
NVIDIA Grace Hopper 超級芯片架構 是 高性能計算?( HPC )和 AI 工作負載的第一個真正的異構加速平臺。它利用 GPU 和 CPU 的優勢加速應用程序,同時提供迄今為止最簡單和最高效的分布式異構編程模型。科學家和工程師可以專注于解決世界上最重要的問題。
在這篇文章中,您將了解 Grace Hopper 超級芯片的所有信息,并重點介紹 NVIDIA Grace Hoppper 所帶來的性能突破。有關 Grace Hopper 使用 NVIDIA Hopper H100 GPU 在最強大的基于 PCIe 的加速平臺上實現的加速的更多信息,請參閱 NVIDIA Grace Hopper Superchip Architecture 白皮書。
高性能計算和巨大人工智能工作負載的性能和生產力
NVIDIA Grace Hopper 超級芯片架構將 NVIDIA Hopper GPU 的開創性性能與 NVIDIA Grace CPU 的多功能性結合在一起,在單個超級芯片中連接了高帶寬和內存相關 NVIDIA NVLink Chip-2-Chip (C2C) 互連,并支持新的 NVIDIA NVLink Switch System 。
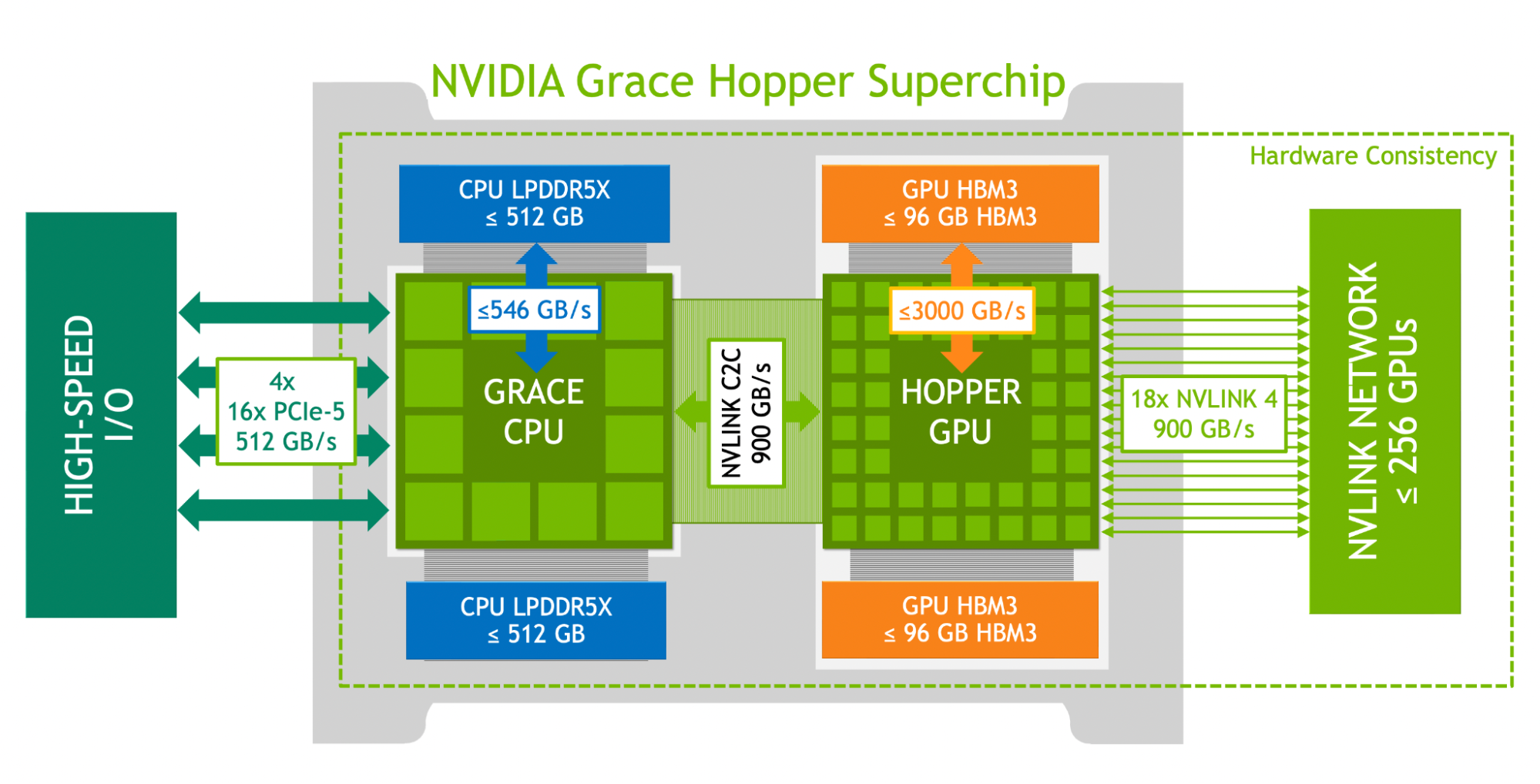
NVIDIA NVLink-C2C 是一種 NVIDIA 內存連貫、高帶寬和低延遲超級芯片互連。它是 Grace Hopper 超級芯片的核心,提供敢達 900 GB / s 的總帶寬。這比通常用于加速系統的 x16 PCIe Gen5 通道高 7 倍的帶寬。
NVLink-C2C 內存一致性提高了開發人員的生產力和性能,并使 GPU 能夠訪問大量內存。 CPU 和 GPU 線程現在可以同時透明地訪問 CPU 和 GPU 駐留內存,使您能夠專注于算法而不是顯式內存管理。
內存一致性使您能夠只傳輸所需的數據,而不會將整個頁面遷移到 GPU 或從 GPU 遷移。它還通過啟用 CPU 和 GPU 的本機原子操作,實現 GPU 和 CPU 線程之間的輕量級同步原語。帶地址轉換服務( ATS )的 NVLink-C2C 利用 NVIDIA Hopper 直接內存訪問( DMA )復制引擎,加快主機和設備間可分頁內存的批量傳輸。
NVLink-C2C 使應用程序能夠超額訂閱 GPU 的內存,并以高帶寬直接利用 NVIDIA Grace CPU 的內存。每個 Grace Hopper 超級芯片最多 512 GB LPDDR5X CPU 內存, GPU 可直接高帶寬訪問比 HBM 多 4 倍的內存。結合 NVIDIA NVLink 交換機系統,在多達 256 個 NVLink 連接的 GPU 上運行的所有 GPU 線程現在可以以高帶寬訪問多達 150 TB 的內存。第四代 NVLink 支持使用直接加載、存儲和原子操作訪問對等內存,使加速應用程序比以往任何時候都更容易解決更大的問題。
