隨著電力需求不斷增長,電網的電力系統優化(PSO)對于確保高效的資源管理、可持續性和能源安全至關重要。
東部互聯是北美的主要電網,由大約 70,000 個節點組成 (圖 1)。除了規模龐大之外,此類電網的優化還因災難性天氣事件和發電中斷等不確定性而變得復雜。

PSO 通常涉及解決大規模非線性優化問題,例如交變電流最優功率流(ACOPF)模型,這些模型通常包含數百萬個變量和約束。實時獲得準確的結果對于保持電網穩定性和效率至關重要,但這是一項極其困難的任務。
Sungho Shin 教授 (MIT)、Fran?ois Pacaud 教授 (MINES Paris – PSL) 和博士后研究員 Alexis Montoison (ANL) 一直在開發非線性優化算法和求解器,這些算法和求解器使用 NVIDIA 工具來解決大規模 PSO 和其他復雜的非線性優化問題。
他們最近發表的論文 《在 GPU 上進行非線性編程的凝聚空間方法》利用 NVIDIA cuDSS (Direct Sparse Solver) 庫和 NVIDIA Grace Hopper Superchip 等高內存 GPU,以前所未有的規模解決問題。
解決非線性優化問題?
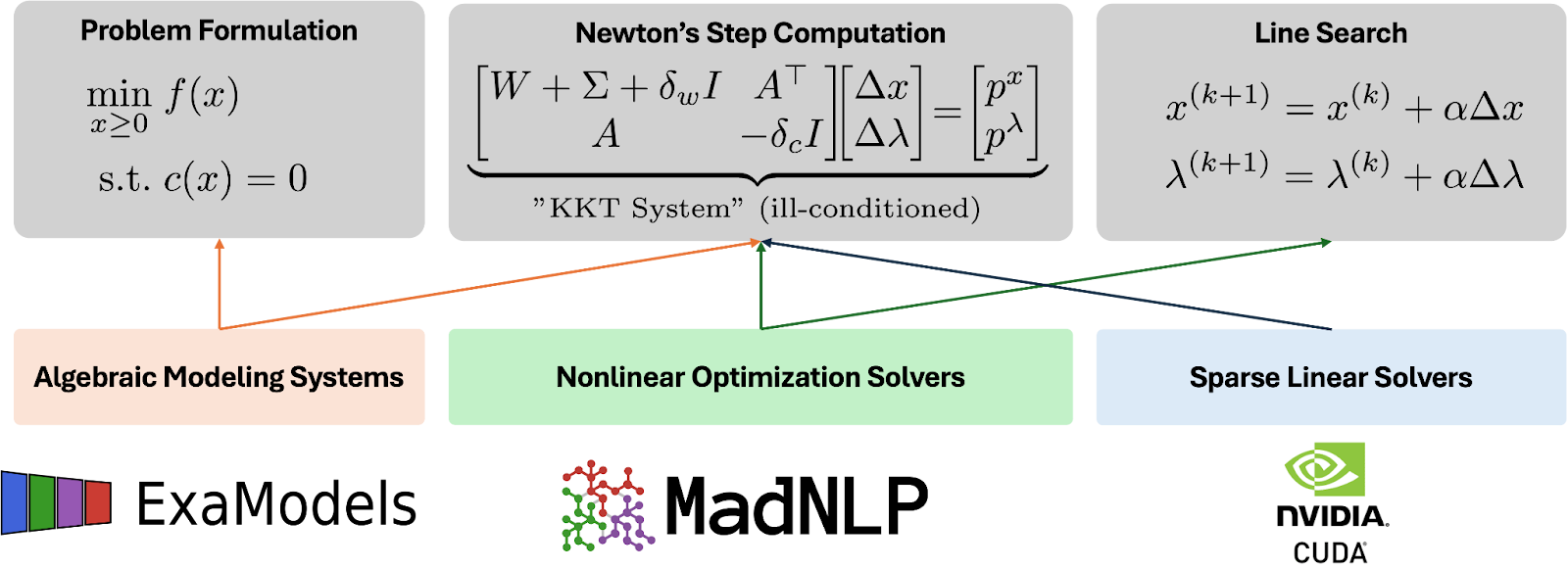
大規模、稀疏、受限問題(如 PSO)非線性優化主要使用內部點方法解決。IPOPT、KNITRO 和 MadNLP 等求解器通過計算步長方向迭代地搜索解決方案,其中包括求解一系列 Karush-Kuhn-Tucker(KKT)系統,并通過行搜索標準確定步長(圖 2)。
KKT 系統條目(目標和約束的導數)及其評估和 KKT 系統的數值解的計算量很大,通常委托給外部庫執行。導數評估由具有自動微分功能的代數建模系統(AMPL、Pyomo 或 JuMP.jl)處理,而 KKT 系統則使用稀疏線性求解器(Pardiso、MUMPS 或 HSL)求解。
內部點算法的主要瓶頸是解決 KKT 系統,這些系統通常是大型、稀疏和條件不良的。由于難以為迭代線性求解器設計預處理器,直接求解器成為獲得 KKT 系統足夠準確的解的首選工具。
在傳統實現中,常用于使用 LBL?分解的稀疏求解器,例如 libHSL 集合中的 MA27 和 MA57 線性求解器。雖然加速并行計算在加速大規模優化方面具有巨大潛力,但高效的直接稀疏求解器對于 GPU 來說一直是難以實現的。
NVIDIA cuDSS 等庫專注于解決這些差距。
使用 cuDSS 為大規模 PSO 求解器提供支持?
得益于 MadNLP 程序中可以利用新 cuDSS 庫的突破,現在可以實現內部點方法的高效 GPU 實現。MadNLP 使用精簡的 KKT 程序(lifted 和 hybrid),將問題重新表述為稀疏正定系統,而不是最初的無限系統。
然后,cuDSS 可以在 GPU 上高效地分解和求解壓縮的 KKT 系統,從而顯著提高大規模非線性優化的性能。
Sungho、Fran?ois 和 Alexis 利用這些功能開發了一套全面的軟件套件,可完全在 NVIDIA GPU 上運行非線性優化。此套件包括用于代數建模和自動微分的 ExaModels,以及用于實現內部點方法的 MadNLP,后者使用提升和混合 KKT 系統策略(圖 2)。
這套工具為 PSO 問題帶來了巨大的加速,其規模足以對整個東部互連進行建模,節點數量超過 70K 個,對應 674K 的維度系統。借助 NVIDIA A100 GPU 加速工作流程中的 ExaModels、MadNLP 和 cuDSS 部分,首次實現了針對這種規模問題的實時解決方案 (不到 20 秒)。這表明計算屏障不再抑制整個東部互連的實際 PSO。

