
在不斷增長的模型大小、實時延遲要求以及最近的 AI 推理的推動下, 大語言模型 (LLM) 推理的計算需求正在快速增長。與此同時,隨著 AI 采用率的增長, AI 工廠 能否為盡可能多的用戶提供服務,同時保持良好的每位用戶體驗,是更大限度地提高其價值的關鍵。要在最新模型上實現高推理吞吐量和低推理延遲,需要在涵蓋芯片、網絡系統和軟件的整個技術堆棧中表現出色。
MLPerf Inference v5.0 是長期運行的基準套件中的最新版本,可測量一系列不同模型和用例的推理吞吐量。于 2019 年首次推出的 MLPerf Inference 不斷更新新的模型和場景,以確保它仍然是衡量 AI 計算平臺推理性能的有用工具。
本輪測試新增三個新的基準測試:
- Llama 3.1 405B:具有 405 億參數的密集 LLM。在服務器場景中,基準測試將第一個令牌 (TTFT) 的延遲要求設置為 6 秒,將每個輸出令牌 (TPOT) 的時間設置為 175 毫秒。
- Llama 2 70B Interactive:擁有 70 億參數的密集 LLM。此工作負載基于 MLPerf Inference v4.0 中首次引入的相同 Llama 2 70B 模型,但具有更嚴格的延遲限制,即 450 毫秒 TTFT 和 40 毫秒 TPOT (每位用戶每秒 25 個令牌)。
- 關系圖注意力網絡 (R-GAT) :圖神經網絡 (GNN) 基準測試。GNN 應用于各個領域,包括社交網絡分析、藥物研發、欺詐檢測和分子化學。
這些新基準測試加入了涵蓋各種模型和用例的眾多返回基準測試:ResNet-50、RetinaNet、3D U-Net、DLRMv2、GPT-J、Stable Diffusion XL、Llama 2 70B 和 Mixtral 8x7B。
NVIDIA 提交了數據中心類別中每個基準測試的結果,提供了全面的出色性能,包括新添加的 Llama 3.1 405B、Llama 2 70B Interactive 和 GNN 測試的新性能結果。本輪,NVIDIA 還提交了許多關于 Blackwell 架構的結果 NVIDIA GB200 NVL72 以及 NVIDIA DGX B200 比上一代產品大幅提升了速度 NVIDIA Hopper 架構 。Hopper 推出三年后,在軟件增強的推動下,繼續全面提供出色性能,從而不斷提升該 GPU 系列的性能。
在本文中,我們將詳細了解性能結果,并詳細介紹實現這些結果的全棧創新。
Blackwell 為 MLPerf 設定了新的性能標準
在 NVIDIA GTC 2024 上推出的 NVIDIA Blackwell 架構 現已全面投產,主要云服務提供商和眾多服務器制造商均可提供。Blackwell 集成了許多架構創新,包括第二代 Transformer Engine、第五代 NVLink 、FP4 和 FP6 精度等,可顯著提高訓練和推理性能。
Blackwell 平臺具有多種不同的系統外形規格,可滿足各種數據中心部署要求。NVIDIA 提交的結果使用了 GB200 NVL72 和 DGX B200,前者是一個機架級系統,配備 36 個 Grace CPU 和 72 個 Blackwell GPU,通過 NVLink 和 NVSwitch 完全連接在一起。
此外,在本輪中,Blackwell 提交的 Llama 3.1 405B、Llama 2 70B Interactive、Llama 2 70B 和 Mixtral 8x7B 使用了具有 FP4 Tensor Cores 的第二代 Transformer Engine、用于高效模型執行的 NVIDIA TensorRT-LLM 軟件 以及用于 FP4 量化的 TensorRT Model Optimizer 。這些技術的結合使得 FP4 精度的使用成為可能,在滿足基準精度要求的同時,Blackwell 的峰值吞吐量是 FP8 的兩倍。
