
NVIDIA 和 Mozilla 很自豪地宣布了 通用語音數據集 的最新版本,擁有超過 13000 小時的眾包語音數據,并向語料庫中添加了另外 16 種語言。
Common Voice 是世界上最大的開放數據語音數據集,旨在實現語音技術的民主化。全世界的研究人員、學者和開發人員都在使用它。貢獻者動員自己的社區向 MCV 公共數據庫捐贈語音數據,任何人都可以使用它來培訓語音技術。作為 NVIDIA 與 Mozilla Common voice 合作的一部分,通過一個名為 NVIDIA NeMo 的開源工具包,可以免費獲得在此和其他公共數據集上培訓的模型。
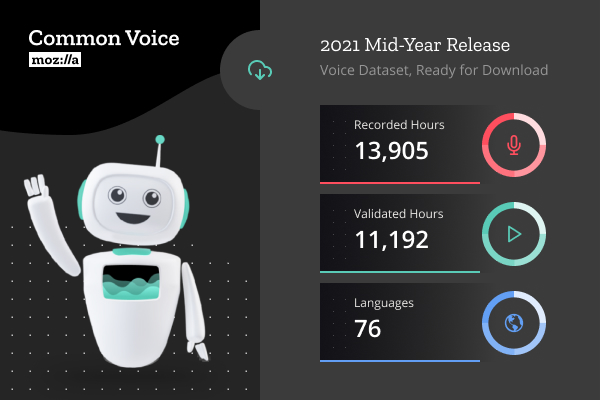
本版本的亮點包括:
- 通用語音數據集發布時間現在是 13905 小時,比上一版本增加了 4622 小時。
- 向通用語音數據集中引入 16 種新語言:巴薩語、斯洛伐克語、北庫爾德語、保加利亞語、哈薩克語、巴什基爾語、加利西亞語、維吾爾語、亞美尼亞語、白俄羅斯語、烏爾都語、瓜拉尼語、塞爾維亞語、烏茲別克語、阿塞拜疆語、豪薩語。
- 按總學時數計算,前五名語言為英語( 2630 學時)、基尼亞盧旺達語( 2260 學時)、德語( 1040 學時)、加泰羅尼亞語( 920 學時)和世界語( 840 學時)。
- 增長最快的語言是泰語(增長近 20 倍,從 12 小時到 250 小時)、盧干達語(增長 9 倍,從 8 小時到 80 小時)、世界語(增長超過 7 倍,從 100 小時到 840 小時)和泰米爾語(增長超過 8 倍,從 24 小時到 220 小時)。
- 該數據集現在擁有超過 182000 個獨特的聲音,貢獻者社區在短短六個月內增長了 25% 。
預訓練模型:
NVIDIA 免費發布了 計算機中的多語言語音識別模型 NGC ,作為語音技術民主化合作任務的一部分。 NeMo 是一個開源工具包,供研究人員開發最先進的對話人工智能模型。研究人員可以在多語言數據集上進一步微調這些模型。參見本文中的示例 筆記本 在 MCV 日語數據集上微調英語語音識別模型。
貢獻您的聲音,并驗證示例:
該數據集依靠世界各地許多社區的驚人努力和貢獻。花點時間記錄您的聲音并驗證來自其他貢獻者的樣本,從而反饋到數據集: https://commonvoice.mozilla.org/speak
您可以從 https://commonvoice.mozilla.org/datasets 下載最新的 MCV 數據集,包括完整統計數據的回購 https://github.com/common-voice/cv-dataset/ ,以及 NGC 目錄 和 GitHub 的 NVIDIA NeMo 。
“問我任何事”:
2021 年 8 月 4 日 UTC 時間下午 3 : 00 – 4 : 00 / EDT 時間下午 2 : 00 – 3 : 00 / PDT 時間上午 11 : 00 –下午 12 : 00 :
為了慶祝數據集的發布, Mozilla 將于 8 月 4 日與首席工程師 Jenny Zhang 主持 AMA 討論會。 Jenny 將現場回答您的問題,若要加入并提出問題,請使用 以下是 AMA 的話題
?






