
今天,NVIDIA 宣布推出 KAI Scheduler 的開源版本,這是一種 Kubernetes-native GPU 調度解決方案,現已在 Apache 2.0 許可證下提供。KAI Scheduler 最初在 Run:ai 平臺中開發,現在可供社區使用,同時繼續作為 NVIDIA Run:ai 平臺 的一部分打包和交付。該計劃強調了 NVIDIA 致力于推動開源和企業 AI 基礎設施的發展,打造積極協作的社區,鼓勵貢獻、反饋和創新。
在本文中,我們概述了 KAI Scheduler 的技術細節,強調了其對 IT 和 ML 團隊的價值,并解釋了調度周期和操作。
KAI 調度程序的優勢
管理 GPU 和 CPU 上的 AI 工作負載帶來了傳統資源調度器通常無法解決的一系列挑戰。調度程序專為解決以下問題而開發:
- 管理不斷變化的 GPU 需求
- 減少計算訪問的等待時間
- 資源保障或 GPU 分配
- 無縫連接 AI 工具和框架
管理不斷變化的 GPU 需求
AI 工作負載可能會迅速變化。例如,您可能只需要一個 GPU 來進行交互式工作 (例如,用于數據探索) ,然后突然需要多個 GPU 來進行分布式訓練或多項實驗。傳統的調度程序難以應對這種可變性。
KAI 調度程序不斷重新計算公平份額值,并實時調整配額和限制,自動匹配當前的工作負載需求。這種動態方法有助于確保高效的 GPU 分配,而無需管理員不斷進行手動干預。
減少計算訪問的等待時間
對于 ML 工程師來說,時間至關重要。調度程序通過將 gang scheduling、GPU sharing 和 hierarchical queuing system 相結合來減少等待時間,使您能夠提交批量 jobs,然后離開,確信 tasks 將在資源可用時立即啟動,并符合 priorities 和 fairness。
為了進一步優化資源使用,即使在需求波動的情況下,調度程序也對 GPU 和 CPU 工作負載采用了兩種有效的策略:
- Bin-packing 和整合:通過消除資源碎片化 (將較小的任務打包成部分使用的 GPU 和 CPU) ,并通過在節點之間重新分配任務來解決節點碎片化問題,從而更大限度地提高計算利用率。
- 擴散 :在節點或 GPU 和 CPU 之間均勻分布工作負載,以最大限度地減少每節點負載,并最大限度地提高每個工作負載的資源可用性。
資源保障或 GPU 分配
在共享集群中,一些研究人員在早期獲得的 GPU 數量超過了必要數量,以確保始終可用。這種做法可能會導致資源未得到充分利用,即使其他團隊仍有未使用的配額。
KAI 調度程序通過執行資源保證來解決這一問題。它可確保 AI 從業者團隊獲得分配的 GPU,同時動態地將空閑資源重新分配給其他工作負載。這種方法可以防止資源占用,并提高集群的整體效率。
無縫連接 AI 工具和框架
將 AI 工作負載與各種 AI 框架連接起來可能非常困難。傳統上,團隊需要通過一系列手動配置來將工作負載與 Kubeflow、Ray、Argo 和 Training Operator 等工具綁定在一起。這種復雜性會延遲原型設計。
KAI Scheduler 通過內置的 podgrouper 來解決這一問題,該程序可自動檢測并連接這些工具和框架,從而降低配置復雜性并加速開發。

