
隨著生成式 AI 模型的持續創新,生成式 AI 在計算應用方面取得了巨大進步,從而大幅增強人類能力。這些模型包括 生成式 AI 模型,例如 大型語言模型 (LLM),用于創作營銷文案、編寫代碼、渲染圖像、作曲和生成視頻等。隨著新模型的不斷出現,所需的計算量也隨之增加。
生成式 AI 的計算強度要求芯片、系統和軟件要卓越。MLPerf 推理是一個基準套件,用于衡量多個熱門深度學習用例的推理性能。最新版本 MLPerf Inference v4.0 加入兩個新工作負載,代表了熱門的現代生成式 AI 用例。其中一個是基于最大的 Meta Lama 2 系列大型語言模型 (LLM) 的 LLM 基準測試,以及另一個是基于 Stable Diffusion XL 穩定漫反射的。
NVIDIA 加速計算平臺利用 NVIDIA H200 Tensor Core GPU。其 TensorRT-LLM 軟件在 NVIDIA H100 Tensor Core GPU 上加速了 GPT-J LLM 的推理。NVIDIA Hopper 架構的 GPU 在數據中心類別的所有 MLPerf 推理工作負載中提供了更高的性能。此外,NVIDIA 在 MLPerf 推理的開放分區中提交了一些內容,展示了其模型和算法的創新。
在本文中,我們將介紹這些創記錄的生成式 AI 推理性能成就背后的眾多全棧技術。
TensorRT-LLM 將 LLM 推理性能提升近三倍
基于 LLM 的服務 (例如聊天機器人) 必須快速響應用戶查詢并具有成本效益,這需要高推理吞吐量。生產推理解決方案必須能夠同時為具有低延遲和高吞吐量的先進 LLM 提供服務。
TensorRT-LLM 是一個高性能開源軟件庫,可在 NVIDIA GPU 上運行最新的 LLM 時提供先進的性能。
MLPerf Inference v4.0 包括兩項 LLM 測試。第一項是上一輪 MLPerf 中引入的 GPT-J,第二項是新添加的 Lama 2 70B 基準測試。使用 TensorRT-LLM 的 H100 Tensor Core GPU 在離線和服務器場景中在 GPT – J 上分別實現了 2.4 倍和 2.9 倍的加速。與上一輪提交的測試相比。TensorRT – LLM 也是 NVIDIA 平臺在 Lama 2 70B 測試中的出色性能的核心。
