
對萬億參數模型的興趣是什么?我們知道當今的許多用例,并且由于有望提高以下方面的能力,人們的興趣正在增加:
- 自然語言處理任務,例如翻譯、問答、抽象和流暢性。
- 掌握長期背景和對話能力。
- 結合語言、視覺和語音的多模態應用。
- 創意應用,如敘事、詩歌生成和代碼生成。
- 科學應用,例如蛋白質折疊預測和藥物研發。
- 個性化,能夠培養一致的個性并記住用戶上下文。
其優勢是巨大的,但訓練和部署大型模型的計算成本高昂且需要大量資源。旨在提供實時推理的計算高效、經濟高效且節能的系統對于廣泛部署至關重要。新的 NVIDIA GB200 NVL72 就是這樣一個系統,可以完成這項任務。
為了說明這一點,我們考慮一下多專家模型 (MoE).這些模型有助于在多個專家之間分配計算負載,并使用模型并行和管道并行跨數千個 GPU 進行訓練。提高系統效率。
然而,并行計算、高速顯存和高性能通信的新水平可以使 GPU 集群能夠應對棘手的技術挑戰。 NVIDIA GB200 NVL72 機架級架構實現了這一目標,我們將在以下博文中詳細介紹。
適用于百億億級 (Exascale) AI 超級計算機的機架級設計
核心 GB200 NVL72 是 NVIDIA GB200 Grace Blackwell 超級芯片。它將兩個高性能 NVIDIA Blackwell Tensor Core GPU 和 NVIDIA Grace CPU 通過 NVLink 芯片到芯片 (C2C) 接口連接,可提供 900 GB/s 的雙向帶寬。借助 NVLink-C2C,應用程序可以一致地訪問統一內存空間。這簡化了編程,并支持萬億參數 LLM、用于多模態任務的 Transformer 模型、用于大規模模擬的模型和用于 3D 數據的生成模型的更大內存需求。