核心調度實體
KAI Scheduler 有兩個主要實體:podgroups 和 queues。
Pod 組
Pod 組是用于調度的原子單元,表示必須作為單個單元執行的一個或多個相互依賴的 Pod,也稱為 gang scheduling 。這一概念對于分布式 AI 訓練框架如 TensorFlow 或 PyTorch 至關重要。
以下是 Podgroup 的關鍵屬性:
- 最低成員數 :指定必須一起調度的 pod 的最低數量。如果所有成員均不可用所需資源,則 pod 組將保持待處理狀態。
- 隊列關聯 :每個 podgroup 都與特定的調度隊列關聯,并將其與更廣泛的資源分配策略關聯。
- 優先級類: 確定相對于其他 podgroups 的調度順序,從而影響作業優先級。
隊列
隊列是實現資源公平性的基礎實體。每個隊列都有指導其資源分配的特定屬性:
- 配額:保證向隊列分配的基準資源分配(Quota)。
- 超額配額權重: 影響所有隊列中超出基準配額的額外剩余資源的分配方式。
- 限制: 定義隊列可以消耗的最大資源,例如 GPU、DPU 等。
- 隊列優先級 :確定相對于其他隊列的調度順序,從而影響隊列優先級。
架構和調度周期
調度程序的核心是持續捕獲 Kubernetes 集群的狀態、計算最優資源分配并應用有針對性的調度操作。

該過程分為以下階段:
- 集群快照
- 資源分配和公平分配計算
- 調度操作
集群快照
調度周期始于捕獲 Kubernetes 集群的完整快照。在此階段,系統會記錄節點、pod 組和隊列的當前狀態。
Kubernetes 對象可轉換為內部數據結構,從而防止中期不一致,并確保所有調度決策均基于集群的穩定視圖。
資源分配和公平分配計算
有了準確的快照,就可以通過資源分割算法為每個調度隊列計算公平份額。該算法的結果是一個數值,該值表示隊列應獲得的最佳資源量,以最大限度地提高集群中所有隊列之間的公平性。
除法算法具有以下階段:
- 當之無愧配額: 每個調度隊列最初都會分配與其基準配額(baseline quota)相等的資源。這可保證每個部門、項目或團隊都能獲得應有的最少資源。
- 超額配額 :任何剩余資源將按照超出配額權重的比例分配給未滿足要求的隊列。這種迭代過程會微調每個隊列的公平比例,動態適應工作負載需求。
調度操作
計算公平份額后,調度程序會應用一系列有針對性的操作,使當前分配與計算出的最佳狀態保持一致:
- 分配 :待處理作業的評估基于分配與公平分配比率。適合可用資源的作業會立即綁定,而需要當前釋放資源的作業則會排隊等待流水線分配。
- 整合:對于訓練工作負載,調度程序會構建剩余待處理訓練作業的有序隊列。 它會對這些作業進行迭代,并嘗試通過將當前分配的 pods 移動到其他節點來分配它們。此過程可最大限度地減少資源碎片化,為待處理作業釋放連續塊。
- 回收: 為確保公平性,調度程序可識別消耗超過合理比例的隊列。然后,它根據定義明確的策略驅逐選定的作業,確保服務不足的隊列獲得必要的資源。
- 搶占先機 :在同一隊列中,低優先級作業可以優先用于高優先級的待處理作業,確保關鍵工作負載不會因資源爭奪而資源乏。
示例場景
設想一個集群有三個節點,每個節點配備八個 GPU,總共 24 個 GPU。目前正在進行兩個項目:project-a 和 project-b。它們分別與 queue-a (中優先級隊列) 和 queue-b (高優先級隊列) 相關聯。假設所有隊列均在公平分配范圍內。圖 3 顯示了當前狀態。

- 節點 1: 訓練作業 1 使用高優先級隊列中的四個 GPU,訓練作業 2 使用兩個 GPU。
- 節點 2: 訓練任務 3 使用六個 GPU。
- 節點 3:交互式作業 (包括數據探索或腳本調試) 使用 5 個 GPU。
現在有兩個待處理的作業提交到隊列中 (圖 4) :
- 訓練作業 A 需要在單個節點上使用四個連續的 GPU。
- 訓練作業 B 需要向高優先級隊列提交三個連續的 GPU。

