Scikit-learn 是應用最廣泛的 ML 庫,因其 API 簡單、算法多樣且與 pandas 和 NumPy 等熱門 Python 庫兼容,因此在處理表格數據方面備受歡迎。現在,NVIDIA cuML 使您能夠繼續使用熟悉的 Scikit-learn API 和 Python 庫,同時使數據科學家和機器學習工程師能夠在 NVIDIA GPU 上利用 CUDA 的強大功能,而無需更改任何應用代碼。
在 NVIDIA cuML 25.02 中,我們將在公測版中發布無需更改代碼即可加速 scikit-learn 算法的功能。2019 年首次推出的 NVIDIA cuML 已迅速為 Python 機器學習添加基于 CUDA 的 GPU 算法。借助最新版本,數據科學家和機器學習工程師能夠保持 scikit-learn 應用不變,并在 NVIDIA GPU 上實現比 CPU 快 50 倍的性能。
此新版本的 cuML 還可加速領先的降維和聚類算法 UMAP 和 HDBSCAN,在 NVIDIA GPU 上的速度是 CPU 的 60 倍和 175 倍,且無需更改代碼。
在本文中,我們將討論 cuML 中新的零代碼更改功能的工作原理,并展示如何將其用于 scikit-learn 應用的示例。
概述
在 CPU 上訓練 ML 模型一次運行可能需要幾分鐘時間。多次迭代和超參數掃描會導致速度變慢,導致開發者工作效率降低、迭代次數減少以及模型質量降低。
此 cuML 版本將 cuDF-pandas 為 DataFrame 操作建立的零代碼更改加速范式擴展到機器學習,將迭代時間縮短到數秒,且無需對代碼進行任何更改。
過去,數據科學家必須自定義應用程序,以便使用 NVIDIA GPU 加速應用程序。這使得在不同平臺上進行開發、訓練和推理變得更加困難。
借助 cuML 中全新的零代碼更改功能,現有的 scikit-learn 腳本可以保持不變地運行。cuML 會自動加速 NVIDIA GPUs 上的兼容組件,并針對不受支持的操作回退至 CPU 執行。這使得在 CPUs 上進行開發和在 GPUs 上進行部署成為可能,并且可以根據您的應用需求進行反向部署。
該測試版目前可通過零代碼更改加速最熱門的 scikit-learn 算法,包括隨機森林、k-Nearest Neighbors、主成分分析 (PCA) 和 k-means 聚類。有關受支持方法的完整列表的更多信息,請參閱 cuML-accel 會加速什么? 正在進行的開發將根據用戶反饋優先考慮額外的算法覆蓋范圍。
要在 NVIDIA GPU 上獲得 ML 工作流的最高性能,請盡量減少 CPU 和 GPU 之間作為工作流一部分的數據傳輸。這可以通過以下方式實現:將數據加載到 GPU 上一次,然后執行預處理、ML 訓練和推理,然后將結果發送回主機內存。
要使用 NumPy pandas 和 scikit-learn 過渡 CPU 工作流,請在發送返回結果之前使用 cuPy、cuDF-pandas 和 cuML。在此版本中,使用 cuDF-pandas 和 cuML 零代碼更改的功能是試驗性的,我們鼓勵您在工作流中試用此功能。
要在 ML 模型推理期間獲得最高性能,您可以使用 CUDA-X 生態系統中的庫和模塊在 GPU 上運行。
例如,要對隨機森林模型執行推理,請使用 cuML 庫中的 Forest Inference Library (FIL) 模塊 。這可與 NVIDIA Triton 推理服務器 配合使用,在生產環境中部署和擴展 AI 模型。
