NVIDIA cuDSS 是第一代稀疏直接求解器庫,旨在加速工程和科學計算。cuDSS 正越來越多地應用于數據中心和其他環境,并支持單 GPU、多 GPU 和多節點(MGMN)配置。
cuDSS 已成為加速多個領域 (例如結構工程、流體動力學、電磁學、電路模擬、優化和 AI 輔助工程問題) 的計算機輔助工程 (CAE) 工作流程和科學計算的關鍵工具。
本文重點介紹了 cuDSS v0.4.0 和 cuDSS v0.5.0 中提供的一些關鍵性能和可用性功能 (如表 1 中總結的內容),cuDSS v0.4.0 可顯著提升分解和求解步驟的性能,同時還引入了一些新功能,包括內存預測 API、自動混合內存選擇和可變批量支持。cuDSS v0.5.0 增加了主機執行模式,這對較小的矩陣特別有利,并且在分析階段使用混合內存模式和主機多線程實現了顯著的性能提升,而有效并行化通常是一個具有挑戰性的領域。
| cuDSS v0.4.0 版本 | cuDSS v0.5.0 版本 |
| PIP wheel 和 Conda 支持在因子具有密集部分時,對單 GPU 和多 GPU 進行分解并解決性能提升 (高達 10 倍) 內存預測 API 自動選擇正常/混合內存模式可變 (非均勻) 批量支持 (變量 N、NNZ、NRHS、LD) | 較小矩陣的主機執行模式 (部分主機計算模式) 帶有用戶定義線程后端的主機多線程 (目前僅用于重新排序) 新的透視方法 (通過擴展進行靜態透視) 提高了混合內存模式的性能和內存需求 |
功能亮點
本節重點介紹顯著的可用性增強和性能改進。
內存預測 API
對于需要在達到顯存密集型階段(數值分解)之前了解 cuDSS 所需設備和主機顯存的精確數量的用戶而言,內存預測 API 非常重要。
在設備顯存不足的情況下,無論是求解大型線性系統,還是應用程序的 cuDSS 顯存預算有限時,此功能尤其有用。在這兩種情況下,建議在分析階段之前啟用混合顯存模式。
請注意,如果混合顯存模式已啟用,但一切都適合可用設備顯存 (無論是基于用戶定義的限制還是 GPU 容量),cuDSS 將自動檢測到這一點并切換到更快的默認顯存模式。
使用 cuDSS 求解線性系統的典型調用序列如下所示:
- 分析 (重新排序和符號分解)
- 數值分解(分配并計算因子值)
- 求解
引入 memory prediction 后,用戶現在可以在分析階段結束后查詢所選模式(默認或 hybrid memory)所需的 device 和 host memory 數量,以及 hybrid memory 模式所需的最小 memory。如下示例所示,查詢是使用 CUDSS_DATA_MEMORY_ESTIMATES 對 cudssDataGet 進行的一次調用,可將輸出寫入固定大小的小型數組中。
