量子位本身對噪聲很敏感,預計即使是最可靠的量子位也始終會表現出比實際量子應用所需數量級的噪聲水平。
此噪聲問題可通過 量子糾錯(Quantum Error Correction,QEC) 解決。這是一系列能夠以可控方式識別和消除錯誤的技術,前提是量子位的噪聲級別可以低于某個更可實現的閾值級別。QEC 代碼將許多物理量子位編碼為邏輯量子位,這些量子位在防止錯誤時保持穩健性。
在這種方法中,通過重復測量構成邏輯量子位的許多物理量子位的選定組,然后在推理錯誤發生位置的傳統算法中使用測量結果 (此過程稱為 解碼 ) 來糾正錯誤。解碼具有計算挑戰性,是 QEC 技術的主要瓶頸之一。
構建快速、準確且可擴展的解碼器對于實現有用的量子計算機至關重要。在許多案例中, AI 通過解決與 QEC、編譯、 算法開發 等相關的挑戰來支持量子計算 ,這是一個很好的例子。
在 GTC 25 上,NVIDIA 宣布使用 NVIDIA CUDA-Q 平臺與 QuEra 合作開發一款基于 Transformer 的 AI 解碼器。該解碼器不僅超越了先進的解碼器,而且為未來的可擴展解碼提供了一條前景光明的道路。
這項工作的成果展示了 AI 超級計算機 (例如最近宣布成立的 NVIDIA 加速量子研究中心 (NVAQC)) 對于量子糾錯技術的開發和部署至關重要。
解碼解碼器
QEC 代碼通常以【n,k,d】命名,其中 n 是物理量子位的數量,k 是邏輯量子位的數量,d 是距離。更遠距離的代碼能夠糾正更多錯誤,但通常需要更復雜的編碼方案和更大的物理量子比特用度。
糾正作用于一組物理量子位(Figure 1)上的錯誤的第一步是對其中的子集執行一組選定的測量,這些測量共同產生所謂的誤差綜合征。
然后,將綜合癥數據傳輸到經典處理器(classical processor)中進行解碼。解碼器的目標是從誤差綜合征中推斷出是否發生了任何錯誤。然后,解碼器會輸出對錯誤位置的最佳猜測,這些猜測可被追蹤并最終用于確定要發送回量子處理單元(QPU)的糾正操作。在量子算法的整個過程中,此循環會不斷重復。
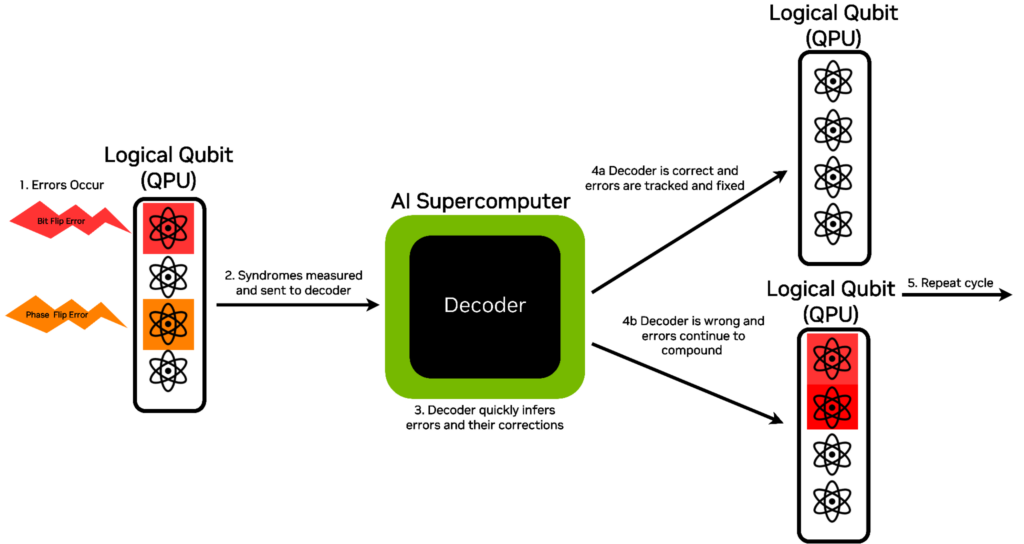
解碼器的準確性至關重要:如果解碼器出錯,錯誤要么漏掉,要么因不當更正而引入,這可能會損壞編碼信息并破壞算法。
高精度解碼器可降低邏輯錯誤率。與其他解碼器相比,使用更低的距離代碼可以實現相同的目標錯誤率,從而減少所需的物理量子位數量。
除了準確性之外,解碼器還必須快速且可擴展。如果解碼器無法及時處理傳入的綜合征數據,則會出現積壓,導致錯誤滾雪球,導致無法進行糾錯。這也對解碼器在 QPU 之間傳輸數據的速度提出了嚴格的延遲要求。
AI 在復雜模式識別方面的能力及其自然可擴展性使其成為構建解碼器的最具前景的工具之一,這些解碼器快速、準確,并且能夠擴展以處理有用的量子計算所需的數百萬個物理量子位。
利用來自 QuEra 的 QPU 的數據施展魔法
在 QPU 上實施量子算法需要一個容錯的通用門集,并且可以從中對任何算法進行編程。在大多數量子計算的容錯方法中,容錯執行運算的策略依賴于能夠準備所謂的“magic state”。這些特殊狀態是一種資源,可以在計算中使用,以執行任意量子計算,也稱為通用量子計算。
事實上,在容錯量子計算機中完成的大部分工作都會產生 magic states。但似乎有一個 Catch-22。如何在不訪問其承諾提供的容錯運算的情況下可靠地生成 magic states?
