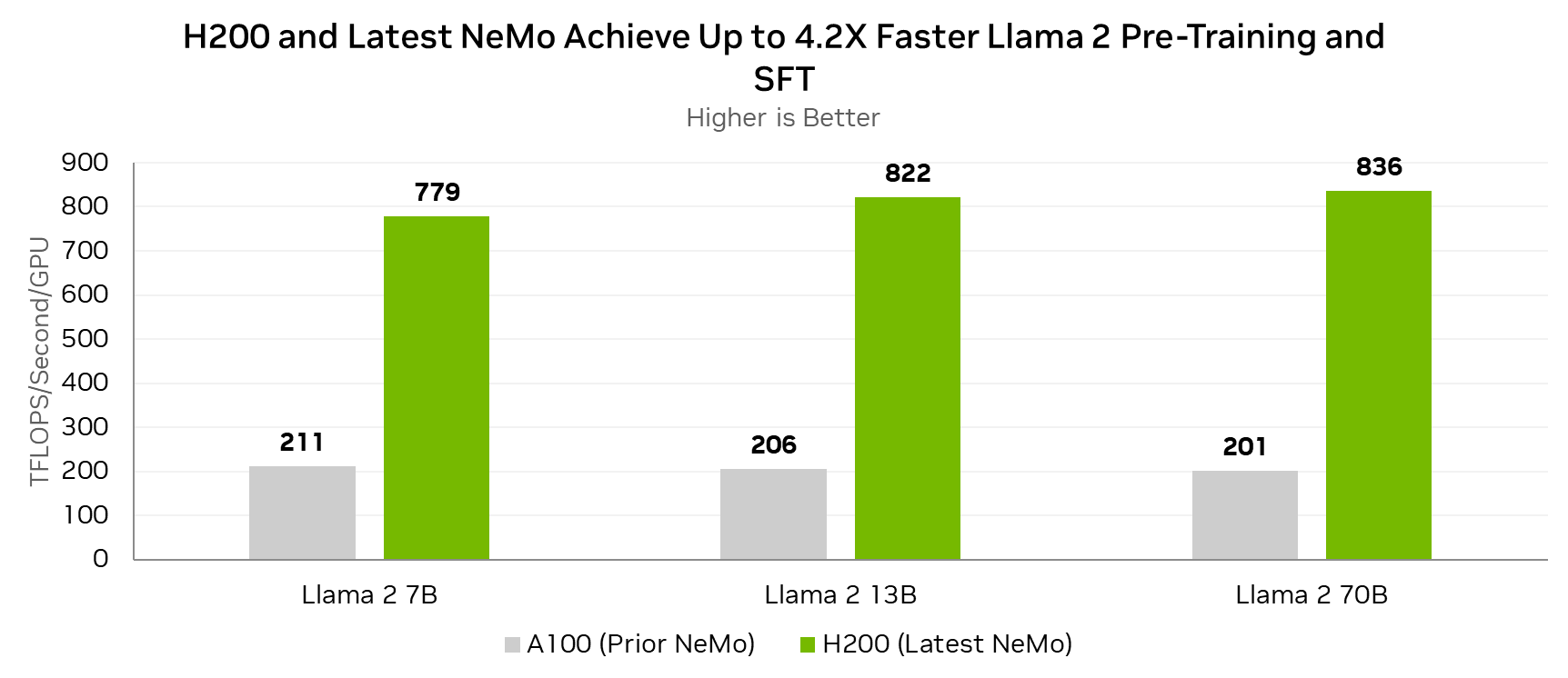
每個 GPU 的測量性能。全局批量大小=128.
||Lama 2 7B:序列長度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 13B:序列長度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 70B:序列長度 4096 A100 32x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
H200 GPU 與最新版本的 NeMo 相結合,可以實現出色的 Lama 2 訓練吞吐量,與運行上一個 NeMo 版本的 A100 GPU 相比,可實現高達 4.2 倍的提升。
| 訓練令牌/秒/GPU | ? | Lama 2 13B | Lama 2 70B |
|---|---|---|---|
| H200 (最新 NeMo) | 小行星 16913 | 9432 | 1880 年 |
| A100 (之前的 NeMo) | 小行星 4583 | 2357 | 451 |
| 加速 | 3.7 倍 | 4.0 倍 | 4.2 倍 |
每個 GPU 的測量性能。全局批量大小=128.