/* * After cudssExecute(..., CUDSS_PHASE_ANALYSIS, ,,,) */int64_t memory_estimates[16] = {0};cudssDataGet(cudssHandle, solverData, CUDSS_DATA_MEMORY_ESTIMATES, &memory_estimates, sizeof(memory_estimates);/* memory_estimates[0] - permanent device memory * memory_estimates[1] - peak device memory * memory_estimates[2] - permanent host memory * memory_estimates[3] - peak host memory * memory_estimates[4] - minimum device memory for the hybrid memory mode * memory_estimates[5] - maximum host memory for the hybrid memory mode * memory_estimates[6,...,15] - reserved for future use */ |
要查看使用此功能的 完整示例代碼 ,請訪問 NVIDIA/CUDALibrarySamples GitHub 存儲庫。
不均勻批處理 API
在應用程序需要求解多個線性系統,且每個系統單獨不夠大,無法使 GPU 完全飽和的情況下,可以通過批處理來提高性能。有兩種類型的批處理:uniform 和 non-uniform。與 uniform 批量不同,non-uniform 批量不會對矩陣的維度或稀疏模式施加限制。
cuDSS v0.4.0 引入了對不均勻批量的支持。不透明的 cudssMatrix_t 對象可以表示單個矩陣,也可以表示批量矩陣,因此唯一需要更改的部分是創建和修改矩陣對象的方式。
為創建密集或稀疏矩陣的批量,v0.4.0 引入了新的 API cudssMatrixCreateBatchDn 或 cudssMatrixCreateBatchCsr、添加的類似 API cudssMatrixSetBatchValues 和 cudssMatrixSetBatchCsrPointers 以及 cudssMatrixGetBatchDn 和 cudssMatrixGetBatchCsr 可用于修改矩陣數據。cuDSS v0.5.0 修改 cudssMatrixFormat_t,現在可以使用 cudssMatrixGetFormat 查詢 tg_10,以確定 cudssMatrix_t 對象是單個矩陣還是批量對象。
創建矩陣批量后,它們可以像單個矩陣一樣以完全相同的方式傳遞給 cudssExecute 的主要調用。以下示例演示了如何使用新的批量 API 為解和右側創建批量密集矩陣,并為 As 創建批量稀疏矩陣。
