?
隨著大型語言模型( LLM )的規模和復雜性不斷增長, NVIDIA 今天宣布更新 NeMo Megatron 框架,提供高達 30% 的訓練速度。
這些更新包括兩種開拓性技術和一個超參數工具,用于優化和擴展任何數量 GPU 上的 LLM 訓練,提供了使用 NVIDIA AI 平臺訓練和部署模型的新功能。
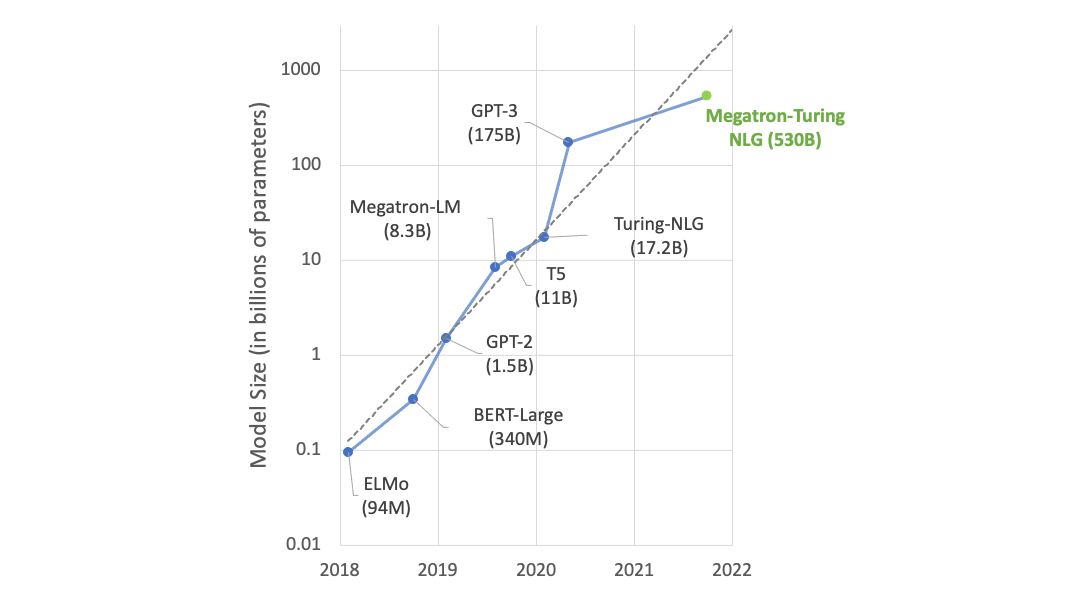
BLOOM?,世界上最大的開放科學、開放獲取多語言模型,具有 1760 億個參數,最近 在 NVIDIA AI 平臺上接受培訓 ,支持 46 種語言和 13 種編程語言的文本生成。 NVIDIA AI 平臺還支持最強大的 transformer 語言模型之一,具有 5300 億個參數, Megatron-Turing NLG 模型 (MT-NLG).