||Lama 2 7B:序列長度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 13B:序列長度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 70B:序列長度 4096 A100 32x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
從上下文來看,基于八路 NVIDIA HGX H200 的單個系統可以在長度為 4096 的序列上使用 70B 參數以超過 15000 個令牌/秒的速率對 Lama 2 進行微調。這意味著它可以在 18 小時多一點的時間內完成包含 1B 令牌的監督式微調任務。
完全分片數據并行
全分片數據并行 (FSDP) 是深度學習社區中眾所周知的熱門功能。它被主要框架(包括 PyTorch、DeepSpeed 和 JAX)中的深度學習從業者所使用,并應用于各種模型。
FSDP 可應用于各種模型,并且對于 LLM 尤其有用,因為現代 LLM 的計算和內存需求遠遠超出了單個高級 GPU 的范圍。
對模型進行管線處理是一種有效的性能優化。但這需要模型具有非常規則的結構(例如,同一層重復 128 次),因為不同的層分布在不同的 GPU 上,并且數據以管線方式在它們之間流動。
FSDP 為開發者提供了更高的易用性,并將各種情況下的性能損失降至最低。這是因為模型的數據和內存是按層分布的,因此更容易管理常規或不規則的神經網絡結構。
作為數據并行性的自然擴展,FSDP 通常可通過簡單的模型包裝器來使用,而無需考慮模型的分區方式(就像管道并行中的情況一樣)。這還可以更輕松地將 FSDP 擴展到新的和新興的模型架構,例如多模態 LLM.
在小于全局批量大小的規模上有足夠的并行性時,FSDP 還可以實現與張量并行性和管道并行性方法的傳統組合具有競爭力的性能。
| GPT-20B 訓練性能 (BF16) | |||||
| H100 GPU 數量 | 8 | 16 | 32 | 64 | 128 |
| FSDP | 0.78 倍 | 0.88 倍 | 0.89 倍 | 0.86 倍 | 0.96 倍 |
| 3D 并行度 | 1.0 倍 | 1.0 倍 | 1.0 倍 | 1.0 倍 | 1.0 倍 |
測量性能。全局批量大小=256,序列長度=2048
多專家模型
提高生成式 AI 模型的信息吸收和泛化能力的一種經過驗證的方法是增加模型中的參數數量。但是,隨著模型容量的增加,執行推理所需的計算量也會增加,從而增加在生產環境中運行模型的成本。
最近,一種名為“多專家模型 (MoE)”的機制引起了極大的關注。該機制能夠在訓練和推理計算需求不按比例增加的情況下提高模型容量。MoE 架構通過條件計算方法來實現這一點,其中每個輸入令牌僅路由到一個或幾個專家神經網絡層,而不是通過它們全部路由。這將模型容量與所需的計算解。
最新版本的 NeMo 引入了對具有專家并行性的基于 MoE (Mixture of Experts) 的 LLM (Large Language Models) 架構的官方支持。此實現采用的架構類似于平衡分配專家 (BASE),其中每個 MoE 層將每個令牌精確地傳送給一位專家,并采用算法實現負載均衡。NeMo 使用基于Sinkhorn算法的路由,以在各個專家之間平衡令牌負載。