與之前在 AMD EPYC 7443 CPU 上采用的先進技術相比,他們的 GPU 加速實現了 10 倍以上的加速(圖 3)。通過將基于 CPU 的 HSL MA27 線性求解器替換為 cuDSS,數值分解和三角求解步驟的速度提高了 30 倍。
實現這些加速的部分原因是 KKT 程序特別適用于 cuDSS。它們呈現固定的稀疏模式,確保在預處理階段只需執行一次昂貴且具有挑戰性的并行符號分析步驟。然后,算法的其余部分僅依賴于高效的 cuDSS 重構例程。
借助 NVIDIA GH200 重新定義 PSO 的極限?
PSO 的一些重要應用涉及復雜度更大的問題,例如具有數百萬個變量和約束的問題。例如,多周期表述有助于預測未來電力需求,而安全受限的表述有助于通過應急規劃確保國家基礎設施的可靠性。
這些問題非常龐大且復雜,需要在加速計算硬件方面取得突破才能變得易于處理。
NVIDIA Grace Hopper 超級芯片 (GH200)使 MadNLP 能夠解決以前認為棘手的問題。最近的一份出版物展示了如何需要 GH200 來解決具有超過 10M 個變量(圖 4)和約束的多周期優化問題,以及 576 GB 統一內存(480-GB CPU 加 96-GB GPU)帶來的優勢。
對于小問題實例,由于向 GPU 傳輸數據的開銷,CPU 的速度更快。

研究結果極具突破性,作者表示:“我們預計,具有統一內存的 CPU/GPU 系統 (如 NVIDIA GH200) 將在不久的將來成為主流硬件,并提供更高的 RAM 容量。這些進步可以為電力市場運作提供強大的計算工具。”
加速新一代能效?
Sungho、Fran?ois 和 Alexis 在實際解決具有挑戰性的 PSO 問題方面已經取得了巨大進步。他們計劃繼續努力,提高求解器的數值精度和健壯性。
他們正在開發新的求解器 MadNCL,該求解器使用 MadNLP 解一系列子問題,以最小化增強拉格朗日量。這一方法展示了在優化過程中提高準確性和對退化的魯棒性的巨大前景。
這些新方法繼續依賴于 cuDSS 和 NVIDIA GPU 快速發展的功能,包括通過多 GPU 多節點支持擴展以解決更大問題的能力。
開始使用 cuDSS?
您可以下載早期訪問版的 cuDSS 庫 ,開始加速您的應用程序。有關 cuDSS 功能的更多信息,請參閱 NVIDIA cuDSS (預覽版):用于直接稀疏求解器的高性能 CUDA 庫 。如需詳細了解可與 cuDSS 結合使用的其他數學庫,請參閱 CUDA-X GPU 加速庫 。
如果您對 PSO 和其他 GPU 加速的非線性優化應用程序感興趣,請探索 ExaModels 和 MadNLP GitHub 資源庫。
對于實際部署,了解 Honeywell 如何將 cuDSS 集成到 UniSim Design 中, 實現高達 78 倍的性能提升 。
?