GPU – accelerated computing 的業務應用程序將在未來幾年大幅擴展。增長最快的趨勢之一是使用生成人工智能來創建類似人類的文本和所有類型的圖像。
推動市場對生成人工智能興趣激增的是 transformer models 等技術,這些技術將人工智能帶入日常應用,從對話文本到蛋白質結構生成。可視化和 3D 計算也迅速引起人們的興趣,特別是在工業模擬和協作領域。
隨著 Apache Spark 等核心應用程序的加速, GPU 有望成為數據分析、商業智能和機器學習效率和成本節約的重要驅動力。最后,在智能空間和工業自動化擴張的推動下,邊緣的人工智能推理部署是企業增長最快的領域之一。
旨在解決這些日益復雜的計算需求的新一代計算技術正在出現。這包括 NVIDIA 的新 GPU 體系結構,以及 AMD 、 Intel 和 NVIDIA 新 CPU 。
全球系統制造商已經創建了新的系統,將這些系統整合到強大的計算平臺中,旨在解決各種加速的計算工作負載。這些系統 NVIDIA-Certified 可確保企業解決方案的最佳性能、可靠性和規模,目前可供購買。訪問 Qualified System Catalog 了解更多信息。本文介紹了其中一些新技術,并討論了企業利用這些技術的最佳方式。
加速生成人工智能和大型語言模型
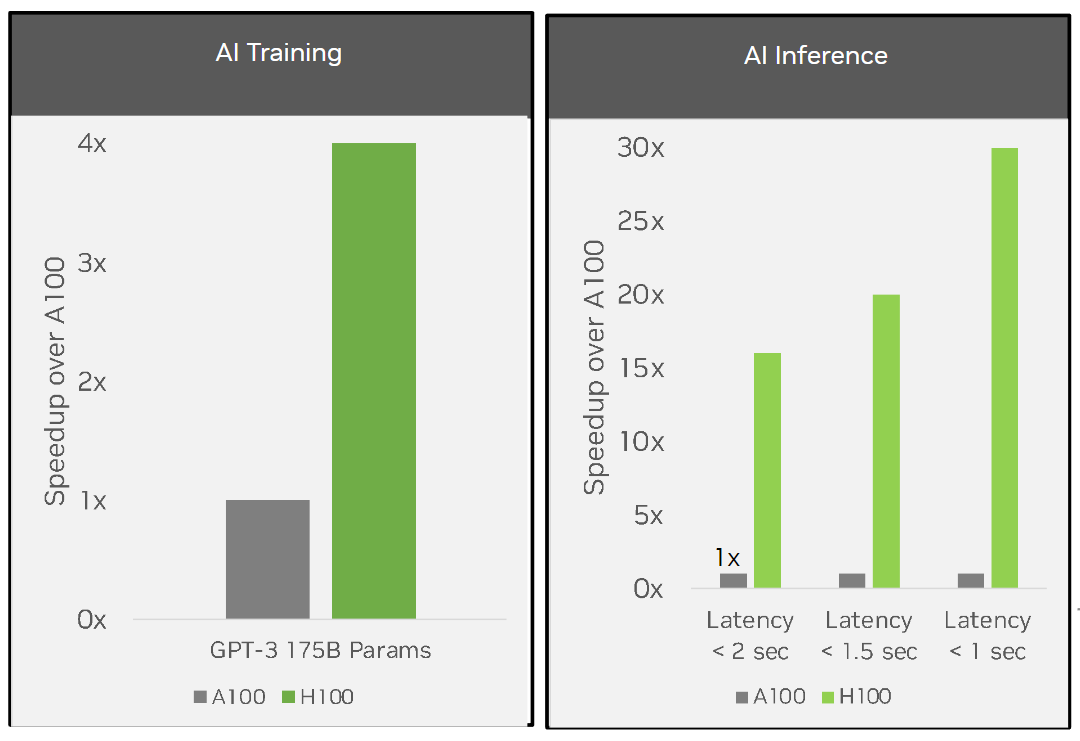
針對訓練大型語言模型和推理進行了優化,與上一代 NVIDIA A100 Tensor Core GPUs 相比, NVIDIA HGX H100 服務器的人工智能訓練速度提高了 4 倍,人工智能推理速度提高了 30 倍。*最新的服務器,包括新一代 CPU ,在人工智能和 HPC 方面具有最高的性能,如下所述。
- 4 路 H100 GPU ,帶 268 個 TFLOP FP64
- 8 路 H100 GPU ,帶 31664 個 TFLOP FP8
- 3.6 在網絡計算中使用 NVIDIA SHARP 的 TFLOP FP16
- 第四代 NVLink ,速度快 3 倍,全部減少通信
- PCIe Gen5 端到端,用于從 CPU 到 GPU 到網絡的更高數據傳輸速率
- 每個 GPU 3.35 TB / s 內存帶寬
*配置: HGX A100 集群: HDR IB 網絡。 HGX H100 集群: NDR IB 網絡, GPT-3 16 B 512 (批次 256 ), GPT–3 16 K (批次 512 )。所有性能數據均來自 NVIDIA H100 GPU 體系結構白皮書。
在 NVIDIA GTC 2023 主題演講中, NVIDIA 宣布推出 NVIDIA H100 NVL ,這是一款用于 NVLink 的 H100 PCIe 產品,具有 94 GB HBM3 內存。它非常適合大型語言型號,為 GPT-3 提供了 NVIDIA HGX A100 的 12 倍性能。