/* * For the batch API, scalar arguments like nrows, ncols, etc. * must be arrays of size batchCount of the specified integer type */cudssMatrix_t b, x;cudssMatrixCreateBatchDn(&b, batchCount, ncols, nrhs, ldb, batch_b_values, CUDA_R_32I, CUDA_R_64F, CUDSS_LAYOUT_COL_MAJOR);cudssMatrixCreateBatchDn(&x, batchCount, nrows, nrhs, ldx, batch_x_values, CUDA_R_32I, CUDA_R_64F, CUDSS_LAYOUT_COL_MAJOR);cudssMatrix_t A;cudssMatrixCreateBatchDn(&A, batchCount, nrows, ncols, nnz, batch_csr_offsets, NULL, batch_csr_columns, batch_csr_values, CUDA_R_32I, CUDA_R_64F, mtype, mview, base);/* * The rest of the workflow remains the same, incl. calls to cudssExecute() with batch matrices A, b and x */ |
要查看使用此功能的 完整示例代碼 ,請訪問 NVIDIA/CUDALibrarySamples GitHub 存儲庫。
托管多線程 API
雖然 cuDSS 的大多數計算和內存密集型部分都在 GPU 上執行,但一些重要任務仍然在主機上執行。在 v0.5.0 之前,cuDSS 不支持主機上的多線程 (MT),并且主機執行始終是單線程的。新版本引入了對任意用戶定義線程運行時 ( 例如 pthreads、OpenMP 和線程池 ) 的支持,其靈活性與 cuDSS v0.3.0 中在 MGMN 模式 下引入對用戶定義通信后端的支持類似。
在主機上執行的任務中,重新排序 (分析階段的關鍵部分) 通常非常突出,因為它可能占用總執行時間 (分析加分解加解) 的很大一部分。為解決直接稀疏求解器中的常見瓶頸,cuDSS v0.5.0 在主機上引入了通用 MT 支持和多線程版本的重新排序。請注意,此功能僅適用于 CUDSS_ALG_DEFAULT 重排序算法。
與 MGMN 模式一樣,新的 MT 模式是可選的,如果不使用,不會向用戶應用引入任何新的依賴項。在應用中啟用此功能非常簡單 – 只需使用 cudssSetThreadingLayer 設置 shim 線程層庫的名稱,并 (可選) 指定允許 cuDSS 使用的最大線程數,如下例所示:
