
最新一代熱門 Llama AI 模型現已支持 Llama 4 Scout 和 Llama 4 Maverick。它們由 NVIDIA 開源軟件加速,在 NVIDIA Blackwell B200 GPU 上每秒可實現超過 40K 輸出 token,并可作為 NVIDIA NIM 微服務 進行試用。
Llama 4 模型現在采用混合專家 (MoE) 架構,原生支持多模態和多語言。Llama 4 模型提供各種多模態功能,推動規模、速度和效率的提升,使您能夠打造更加個性化的體驗。
Llama 4 Scout 是一個 109B 參數模型,每個令牌活躍 17B,由 16 位專家組成,擁有 10M 上下文長度的窗口,并針對單個 NVIDIA H100 GPU 優化和量化為 int4。這支持各種用例,包括多文檔摘要、解析大量用戶活動以執行個性化任務,以及對大量代碼庫進行推理。
Llama 4 Maverick 是一個 400B 參數模型,每個 token 活躍 17B,由 128 名專家組成,接受 1M 上下文長度。該模型可提供高性能的圖像和文本理解。
已針對 NVIDIA TensorRT-LLM 進行優化
NVIDIA 針對 NVIDIA TensorRT-LLM 優化了 Llama 4 Scout 和 Llama 4 Maverick 模型。TensorRT-LLM 是一個開源庫,用于加速 NVIDIA GPU 上最新基礎模型的 LLM 推理性能。
您可以使用 TensorRT Model Optimizer (一個可以使用最新的算法模型優化和量化技術重構 bfloat16 模型的庫),在不影響模型準確性的情況下,利用 Blackwell FP4 Tensorcore 性能加速推理。
在 Blackwell B200 GPU 上,TensorRT-LLM 通過 NVIDIA 優化的 Llama 4 Scout 的 FP8 版本提供每秒超過 40K 個 token 的吞吐量,在 Llama 4 Maverick 上提供每秒超過 30K 個 token。
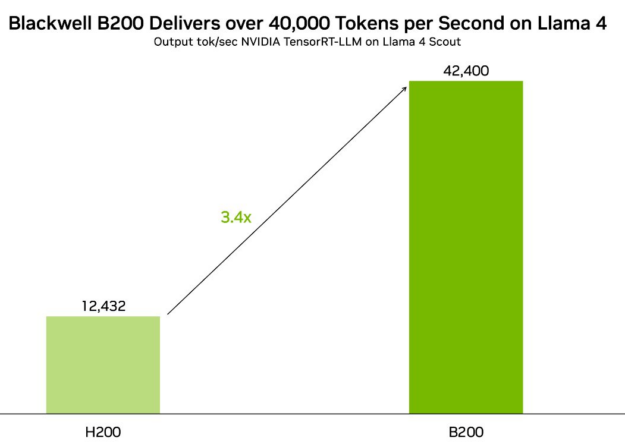
Blackwell 憑借架構創新實現了巨大的性能飛躍,包括第二代 Transformer Engine、第五代 NVLink 以及 FP8、FP6 和 FP4 精度,可實現更高的訓練和推理性能。對于 Llama 4,這些進步提供了 3.4 倍的吞吐量提升和 2.6 倍的單令牌成本提升,與 NVIDIA H200 相比。
最新的 Llama 4 優化可在開源 NVIDIA/TensorRT-LLM GitHub 資源庫中獲取。
Meta 和 NVIDIA 的持續合作
NVIDIA 和 Meta 在合作推進開放模型方面有著長期的記錄。NVIDIA 是一個積極的開源貢獻者 ,可幫助您高效工作,解決最棘手的挑戰,并提高性能和降低成本。
開源模型還提高了 AI 透明度,讓用戶能夠廣泛分享 AI 安全性和彈性方面的工作。這些開放模型與 NVIDIA 加速計算 相結合,使開發者、研究人員和企業能夠在各種應用中負責任地進行創新。
后訓練 Llama 模型以提高準確性
NVIDIA NeMo 是一個端到端框架,專為使用您的企業數據定制大語言模型 (LLMs) 中的 Llama 模型而構建。
首先,使用 NeMo Curator 管理高質量的預訓練或微調數據集,這有助于大規模提取、篩選和刪除重復的結構化和非結構化數據。然后,使用 NeMo 高效地微調 Llama 模型,并支持 LoRA、PEFT 和完整參數調整等技術。
對模型進行微調后,您可以使用 NeMo Evaluator 評估模型性能。NeMo Evaluator 支持行業基準測試,也支持根據您的特定用例定制的自定義測試集。
借助 NeMo,企業可以獲得強大而靈活的工作流,以調整 Llama 模型,以適應生產就緒型 AI 應用。
借助 NVIDIA NIM 簡化部署
為了確保企業可以利用這些模型,Llama 4 模型將被打包為 NVIDIA NIM 微服務,以便在任何 GPU 加速的基礎設施上輕松部署,同時具有靈活性、數據隱私和企業級安全性。
NIM 還通過支持行業標準 API 簡化了部署,因此您可以快速啟動和運行。無論您使用的是 LLMs、vision models、或 multimodal AI,NIM 都能消除基礎架構的復雜性,并實現跨云、數據中心和 edge environments 的無縫擴展。
立即開始使用
試用 Llama 4 NIM 微服務 來試驗您自己的數據,并通過將 NVIDIA 托管的 API 端點集成到您的應用中來構建概念驗證。
?