分配階段
調度程序按優先級對待處理作業進行排序。在本例中,Training Job B 會被優先處理,因為其隊列在緊急程度方面排名較高。當然,作業訂購流程比簡單的優先級排序更復雜。調度程序使用高級策略來確保公平性和效率。
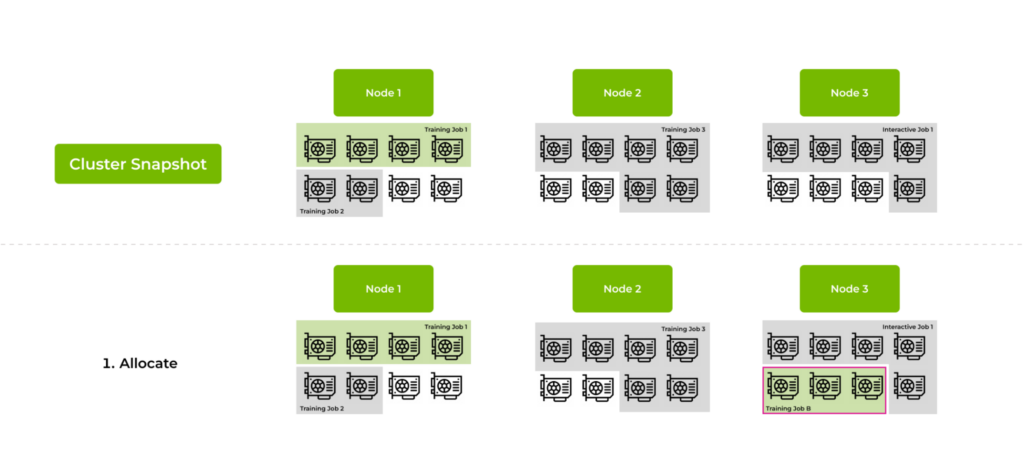
- 對于訓練作業 B,節點 3 符合資格,因為它有三個連續的免費 GPU。調度程序將訓練作業 B 綁定到節點 3,節點 3 將完全占用。
- 接下來,調度程序嘗試分配訓練任務 A。但是,沒有一個節點提供四個連續的免費 GPU。
鞏固階段
由于無法通過分配操作來調度 Training Job A,因此調度程序進入整合階段。它會檢查節點,確定是否可以重新分配正在運行的 pods,以形成用于 Training Job A 的連續塊。

- 在節點 1 中,除了 Training Job 1 (由于優先級較高,必須保持不變) 之外,Training Job 2 占用兩個 GPUs。調度程序會將 Training Job 2 從節點 1 遷移到節點 2。
- 此次整合后,節點 1 的可用 GPU 數量從兩個增加到四個連續的 GPU。
- 借助這種新布局,Training Job A 現在可以分配到 Node 1,從而滿足四個連續的 GPU 的要求。
在這種情況下,整合行動已經足夠了,既不需要 reclaim,也不需要 preempt。但是,如果隊列中有一項額外的待處理作業低于其 fair share,且沒有可用的整合路徑,則調度程序的 reclaim 或 preempt 操作將開始執行,即從過度分配的隊列或同一隊列中的低優先級作業中回收資源,以恢復平衡。
狀態更新
隊列的狀態會更新,并且整個周期會從頭開始,以確保日程安排能夠跟上新工作負載的發展。
社區協作
KAI 調度程序 不僅僅是一個原型。它是 NVIDIA Run:ai 平臺 核心的強大引擎,受到許多企業的信任,并為關鍵的 AI 運營提供支持。憑借其可靠的跟蹤記錄,KAI 調度程序為 AI 工作負載編排設定了黃金標準。
我們邀請企業、初創公司、研究實驗室和開源社區在您自己的環境中試驗 scheduler,并貢獻 learnings。
加入我們的 /NVIDIA/KAI-scheduler GitHub 資源庫,為項目添加一顆星,進行安裝,并分享您的真實體驗。在我們不斷突破 AI 基礎架構的極限時,您的反饋對我們來說非常寶貴。
KubeCon 2025
NVIDIA 很高興參加 4 月 1 日至 4 日在英國倫敦舉行的 KubeCon 。歡迎在 S750 展位與我們互動,進行實時對話和演示。有關我們工作的更多信息,包括我們的 16 場演講,請參閱 NVIDIA 在 KubeCon 上的會議。
?