/* * Before cudssExecute(CUDSS_PHASE_ANALYSIS) * thrLibFileName - filename to the cuDSS threading layer library * If NULL then export CUDSS_THREADING_LIB = ‘filename’ */cudssSetThreadingLayer(cudssHandle, thrLibFileName); /* * (optional)Set number of threads to be used by cuDSS */int32_t nthr = ...;cudssConfigSet(cudssHandle, solverConfig, CUDSS_CONFIG_HOST_NTHREADS, &nthr, sizeof(nthr); |
要查看使用此功能的 完整示例代碼 ,請訪問 NVIDIA/CUDALibrarySamples GitHub 存儲庫。
主機執行
雖然 cuDSS 的主要目標是為稀疏直接求解器功能實現 GPU 加速,但對于微小的矩陣 (通常沒有足夠的并行度使 GPU 飽和),廣泛使用 GPU 會帶來不可忽略的開銷。有時,這甚至會主宰總運行時間。
為使 cuDSS 成為更通用的解決方案,v0.5.0 引入了主機執行模式,該模式可在主機上啟用分解和求解階段。啟用 cuDSS 后,cuDSS 將使用基于大小的啟發式分配來確定是否在主機或設備上執行部分計算 (在分解和求解階段)。
此外,啟用混合執行模式后,用戶可以為矩陣數據傳遞主機緩沖區,從而節省從主機到設備的不必要的內存傳輸。主機執行模式無法提供成熟 CPU 求解器的 cuDSS 功能,但有助于選擇性地消除不需要的內存傳輸,并提高小型矩陣的性能。
以下示例演示了如何開啟混合執行模式。
/* * Before cudssExecute(CUDSS_PHASE_ANALYSIS) */int hybrid_execute_mode = 1;cudssConfigSet(solverConfig, CUDSS_CONFIG_HYBRID_EXECUTE_MODE, &hybrid_execute_mode, sizeof(hybrid_execute_mode); |
要查看使用此功能的 完整示例代碼 ,請訪問 NVIDIA/CUDALibrarySamples GitHub repo。
cuDSS v0.4.0 和 v0.5.0 的性能提升
cuDSS v0.4.0 和 v0.5.0 為多種類型的工作負載引入了顯著的性能提升。
在 v0.4.0 中,通過檢測三角形因子的某些部分何時變得密集,并為這些部分利用更高效的密集 BLAS 內核,可加速分解和求解步驟。通過此優化實現的加速在很大程度上取決于因子的符號結構,而符號結構又會受到原始矩陣和重新排序排列的影響。
根據 SuiteSparse 矩陣集合中的大量矩陣集合,并在 NVIDIA H100 GPU 上進行分析,圖 1 展示了 v0.4.0 相較于 v0.3.0 的性能提升。
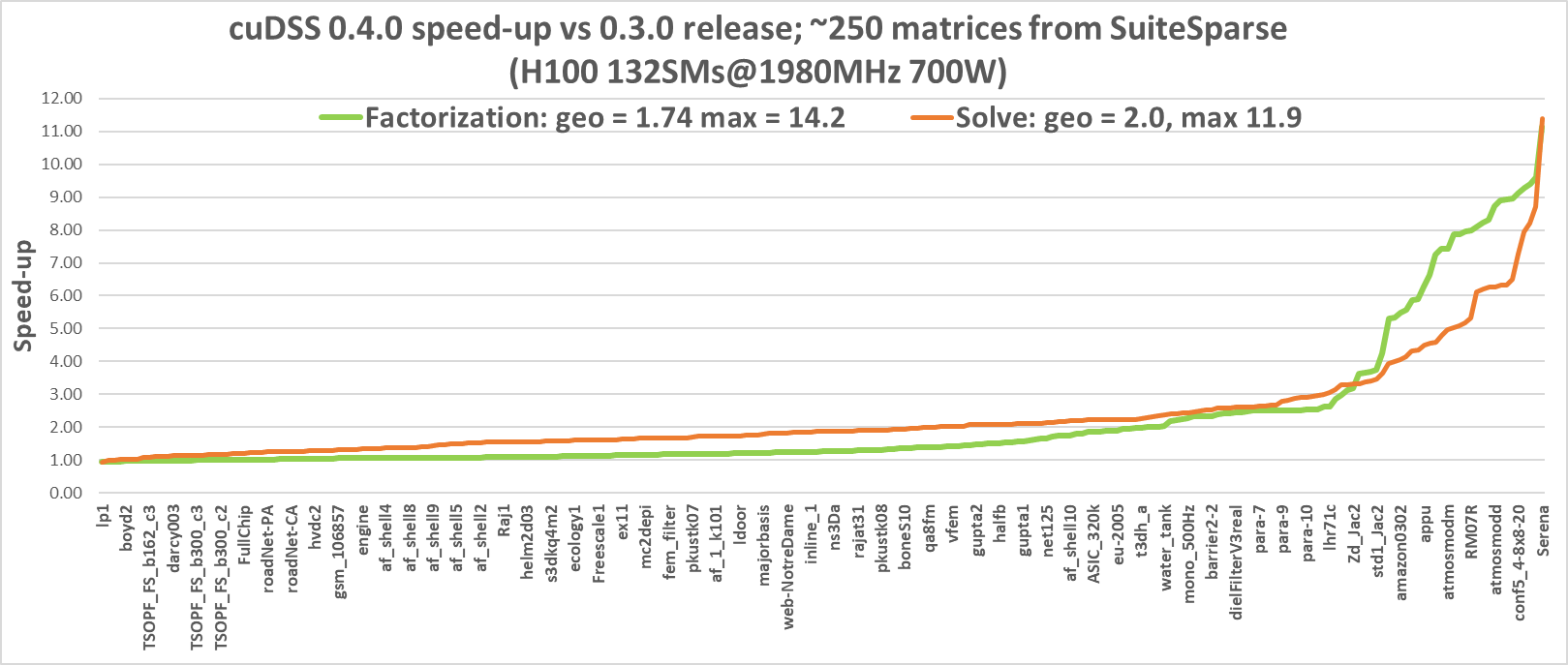
如圖所示,分解階段和求解階段均有顯著改進,幾何均值分別為 1.74 和 2.0、一些三角形因子相對稀疏的矩陣并未顯示出顯著的加速。但是,Serena、conf5_4_8x8_20 和 atmosmodd (來自各種類型的 HPC 應用) 等矩陣在分解階段的速度提升超過 8 倍,在求解階段的速度提升超過 6 倍。