與 NVIDIA 網絡技術一起, Grace Hopper Superchips 為下一代 HPC 超級計算機和 AI 工廠提供了配方。客戶可以接受更大的數據集、更復雜的模型和新的工作負載,從而比以前更快地解決這些問題。
NVIDIA Grace Hopper 超級芯片的主要創新如下:
- NVIDIA Grace CPU :
- 多達 72x Arm Neoverse V2 內核,每個內核配備 Armv9.0-A ISA 和 4 × 128 位 SIMD 單元。
- 高達 117 MB 的三級緩存。
- 高達 512 GB 的 LPDDR5X 內存,提供高達 546 GB / s 的內存帶寬。
- 最多 64x PCIe Gen5 通道。
- NVIDIA 可擴展一致性結構( SCF )網格和分布式緩存,內存帶寬高達 3.2 TB / s 。
- 具有單個 CPU NUMA 節點的高開發人員生產率。
- NVIDIA Hopper GPU :
- 與 NVIDIA A100 GPU 相比,多達 144 個 SM ,具有第四代 Tensor 核心、 transformer 引擎、 DPX 和高 3 倍的 FP32 和 FP64 。
- 高達 96 GB 的 HBM3 內存,傳輸速度高達 3000 GB / s 。
- 60 MB 二級緩存。
- NVLink 4 和 PCIe 5 。
- NVIDIA NVLink-C2C :
- Grace CPU 和 Hopper GPU 之間的硬件相干互連。
- 總帶寬高達 900 GB / s , 450 GB / s / dir 。
- 擴展 GPU 內存功能使料斗 GPU 可將所有 CPU 內存尋址為 GPU 內存。每個 Hopper GPU 可以在超級芯片內尋址多達 608 GB 的內存。
- NVIDIA NVLink 交換機系統:
- 使用 NVLink 4 連接多達 256 倍 NVIDIA Grace Hopper 超級芯片。
- 每個 NVLink 連接的 Hopper GPU 可以尋址網絡中所有超級芯片的所有 HBM3 和 LPDDR5X 內存,最多可尋址 150 TB 的 GPU 內存。
針對性能、可移植性和生產力的編程模型
具有 PCIe 連接加速器的傳統異構平臺要求用戶遵循復雜的編程模型,該模型涉及手動管理設備內存分配以及與主機之間的數據傳輸。