基于 NeMo 的 MoE 模型支持專家并行,可與數據并行結合使用,在數據并行秩中分配 MoE 專家。NeMo 還提供了任意配置專家并行的能力。用戶可以以各種方式將專家映射到不同的 GPU,而不限制單個設備上的專家數量(但是,所有設備必須包含相同數量的專家)。NeMo 還支持專家并行大小小于數據并行大小的情況。
開發者可以將 NeMo 專家并行方法與 NeMo 提供的許多其他并行維度(包括張量、管線和序列并行)結合使用。這有助于在具有多個 NVIDIA GPU 的集群上高效訓練具有超過萬億個參數的模型。
使用 TensorRT-LLM 的 RLHF
現在,使用 TensorRT-LLM 在 RLHF 循環內進行推理的能力增強了 NeMo 對基于人類反饋的強化學習 (RLHF) 的支持。
TensorRT-LLM 可加速 Actor 模型的推理階段,該階段目前占用了大部分端到端計算時間。Actor 模型是正在對齊的感興趣模型,將成為 RLHF 過程的最終輸出。
即將發布的 NeMo 版本通過 TensorRT-LLM 實現 RLHF 的管道并行,使其能夠以更少的節點實現更好的性能,同時還支持更大的模型。
事實上,對于 Lama 2 70B 參數模型,與在同一 H100 GPU 上不使用 TensorRT-LLM 的 RLHF 循環相比,在配備 H100 GPU 的 RLHF 循環中使用 TensorRT – LLM 可實現高達 5.6 倍的性能提升。
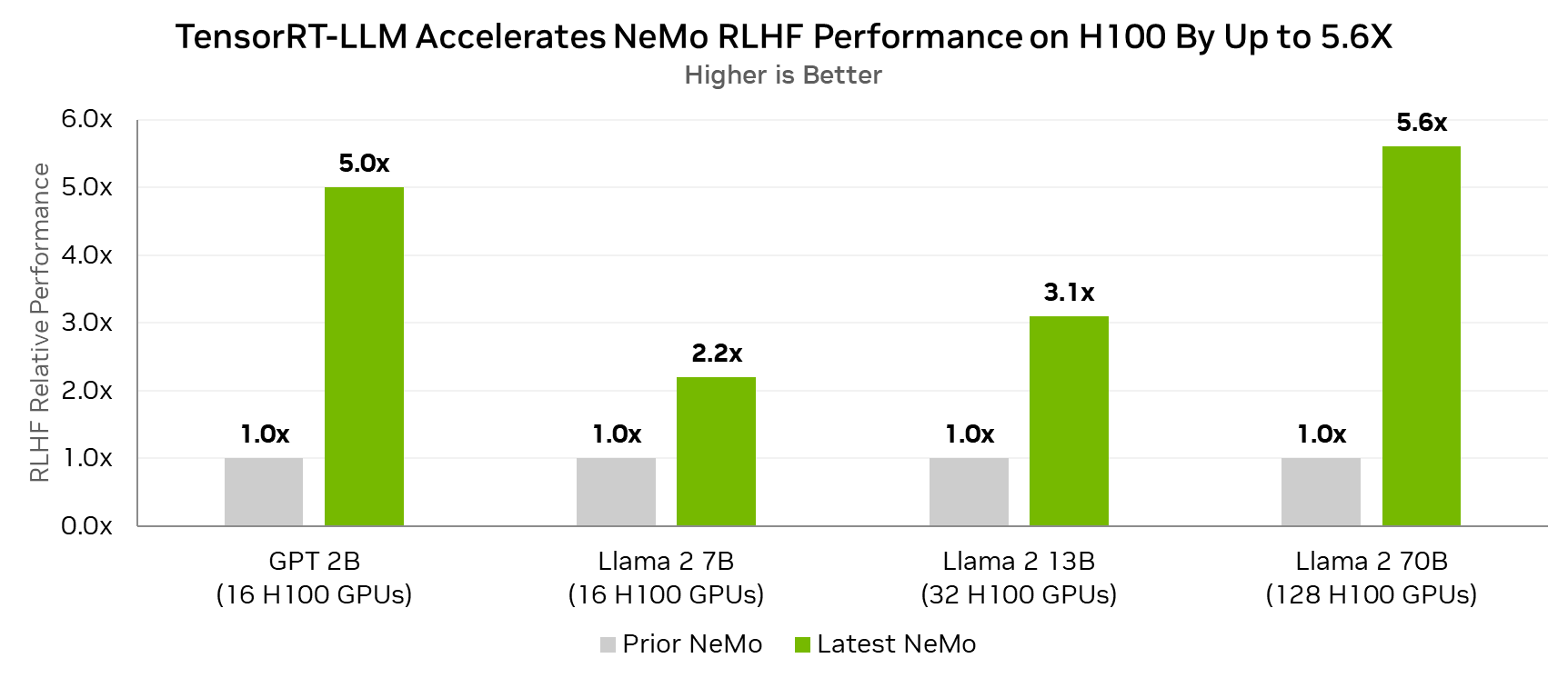
測量性能。全局批量大小=64,滾動大小=512,最大生成長度=1024.
在實施的 RLHF 算法中,每個結果的一半節點運行 Actor,另一半運行 Critical.
突破生成式 AI 的界限
AI 訓練需要全棧方法。 NVIDIA NeMo 會定期更新,為訓練高級生成式 AI 模型提供最佳性能。它采用最新的訓練方法來提高性能,并為 NVIDIA 平臺用戶提供更高的靈活性。
NVIDIA 平臺的應用范圍極其廣泛,能夠端到端地加速整個 AI 工作流程,包括數據準備、模型訓練以及部署推理。繼 10 月推出 TensorRT-LLM 之后,NVIDIA 最近展示了在單個 H200 GPU 上運行最新的 Falcon-180B 模型的能力。該模型利用了 TensorRT-LLM 的先進 4 位量化技術,同時保持了 99% 的準確率。欲了解更多關于此實現的信息,請訪問關于 TensorRT-LLM 的最新帖子。
NVIDIA AI 平臺不斷以光速提升性能、通用性和功能。因此,它是開發和部署當今生成式 AI 應用程序以及發明為未來提供動力支持的模型和技術的首選平臺。
開始使用 NeMo 框架
我們的 NVIDIA NeMo 框架 可以作為 GitHub 上的開源庫、NGC 上的容器使用,同時也是 NVIDIA AI Enterprise 的一部分。NVIDIA AI Enterprise 是一個為企業級 AI 提供的軟件平臺,它具備安全性、穩定性、可管理性和強大的支持功能。
?