法學碩士研究進展
LLM 是當今最重要的先進技術之一,涉及數萬億個從文本中學習的參數。然而,開發它們是一個昂貴、耗時的過程,需要深入的技術專業知識、分布式基礎設施和全堆棧方法。
然而,在推進實時內容生成、文本摘要、客戶服務聊天機器人和對話 AI 界面的問答方面,它們的好處是巨大的。
為了推進 LLM ,人工智能社區正在繼續創新工具,例如 Microsoft DeepSpeed , 巨大的人工智能 , 擁抱大科學 和 公平比例 –由 NVIDIA AI 平臺提供支持,涉及 Megatron LM , 頂 ,以及其他 GPU 加速庫。
這些對 NVIDIA AI 平臺的新優化有助于解決整個堆棧中存在的許多難點。 NVIDIA 期待著與人工智能社區合作,繼續讓所有人都能使用 LLM 。
更快地構建 LLM
NeMo Megatron 的最新更新為訓練 GPT-3 模型提供了 30% 的加速,模型大小從 220 億到一萬億參數不等。現在,使用 1024 個 NVIDIA A100 GPU 只需 24 天,就可以在 1750 億個參數模型上完成訓練——在這些新版本發布之前,將得出結果的時間減少了 10 天,或約 250000 個小時的 GPU 計算。
NeMo Megatron 是一種快速、高效且易于使用的端到端集裝箱化框架,用于收集數據、訓練大規模模型、根據行業標準基準評估模型,以及用于推斷最先進的延遲和吞吐量性能。
它使 LLM 訓練和推理在廣泛的 GPU 簇配置上易于重復。目前,這些功能可供早期訪問客戶使用 DGX 疊加視圖 和 NVIDIA DGX 鑄造廠 以及 Microsoft Azure 云。對其他云平臺的支持將很快提供。