NVIDIA Grace Hopper Superchip 平臺是異構的,易于編程, NVIDIA 致力于讓所有開發人員和應用程序都可以使用它,而不依賴于選擇的編程語言。
Grace Hopper Superchip 和平臺的構建都使您能夠為手頭的任務選擇合適的語言, NVIDIA CUDA LLVM Compiler API 使您能夠將首選的編程語言帶到 CUDA 平臺,其代碼生成質量和優化水平與 NVIDIA 編譯器和工具相同。
NVIDIA 為 CUDA 平臺提供的語言(圖 3 )包括 ISO C ++、 ISO Fortran 和 Python 等加速標準語言。該平臺還支持基于指令的編程模型,如 OpenACC 、 OpenMP 、 CUDA C ++和 CUDA Fortran 。 NVIDIA HPC SDK 支持所有這些方法,以及一組用于評測和調試的加速庫和工具。

NVIDIA 是 ISO C ++和 ISO Fortran 編程語言社區的成員,這些社區使符合 ISO C ++和 ISOFortran 標準的應用程序能夠在 NVIDIA CPU 和 NVIDIA GPU 上運行,無需任何語言擴展。有關在 GPU 上運行符合 ISO 的應用程序的更多信息,請參閱 Multi-GPU Programming with Standard Parallel C++ 和 Using Fortran Standard Parallel Programming For GPU Acceleration 。
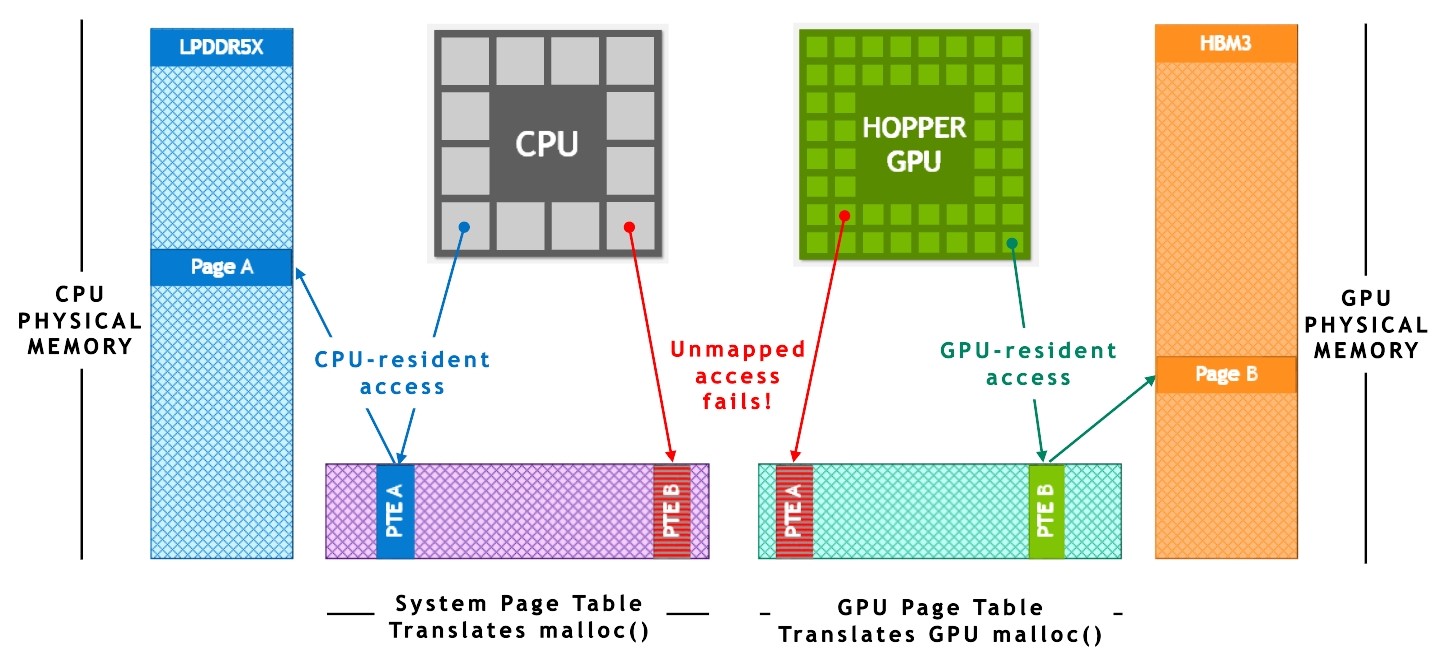
該技術嚴重依賴于 NVIDIA NVLink-C2C 和 NVIDIA 統一虛擬內存提供的硬件加速內存一致性。如圖 4 所示,在沒有 ATS 的傳統 PCIe 連接 x86 + Hopper 系統中, CPU 和 GPU 具有獨立的每個進程頁表,系統分配的內存不能直接從 GPU 訪問。當程序使用系統分配器分配內存,但 GPU 頁面表中的頁面條目不可用時,從 GPU 線程訪問內存失敗。
在基于 NVIDIA Grace Hopper Superchip 的系統中, ATS 使 CPU 和 GPU 能夠共享單個進程頁表,使所有 CPU 和 GPU 線程能夠訪問所有系統分配的內存,這些內存可以駐留在物理 CPU 或 GPU 內存上。所有 CPU 和 GPU 線程都可以訪問 CPU heap 、 CPU 線程堆棧、全局變量、內存映射文件和進程間內存。
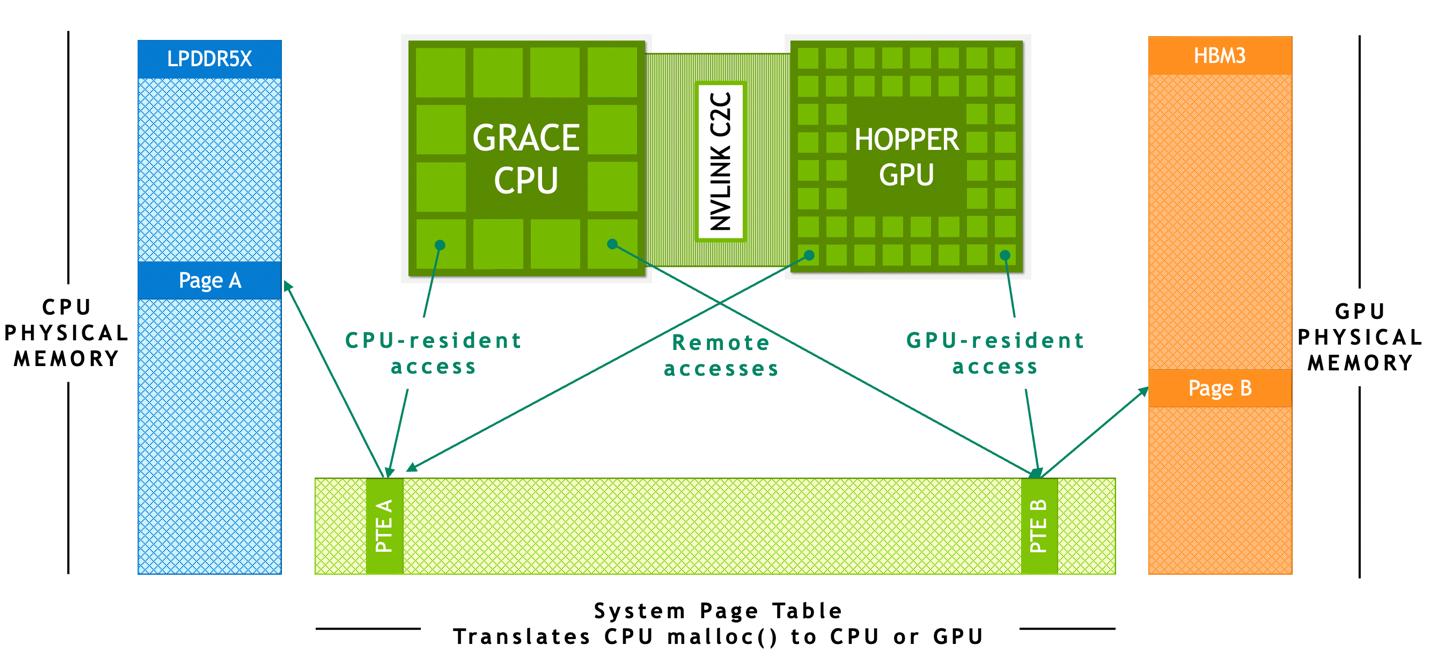