幕后使用 cuML 零代碼更改 scikit-learn
cuML 零代碼更改功能通過 cuml.accel 模塊實現。啟用后,導入 scikit-learn 或其算法類會激活兼容性層,用于代理模型類型和函數。
對這些代理對象的操作通過受支持的 cuML 在 NVIDIA GPU 上執行,否則則退回到基于 CPU 的 scikit-learn 實現。即使與內部使用 scikit-learn 的第三方庫集成,設備和主機內存之間的同步也會自動發生。
調用 scikit-learn 估計器時,如果 cuML 支持估計器,代理對象會生成 GPU 加速 (cuML) 模型實例,如果不支持,代理對象會創建 CPU 原生 (scikit-learn) 模型實例。
對于受支持的估測器,該方法首先調用 GPU 執行,并根據需要將輸入數據復制到設備內存。對于不受支持的操作,系統通過在 CPU 上重建模型并在需要時將數據復制到 CPU,從而透明地將計算轉移到 CPU。
如有需要,cuML 可在 CPU 上的 scikit-learn 對象和后端 GPU 上的 cuML 對象之間進行透明轉換,從而實現真正的零代碼更改功能。
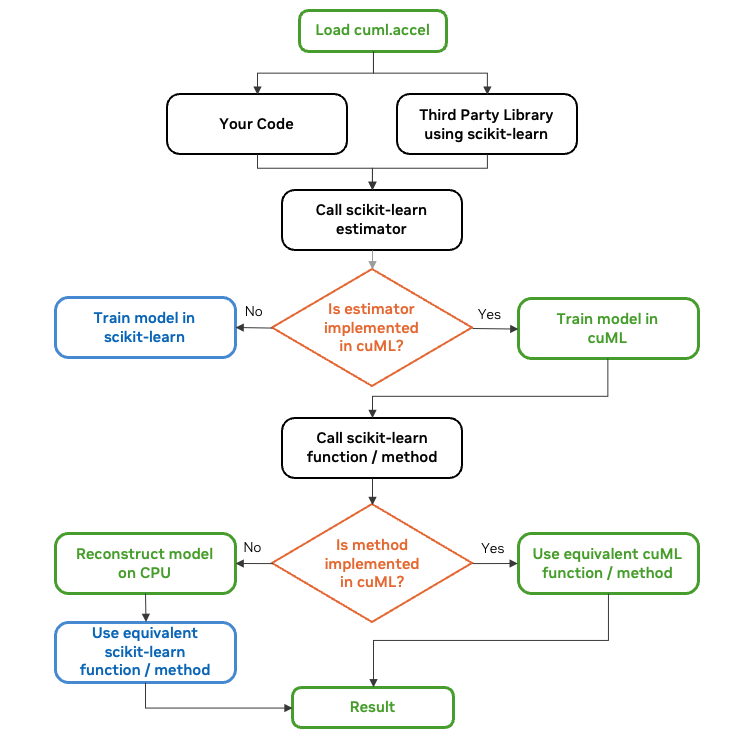
借助 cuml.accel,cuML 可自動轉換超參數,并按照 scikit-learn 的約定對齊輸出,以確保與 Python 生態系統中的其他庫兼容。這可確保與基于 CPU 的工作流保持一致,同時加速受支持的算法。
在隨機森林等某些情況下,為了利用 NVIDIA GPU 的巨大并行性,cuML 的實現方式與 scikit-learn 不同。
cuML 中的算法旨在在合并輸出之前同時處理多行輸入,管理 GPU 內存以避免昂貴的分配,并使用并行友好型算法版本。這預計會生成數值上等效的結果,但由于運算順序不同或算法中錯誤的累積,這些結果并不總是相同的。
在某些情況下,機器學習數據集可能會超過 GPU 顯存容量。cuml.accel 模塊會自動使用 CUDA 統一內存 。借助統一內存,主機內存可以與 GPU 內存一起使用,并根據需要自動執行兩者之間的數據遷移。這將可用于 ML 處理的有效內存擴展到 GPU 和主機內存的總和。
如何使用 cuML 加速 scikit-learn 代碼
新版本的 NVIDIA cuML 與 scikit-learn 零代碼更改,已預安裝在 Google Colab 中。
在 Jupyter notebook 中,在導入其他 notebook 之前,使用 notebook 開頭的以下命令:
%load_ext cuml.accelimport sklearn |
要在各種本地和云環境中安裝 cuML,請參閱 RAPIDS 安裝指南 。使用帶有 python 模塊標志的 Python 腳本來加速保持不變的 scikit-learn 腳本:
python -m cuml.accel unchanged_script.py |
這是一個簡單的 scikit-learn 應用,可基于具有 50 萬個樣本和 100 個特征的數據集訓練隨機森林模型。
%load_ext cuml.accelfrom sklearn.datasets import make_classificationfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierX, y = make_classification(n_samples=500000, n_features=100, random_state=0)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)rf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)rf.fit(X_train, y_train) |