在 Llama 3.1 405B 基準測試中,與 NVIDIA H200 Tensor Core 八-GPU 系統相比,GB200 NVL72 的單 GPU 性能提升高達 3.4 倍。
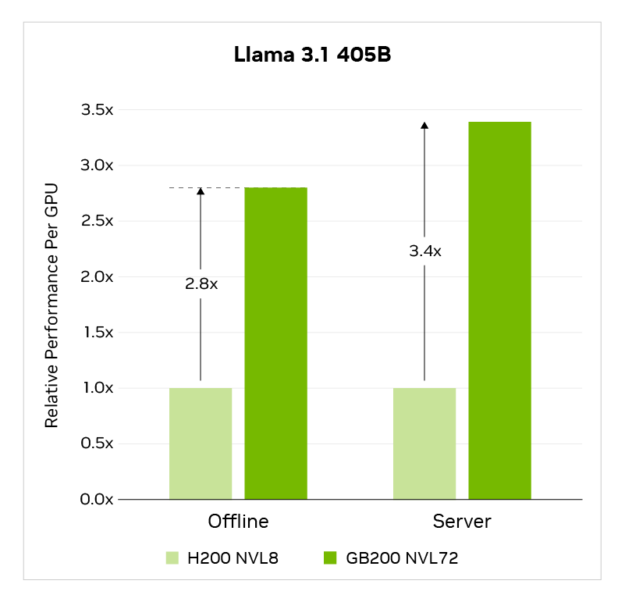
MLPerf Training v5.0 結果于 2025 年 4 月 2 日檢索自 http://www.mlcommons.org ,來自以下條目:5.0-0058、5.0-0060。每個 GPU 的性能不是 MLPerf Inference v5.0 的主要指標,而是通過報告的吞吐量除以加速器數量得出的。MLPerf 名稱和徽標均為 MLCommons Association 在美國和其他國家地區的商標。保留所有權利。未經授權嚴禁使用。詳情請參見 http://www.mlcommons.org。
在系統層面,GB200 NVL72 通過結合更高的每個 GPU 性能以及系統中 9 倍以上的 GPU,將性能提升高達 30 倍,所有 GPU 都連接在單個 NVLink 域上,使用 NVLink 和 NVLink Switch。
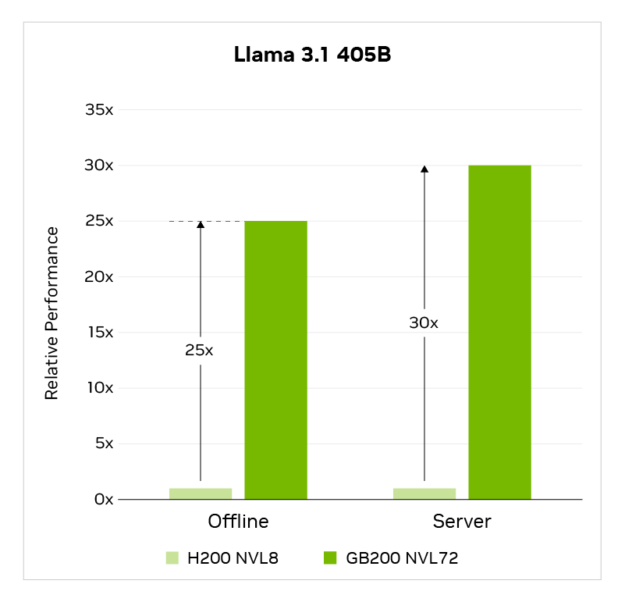
MLPerf Training v5.0 結果于 2025 年 4 月 2 日檢索自 http://www.mlcommons.org ,來自以下條目:5.0-0058、5.0-0060。MLPerf 名稱和徽標均為 MLCommons Association 在美國和其他國家地區的商標。保留所有權利。未經授權嚴禁使用。詳情請參見 http://www.mlcommons.org。
此外,NVIDIA 在 GB200 NVL72 上運行 MLPerf Inference v4.1 中的 Llama 2 70B 基準測試,達到每秒 869,203 個令牌的未經驗證的結果。
在 Llama 2 70B Interactive 基準測試中,與使用 8 個 H200 GPU 的 NVIDIA 提交相比,8 個 GPU 的 B200 系統的吞吐量提高了 3.1 倍。
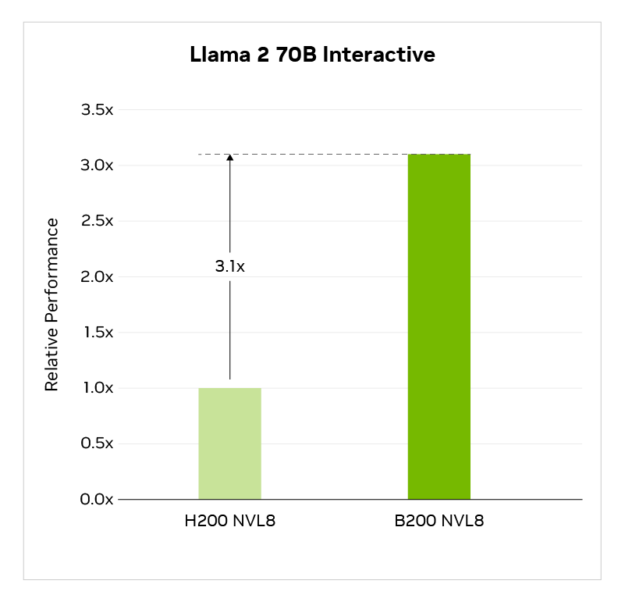
MLPerf Inference v5.0,封閉,數據中心。結果于 2025 年 4 月 2 日從 www.mlcommons.org 檢索到。以下條目的結果:5.0-0056、5.0-0060。MLPerf 名稱和徽標均為 MLCommons Association 在美國和其他國家地區的商標。保留所有權利。未經授權嚴禁使用。詳情請參見 http://www.mlcommons.org 。
在 Llama 2 70B、Mixtral 8x7B 和 Stable Diffusion XL 上,B200 也實現了顯著的加速。
| 基準測試 | 8x Blackwell GPUServer | Offline | 8 塊 H200 GPU 服務器 | 離線 | Blackwell 加速 服務器 | 離線 |
| Llama 2 70B Token/sec | 98443 | 98858 | 33072 | 34988 | 3 倍 | 2.8 倍 |
| Mixtral 8x7B Tokens/sec | 126845 | 128148 | 61802 | 62630 | 2.1 倍 | 2.1 倍 |
| Stable Diffusion XLSamples/sec | Queries/sec | 28.44 | 30.38 | 18.30 | 18.99% | 1.6 倍 | 1.6 倍 |
MLPerf Inference v5.0,封閉,數據中心。結果于 2025 年 4 月 2 日從 www.mlcommons.org 檢索到。以下條目的結果:5.0-0056、5.0-0060。MLPerf 名稱和徽標均為 MLCommons Association 在美國和其他國家地區的商標。保留所有權利。未經授權嚴禁使用。詳情請參見 http://www.mlcommons.org 。