一種解決方案是 Magic State Distillation (MSD)。MSD 協議將大量噪聲魔術狀態作為輸入,并使用一系列操作(本質上是一個簡單的量子糾錯碼)將其“提煉”為單個、更高保真的魔術狀態,確保生成高質量的魔術狀態。
但 MSD 的成本很高。通常需要進行多輪 MSD,以生成可在算法中使用的足夠保真的魔術狀態。此外,隨著達到充分無噪音的魔術狀態所需的回合數,MSD 所需的資源也呈指數級增長。這意味著,任何提高每一輪 MSD 輸出的效率和保真度的方法都有可能大幅減少容錯量子計算的開銷。
QuEra 最近發表的論文 Experimental Demonstration of Logical Magic State Distillation 展示了一項使用中性原子 QPU 上的邏輯量子位執行 magic state distillation 的實驗。他們首先將 35 個中性原子量子位編碼為五個邏輯 magic states。然后,他們使用 5-to-1 協議 (Figure 2) ,蒸出單一的、更高保真的 magic state。
![A diagram shows the [[7,1,3]] color code which is used to prepare the five logical qubits for the 5-to-1 magic state distillation circuit.](https://developer-blogs.nvidia.com/wp-content/uploads/2025/03/five-logical-magical-states-1024x343.png)
QuEra 使用 [[7,1,3]] 顏色代碼 (圖 2) 對每個邏輯量子位進行編碼。MSD 過程包含兩個量子位邏輯門,這也會導致邏輯量子位之間的誤差傳播。
為提高輸出的保真度,QuEra 使用了一種名為“ 相關解碼 ”的方法,即同時從所有邏輯量子位解讀癥狀以推理錯誤,而不是單獨解碼每個邏輯量子位。這樣做的好處是,可以解碼由邏輯 2-量子位門引起的相關錯誤,從而提高解碼器的準確性。這需要一個功能強大的解碼器來解釋所有 35 個物理量子位的癥狀。
QuEra 的方法是使用最有可能出錯 (MLE) 的解碼器來解決相關解碼問題。MLE 是一種高精度解碼算法,需要解決 NP 難題,因此其先進的性能以算法運行時隨代碼大小呈指數級增長為代價。
