數字生成的生成式 AI 采用率一直很高。在 2022 年推出 OpenAI 聊天 GPT 的推動下,這項新技術在幾個月內積累了超過 1 億用戶,幾乎推動了各行各業的開發活動激增。
到 2023 年,開發者開始使用 Meta、Mistral、Stability 等公司的 API 和開源社區模型創建 POC。
進入 2024 年后,企業組織正將注意力轉向大規模生產部署,其中包括將 AI 模型連接到現有企業基礎設施、優化系統延遲和吞吐量、日志記錄、監控和安全性等。這種生產路徑既復雜又耗時,需要專門的技能、平臺和流程,尤其是大規模部署。
NVIDIA NIM 是?NVIDIA AI Enterprise 的一部分,為開發 AI 驅動的企業應用程序和在生產中部署 AI 模型提供了簡化的路徑。
NIM 是一套經過優化的云原生微服務,旨在縮短上市時間,并簡化生成式 AI 模型在云、數據中心和 GPU 加速工作站的任何位置的部署。它使用行業標準 API,抽象化 AI 模型開發和生產包裝的復雜性,從而擴展開發者池。
用于優化 AI 推理的 NVIDIA NIM
NVIDIA NIM 旨在彌合復雜的 AI 開發環境與企業環境的運營需求之間的差距,使 10 到 100 倍的企業應用開發者能夠為其公司的 AI 轉型做出貢獻。
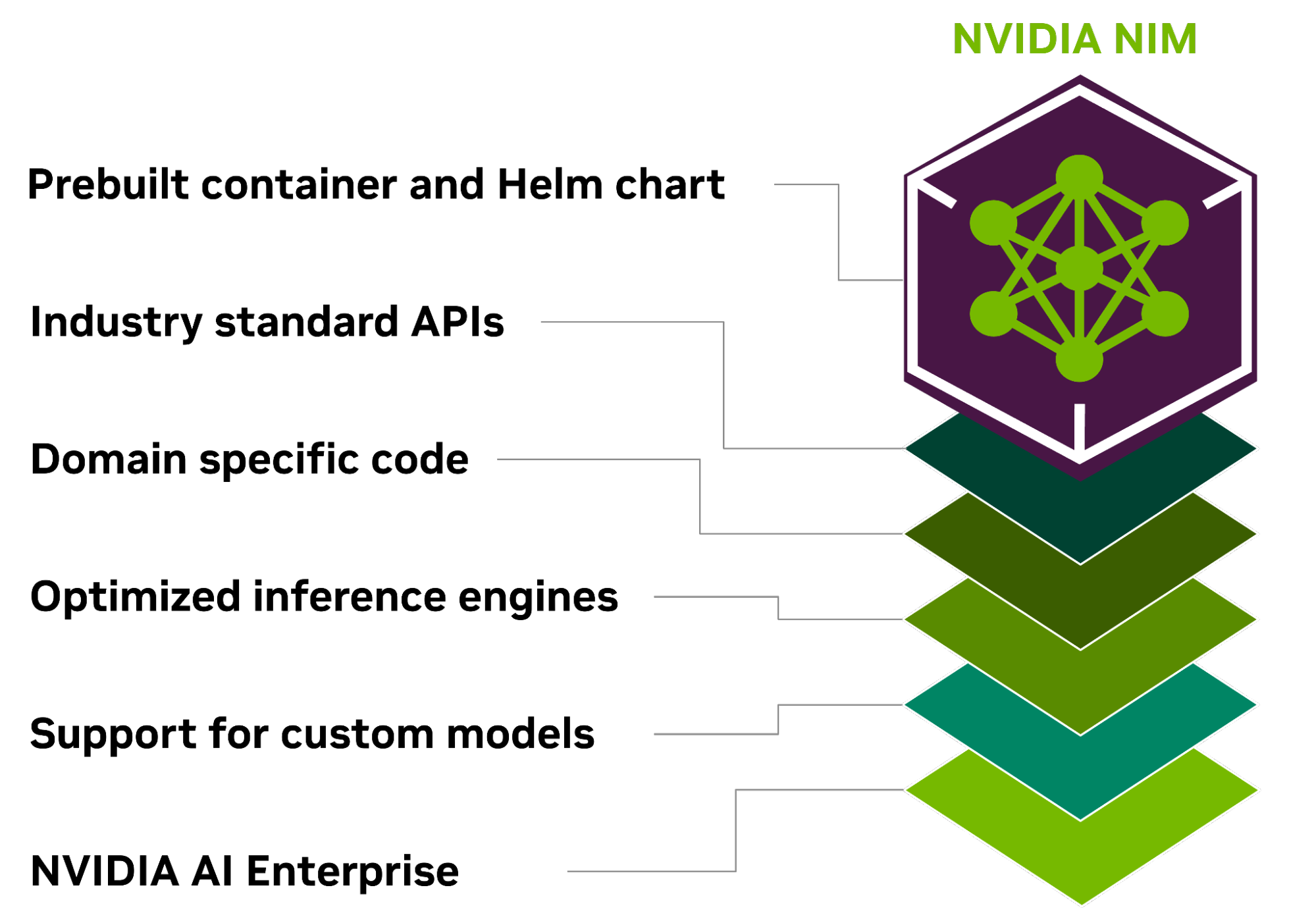
NIM 的一些核心優勢包括以下內容。
隨時隨地部署
NIM 專為可移植性和可控性而構建,支持跨各種基礎設施 (從本地工作站到云再到本地數據中心) 進行模型部署。其中包括 NVIDIA DGX、 NVIDIA DGX 云、 NVIDIA 認證系統、 NVIDIA RTX 工作站和 PC。
預構建的容器和 Helm Chart 打包了優化模型,并在不同的 NVIDIA 硬件平臺、云服務提供商和 Kubernetes 發行版中進行了嚴格驗證和基準測試。這支持所有 NVIDIA 驅動的環境,并確保組織可以在任何地方部署其生成式 AI 應用,同時保持對其應用及其處理的數據的全面控制。
使用行業標準 API 進行開發
開發者可以通過符合每個領域行業標準的 API 訪問 AI 模型,從而簡化 AI 應用的開發。這些 API 與生態系統中的標準部署流程兼容,使開發者能夠快速更新其 AI 應用 (通常只需 3 行代碼)。這種無縫集成和易用性有助于在企業環境中快速部署和擴展 AI 解決方案。
利用特定領域的模型
NIM 還通過幾個關鍵功能滿足了對特定領域解決方案和優化性能的需求。它包含特定于領域的 NVIDIA CUDA 庫,以及為語言、語音、視頻處理、醫療健康等各個領域量身定制的專用代碼。這種方法可確保應用程序準確無誤并與其特定用例相關。
在優化的推理引擎上運行
NIM 針對每個模型和硬件設置利用經過優化的推理引擎,在加速基礎設施上提供盡可能好的延遲和吞吐量。這降低了在擴展推理工作負載時運行推理工作負載的成本,并改善了最終用戶體驗。除了支持優化的社區模型外,開發者還可以通過使用從未離開數據中心邊界的專有數據源對模型進行對齊和微調,從而實現更高的準確性和性能。
支持企業級 AI
作為 NVIDIA AI Enterprise 的一部分,NIM 采用企業級基礎容器構建,通過功能分支、嚴格的驗證、通過服務級別協議提供的企業級支持以及針對 CVE 的定期安全更新,為企業 AI 軟件提供堅實的基礎。全面的支持結構和優化功能突出了 NIM 作為在生產環境中部署高效、可擴展和定制的 AI 應用的關鍵工具的作用。
加速 AI 模型隨時可供部署
支持多種 AI 模型,包括社區模型 NVIDIA AI 基礎模型 和 NVIDIA 合作伙伴提供的定制 AI 模型。NIM 支持跨多個領域的 AI 用例,包括 大型語言模型 (LLM)、視覺語言模型 (VLM),以及用于語音、圖像、視頻、3D、藥物研發、醫學成像等的模型。