得益于 cuDSS v0.5.0 中引入的多線程重排序,分析階段的速度也得到了顯著提升。圖 2 使用來自 SuiteSparse 矩陣集合的同一組矩陣,比較了 v0.5.0 和 v0.4.0 分析階段的性能。
性能提升的原因是,v0.4.0 使用了單線程重排序實現,而 v0.5.0 則利用主機上的多個 CPU 線程 (cores)。眾所周知,先進的重排序算法很難高效并行化,而 cuDSS v0.5.0 可以很好地利用多個 CPU cores,從而實現 1.98 的幾何平均加速,最大提升可達 4.82。
請注意,分析階段包括 (可選多線程) 重排序和符號分解,這在 GPU 上執行。因此,重新排序部分的實際加速可能甚至高于圖表所示。

cuDSS v0.5.0 進一步優化了混合顯存模式(最初在 v0.3.0 中引入)的性能。此功能允許 cuDSS 中使用的部分內部數組駐留在主機上,從而為不適合單個 GPU 內存的系統提供解決方案。由于 CPU 和 GPU 之間的內存帶寬顯著增加,它在基于 NVIDIA Grace 的系統上的運行效果尤為出色。
圖 3 展示了 cuDSS 0.5.0 下分解和求解階段的性能提升情況,并使用一組大型矩陣比較了 NVIDIA Grace Hopper 系統 (Grace CPU 加 NVIDIA H100 GPU) 與 x86 系統 (Intel Xeon Platinum 8480CL,2S) 加 NVIDIA H100 GPU 的性能提升情況。

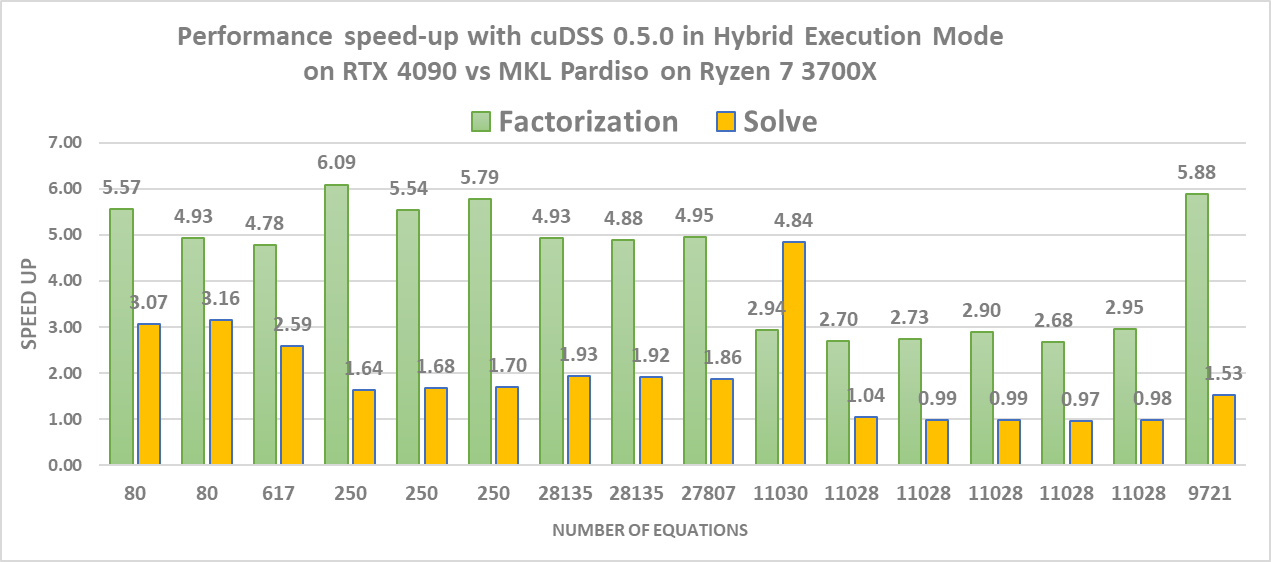
如前所述,v0.5.0 引入了混合執行模式,可提高 cuDSS 在處理小型矩陣時的性能。圖 4 顯示了在分解和求解階段,混合執行模式相對于 CPU 求解器 (Intel MKL PARDISO) 的加速情況。
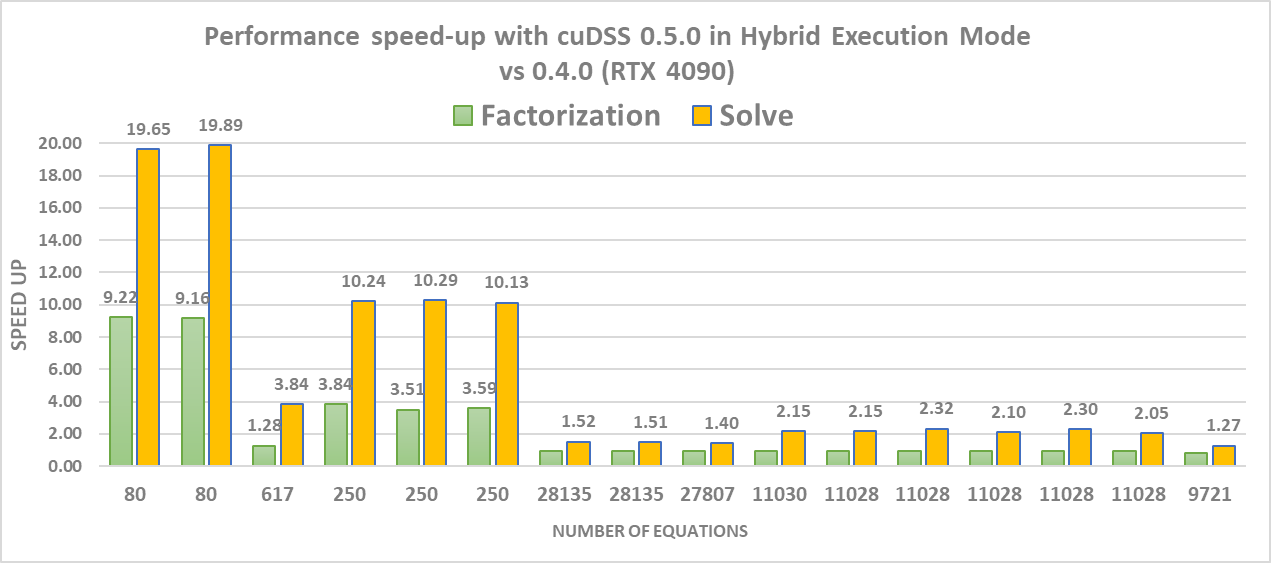
最后,圖 5 顯示了與默認模式 (cuDSS v0.4.0) 相比,新的混合執行模式 (cuDSS v0.5.0) 在一組小矩陣上分解和求解階段的速度提升情況。雖然分解階段的加速僅適用于非常小的矩陣,但求解階段可為方程高達 30K 個的系統提供加速。這可以解釋為,與分解階段相比,求解階段的工作量較少,并且無法充分利用 GPU 來測試矩陣。
總結
NVIDIA cuDSS v0.4.0 和 v0.5.0 版本提供了多項新的增強功能,可顯著提高性能。亮點包括分解和求解方面的一般加速、混合內存和執行模式、主機多線程,以及對非均勻批量大小的支持。除了持續投資性能之外,我們還將持續增強 API 以擴展功能,為用戶提供更高的靈活性和細粒度控制。
準備好開始使用了嗎?下載 NVIDIA cuDSS v0.5.0。
如需了解更多信息,請查看 cuDSS v0.5.0 版本說明 以及之前的以下帖子:
在 NVIDIA 開發者論壇 中加入對話并提供反饋。
?