你可以試試這些功能 NVIDIA LaunchPad ,這是一個免費項目,提供對 NVIDIA 加速基礎設施上的動手實驗室目錄的短期訪問。
NeMo Megatron 是 NeMo 的一部分, NeMo 是一個開源框架,用于為會話人工智能、語音人工智能和生物學構建高性能和靈活的應用程序。
加速 LLM 訓練的兩種新技術
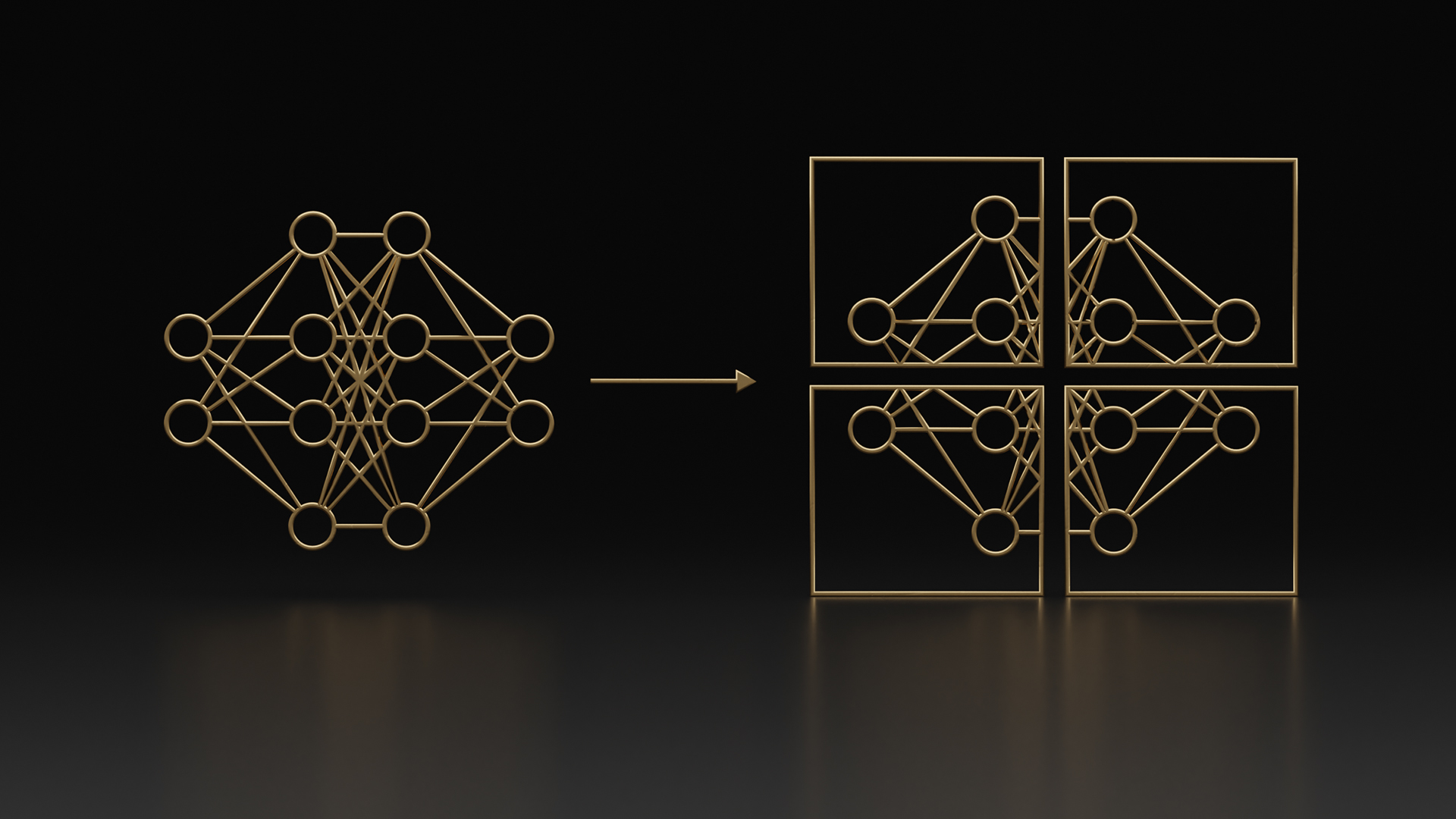
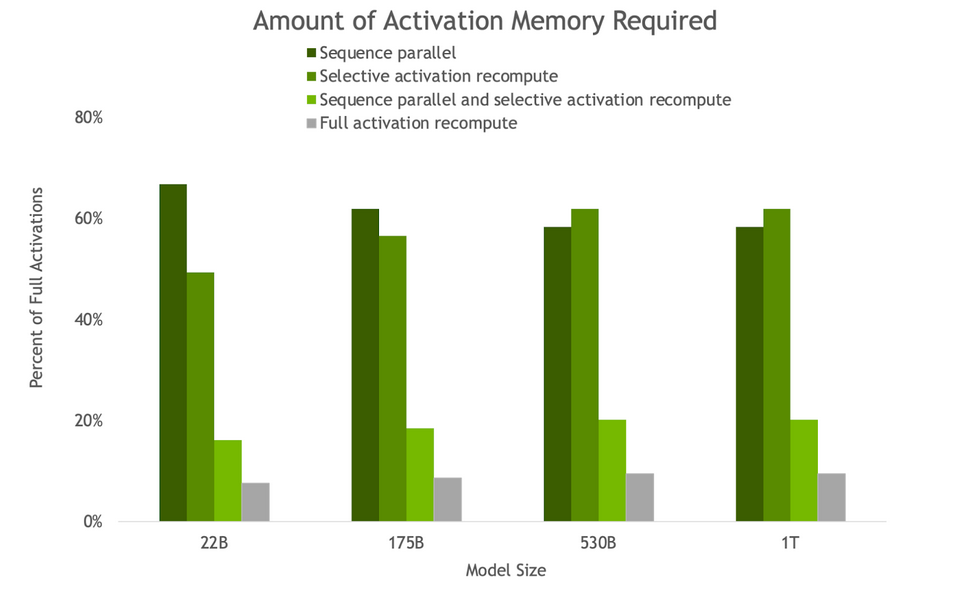
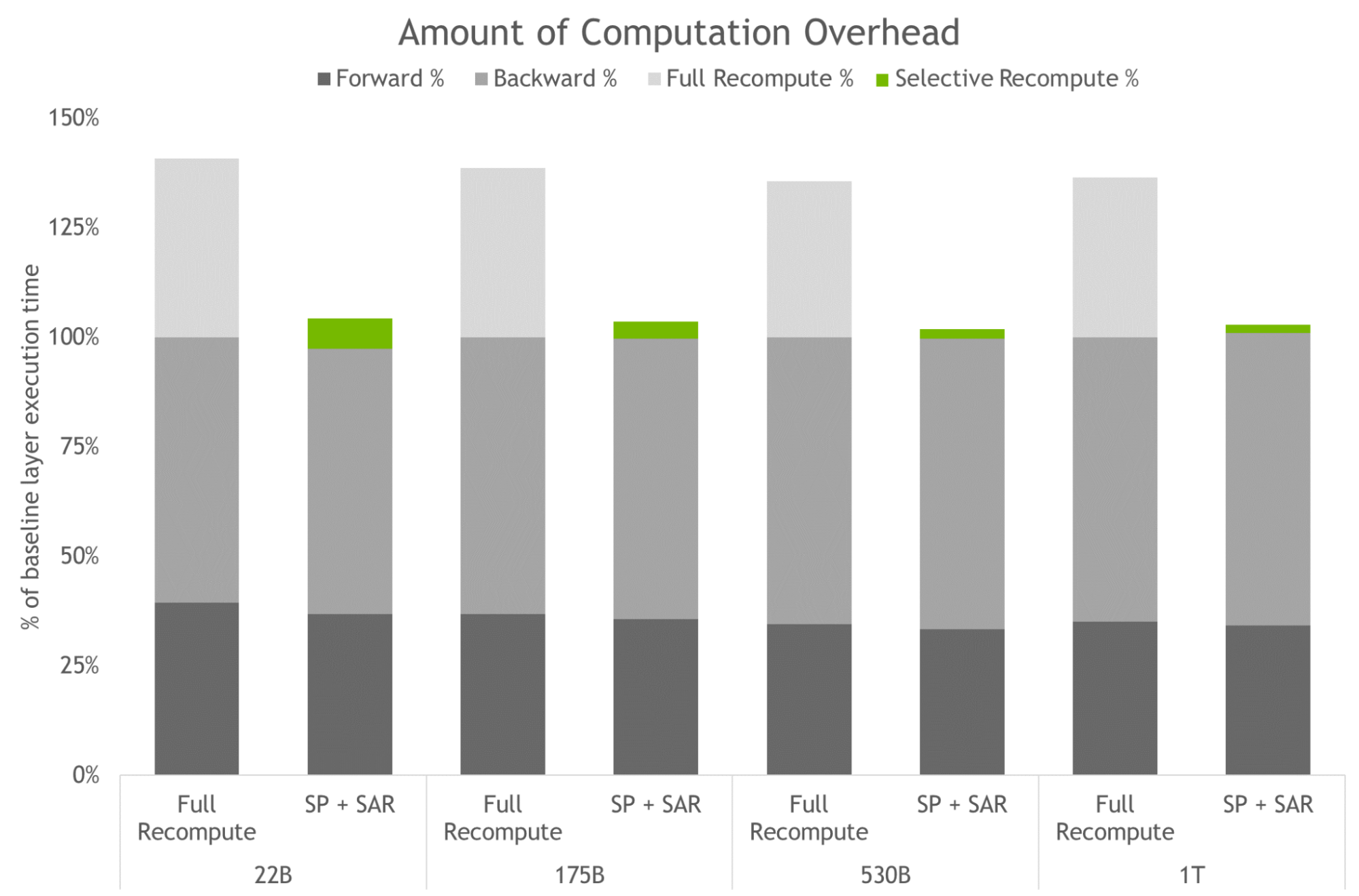
優化和擴展 LLM 訓練的更新中包括兩種新技術,即序列并行( SP )和選擇性激活重新計算( SAR )。
序列并行性擴展了張量級模型并行性,注意到之前未并行的 transformer 層的區域沿序列維度是獨立的。