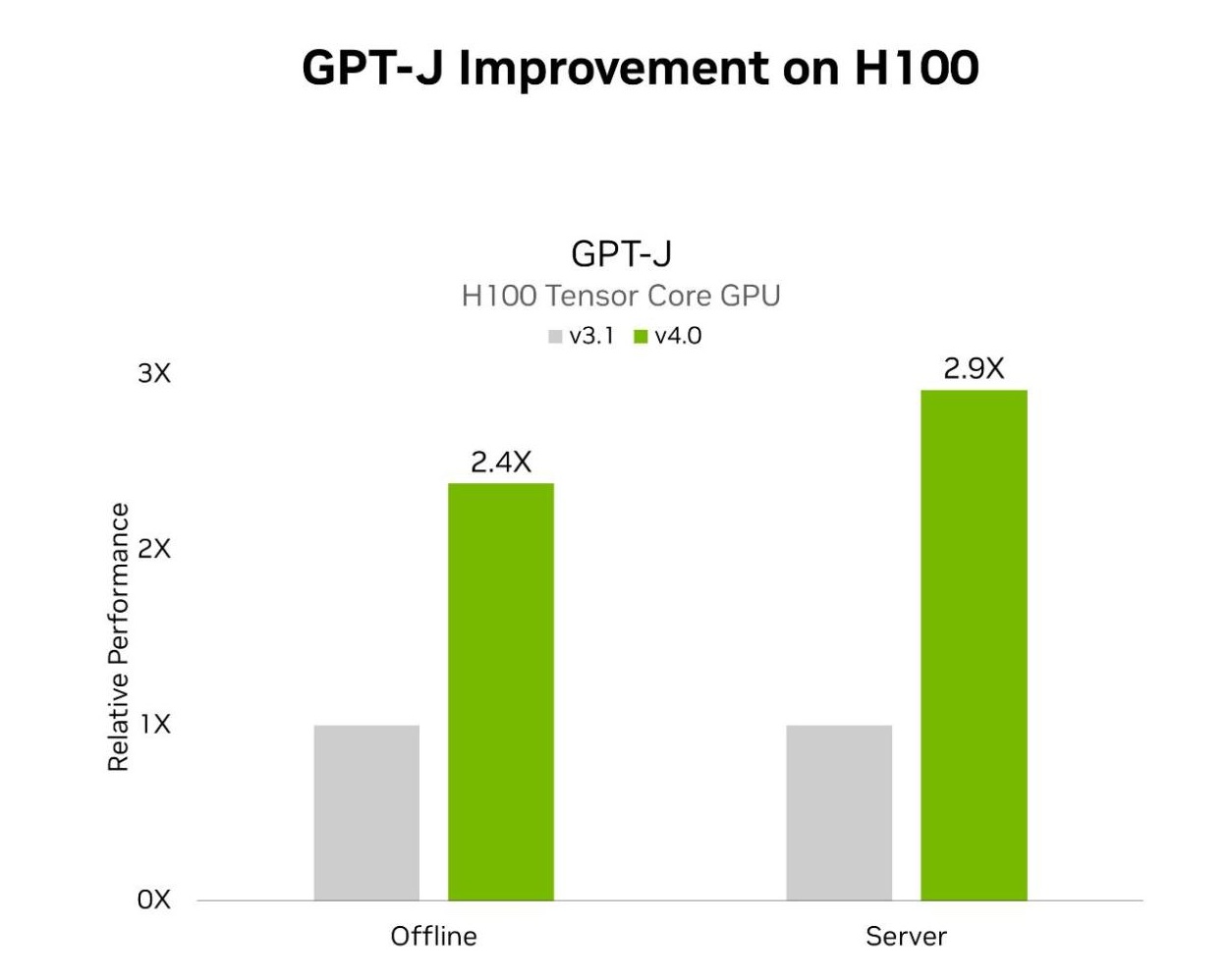
MLPerf Inference v3.1 和 v4.0 數據中心結果于 2024 年 3 月 27 日從 www.mlperf.org 的條目 3.1-0107 和 4.0-0060 中檢索。MLPerf 名稱和徽標是 MLCommons 協會在美國和其他國家地區注冊的注冊和未注冊商標。所有權利保留。嚴禁未經授權使用。有關更多信息,請參閱 www.mlcommons.org。
以下是 TensorRT-LLM 的一些關鍵功能,這些功能實現了出色的性能結果:
- **機上序列批處理** 在 LLM 推理期間提高 GPU 利用率的策略,通過更好地交錯推理請求以及在完成處理并插入新請求后立即分批逐出請求。
- 分頁 KV 緩存 通過將 KV 緩存分成非連續內存塊并將其存儲在其中,并按需分配和移除內存塊,以及在注意力計算期間動態訪問內存塊,從而提高內存消耗和利用率。
- **量化并行** 支持使用 NCCL 在 GPU 和節點之間拆分權重進行通信,以實現大規模高效推理。
- 量化支持 FP8 量化,它利用 NVIDIA Hopper 架構的第四代 Tensor Core 來減少模型大小并提高性能。
- XQA 內核 以高性能實現注意力機制,支持 MHA、MQA 和 GQA,以及波束搜索,從而在給定的延遲預算內顯著提高吞吐量。
有關 TensorRT-LLM 功能的更多詳細信息,請參閱此博文:TensorRT-LLM 如何加速 LLM 推理。
H200 Tensor Core GPU 強效助力 LLM 推理
H200 基于 Hopper 架構,是全球首款使用業內最先進 HBM3e 顯存的 GPU.H200 采用 141 GB 的 HBM3e,顯存帶寬為 4.8 TB/s,與 H100 相比,GPU 顯存增加了近 1.8 倍,GPU 顯存帶寬增加了 1.4 倍。
