
NVIDIA 在 NVIDIA GTC 2025 上宣布了創下世界紀錄的 DeepSeek-R1 推理性能 。 搭載 8 個 NVIDIA Blackwell GPU 的單個 NVIDIA DGX 系統 ,在具有 671 億個參數的先進大型 DeepSeek-R1 模型上,每個用戶每秒可實現超過 250 個 token,或每秒超過 30,000 個 token 的最大吞吐量。得益于 NVIDIA 開放生態系統的推理開發者工具的改進 (現已針對 NVIDIA Blackwell 架構進行優化) ,這些性能頻譜兩端的快速性能提升得以實現。
隨著 NVIDIA 平臺不斷突破最新 NVIDIA Blackwell Ultra GPU 和 NVIDIA Blackwell GPU 的推理極限,這些性能記錄將會得到改善。
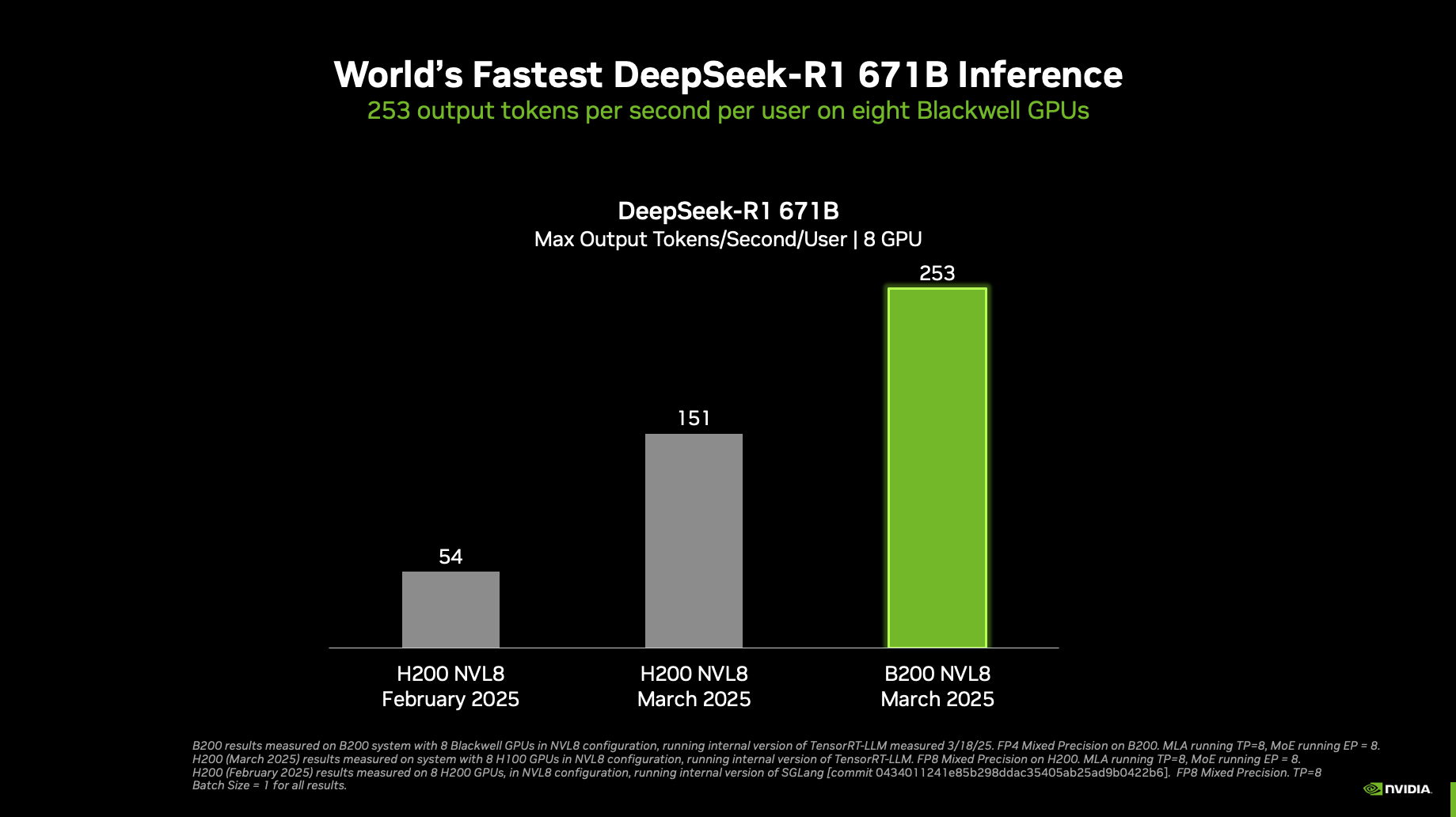
單個 DGX B200 8-GPU 系統和單個 DGX H200 8 GPU 系統 | 在內部版本的 TensorRT-LLM 上運行 B200 和 H200 的 3 月和 2 月數字 | 3 月,輸入 1,024 個令牌,輸出 2,048 個令牌,2 月和 1 月,輸入 1,024 個令牌,輸出 1,024 個令牌 | 并發 1 | B200 FP4,H100 和 H200 FP8 精度。
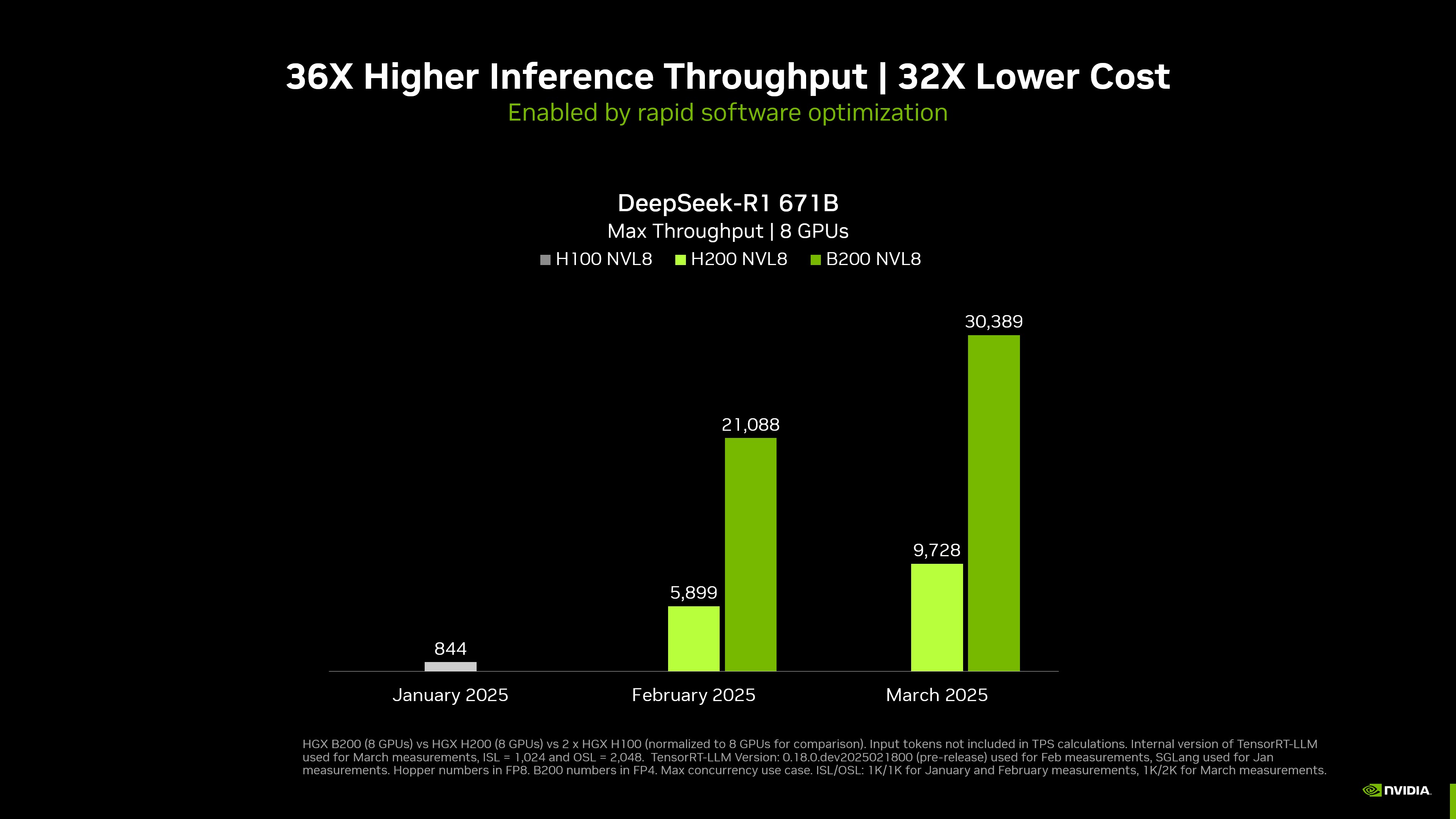
標準化為 8-GPU 系統的最大吞吐量 | 單個 DGX B200 8 GPU 系統、單個 DGX H200 8 GPU 系統、兩個 DGX H100 8 GPU 系統標準化 | TensorRT-LLM 內部版本 | 3 月,輸入 1,024 個令牌,輸出 2,048 個令牌,2 月和 1 月,輸入 1,024 個令牌,輸出 1,024 個令牌 | 并發性 MAX | B200 FP4,H200/H100 FP8 精度。
NVIDIA 推理生態系統是世界上最大的。它使開發者能夠根據其部署需求構建量身定制的解決方案,無論他們的目標是最大限度地提升用戶體驗還是最大限度地提高效率。它包括直接來自 NVIDIA 的開源工具,以及利用最新的 NVIDIA 架構和軟件進展的社區。
