
source-zh.html
CUDA-Q v0.10 具有更多功能和更高的性能,比以往任何時候都更加不可或缺和靈活。例如,用戶現在可以在 Pasqal 的中立原子 QPU 上運行作業,總計四個不同量子比特模式的 八個 QPU 后端 。CUDA-Q v0.10 現在還支持先進的 NVIDIA Blackwell GPU 。
通過對 NVIDIA GB200 NVL72 的 CUDA-Q 支持實現性能和規模
憑借 v0.10 對 NVIDIA GB200 NVL72 及其第五代多節點 NVLink 功能的支持,CUDA-Q 性能現在可以比以往得到進一步提升。基于多個標準化 Quantum Economic Development Consortium (QED-C) 基準應用的性能數據證明了這一點。這是 NVIDIA 與 QED-C 之間更廣泛合作的一部分,旨在改進用于評估量子計算機的行業指標。
QED-C 標準和性能指標技術咨詢委員會創始主席 Tom Lubinski 表示:“采用透明和無偏差的指標對于量子基準測試工作至關重要,我們很高興與 NVIDIA 合作,實現更好的行業標準化。” QED-C 基準測試 GitHub 存儲庫現在包括 CUDA-Q ,因此用戶可以通過運行單個 Notebook 在一組準備好的標準應用程序上測試其模擬性能。
從 CUDA-Q 到 Blackwell,整個平臺的強大功能通過 QED-C 基準測試得到證明,這些基準測試用于模擬 HamLib 數據集 中的哈密頓量。HamLib 包含針對從化學到優化問題等各種問題的哈密頓量。與 192 核 2 插槽 EPYC CPU 相比,在單個 NVIDIA GB200(每個芯片兩個 Blackwell GPU)上對哈密頓模擬問題進行 33 量子位狀態向量模擬的速度快 34 倍,比上一代 NVIDIA GH200 Grace Hopper 超級芯片 快 2 倍。這意味著,在 GB200 芯片上,只需幾個小時即可運行一周的模擬,從而顯著提高工作效率。

GB200 的最大優勢在于 GPU 之間的多對多連接,使 NVIDIA GB200 NVL72 平臺能夠使用多達 72 個 GPU 加速和擴展 CUDA-Q 模擬。
基于運行多達 32 個 GPU 的基準測試,用戶可以進一步將運行 33 量子位模擬的速度提高 10 倍,將等待時間從單個 Blackwell GPU 上的幾個小時縮短到幾分鐘。第二種方案是匯集 32 個 GPU 的顯存,以執行更有影響力的大規模模擬 (高達 38 量子位) 。在這種情況下,高帶寬 NVLink 連接的優勢也十分顯著,因為 GB200 NVL72 系統的速度比之前 InfiniBand 連接的 GH200 芯片快 6 倍以上。
新宣布的 NVIDIA 加速量子研究中心 (NVAQC) 將連接 8 個 GB200 NVL72 系統,形成一臺總計 576 個 GPU 的強大超級計算機,以幫助通過 CUDA-Q 推動量子計算的突破。
來自各行各業和學術界的量子研究人員和開發者正在意識到 CUDA-Q 的強大功能,并將其用于開發一些迄今為止非常先進的量子應用。本文將探討 NVIDIA 合作伙伴如何使用 CUDA-Q 加速其化學模擬和圖像處理等應用的工作。
借助 CUDA-Q 實現無縫的端到端工作流程
NVIDIA、IonQ、Amazon 和 AstraZeneca 利用 Amazon Braket 中的 CUDA-Q 構建了端到端加速量子化學工作流,目標是對由鎳催化劑生成的 Suzuki–Miyaura Cross-Coupling 反應進行建模。AstraZeneca 對此很感興趣,因為它是藥物分子合成中的關鍵反應。
使用量子經典輔助場量子蒙特卡羅 (QC-AFQMC) 技術,可以通過結合量子硬件和 AI 超級計算機的優勢來解決這一問題。CUDA-Q 支持此類研究的能力也為 AstraZeneca 研究有關化學反應性和量子計算的更廣泛問題提供了重要的探索性跳板。
該工作流通過 Amazon Braket 和 AWS ParallelCluster 在 CUDA-Q(IonQ Forte 量子計算機)和 NVIDIA H200 Tensor Core GPUs 上運行。它分為量子部分和經典部分。首先,使用 32 量子位變分量子本征解器(VQE)準備近似的基態。這種狀態的經典表征是通過名為 Matchgate Shadows 的 斷層掃描技術 提取的。然后,對該輸出進行經典的后處理,并在 AFQMC 程序中使用,以進一步優化基態能量(圖 2)。