開發者可以使用 NVIDIA 托管的云 API 測試新的生成式 AI 模型,或者通過下載 NIM 來自行托管模型,并在主要云提供商或本地使用 Kubernetes 快速部署,以減少開發時間、復雜性和成本。
NIM 微服務通過打包算法、系統和運行時優化并添加行業標準 API 來簡化 AI 模型部署流程。這使開發者能夠將 NIM 集成到其現有應用程序和基礎設施中,而無需大量定制或專業知識。
借助 NIM,企業可以優化其 AI 基礎架構,以更大限度地提高效率和成本效益,而無需擔心 AI 模型開發的復雜性和容器化。在加速 AI 基礎架構的基礎上,NIM 有助于提高性能和可擴展性,同時降低硬件和運營成本。
對于希望為企業應用程序定制模型的企業,NVIDIA 提供微服務,以便跨不同領域定制模型。NVIDIA NeMo 使用專有數據為 LLM、語音 AI 和多模態模型提供微調功能。NVIDIA BioNeMo 通過越來越多的生成生物學化學和分子預測模型集合加速藥物研發。NVIDIA Picasso 通過 Edify 模型實現更快的創意工作流程。這些模型在視覺內容提供商的許可庫中進行訓練,從而能夠部署自定義的生成式 AI 模型,以創建視覺內容。
NVIDIA NIM 入門
NVIDIA NIM 入門非常簡單。在 NVIDIA API 目錄,開發者可以訪問各種 AI 模型,這些模型可用于構建和部署自己的 AI 應用。
通過圖形用戶界面直接在目錄中開始原型設計,或直接與 API 免費交互。要在基礎設施上部署微服務,只需注冊 NVIDIA AI Enterprise 90 天評估許可證,并按照以下步驟操作。
- 從 NVIDIA NGC 下載要部署的模型。在本示例中,我們將下載為單個 A100 GPU 構建的 Lama-2 7B 模型版本。
ngc registry model download-version "ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01"如果您使用的是其他 GPU,則可以使用 ngc 注冊表模型列表“ohlfw0olaadg/ea-participants/llama-2 -7b:”列出模型的可用版本
2.將下載的構件解壓到模型庫中:
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gz
3.使用所需模型啟動 NIM 容器:
docker run --gpus all --shm-size 1G -v $(pwd)/model-store:/model-store --net=host nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01 nemollm_inference_ms --model llama-2-7b --num_gpus=14.部署 NIM 后,您可以開始使用標準 REST API 發出請求:
import requestsheaders = { 'accept': 'application/json', 'Content-Type': 'application/json'}data = { 'model': 'llama-2-7b', 'prompt': "The capital of France is called", 'max_tokens': 100, 'temperature': 0.7, 'n': 1, 'stream': False, 'stop': 'string', 'frequency_penalty': 0.0}response = requests.post(endpoint, headers=headers, json=data)print(response.json()) |
NVIDIA NIM 是一款功能強大的工具,可以幫助組織加速生產級 AI 之旅。立即開始您的 AI 之旅。
?