NVIDIA NVLink-C2C 硬件一致性使 Grace CPU 能夠以緩存線粒度緩存 GPU 內存,并使 GPU CPU 能夠訪問彼此的內存而無需頁面遷移。
NVLink-C2C 還加速了系統分配內存上 CPU 和 GPU 支持的所有原子操作。 Scoped atomic operations 完全受支持,并支持系統中所有線程之間的細粒度和可擴展同步。
根據 CPU 或 GPU 線程是否首先訪問系統分配的內存,運行時在 LPDDR5X 或 HBM3 上第一次接觸時使用物理內存備份系統分配的存儲器。從操作系統的角度來看, Grace CPU 和 Hopper GPU 只是兩個獨立的 NUMA 節點。系統分配的內存是可遷移的,因此運行時可以更改其物理內存支持,以提高應用程序性能或處理內存壓力。
對于基于 PCIe 的平臺(如 x86 或 Arm ),您可以使用與 NVIDIA Grace Hopper 模型相同的統一內存編程模型。這最終將通過 Heterogeneous Memory Management (HMM) feature 實現,它是 Linux 內核功能和 NVIDIA 驅動程序功能的組合,使用軟件模擬 CPU 和 GPU 之間的內存一致性。
在 NVIDIA Grace Hopper 上,這些應用程序可以從 NVLink-C2C 提供的更高帶寬、更低延遲、更高原子吞吐量和硬件加速(無需任何軟件更改)中獲益。
超級芯片架構特征
以下是 NVIDIA Grace Hopper 架構的主要創新:
- NVIDIA Grace CPU
- NVIDIA Hopper GPU
- NVLink-C2C
- NVLink 交換機系統
- 擴展 GPU 存儲器
NVIDIA Grace CPU
隨著 GPU 的并行計算能力在每一代中持續增長三倍,快速高效的 CPU 對于防止現代工作負載中的串行和僅 CPU 部分主宰性能至關重要。
NVIDIA Grace CPU 是 first NVIDIA data center CPU ,它是 built from the ground up to create HPC and AI superchips 。 Grace 提供多達 72 個 Arm Neoverse V2 CPU 內核和 Armv9.0-A ISA ,每個內核提供 4 × 128 位寬的 SIMD 單元,支持 Arm 的 Scalable Vector Extensions 2 (SVE2) SIMD 指令集。