加速經典部分大大提升了團隊測試整個工作流程改進的速度。
這種工作流也有利于 為量子應用開發 AI ,例如 生成式量子本征求解器 (GQE) 和最近發表的工作,這些工作擴展了 GQE,以生成用于組合優化問題的電路。
CUDA-Q 是唯一同時提供社區硬件集成和此類混合算法研究所需性能的平臺。隨著 CUDA-Q 的持續擴展以及越來越多的軟件和硬件集成,CUDA-Q 在加速新應用方面的應用越來越廣泛。
通過多 GPU 加速實現擴展
CUDA-Q 正在突破混合應用開發的極限。基于 CUDA-Q 內核的編程模型可以輕松利用多個 GPU 來并行化和擴展實驗。這將加快開發周期并帶來更有影響力的結果,這也是行業和學術合作伙伴將工作負載轉移到 CUDA-Q 的原因。
Aramco 正在使用 CUDA-Q 開發用于圖像處理應用的 混合工作流 。其目標是能夠識別三維圖像中物體邊界的量子工作流,這是包括大型地理空間圖像分析在內的許多應用的重要工具。
傳統的邊緣檢測會呈指數級擴展,因為每個像素必須單獨處理。量子 Hadamard 邊緣檢測(QHED)等量子方法利用了一個事實,即 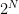

CUDA-Q MQPU 后端支持使用多個 GPU 模擬 QPU 并行處理此算法,其中一個虛擬 QPU 用于在圖像的每個維度上運行 QHED。 這極大地縮短了算法測試的開發周期。
CUDA-Q MQPU 后端還使用戶能夠開發應用程序,為未來的異構加速量子超級計算機做好準備,這些計算機將包含多個 QPU。這種前瞻性思維是 NVIDIA 與 HPE 之間正在進行的其他項目的關鍵動力。
在 NVIDIA GTC 2025 上,Hewlett Packard Enterprise(HPE)宣布了 在加速量子超級計算機中分配大型量子電路的方法的研究結果,這也是近期發表的立場論文《 如何構建量子超級計算機:從數百個量子比特擴展到數百萬個量子比特 》的中心主題 。
HPE 團隊正在使用 CUDA-Q 開發自適應電路編織 (ACK) 方法,這是一種通過在低糾纏位置進行優化切割,在小型 QPU 上動態劃分大型電路的方法。這種方法可最大限度地降低與電路切割相關的成本,允許在多個量子處理器或 AI 超級計算機上運行子電路 (圖 4)。

大規模地對 ACK 算法進行基準測試依賴于大規模的狀態向量模擬,需要這種模擬來確保子電路的結果與最初預期的電路保持一致。此驗證由 CUDA-Q MGPU 后端 提供支持,該后端匯集了 GPU 內存,因此 HPE 可以在 NERSC 的 Perlmutter 超級計算機上跨 1024 個 GPU 運行多達 40 個量子比特的模擬。模擬全部在 34 分鐘內完成,其中一些速度快達 12 分鐘,并且無法在 CPU 上運行。
CUDA-Q 還可以通過其 MQPU 后端促進在多個 GPU 模擬 QPU 中分配許多相關子電路,從而加速 ACK 測試。
快速開始使用 CUDA-Q
CUDA-Q 設計的一大特點是易于使用。它的性能、可擴展性和靈活性并非面向量子專家,而是面向任何人開放,即使是首次學習量子的人也是如此。NVIDIA CUDA-Q 學術計劃讓入門變得更加簡單。
CUDA-Q Academic 正在通過與超過 25 所頂尖大學合作,幫助培養一支技能熟練的量子勞動力隊伍。最近,我們與阿卜杜拉國王科技大學 (KAUST) 合作,為教職人員和學生舉辦了實操研討會,展示了合作的有效性。
此研討會基于免費提供的 NVIDIA Quick Start to Quantum Computing 系列 ,涵蓋了量子狀態和門、內核構建和變分量子算法等關鍵主題。該研討會的四個交互式實驗室從單量子位編程發展到更復雜的任務,包括對離散時間量子行走進行編碼,以及使用 CUDA-Q 使用 GPU 加速混合程序。

KAUST 應用數學和計算科學教授兼 KAUST 極端計算研究中心主任 David Keyes 將 NVIDIA Quick Start to Quantum Computing 系列描述為“一次令人高興的經歷,在幾個簡短的會議中展示了如何從沒有量子計算知識到在 GPU 上運行應用程序。NVIDIA CUDA-Q 很高興能使用,也是了解加速混合應用實際方面的重要資源。”
您可以在 CUDA-Q 學術 GitHub 庫中公開獲取這些教育資源以及更高級的材料,例如介紹如何 通過 divide-and-conquer 方法實現 QAOA 的 max cut。 此資料庫為任何希望開發高性能計算和量子計算技能必要的加速量子計算的人提供了寶貴的途徑。
了解詳情
NVIDIA CUDA-Q 平臺正成為開發具有出色性能、靈活性和易用性的混合應用的行業標準。量子社區成員發布的許多其他 NVIDIA GTC 2025 公告都清楚地表明了這一點,他們使用 CUDA-Q 取得了出色而多樣的成果。
您可以安裝 CUDA-Q ,開始設計自己的混合應用,并試用 CUDA-Q 文檔中的許多示例應用 。要了解 NVIDIA 致力于加速量子計算開發的所有工具,請訪問 NVIDIA Quantum 。
?