GB200 計算托盤基于新的 NVIDIA MGX 設計。它包含兩個 Grace CPU 和四個 Blackwell GPU.GB200 具有冷卻板和液體冷卻接口,PCIe Gen 6 支持高速網絡,以及用于 NVLink 線纜盒的 NVLink 接口。GB200 計算托盤提供 80 petaflop 的 AI 性能和 1.7 TB 的快速內存。

最大的問題是需要足夠數量的突破性成果,這些成果使用 Blackwell GPU,因此它們必須以高帶寬和低延遲進行通信,并始終保持忙碌狀態。
GB200 NVL72 機架級系統使用帶有 9 個 NVLink 交換機托盤的 NVIDIA NVLink Switch 系統以及互連 GPU 和交換機的線纜盒,提高了 18 個計算節點的并行模型效率。
NVIDIA GB200 NVL36 和 NVL72
GB200 在 NVLink 域中支持 36 個和 72 個 GPU.每個機架根據 MGX 參考設計和 NVLink Switch 系統托管 18 個計算節點。它采用 GB200 NVL36 配置,一個機架中包含 36 個 GPU,另一個 GB200 計算節點中包含 18 個單 GB200 計算節點。GB200 NVL72 在一個機架中配置 72 個 GPU,在兩個機架中配置 18 個雙 GB200 計算節點,即 72 個 GPU,其中有 18 個單 GB200 計算節點。