對于 MLE 解碼器來說,這是一個嚴重的問題。它們的擴展不會超過最小的代碼距離。對于距離為 5 的 [[85,1,5]] MSD,MLE 需要超過 100 毫秒的時間,這遠遠超出了任何實際使用的時間要求。
NVIDIA 和 QuEra 開發了一個基于 Transformer 的 AI 解碼器,并使用 NVIDIA PhysicsNeMo 進行訓練,以解決此問題。對于 QuEra 的距離 3 MSD 電路,NVIDIA 解碼器的性能優于性能出色但擴展性較差的 MLE 解碼器。
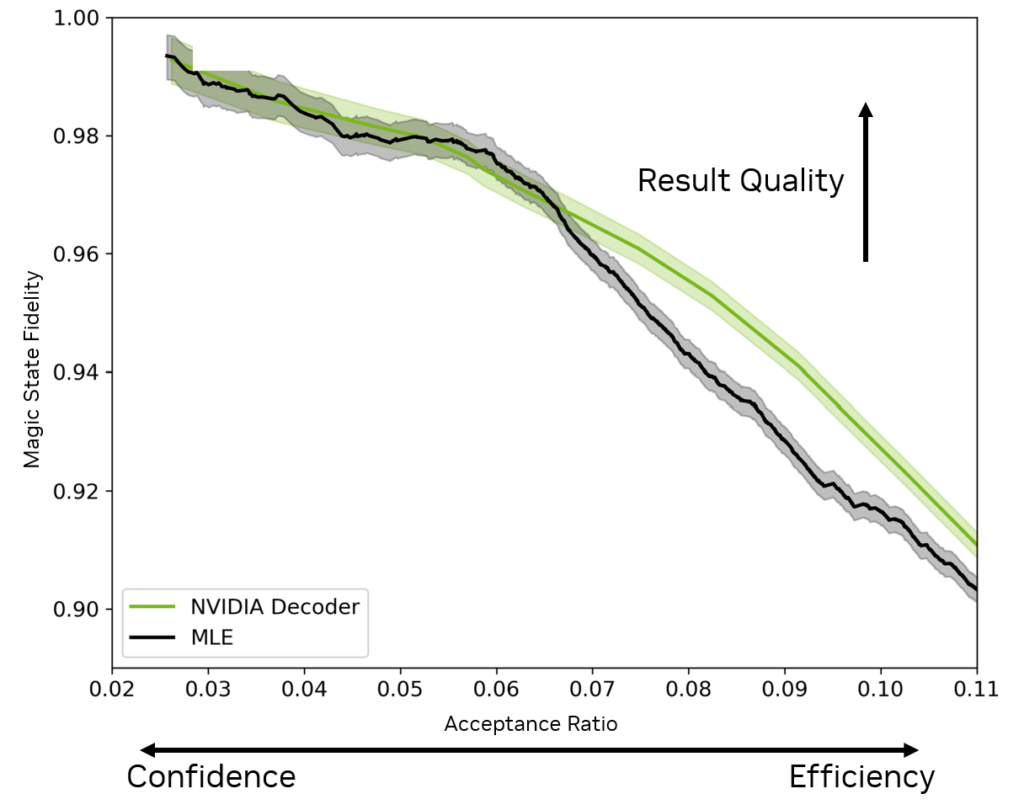
圖 3 將 MLE 和 NVIDIA 解碼器結果繪制為 接受率 函數,接受率是成功實驗運行的分數,其中綜合征的置信度高于特定閾值,接受率越大,魔術狀態的生產速度就越高。圖 3 顯示,對于給定的魔術狀態保真度目標,NVIDIA 解碼器可以更高效地運行,并在高接受率區域產生比 MLE 更多的魔術狀態。
對于實際應用而言,次優但可擴展的解碼器仍然是對 MLE 的改進,但 NVIDIA 解碼器在超越 MLE 的同時具有廣闊的擴展潛力。通過超越 MLE,NVIDIA 解碼器提供了一種功能強大的新工具,該工具還可以擴展到研究人員探索更強大的糾錯碼所需的代碼距離。
NVIDIA 解碼器的性能優于 MLE 的原因之一是其精心設計的架構。Transformer 的注意力機制有助于對不同輸入之間的依賴關系進行動態建模,使其能夠非常有效地捕獲復雜的交互。圖神經網絡(Graph Neural Network,GNN)可用于組合圖結構中的相鄰信息,表示癥狀與邏輯量子位之間的關系。
NVIDIA 解碼器的另一個主要優勢是,它可以主要使用模擬生成的合成數據進行訓練,從實際的量子硬件中提取的實驗數據更少。這避免了在有限的 QPU 資源上執行多次成本高昂的運行。
QuEra 硬件團隊生成了寶貴的數據來驗證和在未來微調 NVIDIA 解碼器的性能,但如果不這樣做,他們可以將機器時間集中在其他工作上,而模型的訓練數據是通過 stim (由 Google 開發并與 CUDA-Q 平臺集成的穩定器電路模擬器) 生成的。
使用 AI 超級計算機擴展 NVIDIA 解碼器