如需詳細了解在 GPU 上運行的模型組件與回退所需的組件相比有哪些,請將 logger 對象添加到函數中。此代碼示例將日志記錄級別設置為 DEBUG:
%load_ext cuml.accelfrom cuml.common import logger; logger.set_level(logger.level_enum.debug)from sklearn.datasets import make_classification… |
執行時,日志記錄器對象會發送捕獲每個命令執行位置的消息。在之前的示例中,fit 函數在 GPU 上執行:
cuML: Installed accelerator for sklearn.cuML: Installed accelerator for umap.cuML: Installed accelerator for hdbscan.cuML: Successfully initialized accelerator.cuML: Performing fit in GPU. |
基準測試
我們比較了在 Intel Xeon Platinum 8480CL CPU 上訓練 scikit-learn 算法與 H100 80GB GPU 在分類和回歸等代表性工作負載上的性能。我們觀察到,隨機森林等常見算法在訓練期間可將速度提高 25 倍,從而將時間從 CPU 上的幾分鐘縮短到 GPU 上的幾秒鐘。
聚類和降維算法的計算更為復雜,通常使用更大的數據集大小。在這些情況下,GPU 可以將訓練時間從使用 CPU 的幾小時縮短到幾分鐘。有關更多結果的更多信息,請參閱 Zero Code Change Benchmarks 。
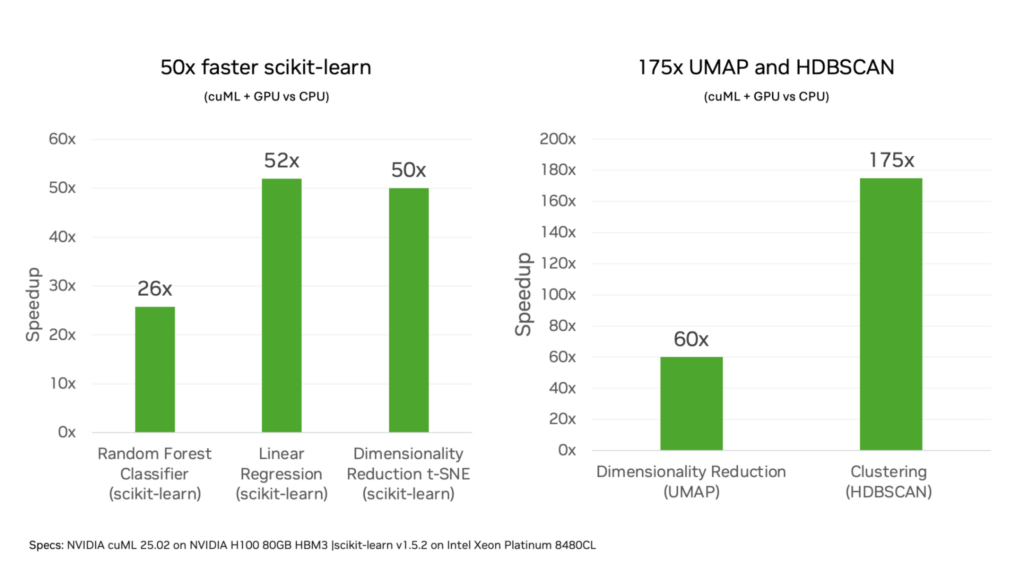
GPU 加速的加速效果受以下因素的影響:
- 算法的計算復雜性越高,GPU 加速的速度提升幅度就越大。計算更復雜的算法可能會影響數據傳輸和初始化的開銷。
- 由于并行計算資源會同時處理更多運算,從而實現更高的速度提升,因此特征數量越多,GPU 利用率就越高。
開始使用 cuML
NVIDIA cuML 引入了一種簡單的方法,使用零代碼更改功能作為測試版,在 NVIDIA GPU 上加速 scikit-learn、UMAP 和 HDBSCAN 應用程序。cuML 現在可以在可能的情況下訪問 NVIDIA GPU 和 CUDA 算法的強大功能,并在函數尚不支持時透明地使用 CPU 上的 scikit-learn。我們觀察到,scikit-learn 的訓練速度提高了 50 倍,UMAP 的訓練速度提高了 60 倍,HDBSCAN 的訓練速度提高了 250 倍。
有關此功能的更多信息,請參閱 NVIDIA cuML。 有關此功能的更多示例,請參閱 Google Colab notebook。最新版本的 cuML,具有零代碼更改功能,已預安裝在 Google Colab 中。
我們鼓勵您下載最新版本并試用您的應用程序。您可以隨時在 Slack 上與我們分享您的反饋,網址是#RAPIDS-GoAi。
有關自定進度課程和講師指導式課程,請參閱 適用于數據科學的 DLI 學習路徑 。
?
?