Blackwell 的這些進步包括:使用第五代 Tensor Core (采用 FP4 加速) 時,AI 計算性能提升高達 5 倍;使用第五代 NVLink 和 NVLink Switch 時, NVIDIA NVLink 帶寬是上一代的 2 倍;以及可擴展到更大的 NVLink 域。無論是單芯片還是數據中心規模的性能提升,都是 DeepSeek-R1 等先進 LLM 高吞吐量、低延遲推理的關鍵推動因素。
加速計算需要的不僅僅是強大的硬件基礎設施。需要經過優化且快速發展的軟件堆棧,以便為當今要求嚴苛的工作負載提供最佳工作負載性能,并隨時為新出現的更具挑戰性的工作負載提供服務。NVIDIA 不斷優化技術堆棧的每一層(芯片、系統、庫、算法等),以提供出色的工作負載性能。
本文概述了為充分利用 NVIDIA Blackwell 平臺而對 NVIDIA 推理生態系統進行的多項更新,包括 NVIDIA TensorRT-LLM , NVIDIA TensorRT , TensorRT 模型優化器 , CUTLASS , NVIDIA cuDNN 熱門 AI 框架,包括 PyTorch , JAX ,以及 TensorFlow 。此外,我們還分享了在 NVIDIA DGX B200 系統上測量的新性能和準確性數據,該系統配備 8 個 Blackwell GPU,并使用兩個 NVLink Switch 芯片進行連接。
TensorRT 生態系統:針對 NVIDIA Blackwell 優化的完整推理堆棧
NVIDIA TensorRT 生態系統旨在支持開發者在 NVIDIA GPU 上優化其生產推理部署。它包含多個庫,支持 AI 模型的準備、加速和部署,所有這些模型現在都可以在最新的 NVIDIA Blackwell 架構上運行。 這表明,與上一代 NVIDIA Hopper 架構相比,性能持續大幅提升。
TensorRT Model Optimizer 是優化推理速度的第一步。它提供了最先進的模型優化技術,包括量化、蒸餾、剪枝、稀疏和猜測解碼,可提高模型在推理過程中的效率。最新的 TensorRT Model Optimizer 0.25 版本支持用于 后訓練量化 (PTQ) 和 量化感知訓練 (QAT) 的 Blackwell FP4,優化了整體推理計算吞吐量,并減少了下游推理框架的內存使用量。