NVIDIA Grace 提供領先的每線程性能,同時提供比傳統 CPU 更高的能效。 72 個 CPU 內核在 SPECrate 2017_int_base 上的得分高達 370 (估計),確保高性能以滿足 HPC 和 AI 異構工作負載的需求。
機器學習和數據科學中的現代 GPU 工作負載需要訪問大量內存。通常,這些工作負載必須使用多個 GPU 將數據集存儲在 HBM 內存中。
NVIDIA Grace CPU 提供高達 512 GB 的 LPDDR5X 內存,可在內存容量、能效和性能之間實現最佳平衡。它提供高達 546 GB / s 的 LPDDR5X 內存帶寬, NVLink-C2C 使 GPU 能夠以 900 GB / s 的總帶寬訪問該內存。
單個 NVIDIA Grace Hopper 超級芯片為 Hopper GPU 提供了總計 608 GB 的快速可訪問內存,幾乎是 DGX-A100-80 中可用的慢速內存總量;上一代的 8- GPU 系統。
這是通過圖 7 所示的 NVIDIA SCF 實現的,這是一種網狀結構和分布式緩存,提供高達 3.2 TB / s 的總二等分帶寬,以實現 CPU 內核、內存、系統 I / O 和 NVLink-C2C 的全部性能。 CPU 核心和 SCF 緩存分區( SCC )分布在整個網格中,而緩存交換節點( CSN )通過結構路由數據,并充當 CPU 核心、緩存存儲器和系統其余部分之間的接口。
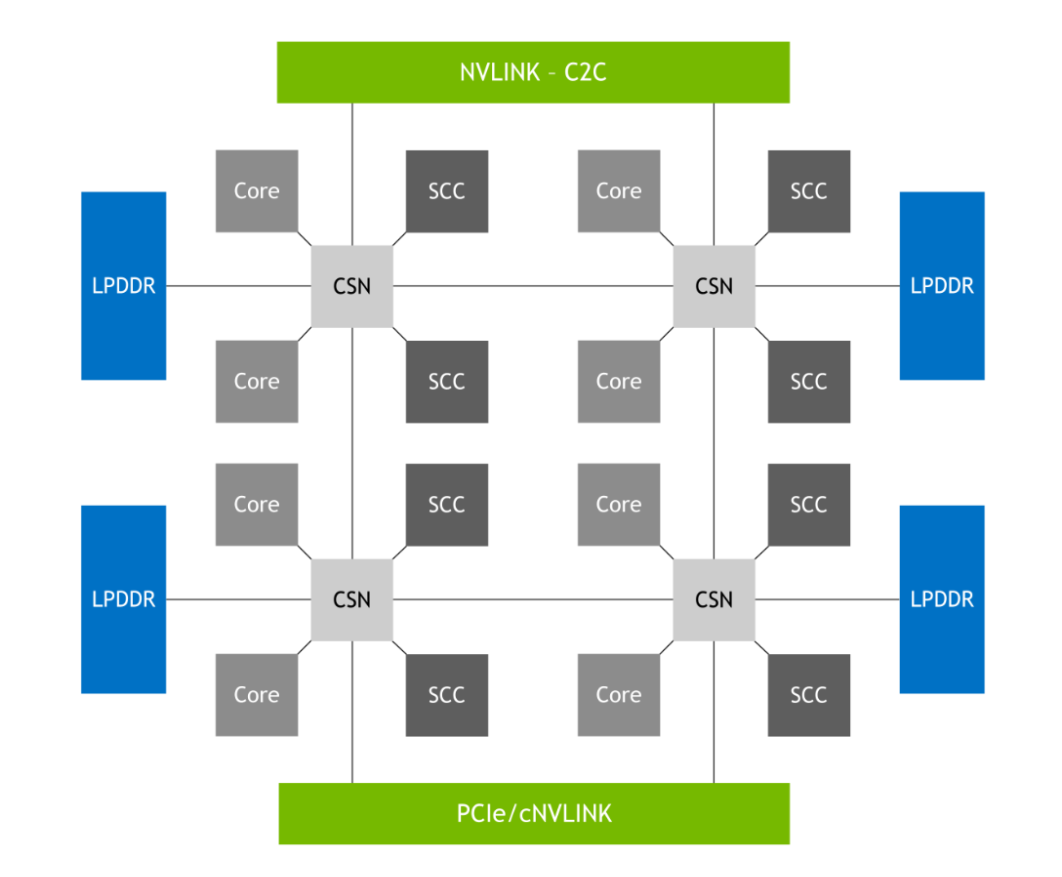
NVIDIA Hopper GPU
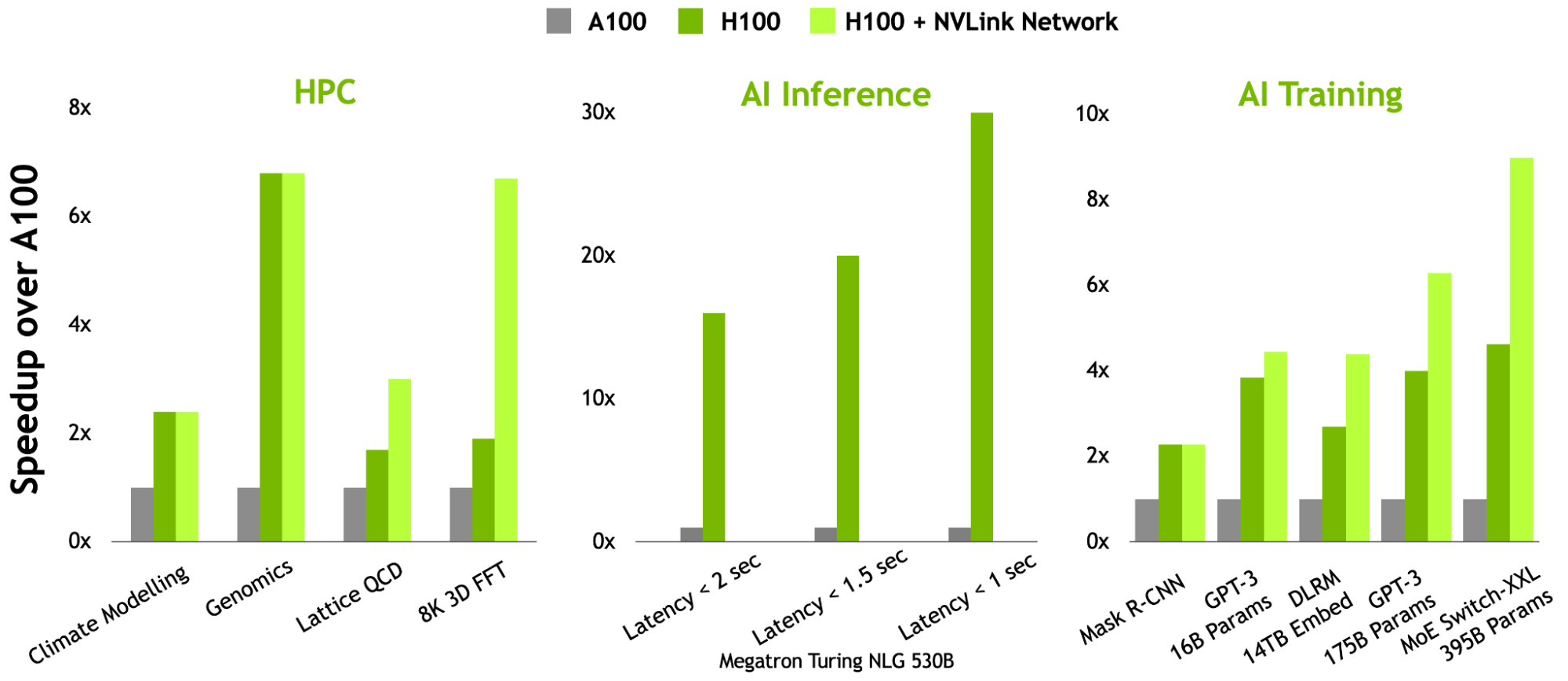
NVIDIA Hopper GPU 是第九代 NVIDIA 數據中心 GPU 。與前幾代 NVIDIA Ampere GPU 相比,它旨在為大規模 AI 和 HPC 應用提供數量級的改進。料斗 GPU 還具有多項創新:
- 新的第四代 Tensor 核心在更廣泛的 AI 和 HPC 任務上執行比以往更快的矩陣計算。
- 與上一代 NVIDIA A100 GPU 相比,新的 transformer 引擎使 H100 在大型語言模型上提供高達 9 倍的 AI 訓練和高達 30 倍的 AI 推理加速。
- 改進的空間和時間數據位置和異步執行功能使應用程序能夠始終保持所有單元忙碌,并最大限度地提高能效。
- 安全 Multi-Instance GPU (MIG ) 將 GPU 劃分為獨立的、適當大小的實例,以最大限度地提高服務質量( QoS ),以適應較小的工作負載。
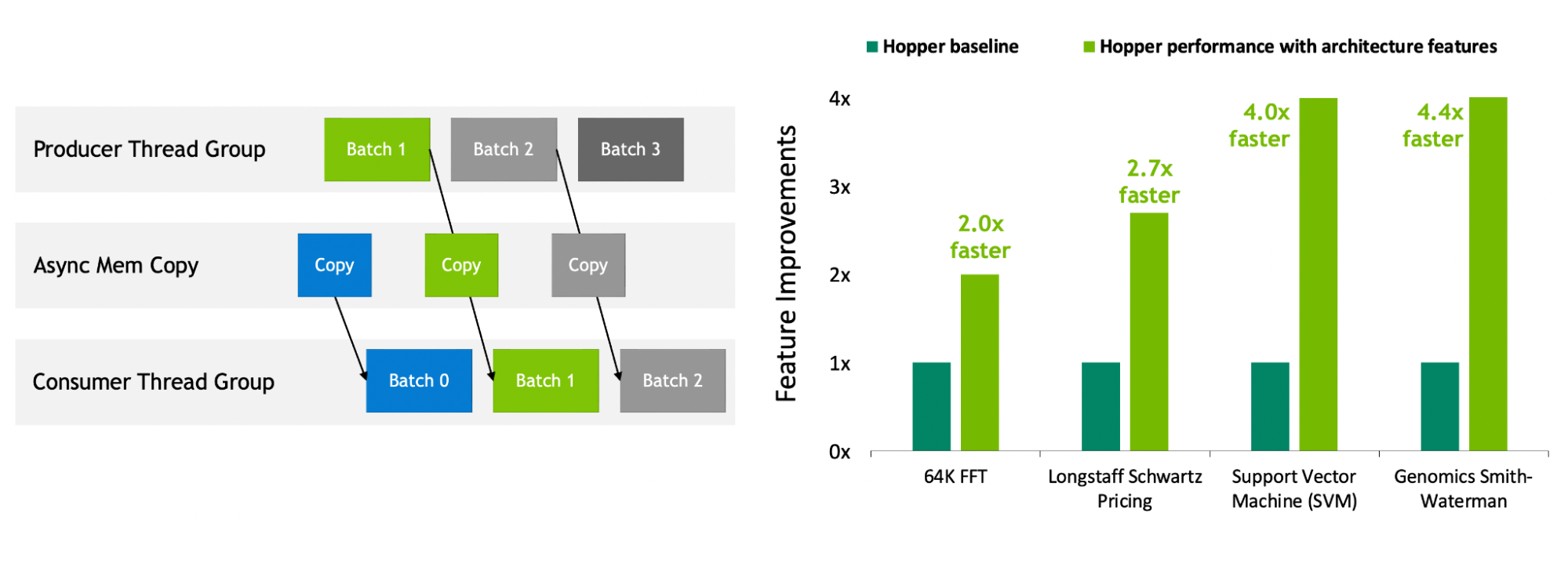