通過將更大、更快速的顯存和新的定制散熱解決方案相結合,與本輪提交的 H100 相比,H200 GPU 在 Lama 2 70B 基準測試中實現了巨大的性能提升。
HBM3e 實現更高性能
與 H100 相比,H200 的升級 GPU 顯存在兩個重要方面有助于在處理 Lama 2 70B 工作負載時釋放更多性能。
在 MLPerf Lama 2 70B 基準測試中,它無需進行張量并行或管線并行執行,以獲得最佳性能。這減少了通信開銷并提高了推理吞吐量。
其次,與 H100 相比,H200 GPU 具有更高的顯存帶寬,緩解了工作負載中顯存帶寬受限部分的瓶頸,并提高了 Tensor Core 的利用率。這提高了推理吞吐量。
定制冷卻設計進一步提升性能
TensorRT-LLM 中的廣泛優化與 H200 的升級顯存相結合,意味著 H200 上的 Lama 2 70B 執行受到計算性能的限制,而不會受到顯存帶寬或通信瓶頸的限制。
由于 NVIDIA HGX H200 與 NVIDIA HGX H100 兼容,因此它為系統制造商提供了認證系統的能力,以更快地將產品推向市場。正如 NVIDIA MLPerf 在本輪提交的結果所表明的那樣,H200 在與 H100 相同的 700 W 熱設計功耗 (TDP) 下,可提供高達 28%的 Lama 2 70B 推理性能。
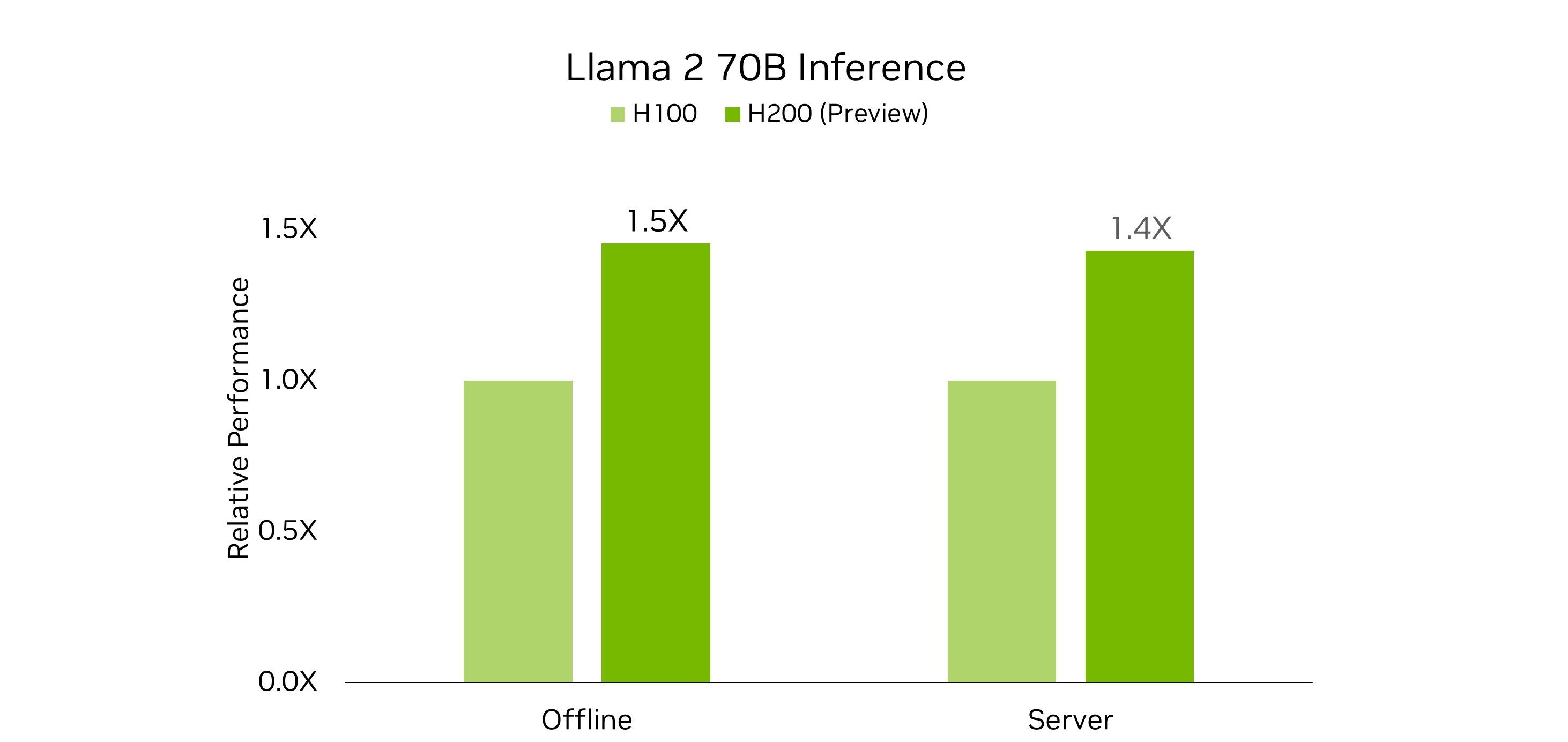
MLPerf Inference v4.0 數據中心結果檢索自 mlperf.org,于 2024 年 3 月 27 日發布。結果來自 4.0-0062 和 4.0-0068。MLPerf 的名稱和徽標為 MLCommons Association 在美國和其他國家/地區的注冊商標和未注冊商標。所有權利保留。未經授權使用受禁止。有關更多信息,請參閱 mlcommons.org。
借助 NVIDIA MGX,系統組裝商可以通過定制冷卻設計為客戶提供更多價值,從而實現更高的 GPU 散熱。在這一輪中, NVIDIA 還提交了使用 H200 的定制散熱設計,使 GPU 能夠在更高的 1000 W TDP 下運行。在運行 Lama 2 70B 基準測試時,這將使服務器和離線場景中的性能分別提高 11%和 12%,與 H100 相比,總加速分別提高 43%和 45%。