模型經過優化后,高性能推理框架對于高效運行模型至關重要。TensorRT-LLM 為開發者提供了一個工具箱,可實現實時、經濟、高效的 LLM 推理。最新的 TensorRT-LLM 0.17 版本增加了對 Blackwell 的支持,并為 Blackwell 指令、內存層次結構和 FP4 提供了量身定制的優化。
TensorRT-LLM 采用 PyTorch 架構,通過強大而靈活的內核為常見的 LLM 推理操作和高級運行時功能 (例如 in-flight batching、KV cache 內存管理和 speculative decoding) 提供峰值性能。
熱門深度學習框架 PyTorch、JAX 和 TensorFlow 也已更新,支持在 Blackwell 上進行推理和訓練。其他 LLM 服務框架 (如 vLLM 和 Ollama) 現在可以在 Blackwell GPU 上使用。在不久的將來,我們還將為其他應用提供支持。
Blackwell with TensorRT 推理性能
與 Hopper 架構相比,Blackwell 架構與 TensorRT 軟件相結合,可實現顯著的推理性能提升。這種性能提升得益于顯著提高的計算性能、內存帶寬和經過優化的軟件堆棧,從而實現出色的交付性能。
在熱門社區模型 (包括 DeepSeek-R1、Llama 3.1 405B 和 Llama 3.3 70B) 上,運行 TensorRT 軟件并使用 FP4 精度的 DGX B200 平臺的推理吞吐量已超過 DGX H200 平臺的 3 倍。
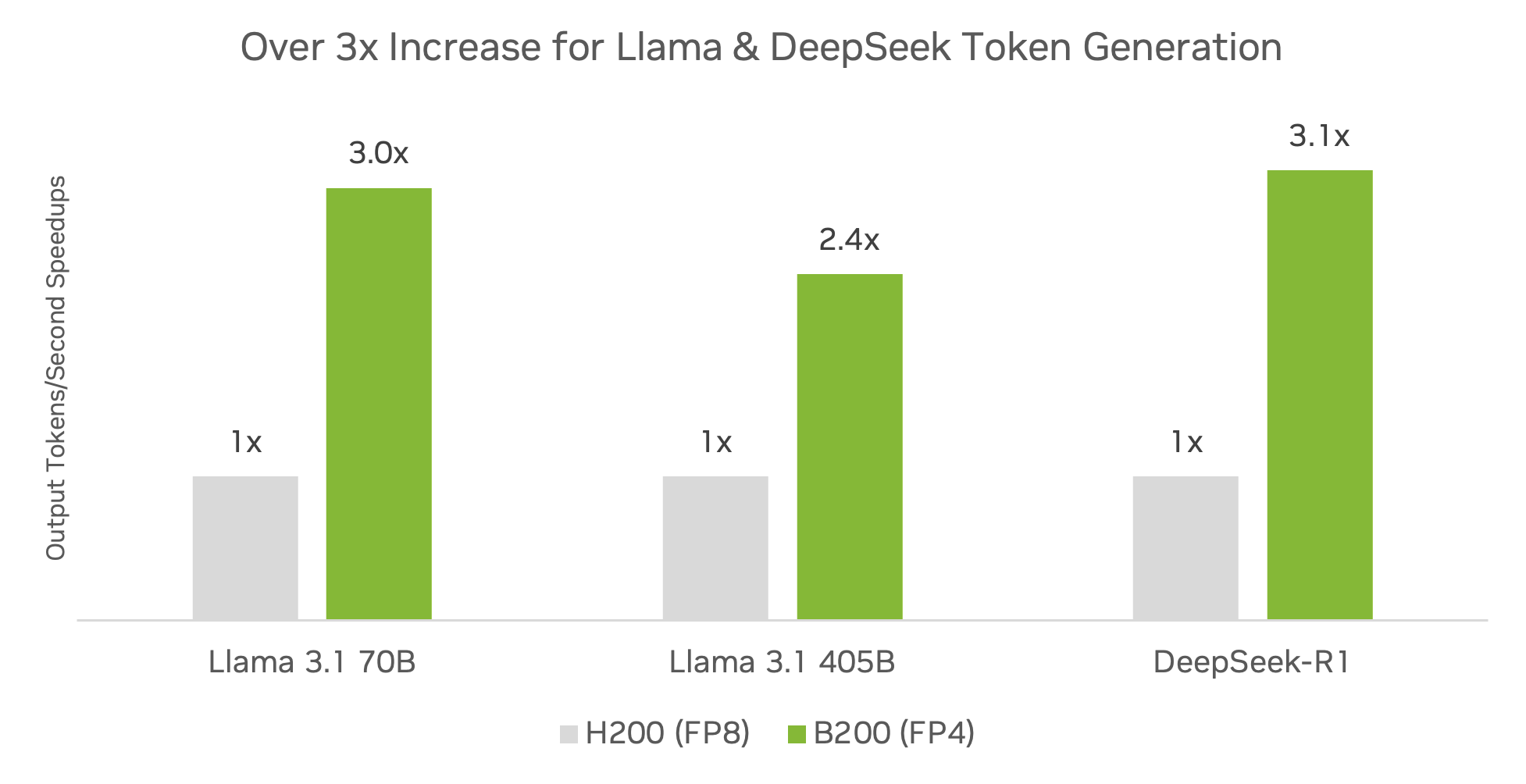
初步規格。可能會發生變化。TensorRT Model Optimizer v0.23.0。TensorRT-LLM v0.17.0。最大批量大小 2048,使用 TensorRT-LLM Inflight Batching 的實際批量大小動態。H200 FP16/BF16 GEMM + FP8 KV cache。B200 FP4 GEMM + FP8 KV cache。吞吐量提升。Llama 3.3 70B:ISL 2048,OSL 128。Llama 3.1 405B:ISL 2048,OSL 128。DeepSeek-R1:ISL 1024,OSL 1024。