沿著序列維度拆分這些層可以實現計算的分布,最重要的是,這些區域的激活內存可以跨張量并行設備分布。由于激活是分布式的,因此可以為向后傳遞保存更多激活,而不是重新計算它們。
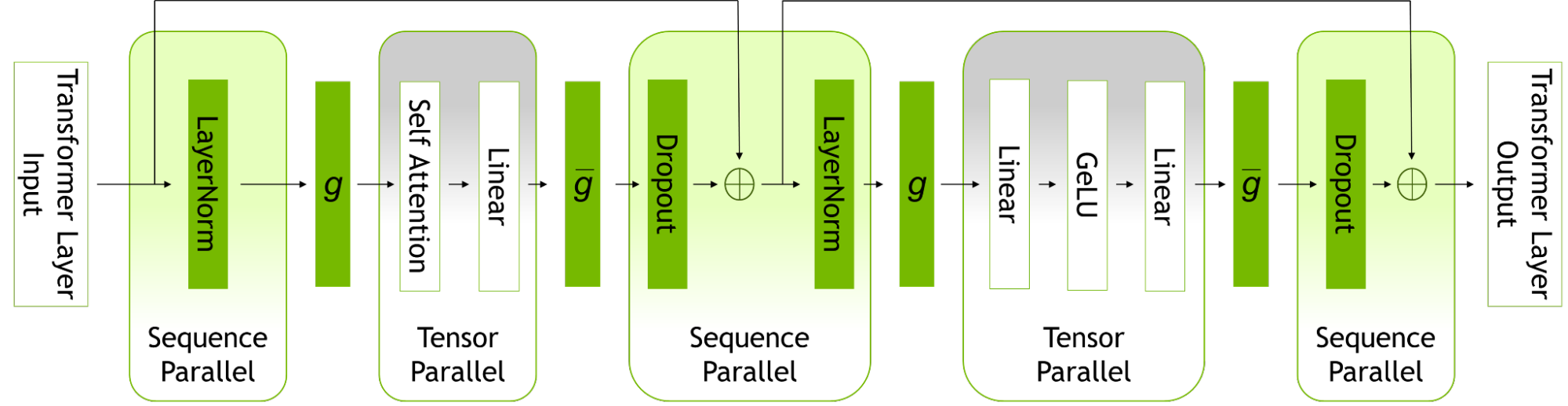
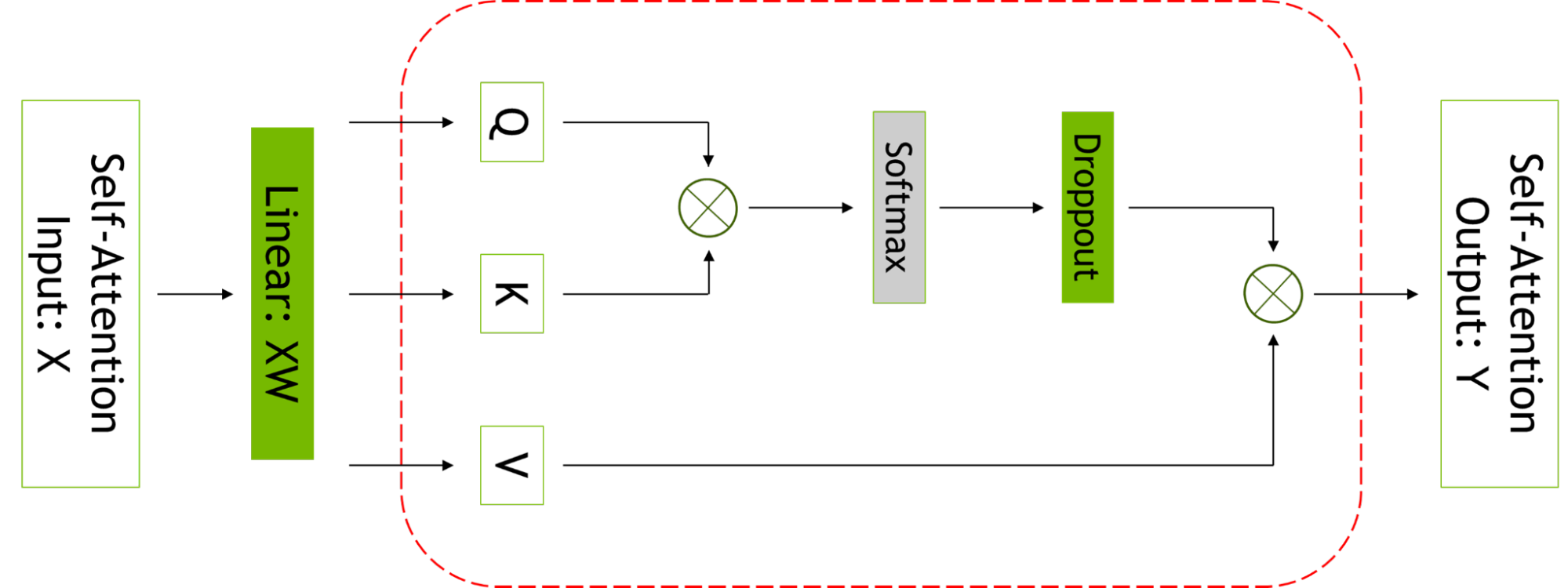
選擇性激活重新計算通過注意到不同的激活需要不同數量的操作來重新計算,從而改善了內存約束強制重新計算部分(但不是全部)激活的情況。
與檢查點和重新計算整個 transformer 層不同,可以只檢查和重新計算每個 transformer 層中占用大量內存但重新計算計算成本不高的部分。
有關更多信息,請參閱 減少大型 transformer 模型中的激活重新計算 .