NVIDIA Hopper 是第一款真正的異步 GPU 。它的 Tensor Memory Accelerator ( TMA )和異步事務屏障使線程能夠重疊和流水線無關的數據移動和數據處理,使應用程序能夠充分利用所有單元。
新的空間和時間局部特性,如線程塊集群、分布式共享內存和線程塊重新配置,為應用程序提供了對更大量共享內存和工具的快速訪問。這使應用程序能夠在數據在芯片上時更好地重用數據,從而進一步提高應用程序性能。
有關詳細信息,請參見 NVIDIA H100 Tensor Core Architecture Overview 和 深入NVIDIA Hopper 架構?。
NVLink-C2C :用于超級芯片的高帶寬芯片到芯片互連
NVIDIA Grace Hopper 通過 NVIDIA NVLink-C2C 將 NVIDIA 格雷斯 CPU 和 NVIDIA Hopper GPU 融合到一個超級芯片中, NVIDIA NVLink-C2C 是一個 900 GB / s 芯片到芯片的連貫互連,可以使用統一的編程模型對格雷斯 Hopper 超級芯片進行編程。
NVLink 芯片 2 芯片( C2C )互連在 Grace CPU 和 Hopper GPU 之間提供了高帶寬的直接連接,以創建 Grace Hopper 超級芯片,該芯片專為 AI 和 HPC 應用的降速加速而設計。
憑借 900 GB / s 的雙向帶寬, NVLink-C2C 以較低的延遲提供了 x16 PCIe Gen 鏈路的 7 倍帶寬。 NVLink-C2C 也僅使用 1.3 微微焦/比特傳輸,這比 PCIe Gen 5 能效高 5 倍以上。
此外, NVLink-C2C 是一種相干存儲器互連,具有對系統范圍原子操作的本地硬件支持。這提高了對非本地存儲器的內存訪問的性能,例如 CPU 和 GPU 線程訪問駐留在其他設備中的內存。硬件一致性還提高了同步原語的性能,減少了 GPU 或 CPU 彼此等待的時間,提高了系統的總利用率。
最后,硬件一致性還簡化了使用流行編程語言和框架開發異構計算應用程序。有關更多信息,請參閱 NVIDIA Grace Hopper 編程模型部分。
NVLink 交換機系統
NVIDIA NVLink 交換機系統將第四代 NVIDIA NVLink 技術與新的第三代 NVIDIA NVSwitch 結合在一起。 NVSwitch 的一級可連接多達八個 Grace Hopper 超級芯片,而另一級采用胖樹拓撲結構,可通過 NVLink 連接多達 256 個 Grace Hopper 超級芯片。 Grace Hopper 超級芯片對以高達 900 GB / s 的速度交換數據。