在量化模型以利用低精度計算的優勢時,確保盡可能減少精度損失對于生產部署至關重要。對于 DeepSeek-R1,與 FP8 基準相比,TensorRT Model Optimizer FP4 訓練后量化(PTQ)可將各種數據集的準確性損失降至最低,如表 1 所示。
| MMLU | GSM8K | AIME 2024 | GPQA 鉆石級 | 數學 – 500 | |
| DeepSeek R1-FP8 | 90.8% | 96.3% | 80.0% | 69.7% | 95.4% |
| DeepSeek R1-FP4 | 90.7% | 96.1% | 80.0% | 69.2% | 94.2% |
表 2 提供了在熱門的 Llama 3.1 405B 和 Llama 3.3 70B 上使用基準 BF16 精度和 FP4 量化得出的準確性結果。
| MMLU 基準 | GSM8K 基準 | |
| Llama 3.1 405B-BF16 | 86.5% | 96.3% |
| Llama 3.1 405B-FP4 | 86.1% | 96.1% |
| Llama 3.3 70B-BF16 | 82.5% | 95.3% |
| Llama 3.3 70B-FP4 | 80.5% | 92.6% |
在低精度 (例如 FP4) 中部署時,可以應用 QAT 來恢復準確性,前提是可以使用微調數據集。為說明 QAT 的價值,使用 TensorRT Model Optimizer 通過 QAT 量化到 FP4 的 NVIDIA Nemotron 4 15B 和 Nemotron 4 340B 模型與 BF16 基準相比實現了無損 FP4 量化 (表 3)。
| Nemotron 4 15B Base | Nemotron 4 340B 基礎模組 | |
| BF16 (基準) | 64.2% | 81.1% |
| 采用 PTQ 的 FP4 | 61.0% | 80.8% |
| 采用 QAT 的 FP4 | 64.5% | 81.4% |
使用 TensorRT 和 TensorRT Model Optimizer 以及 FP4 提高 Blackwell 的圖像生成效率
以前,TensorRT 和 TensorRT Model Optimizer 使用量化為 8 位數據格式 (包括 INT8 和 FP8) 的擴散模型來實現高性能圖像生成。