NVIDIA H100 PCIe GPU 配置包括 NVIDIA AI Enterprise 軟件套件訂閱,以簡化人工智能生產工作負載的開發和部署。它僅需 350 瓦的熱設計功率( TDP )即可提供 NVIDIA H100 GPU 的所有功能。此配置可以選擇使用 NVLink 橋接器,以 600 GB / s 的帶寬連接最多兩個 GPU ,幾乎是 PCIe Gen5 的 5 倍。
NVIDIA H100 PCIe GPU 非常適合安裝在標準機架中的主流加速服務器,為一次從一個擴展到四個 GPU s 的應用程序(包括 AI 推理和 HPC 應用程序)提供出色的性能。
NVIDIA 合作伙伴目前正在運送帶有 H100 PCIe 的 NVIDIA 認證服務器。訪問 Qualified System Catalog 了解更多信息。同時擁有 NVIDIA H100 PCIe 和 NVIDIA HGX H100 的其他合作伙伴的系統預計將于今年晚些時候獲得 NVIDIA 認證。總之,這些新平臺使企業能夠以更好的性能和更大的規模運行最新的人工智能和 HPC 應用程序。
AI 視頻和推理的節能性能
NVIDIA Ada Lovelace L4 Tensor Core GPU 為企業、云中和邊緣的視頻、人工智能、虛擬工作站和圖形應用程序提供通用加速和能效。憑借 NVIDIA 人工智能平臺和全棧方法, L4 GPU 針對廣泛的人工智能應用程序進行了大規模視頻和推理優化,以提供最佳的個性化體驗。要了解更多信息,請參閱 Supercharging AI Video and AI Inference Performance with NVIDIA L4 GPUs 。
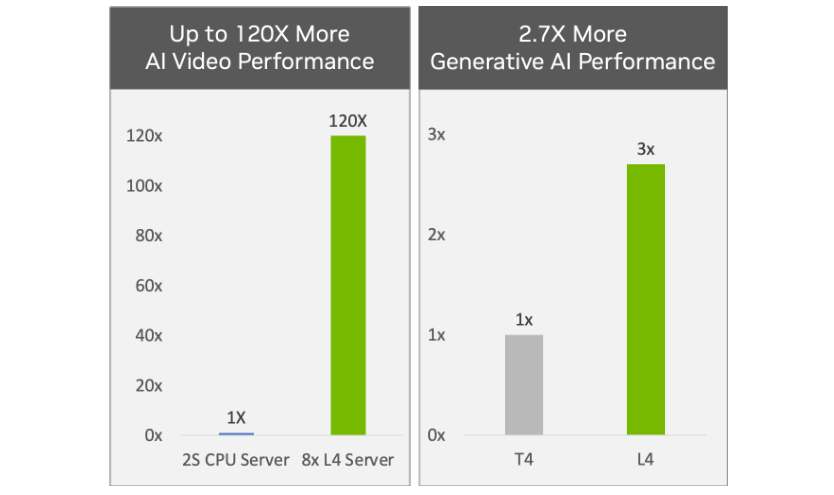
作為主流最高效的 NVIDIA 加速器,配備 L4 GPU 的服務器能夠實現比 CPU 解決方案高出 120 倍的人工智能視頻性能,同時提供 2.7 倍的生成性人工智能性能。與上一代相比,它們提供的圖形性能提高了 4 倍以上。 NVIDIA L4 GPU 功能齊全,具有節能、單插槽、低外形,非常適合邊緣、云和企業部署。
NVIDIA L4 GPU 邊緣用例得益于其硬件解碼器和編碼器的視頻加速,以及 Tensor 內核的 AI 加速。這些在智能城市的邊緣視頻分析應用、工廠質量保證和智能空間的零售營銷中都很有價值。 L4 GPU 專為滿足 HPC 邊緣傳感器處理應用中的人工智能需求而設計。它的圖形和視頻性能為邊緣儀器的科學應用提供了強大的可視化功能。