為 Stable Diffusion XL 設置性能標準
Stable Diffusion XL 穩定漫反射是以下內容組成的文本轉圖像生成 AI 模型:
- 兩個 CLIP 模型,用于將提示文本轉換為嵌入。
- 由殘差塊 (ResBlocks) 和轉換器組成的 UNet 模型,可在較低分辨率的隱空間對圖像進行迭代降噪。
- 變分自動編碼器 (VAE),可將隱空間圖像解碼為分辨率為 1024 × 1024 的 RGB 圖像輸出。
在 MLPerf Inference v4.0 中,Stable Diffusion XL 用于文本轉圖像測試,根據提供的文本提示生成圖像。
采用 TensorRT 軟件的 NVIDIA GPU 在 MLPerf Inference v4.0 文本轉圖像測試中提供了更高的性能。8-GPU NVIDIA HGX H200 系統 (GPU 配置為 700W TDP) 在服務器和離線場景中分別實現了 13.8 條查詢/秒和 13.7 個樣本/秒的性能。
L40S 是性能超強的通用 NVIDIA GPU,專為 AI 計算、圖形和媒體加速領域的突破性多工作負載性能而設計。Stable Diffusion XL 提交使用配備 8 個 L40S GPU 的系統,在服務器和離線場景中分別展示了 4.9 條查詢/秒和 5 個樣本/秒的性能。

NVIDIA 提出了一種創新方法,將 UNet 中的 ResBlock 和 Transformer 部分量化為 INT8 精度。在 ResBlocks 中,卷積層被量化為 INT8,而在 Transformer 中,查詢鍵值塊和前饋網絡線性層被量化為 INT8. 僅從前八個降噪步驟 (共 20 個) 中收集 INT8 絕對最大值。SmoothQuant 用于量化線性層的激活,克服了將激活量化為 INT8 的挑戰,同時保持原始準確性。