現在,NVIDIA Blackwell 和 FP4 精度可為 AI 圖像生成提供更出色的性能。這些優勢還延伸到希望在搭載 NVIDIA GeForce RTX 50 系列 GPU 的 AI PC 上本地生成圖像的用戶。
Black Forest Labs 的 Flux.1 模型系列 是先進的文本轉圖像模型,具有出色的提示依從性和生成復雜場景的能力。開發者現在可以從 Black Forest Lab 的 Hugging Face 集合中下載 FP4 Flux 模型 ,并直接使用 TensorRT 進行部署 。
這些量化模型由 Black Forest Labs 使用 TensorRT Model Optimizer FP4 工作流程和 recipes 生成。為說明在 Blackwell 上生成 FP4 圖像的優勢,與 FP16 相比,FP4 中的 Flux.1-dev 模型 可將吞吐量 (每秒生成的圖像數) 提升高達 3x,同時將 VRAM 占用率壓縮高達 5.2x 并保持圖像質量 (Table 4)。

只有 Flux.1-dev 中的 Transformer 主干被量化為 FP4,其他部分仍為 BF16 格式。
TensorRT DemoDiffusion 中的 low-VRAM 模式根據需要加載 FLUX.1-dev 中使用的 T5、CLIP、VAE 和 FLUX Transformer,并在完成后將其卸載。這使得 FLUX 的峰值內存使用量保持在這四個單獨模型的最大大小范圍內,但由于在推理期間必須加載和卸載每個模型,因此延遲會增加。
| 顯存占用率 (GB) | VRAM 使用壓縮 | |
| FP16 (基準) | 51.4 | 1x |
| FP16 低顯存 | 23.3 | 2.2 倍 |
| FP8 | 26.3 | 1.9 倍 |
| FP8 低顯存 | 19.9 | 2.6 倍 |
| FP4 | 19.5 | 2.6 倍 |
| FP4 低顯存 | 9.9 | 5.2 倍 |
圖 5 展示了使用 FP4 量化的 Flux 模型生成的圖像,突出顯示了在給定提示下,圖像質量和內容如何與 BF16 基準保持一致。此外,表 5 使用 1,000 張圖像對 FP4 圖像質量、相關性和吸引力進行了定量評估。