訪問 LLM 的功能還需要高度優化的推理策略。用戶可以輕松地使用經過訓練的模型進行推理,并使用 p- 調優和即時調優功能針對不同的用例進行優化。
這些功能是微調的參數有效替代方案,并允許 LLM 適應新的用例,而無需對完全預訓練模型進行嚴格的微調。在這種技術中,原始模型的參數不會改變。因此,避免了與微調模型相關的災難性“遺忘”問題。
有關更多信息,請參閱 采用 P-Tuning 解決非英語下游任務 .
用于訓練和推理的新超參數工具
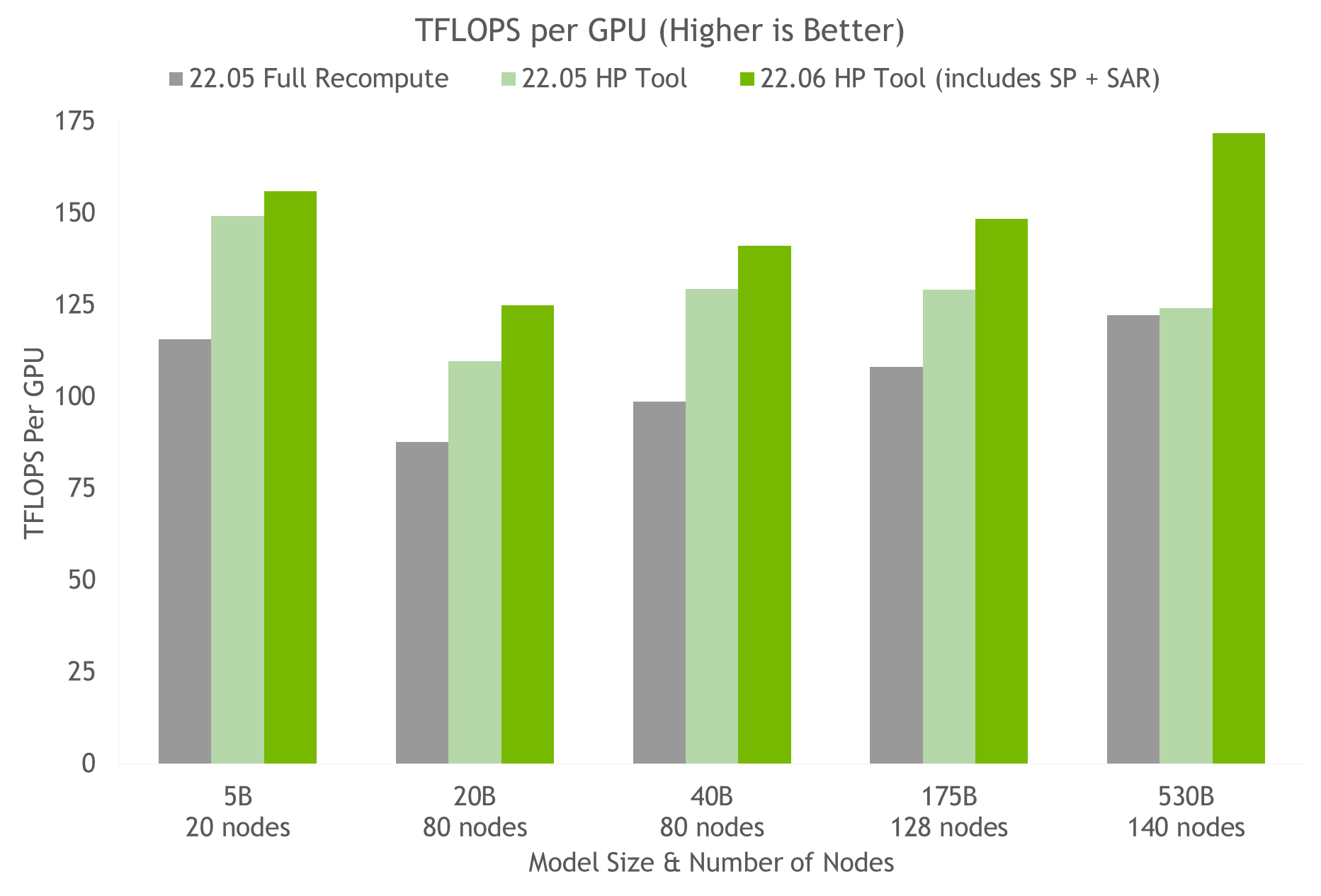
跨分布式基礎設施查找 LLM 的模型配置是一個耗時的過程。 NeMo Megatron 引入了一種超參數工具,可以自動找到最佳的訓練和推理配置,無需更改代碼。這使得 LLM 能夠從第一天開始訓練收斂以進行推理,從而消除了搜索有效模型配置所浪費的時間。
它跨不同參數使用啟發式和經驗網格搜索,以找到具有最佳吞吐量的配置:數據并行性、張量并行性、管道并行性、序列并行性、微批量大小和激活檢查點層的數量(包括選擇性激活重新計算)。