GB200 NVL72 使用銅纜盒密集封裝和互連 GPU,以簡化操作。它還采用液冷系統設計,成本和能耗降低 25 倍。

第五代 NVLink 和 NVLink Switch 系統
NVIDIA GB200 NVL72 引入了第五代 NVLink,可在單個 NVLink 域中連接多達 576 個 GPU,總帶寬超過 1 PB/s,快速內存超過 240 TB.每個 NVLink 交換機托盤提供 144 個 100 GB 的 NVLink 端口,因此 9 臺交換機可完全連接 72 個 Blackwell GPU 上的 18 個 NVLink 端口。
每個 GPU 革命性的 1.8 TB/s 雙向吞吐量是 PCIe 5.0 帶寬的 14 倍以上,可為當今極為復雜的大型模型提供無縫高速通信。

跨代 NVLink
NVIDIA 行業領先的高速低功耗 SerDes 創新推動了 GPU 到 GPU 通信的發展,首先是推出 NVLink,以高速加速多 GPU 通信。NVLink GPU 到 GPU 帶寬為 1.8 TB/s,是 PCIe 帶寬的 14 倍。第五代 NVLink 比 2014 年推出的第一代 160 GB/s 快 12 倍。NVLink GPU 到 GPU 通信在擴展 AI 和 HPC 領域的多 GPU 性能方面發揮了重要作用。
自 2014 年以來,GPU 帶寬的進步,加上 NVLink 域的指數級擴展,使得 576 Blackwell GPU NVLink 域的 NVLink 域的總帶寬增加了 900 倍,達到 1 PB/s。
用例和性能結果
GB200 NVL72 的計算和通信能力前所未有,使 AI 和 HPC 領域的重大挑戰觸手可及。