頂部圖像的輸入提示:“兩顆巨大的恒星在廣的空間中起舞,它們的強大引力將它們拉近了距離。當一顆恒星縮成黑洞時,它會釋放出一束麗的能量,在宇宙背景下營造出耀眼的閃光效果。旋轉的氣體和塵埃云圍繞著這個奇觀,暗示著其中包含的不可思議的力量。”
底部圖像的輸入提示:“圖像的中心位于純色背景上,有一個逼真的球體,上面有動物柔軟、蓬松的皮毛。皮毛在柔和逼真的運動中生輝,皮毛投射的陰影營造出引人入勝的視覺效果。渲染器具有高質量的 Octane 外觀。”

| 圖像獎勵 | CLIP-IQA | CLIPScore 評分 | |
| BF16 戰斗機 | 1.118 | 0.927 | 30.15 |
| FP4 PTQ | 1.096 | 0.923 | 29.86 |
| FP4 QAT | 1.119 | 0.928 | 29.92 |
Flux.1-dev 模型,30 步長,1K 圖像。TensorRT Model Optimizer v0.23.0 FP4 recipe。于 2025 年 1 月 24 日在 NVIDIA H100 GPU 上進行模擬。該模擬在數學上與 RTX 5090 上的 TensorRT 內核級別相同。RTX 5090 上的實際得分可能會略有不同。
TensorRT 10.8 更新現在可以在更高端的 GeForce RTX 50 系列 GPU 上運行具有峰值 FP4 性能的 Flux.1-Dev 和 Flux.1-Schnell 模型 。在 –low-vram 模式下,您甚至可以在有限的內存配置 (例如 GeForce RTX 5070) 上運行這些模型。此外, TensorRT 還支持運行由 Black Forest Labs 提供的 Depth 和 Canny Flux ControlNets 。您現在可以使用 TensorRT demo/Diffusion 進行試用 。
使用 cuDNN 的 Blackwell 優化深度學習基元
自 2014 年推出以來,NVIDIA cuDNN 一直是加速 GPU 深度學習工作負載的基礎。通過提供核心深度學習基元的高度優化實現,它使 PyTorch、TensorFlow 和 JAX 等框架能夠提供最先進的性能。通過與這些框架無縫集成,并在不同的 GPU 架構中優化性能,cuDNN 已成為為從訓練到推理的端到端深度學習工作負載提供支持的性能引擎。