NVIDIA L4 GPU 在 NVIDIA 認證系統中可從 NVIDIA 合作伙伴處獲得,這些合作伙伴包括 Advantech 、 ASUS 、 Atos 、 Cisco 、 Dell Technologies 、 Fujitsu 、 GIGABYTE 、 Hewlett-Packard Enterprise 、 Lenovo 、 QCT 和 Supermicro ,有 100 多種獨特的服務器型號。
下一代 CPU s
CPU 技術的進步補充了新的 NVIDIA GPU 。最新一代 CPU 包括第四代 Intel Xeon 可擴展處理器,也稱為 Sapphire RAPIDS ,以及第四代 AMD EPYC 處理器,也稱稱為 Genoa 。這些最新的架構具有使企業能夠以更好的性能和更大的規模運行最新的人工智能應用程序的能力。這包括通過系統總線的高數據速度傳輸和來自主存儲器的更高數據帶寬。
NVIDIA Grace Hopper Superchip 基于 Arm 架構,具有出色的性能和能源效率。 Grace Hopper 超級芯片專為大規模人工智能和高性能計算而建,具有 NVLink C2C 功能,可為加速人工智能提供 CPU 加 GPU 的相干內存模型。
NVIDIA 認證的加速計算系統
隨著每一代新技術都帶來了更多的復雜性,對預先驗證的解決方案以簡化收購的需求比以往任何時候都更大。 NVIDIA 認證系統計劃是專門為滿足這一需求而創建的。
NVIDIA 認證系統將 NVIDIA GPU 和 NVIDIA 高速、安全的網絡連接到來自領先的 NVIDIA 合作伙伴的系統,其配置經過驗證,可用于各種工作負載的最佳性能、可靠性和規模。
這些測試基于真實世界的數據,代表了最新的 GPU 加速應用程序,包括 PyTorch 和 TensorFlow 的深度學習訓練、 HPC 、 Apache Spark 的數據分析以及 NVIDIA Omniverse 的 3D 計算。
該認證完全建立在一個基于容器的測試套件上,使用 Kubernetes 進行編排,確保任何經過認證的系統都可以無縫集成到現代云原生管理框架中。
了解資格認證和 NVIDIA 認證之間的區別很重要。 一個合格的系統經過了熱、機械、電源和信號完整性測試,以確保特定的 NVIDIA GPU 在該服務器型號中完全可用。 被驗證過的系統已經通過了一系列測試,以驗證其在各種工作負載類別以及網絡、安全和管理功能方面的性能。這些功能對于任何企業計算解決方案都至關重要。
如果您想確保系統得到支持 and 的優化設計和配置,請選擇經過認證的系統。
面向企業的下一代計算平臺
全球制造商采用新一代 GPU 和 CPU 技術的 NVIDIA 認證系統現已上市。訪問 Qualified Systems Catalog ,查看您首選的供應商提供的型號。
?