與不屬于 NVIDIA MLPerf 提交內容的 FP16 基準相比,這項工作將 H100 GPU 的性能提升了 20%。
此外,TensorRT 支持擴散模型的 FP8 量化,這將提高性能和圖像質量并即將推出。
開放式劃分創新
除了在 MLPerf Inference 的封閉分區中提交出色性能外, NVIDIA 還在開放分區中提交了幾項提交內容。根據 MLCommons,開放分區“旨在促進創新,并允許使用不同的模型或重新訓練。”
在這一輪中, NVIDIA 提交了公開分割結果,這些結果利用了 TensorRT 中的各種模型優化功能 (例如稀疏化、剪枝和緩存)。這些結果用于 Lama 2 70B、GPT-J 和 Stable Diffusion XL 工作負載,在保持高精度的同時展示了出色的性能。以下小節概述了為這些提交提供支持的創新。
采用結構化稀疏技術的 Llama 2 70B
基于 H100 GPU 的 NVIDIA 開放分割提交展示了使用 結構化稀疏 Hopper Tensor Core 的能力。模型的所有注意力和 MLP 塊的結構化稀疏,并且該過程在訓練完成后完成,無需對模型進行任何微調。
這種稀疏模型具有兩個主要優勢。首先,模型本身縮小了 37%.縮小后的模型和 KVCache 可以完全適應 H100 的 GPU 顯存,從而無需張量并行性。
接下來,使用 2:4 的稀疏 GEMM 內核提高了計算吞吐量,并更高效地利用內存帶寬。與 NVIDIA 封閉除法提交相比,離線場景中相同 H100 系統的總體吞吐量高出 33%.通過這些加速,稀疏模型仍然達到了 MLPerf 封閉除法設置的嚴格的 99.9%準確率目標。與封閉除法中使用的模型相比,稀疏模型在每個樣本中生成的令牌更少,從而縮短了對查詢的響應時間。
帶有剪枝和提煉功能的 GPT-J
在開放除法 GPT-J 提交中,使用了經過剪枝的 GPT-J 模型。這項技術極大地減少了模型中頭層和層的數量,在 H100 GPU 上運行模型時,與封閉除法提交相比,推理吞吐量增加了近 40%.自 NVIDIA 在本輪 MLPerf 中提交結果以來,性能進一步提升了。