隨著 cuDNN 9.7 的發布,我們將在數據中心和 GeForce 產品線中擴展對 NVIDIA Blackwell 架構的支持。在將 cuDNN 運算遷移到最新的 Blackwell Tensor Cores 時,開發者有望獲得顯著的性能提升。該庫提供經過優化的通用矩陣乘法 (GEMM) APIs,可利用 Blackwell 的高級功能實現塊擴展 FP8 和 FP4 運算,從而抽象出低級優化的復雜性,以便開發者專注于創新。
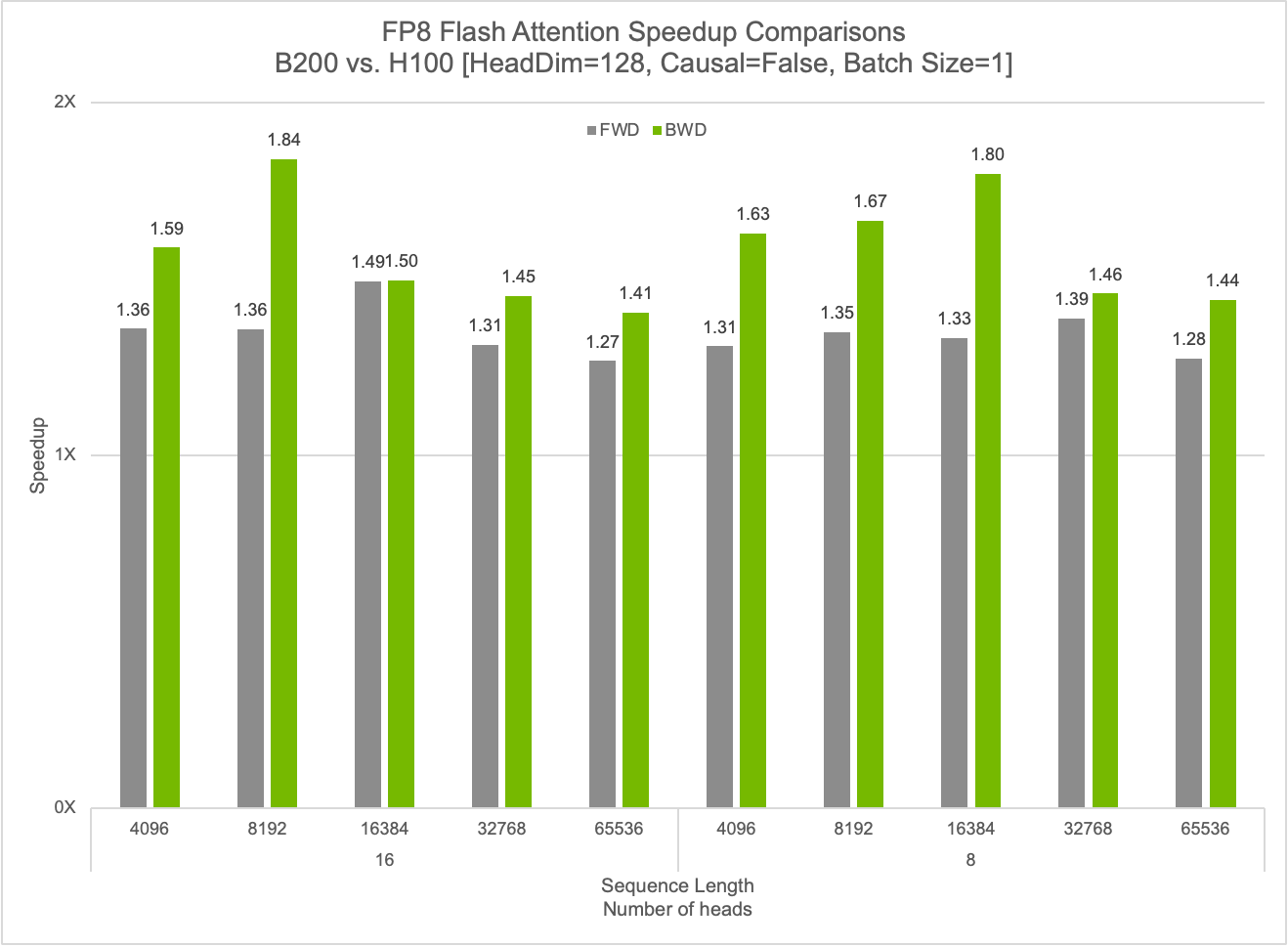
cuDNN 可顯著提升 FP8 閃存注意力運算的性能,利用 FP8 內核實現高達 50% 的前向傳播加速和 84% 的反向傳播加速。該庫還通過 Blackwell 架構上的高級融合功能提供高度優化的 GEMM 運算。展望未來,cuDNN 將繼續擴大其融合支持,以進一步提升深度學習工作負載的性能。
使用 CUTLASS 制作高性能 Blackwell 內核
自 2017 年首次推出以來, CUTLASS 一直在幫助研究人員和開發者在 NVIDIA GPU 上實現高性能 CUDA 核函數。通過為開發者提供全面的工具來設計針對 NVIDIA Tensor Cores 的自定義操作 (例如 GEMMs 和 Convolutions) ,它對于硬件感知算法的開發至關重要,為 FlashAttention 等突破性成果提供了支持,并使自己成為 GPU 加速計算的基石。
隨著 CUTLASS 3.8 的發布,我們將擴展對 NVIDIA Blackwell 架構的支持,使開發者能夠利用支持所有新數據類型的新一代 Tensor Core。這包括新的窄精度 MX 格式和 NVIDIA 自己的 FP4,使開發者能夠利用加速計算方面的最新創新來優化自定義算法和生產工作負載。圖 7 顯示,對于 Tensor Core 運算,我們能夠實現高達 98% 的相對峰值性能。
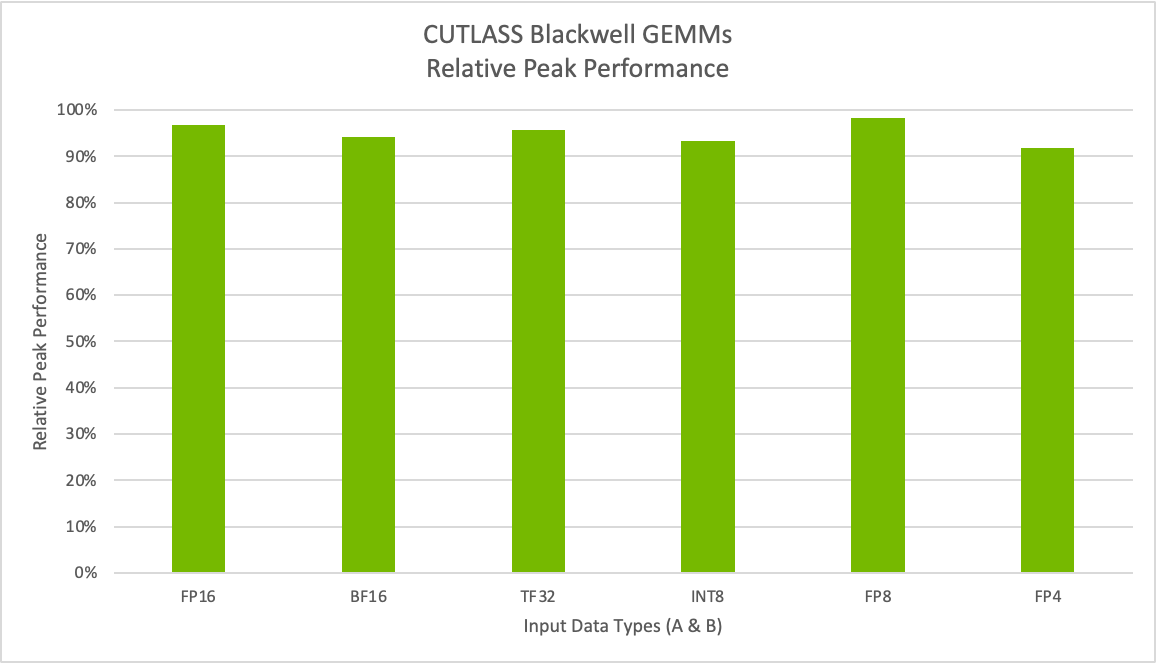
在 B200 系統上執行了基準測試。M=K=16384,N=17290。