AI 訓練
GB200 包含速度更快的第二代 Transformer 引擎,具有 FP8 精度。與相同數量的 NVIDIA H100 GPU 相比,GB200 NVL72 可為 GPT-MoE-1.8 T 等大型語言模型提供 4 倍的訓練性能。
AI 推理
GB200 引入了先進的功能和第二代 Transformer 引擎,可加速 LLM 推理工作負載。與上一代 H100 相比,它將資源密集型應用程序 (例如 1.8 T 參數 GPT-MoE) 的速度提高了 30 倍。新一代 Tensor Core 引入了 FP4 精度和第五代 NVLink 帶來的諸多優勢,使這一進步成為可能
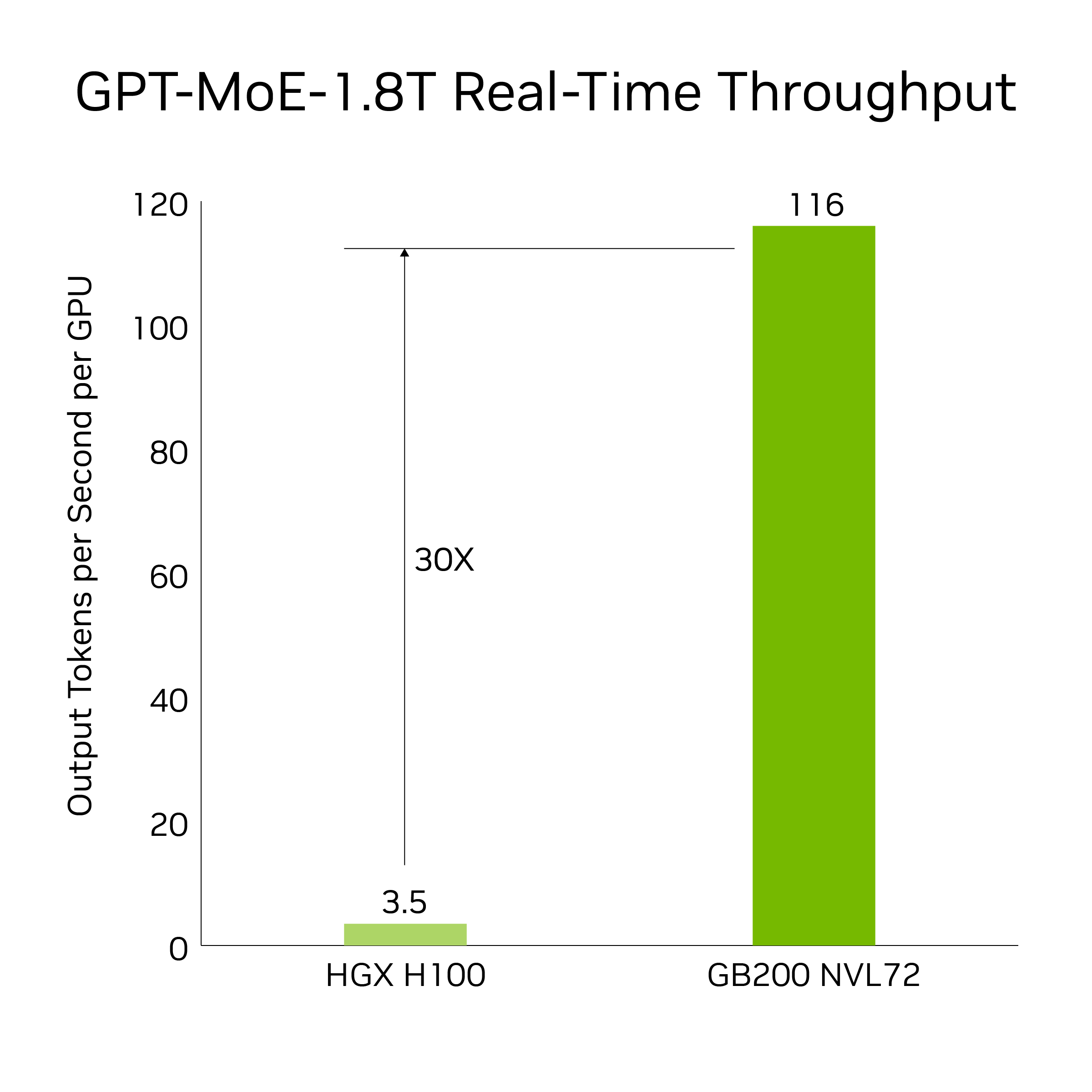
結果基于令牌到令牌延遲=50 毫秒;第一個令牌實時延遲=5000 毫秒;輸入序列長度=32768;輸出序列長度=1024 路輸出,8 路 8 路 HGX H100 風冷:400 GB IB 網絡與 18 GB200 超級芯片液冷:NVL36,每個 GPU 性能比較*.預測性能可能會發生變化。
相比于使用 GPT-MoE-1.8 T 的 GB200 NVL72 中的 32 個 Blackwell GPU,相比之下,30 倍加速是通過 8 路 NVLink 和 InfiniBand 擴展的 64 個 NVIDIA Hopper GPU。
數據處理
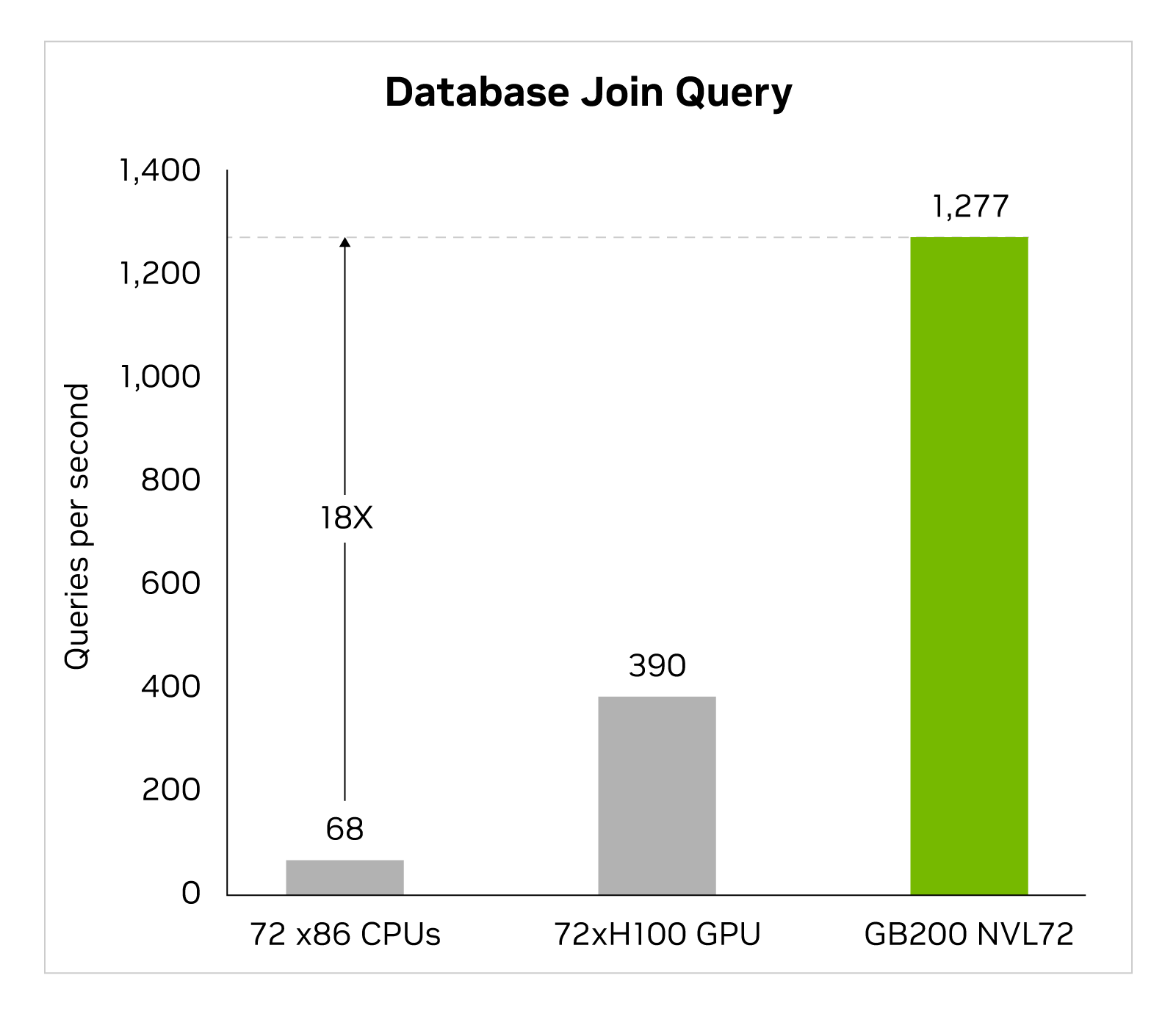