然后,使用知識提煉對經過剪枝的模型進行微調,從而實現 98.5%的出色準確率。
使用 DeepCache 的 Stable Diffusion XL
在 Stable Diffusion XL 工作負載的端到端處理中,約有 90%用于使用 UNet 運行迭代降噪步驟。這具有一個由層組成的 U 拓撲結構,其中隱性首先進行下轉換,然后上轉換回原始分辨率。
DeepCache 文檔中介紹了一種技術,建議使用兩種不同的 UNet 結構。第一種是原始的 UNet,在我們的提交中稱為 Deep UNet。第二種是單層 UNet,稱為 Shallow UNet 或 Shallow UNet,它重復使用(或繞過)來自最新 Deep UNet 的中間張量,顯著減少了計算。
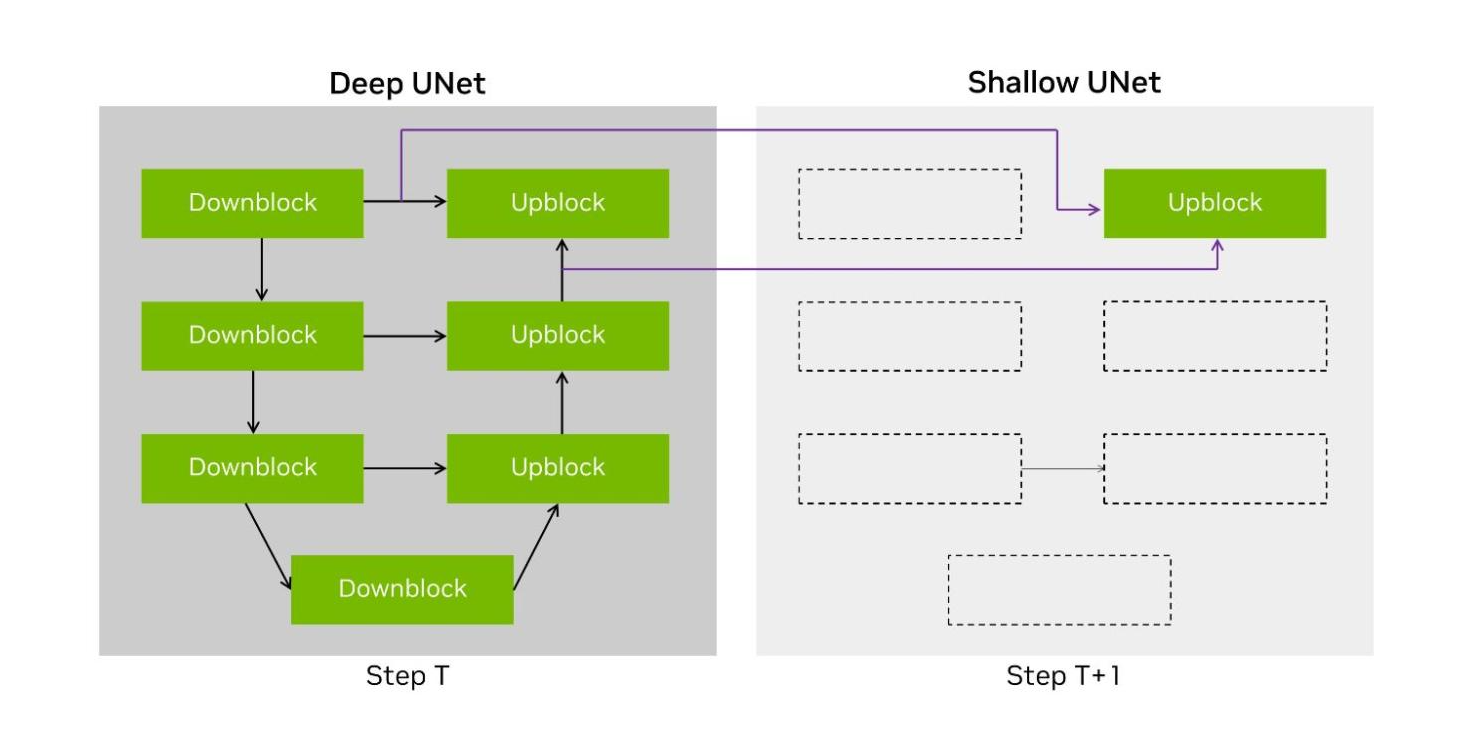
圖 4:使用 Deep UNet 和 Shallow UNet 的 DeepCache 技術說明
NVIDIA 開放分割提交實現了 DeepCache 的變體,我們將兩個輸入緩存到最后一個上轉換層,并在降噪步驟之間交替使用 Deep UNet 和 Shallow UNet.這將運行模型的 UNet 部分所需的計算量減少了一半,在 H100 上將端到端性能提高了 74%。
出色的推理性能
NVIDIA 平臺在 MLPerf Inference v4.0 基準測試中展示了出色的推理性能,而 Hopper 架構可在每個工作負載上實現每個 GPU 的最高性能。
借助 TensorRT-LLM 軟件,H100 在處理 GPT-J 工作負載時實現了出色的性能提升,在短短 6 個月內性能幾乎提升了 3 倍。H200 是全球首款采用 TensorRT – LLM 軟件的 HBM3e GPU,在離線和服務器場景中,為 Lama 2 70B 工作負載提供了創紀錄的推理性能。此外,在首次針對文本轉圖像生成式 AI 進行的 Stable Diffusion XL 測試中, NVIDIA 平臺提供了最高性能。
要重現 NVIDIA MLPerf Inference v4.0 中展示的驚人性能,請參閱 MLPerf 庫。
?