CUTLASS 為 Blackwell 帶來了分組 GEMM 和混合輸入 GEMM 運算等熱門功能。分組 GEMM 提供了一種更高效的并行執行多個專家計算的方法,有助于加速 MoE 模型。混合輸入 GEMM 可為量化內核提供支持,在模型權重主導 GPU 顯存消耗的情況下,量化內核可以降低 LLM 的 GPU 顯存需求。
Blackwell 支持 OpenAI Triton
OpenAI Triton 編譯器現在還支持 Blackwell,使開發者和研究人員能夠通過基于 Python 的編譯器利用最新的 Blackwell 架構功能。OpenAI Triton 現在可以利用 Blackwell 架構中的最新架構創新,并在多個關鍵用例中實現近乎優化的性能。如需了解詳情,請參閱 基于 NVIDIA Blackwell 的 OpenAI Triton 提升 AI 性能和可編程性 由 NVIDIA 和 OpenAI 共同撰寫。
總結
NVIDIA Blackwell 架構融合了許多有助于加速生成式 AI 推理的突破性功能,包括采用 FP4 Tensor Cores 的第二代 Transformer Engine 和 采用 NVLink Switch 的第五代 NVLink 。NVIDIA 在 NVIDIA GTC 2025 上宣布了創下世界紀錄的 DeepSeek-R1 推理性能。搭載 8 個 NVIDIA Blackwell GPUs 的單個 NVIDIA DGX 系統,在具有 671 億個參數的先進大型 DeepSeek-R1 模型上,每個用戶每秒可實現超過 250 個 tokens,或每秒超過 30,000 個 tokens 的最大吞吐量。
豐富的庫套件現已針對 NVIDIA Blackwell 進行優化,使開發者能夠顯著提高當今 AI 模型和未來不斷變化的環境的推理性能。詳細了解 NVIDIA AI 推理平臺,并隨時了解最新的 AI 推理性能更新。
致謝
如果沒有 Matthew Nicely、Nick Comly、Gunjan Mehta、Rajeev Rao、Dave Michael、Yiheng Zhang、Brian Nguyen、Asfiya Baig、Akhil Goel、Paulius Micikevicius、June Yang、Alex Settle、Kai Xu、Zhiyu Cheng 和 Chenjie Luo 等許多人的杰出貢獻,這項工作就不可能實現。
?
?