大數據分析有助于組織獲得見解并做出更明智的決策。組織不斷大規模生成數據,并依靠各種壓縮技術來緩解瓶頸并節省存儲成本。為了在 GPU 上高效處理這些數據集,Blackwell 架構引入了硬件解壓縮引擎,該引擎可以大規模地原生解壓縮壓縮數據,并加速端到端分析流程。解壓縮引擎原生支持使用 LZ4、Deflate 和 Snappy 壓縮格式解壓縮數據。
解壓縮引擎可加快受內存限制的內核操作速度。它提供高達 800 GB/s 的性能,使 Grace Blackwell 的執行速度比 CPU (Sapphire Rapids) 快 18 倍,比 NVIDIA H100 Tensor Core GPU 在查詢基準測試中的執行速度快 6 倍。
借助 8 TB/s 的高顯存帶寬和 Grace CPU 高速 NVlink 芯片到芯片 (C2C),該引擎可加快數據庫查詢的整個過程。這可在數據分析和數據科學用例中實現出色的性能。這使得組織能夠在降低成本的同時快速獲得見解。
基于物理性質的模擬
基于物理性質的模擬仍然是產品設計和開發的中流柱。從飛機和火車到橋梁、硅芯片,甚至是藥物,通過模擬測試和改進產品可節省數十億美元。
在漫長而復雜的工作流程中,特定于應用程序的集成電路幾乎完全在 CPU 上設計,包括用于識別電壓和電流的模擬分析。Cadence SpectreX 模擬器就是求解器的一個示例。下圖顯示了 SpectreX 在 GB200 上的運行速度比在 x86 CPU 上快 13 倍。
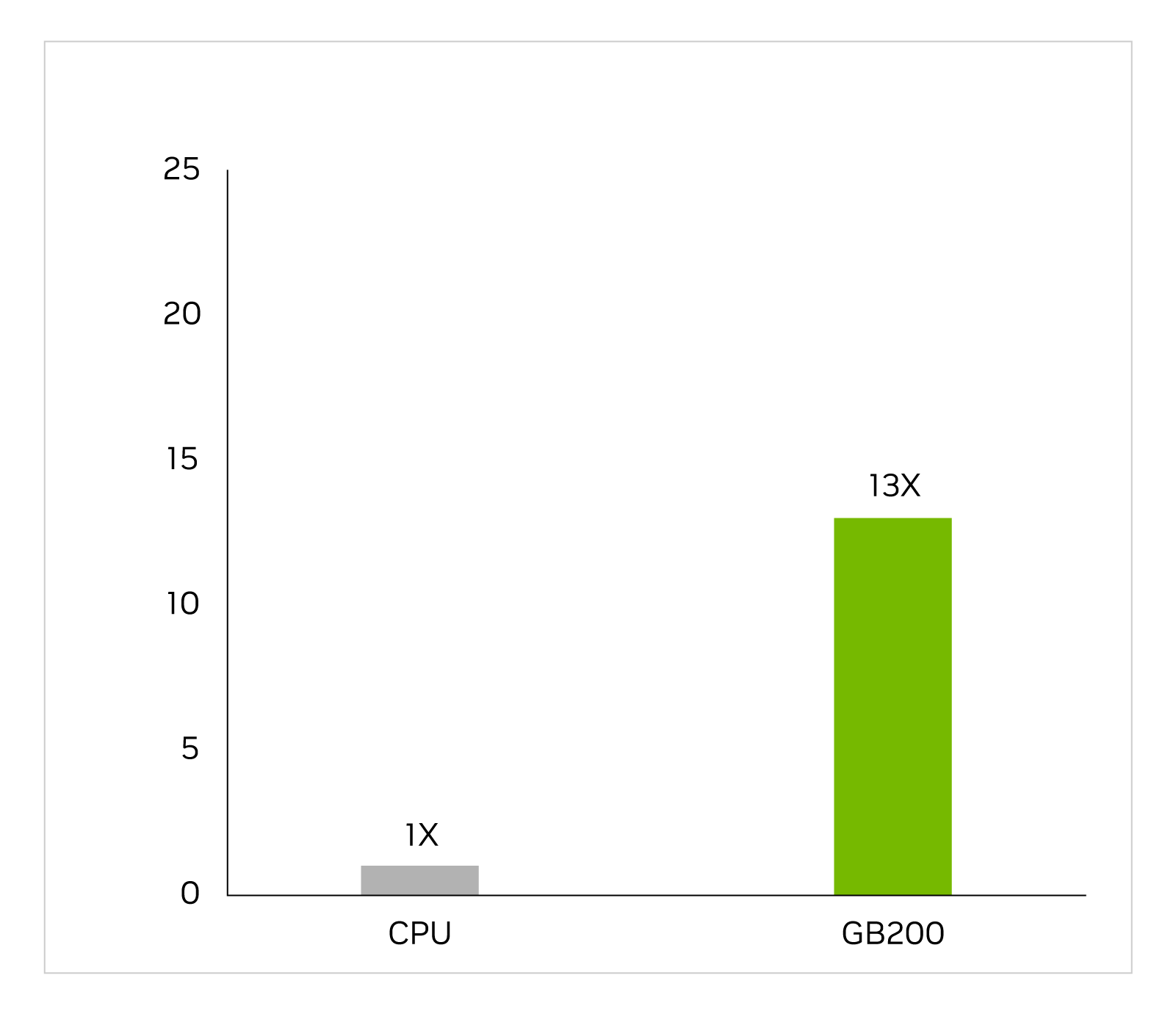