要產生足夠低的邏輯錯誤率,必須使用更高的距離代碼(圖 4)。MLE 無法擴展到這一點,因此 NVIDIA 和 QuEra 正在利用 AI 超級計算來生成更高的代碼距離所需的訓練數據,并為模型訓練和推理的并行化提供 AI 架構,從而努力擴展 NVIDIA 解碼器。即使是最小的(d=3)情況,MLE 解碼器也需要數十毫秒,而 NVIDIA 解碼器可以在一毫秒內解碼任務。
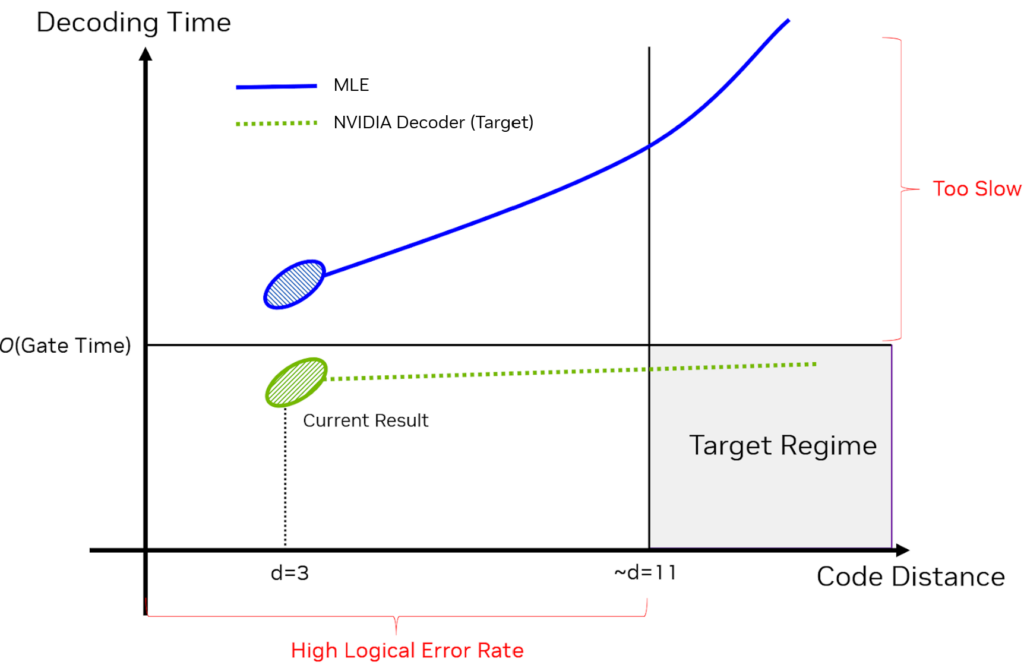
在 MLE 中,解碼的負擔被訓練的挑戰所取代。訓練 NVIDIA 解碼器所需的數據量會隨著代碼距離的增加而呈指數級增長。該團隊正在使用 CUDA-Q 的 GPU 加速、基于軌跡的模擬器生成的數據來完善和擴展解碼器。NVIDIA 研究人員開發了新的采樣算法,可高效生成大量高質量數據集,其中包含更逼真的非 Clifford 噪聲的速度比之前使用 CUDA-Q 時快 1M 倍。
借助這些算法,單個 NVIDIA DGX-H100 節點每小時可生成超過 10 億個鏡頭,用于 35 量子位 MSD 電路的狀態向量模擬。使用 NVIDIA Eos 超級計算機等整個超級計算機,數據生成可以突破極限,其生成數據的速度非常驚人,達到每小時半萬億次數據點擊。
CUDA-Q 的噪聲張量網絡后端還可以將電路模擬擴展到生成用于訓練更大代碼距離的數據所需的量子位數量。訓練 NVIDIA 解碼器,在 42 個 H100 GPU 上運行,在一小時內完成距離=3 的代碼。除了使用來自 QuEra 的 QPU 的實驗數據進行微調之外,更遠距離的訓練將更具挑戰性,并且需要 AI 超級計算的強大功能。
NVIDIA 和 QuEra 使用先進的 NVIDIA Blackwell GPU 大規模生成和訓練數據,從而不斷擴展 NVIDIA 解碼器,而 NVAQC 將成為 NVIDIA 和 QuEra 不可或缺的資源。
詳細了解 NVIDIA 解碼器和量子計算
NVIDIA 正在與 QuEra 等合作伙伴合作,以實現有意義的量子糾錯,更廣泛地說,實現用于量子突破的 AI,并縮短實現有用量子計算的時間線。
有關支持量子誤差計算研究的其他 NVIDIA 工具的更多信息,請參閱 CUDA-Q QEC。
如需詳細了解 NVIDIA 為加速量子計算開發而開展的所有其他工作 ,請參閱 NVIDIA Quantum Computing。
?
?