憑借多達 256 個 Grace Hopper 超級芯片,該網絡可提供高達 115.2 TB / s 的全天候帶寬。這是 NVIDIA InfiniBand NDR400 全對全帶寬的 9 倍。

第四代 NVIDIA NVLink 技術使 GPU 線程能夠使用正常內存操作、原子操作和批量傳輸來尋址 NVLink 網絡中所有超級芯片提供的高達 150 TB 的內存。 MPI 、 NCCL 或 NVSHMEM 等通信庫在可用時透明地利用 NVLink 交換機系統。
擴展 GPU 存儲器
NVIDIA Grace Hopper 超級芯片設計用于加速應用程序,其內存占用量非常大,大于單個超級芯片的 HBM3 和 LPDDR5X 內存容量。有關更多信息,請參閱 NVIDIA Grace Hopper 加速應用程序部分。
高帶寬 NVLink-C2C 上的擴展 GPU 內存( EGM )功能使 GPU 能夠高效地訪問所有系統內存。 EGM 在多節點 NVSwitch 連接的系統中提供高達 150 TB 的系統內存。使用 EGM ,可以分配物理內存,以便從多節點系統中的任何 GPU 線程訪問。所有 GPU 都可以以 GPU- GPU NVLink 或 NVLink-C2C 的最低速度訪問 EGM 。
Grace Hopper 超級芯片配置中的內存訪問通過本地高帶寬 NVLink-C2C ,總速度為 900 GB / s 。遠程內存訪問通過 GPU NVLink 執行,根據訪問的內存,還通過 NVLink-C2C 執行(圖 11 )。使用 EGM , GPU 線程現在可以以 450 GB / s 的速度訪問 NVSwitch 結構上的所有可用內存資源,包括 LPDDR5X 和 HBM3 。

NVIDIA HGX Grace Hopper
NVIDIA HGX Grace Hopper 每個節點都有一個 Grace Hoppper 超級芯片,與 BlueField-3 NIC 或 OEM 定義的 I / O 和可選的 NVLink 交換機系統配對。它可以是空氣冷卻或液體冷卻, TDP 高達 1000W 。

NVIDIA HGX Grace Hopper 與 InfiniBand
具有 Infiniband (圖 13 )的 NVIDIA HGX Grace Hopper 非常適合擴展傳統機器學習( ML )和 HPC 工作負載,這些工作負載不受 Infiniband 網絡通信開銷的限制, Infiniband 是可用的最快互連之一。