Cadence SpectreX (Spice 模擬器) | CPU:16 核 AMD Milan 75F3 數據集:KeithC Design TSMC N5 | GB200 的性能預測可能會發生變化
在過去兩年中,該行業越來越多地將 GPU 加速的計算流體動力學 (CFD) 作為關鍵工具。工程師和設備設計師使用它來研究和預測其設計行為。Cadence Fidelity 是一個大型渦流模擬器 (LES),在 GB200 上運行模擬的速度比 x86 CPU 快 22 倍。
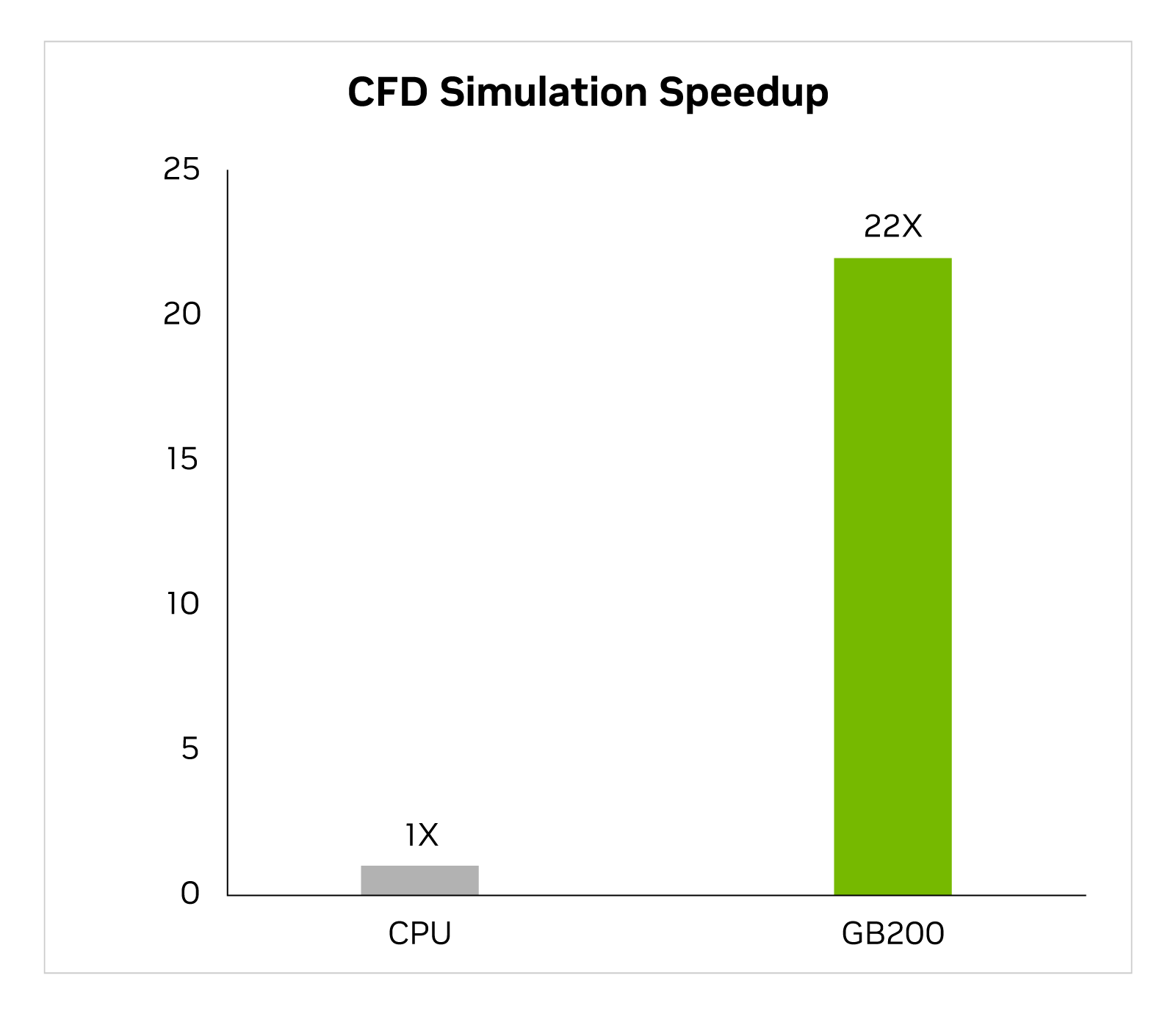
頻率保真度 (LES CFD 求解器) | CPU:16 核 AMD Milan 75F3 數據集:GearPump 200 萬單元 | GB200 的性能預測可能會發生變化
我們期待在 GB200 NVL72 上探索 Cadence Fidelity 的可能性。憑借并行可擴展性和每個機架 30 TB 的顯存,我們的目標是捕獲從未捕獲過的流細節。
總結
回顧一下,我們回顧了 GB200 NVL72 機架級設計,并特別了解了其在單個 NVIDIA NVLink 域上連接 72 個 Blackwell GPU 的獨特功能。這減少了在通過傳統網絡進行擴展時產生的通信開銷。因此,可以對 1.8 T 參數 MoE LLM 進行實時推理,并且訓練該模型的速度加快 4 倍。
72 塊通過 NVLink 連接的 Blackwell GPU 在 130 TB/s 的計算結構上運行,具有 30 TB 的統一顯存,可在單個機架中創建 exaFLOP 的 AI 超級計算機。它就是 NVIDIA GB200 NVL72。
?