Hopper 繼續提供出色的 GPU 性能
Hopper 平臺于 2022 年 3 月首次推出,繼續在 MLPerf Inference v5.0 中的每個基準測試中提供出色的推理性能,包括新添加的 Llama 3.1 405B 和 Llama 2 70B Interactive 基準測試。
隨著云服務提供商和企業尋求更大限度地延長其加速基礎設施投資的使用壽命,平臺支持新 AI 模型和用例的能力至關重要。同時,AI 工廠的推理吞吐量直接取決于其推理吞吐量–通過使用新軟件在同一基礎設施上提高給定模型的吞吐量,token 生成成本可以降低,AI 收入生成潛力可以增加。
在 Llama 2 70B 基準測試中,軟件優化驅動的 NVIDIA H100 Tensor Core GPU 吞吐量在去年增加了 1.5 倍。這些優化包括 GEMM 和注意力核函數優化、高級核函數融合、 分塊預填充 等。此外, TensorRT-LLM 中的 pipeline 并行性改進 發揮了重要作用,有助于提高 Llama 2 在 H100 上的吞吐量。
Hopper 架構具有 NVLink Switch,允許每個 GPU 以全帶寬與任何其他 GPU 通信,而不管通信的 GPU 數量如何。這為開發者提供了選擇最佳并行映射的靈活性,以最大限度地提高給定延遲限制的吞吐量。NVLink Switch 通信可以在細粒度級別與 GEMM 計算進一步重疊,有助于提高 H200 NVL8 上的 Llama 3.1 405B 吞吐量。
這些持續優化的結果是,Hopper 在 MLPerf 最新且最具挑戰性的工作負載 Llama 3.1 405B 和 Llama 2 70B Interactive 上實現了出色性能。
NVIDIA 平臺也是提交 Mixtral 8x7B 基準測試結果的唯一平臺,該基準測試使用 mixture-of-experts (MoE) 模型架構,Hopper 性能比上一輪測試有所提高。此外,GPT-J 基準測試的性能再次提升,自首次引入基準測試以來,Hopper 的性能累計提升至離線場景的 2.9 倍,服務器場景的 3.8 倍。
總結
NVIDIA Hopper 平臺在最新一輪的 MLPerf 訓練和 MLPerf Inference 測試中均表現出色。Hopper 三年后仍然是行業領先的平臺,通過持續的全棧優化,它繼續提高現有 AI 用例的性能,并支持新的 AI 用例,從而提供更長的使用壽命。
NVIDIA Blackwell 為性能和能效設定了新標準,這是 AI 工廠收入和盈利能力的關鍵驅動因素。通過在現有工作負載上實現巨大的性能提升,并在要求更高的場景 (包括最新的推理模型) 中實現更大的收益,Blackwell 正在推動下一波 AI 創新浪潮。
此外,NVIDIA 正在使用在 Hopper 和 Blackwell GPU 上運行的 Dynamo 擴展 AI 推理。
致謝
許多 NVIDIA 員工的努力取得了這些出色的成果。我們要感謝 Kefeng Duan、Shengliang Xu、Yilin Zhang、Robert Overman、Shobhit Verma、Viraat Chandra、Zihao Kong、Tin-Yin Lai 和 Alice Cheng 等人的不懈努力。
使用 NVIDIA MLPerf v4.1 代碼和 TensorRT-LLM 0.18.0.dev 獲得的結果。未經驗證的 MLPerf v4.1 推理已離線關閉 Llama 2 70B。結果未經 MLCommons Association 驗證。未經驗證的結果未通過 MLPerf 審核,并且可能使用與 MLPerf 規范不一致的測量方法和/或工作負載實現來驗證結果。MLPerf 名稱和徽標均為 MLCommons Association 在美國和其他國家地區的注冊商標和未注冊商標。保留所有權利。嚴禁未經授權使用。詳情請參見 www.mlcommons.org 。
?