每個節點包含一個 Grace Hopper 超級芯片和一個或多個 PCIe 設備,如 NVMe 固態驅動器和 BlueField-3 DPU 、 NVIDIA ConnectX-7 NIC 或 OEM 定義的 I / O 。 NDR400 InfiniBand NIC 具有 16x PCIe Gen 5 通道,可在超級芯片上提供高達 100 GB / s 的總帶寬。結合 NVIDIA BlueField-3 DPU ,該平臺易于管理和部署,并使用傳統的 HPC 和 AI 集群網絡架構。
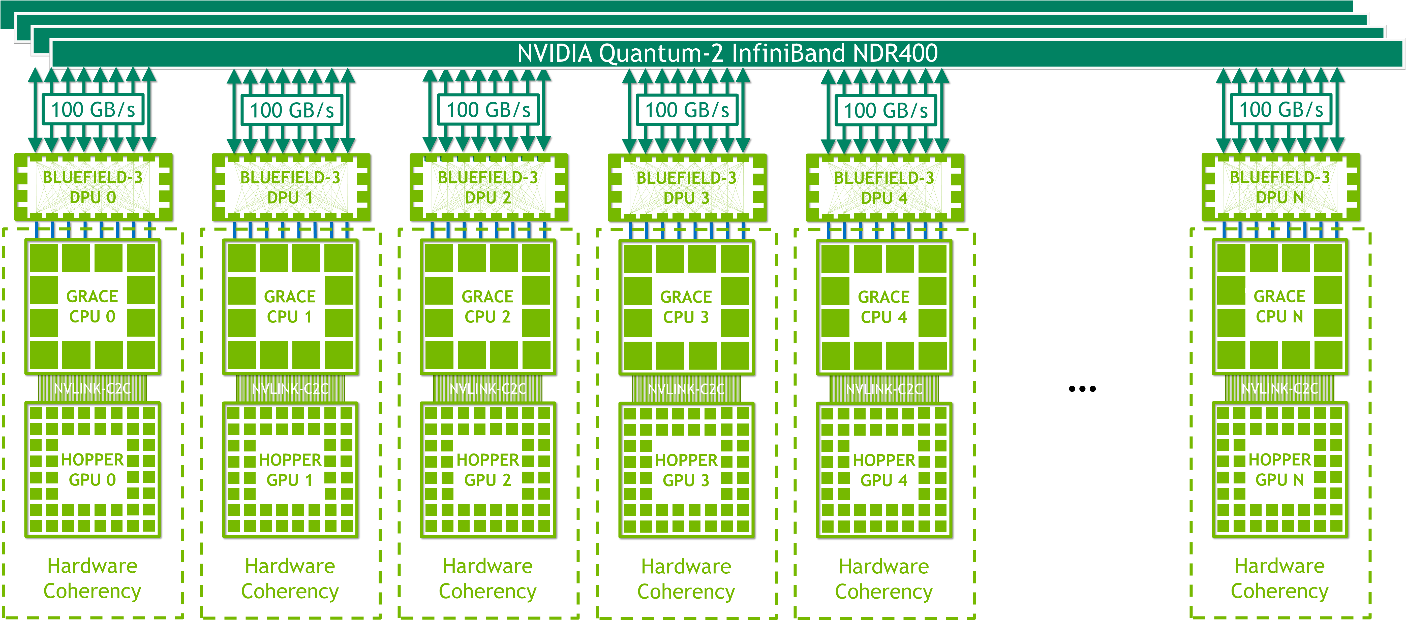
帶 NVLink 開關的 NVIDIA HGX Grace Hopper
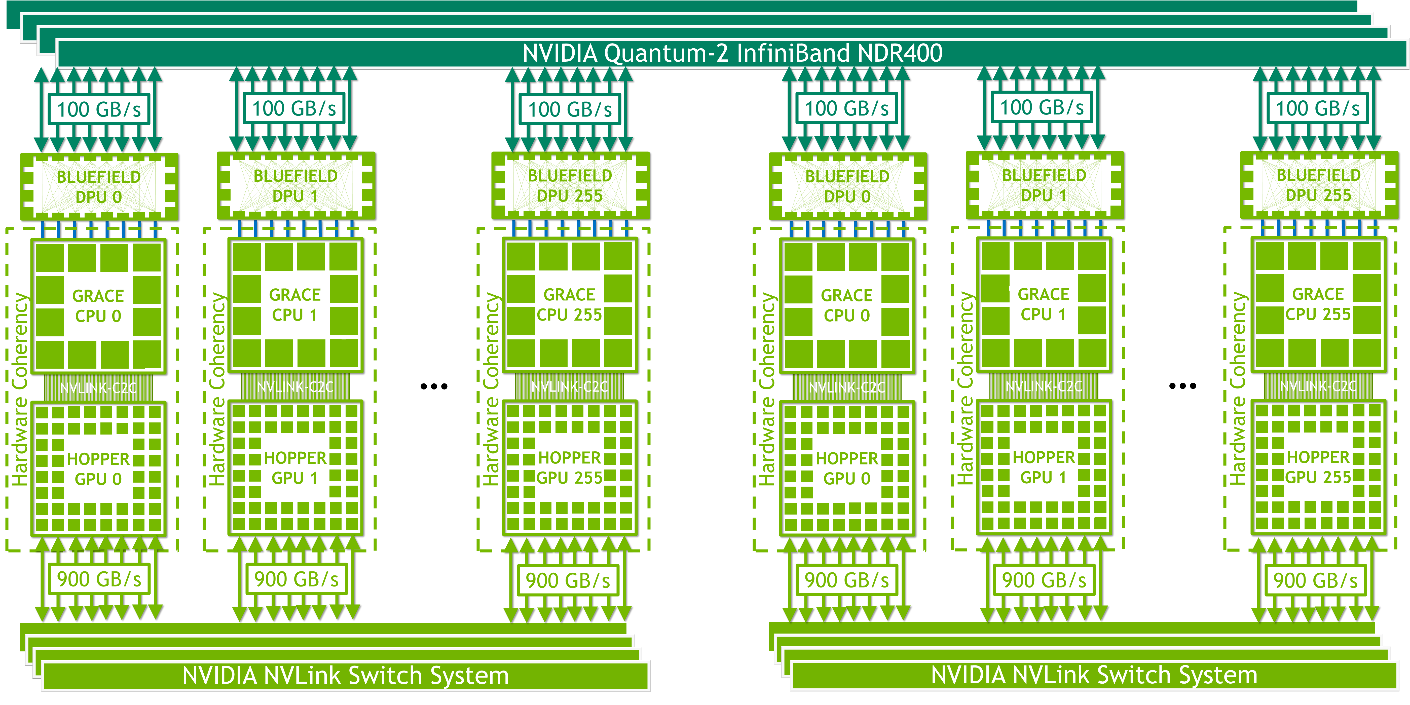
配備 NVLink Switch 的 NVIDIA HGX Grace Hopper 非常適合大規模機器學習和 HPC 工作負載。它使 NVLink 連接域中的所有 GPU 線程能夠在 256- GPU NVLink 連接系統中以每個超級芯片高達 900 GB / s 的總帶寬尋址高達 150 TB 的內存。簡單的編程模型使用指針加載、存儲和原子操作。它的 450 GB / s 全部減少了帶寬,最高可達 115.2 TB / s 的二等分帶寬,使該平臺成為強大擴展世界上最大、最具挑戰性的 AI 訓練和 HPC 工作負載的理想平臺。
NVLink 連接的域通過 NVIDIA InfiniBand 網絡進行網絡連接,例如, NVIDIA ConnectX-7 NIC 或 NVIDIA BlueField-3 數據處理器( DPU )與 NVIDIA Quantum 2 NDR 交換機或 OEM 定義的 I / O 解決方案配對。
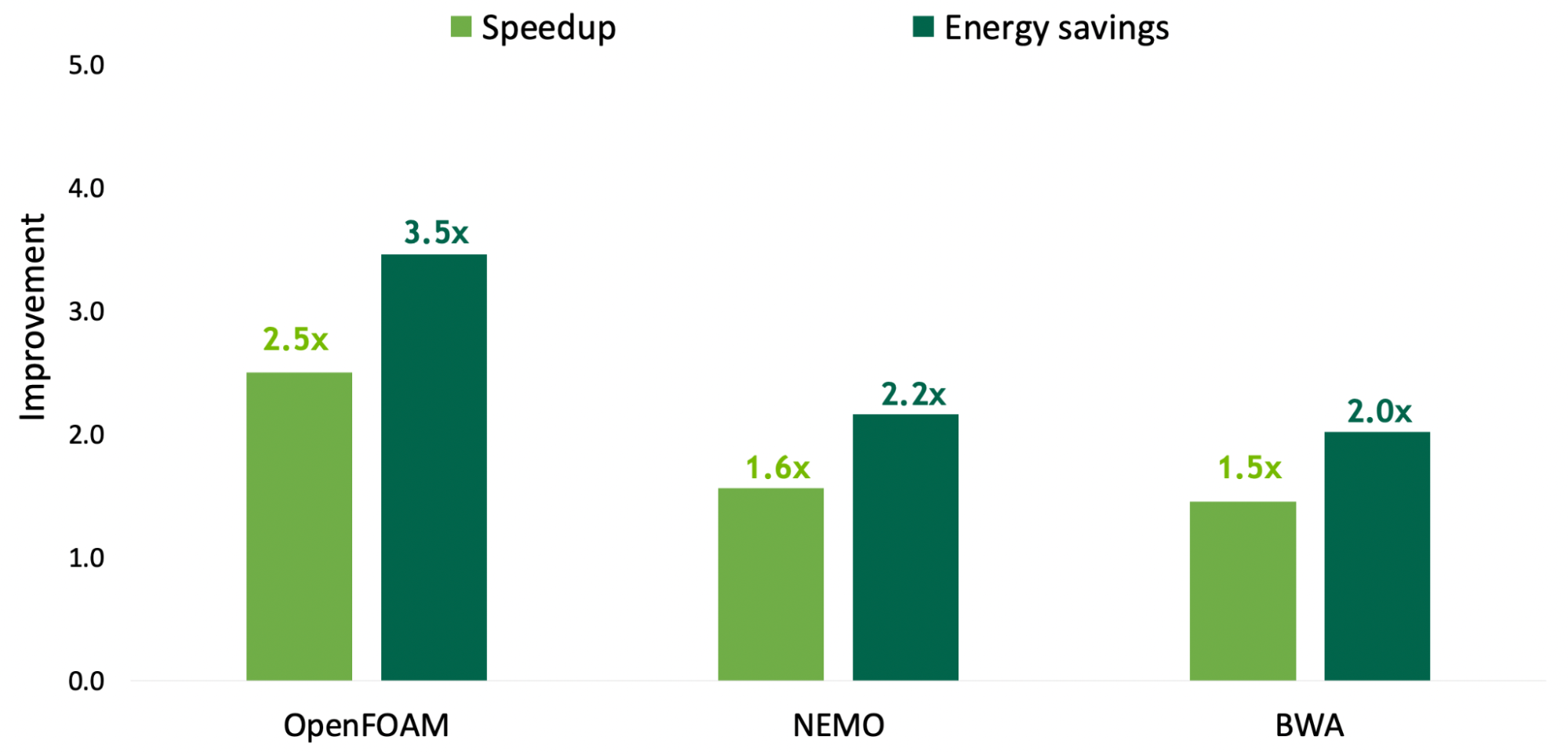
實現性能突破
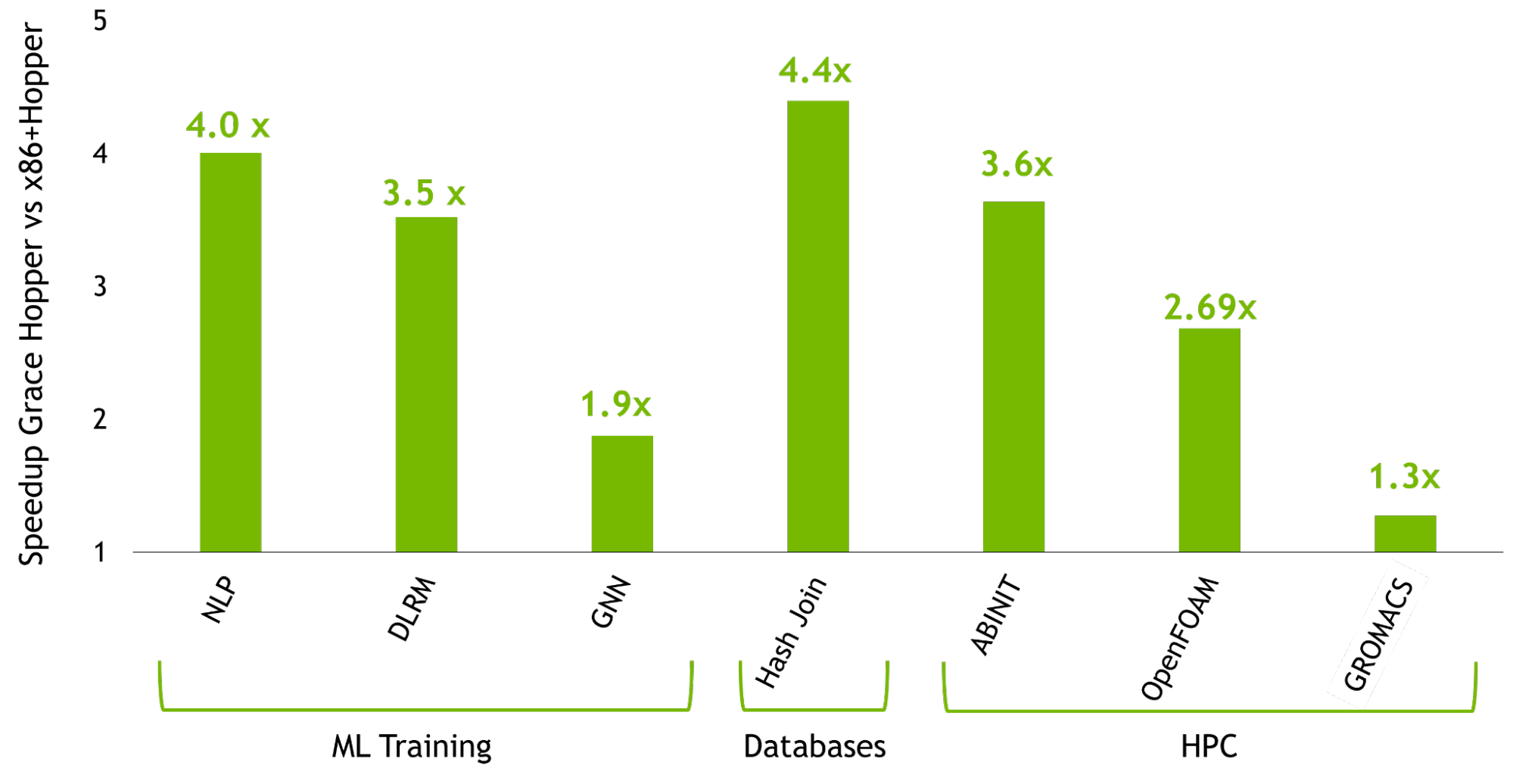
NVIDIA Grace Hopper Superchip Architecture 白皮書詳細介紹了本文中的內容。它將帶您了解 Grace Hopper 是如何實現圖 1 所示的性能突破的,而目前最強大的基于 PCIe 的加速平臺是由 NVIDIA Hopper H100 PCIe GPU 提供支持的。
您是否有適合 NVIDIA Grace Hopper 超級芯片的應用程序?在評論中告訴我們!
致謝
我們要感謝杰克·喬奎特、羅尼·克拉辛斯基、約翰·哈伯德、馬克·胡梅爾、格雷格·帕爾默、瑞安·威爾斯、亞歷克斯·石井、喬納·阿爾本和 為這篇文章做出貢獻的許多 NVIDIA 建筑師和工程師 .
?





