今天, NVIDIA 發布了 TensorRT 8 . 0 ,通過新的優化將 BERT 的大推理延遲降低到 1 . 2 毫秒。該版本還提供了 2 倍的精度為 INT8 精度與量化意識的訓練,并通過支持稀疏性,這是引進安培 GPU 的顯著更高的性能。
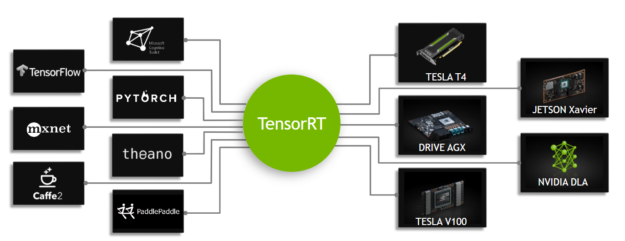
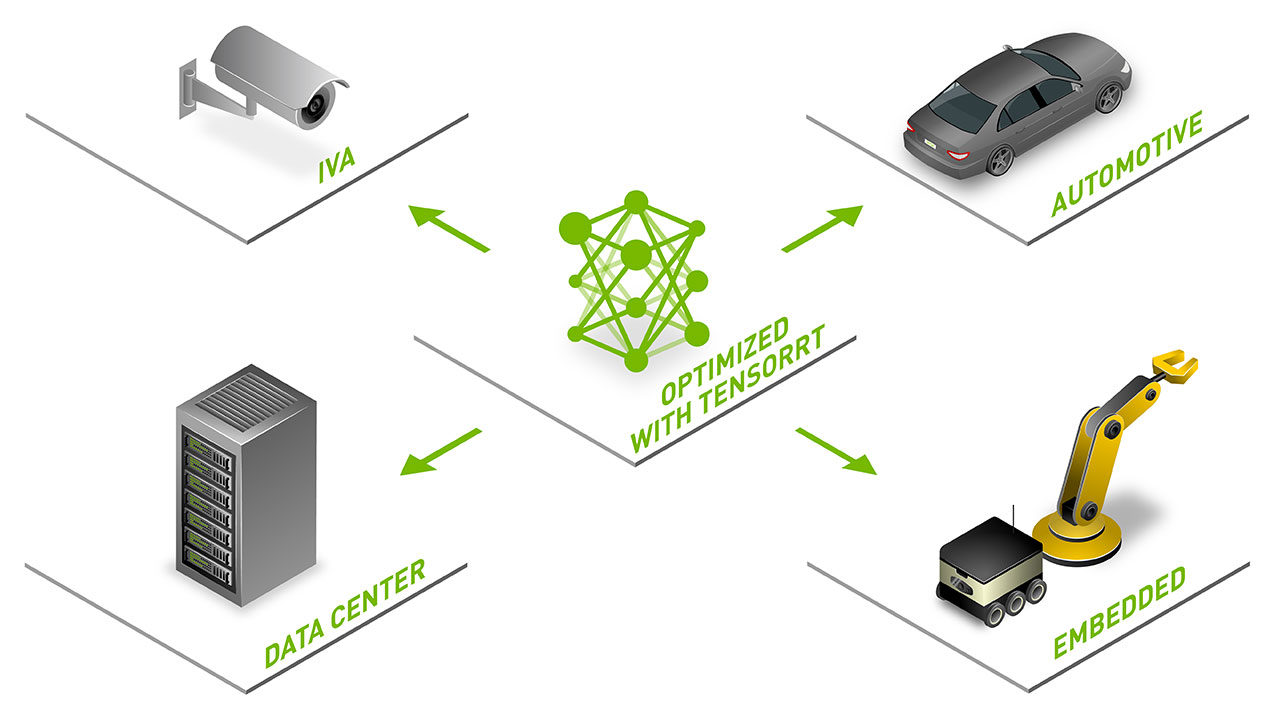
TensorRT 是一個用于高性能深度學習推理的 SDK ,包括推理優化器和運行時,提供低延遲和高吞吐量。 TensorRT 用于醫療、汽車、制造、互聯網/電信服務、金融服務、能源等行業,下載量近 250 萬次。
有幾種新的基于 transformer 模型被用于會話人工智能。 TensorRT 中的新的廣義優化可以加速所有這些模型,將推理時間減少到 TensorRT 7 的一半。
此版本的亮點包括:
- BERT 在 1 . 2 毫秒內進行推斷,并進行了新的 transformer 優化
- 使用量化感知訓練,以 INT8 精度實現與 FP32 相當的準確性
- 引入稀疏性支持對安培 GPU 的快速推理
您可以進在此處進一步了解稀疏性。
微信是中國最大的社交媒體平臺之一,它使用 TensorRT 加速搜索,每月服務 5 億用戶。
“我們已經實現了基于 TensorRT – 和 -INT8 QAT 的模型推理加速,以加速微信搜索的核心任務,如查詢理解和結果排名。我們用 GPU + TensorRT 解決方案突破了 NLP 模型復雜度的傳統限制, BERT / Transformer 可以完全集成到我們的解決方案中。此外,我們還使用卓越的性能優化方法,顯著減少了分配的計算資源( 70% ) – Huili/Raccoonliu/Dickzhu,微信搜索

NVIDIA TensorRT 免費提供給 NVIDIA 開發者計劃的成員。要了解更多信息,請訪問 TensorRT 產品頁。
要進一步了解 TensorRT 8 及其功能:
- 使用 TensorRT 的 BERT 實時自然語言理解
- 利用 TensorRT 量化感知訓練實現 INT8 推理的 FP32 精度
- 用安培結構和 TensorRT 加速稀疏推理
- 利用 TensorRT 加速深度學習推理
- 從 TensorFlow 和 ONNX 導入模型
- TensorRT 快速入門指南
- 筆記本:使用 EfficientDet 和 TensorRT 優化目標檢測
- 筆記本: BERT 帶有 QAT 和稀疏性
按照這些 GTC 課程來熟悉技術:
- GTC 會話 S31876 : 用 TensorRT 8 . 0 加速深度學習推理
- GTC 會話 S31552 : 充分利用 NVIDIA 安培結構中的結構稀疏性
- GTC 會話 S31653 : 用 TensorRT 8 . 0 在 PyTorch 中進行量化感知訓練
- GTC 會話 S32224 : 用 OnnxRuntime- TensorRT 加速深度學習推理
- GTC 會話 S31732 : TensorFlow 2 與 TensorRT 會話集成的推理
- GTC 會話 S31828 : TensorRT 快速入門指南
?