使用超參數工具和 NVIDIA 對 NGC 上的容器進行測試,我們在 24 小時內獲得了 175B GPT-3 模型的最佳訓練配置(見圖 5 )。與使用完全激活重新計算的常見配置相比,我們實現了 20%-30% 的吞吐量加速。使用最新技術,對于參數超過 20B 的模型,我們實現了額外 10%-20% 的吞吐量加速。
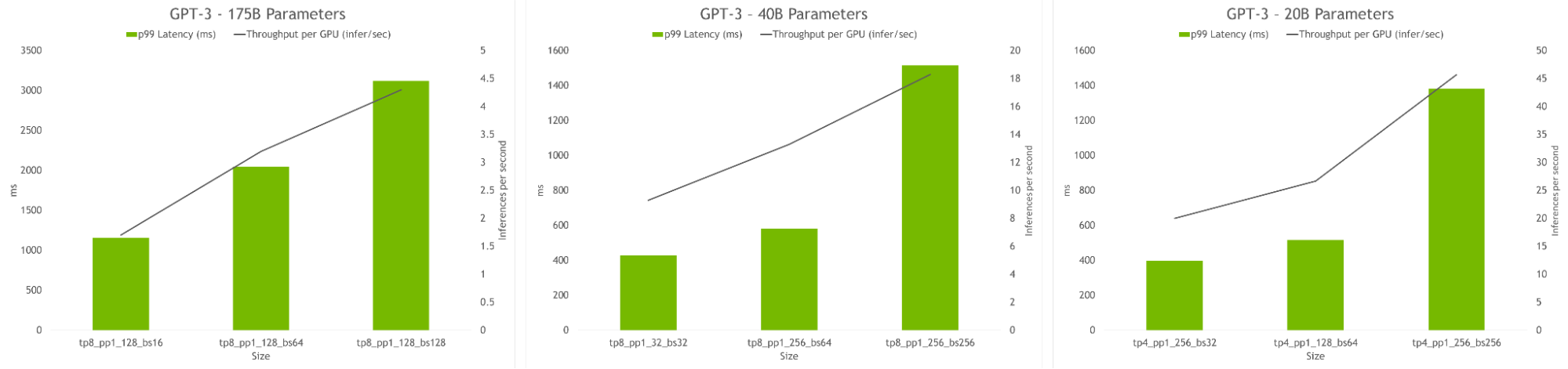
hyperparameter 工具還允許查找在推理過程中實現最高吞吐量或最低延遲的模型配置。可以提供延遲和吞吐量約束來為模型服務,該工具將推薦合適的配置。
為了探索針對 LLM 的 NVIDIA AI 平臺的最新更新, 申請提前進入 NeMo Megatron。 企業也可以嘗試 NVIDIA LaunchPad 上的 NeMo Megatron ,免費提供。
致謝
我們要感謝維賈伊·科爾蒂坎蒂、賈里德·卡斯珀、弗吉尼亞·亞當斯和姚對本帖的貢獻。
?