
NVIDIA 開發的語音和翻譯 AI 模型正在推動性能和創新的發展。NVIDIA Parakeet 自動語音識別 (ASR) 模型系列以及 NVIDIA Canary 多語種、多任務 ASR 和翻譯模型在 Hugging Face 開放 ASR 排行榜 上表現出色。此外,多語種 P-Flow 基于文本轉語音 (TTS) 的模型在 LIMMITS 的 24 項挑戰 中取得了優異成績,使用簡短的音頻片段將說話者的聲音合成為 7 種語言。
本文詳細介紹了其中一些出色的模型如何在語音和翻譯 AI (從語音識別到自定義語音創建) 領域開辟新天地。
NVIDIA Parakeet 語音識別模型
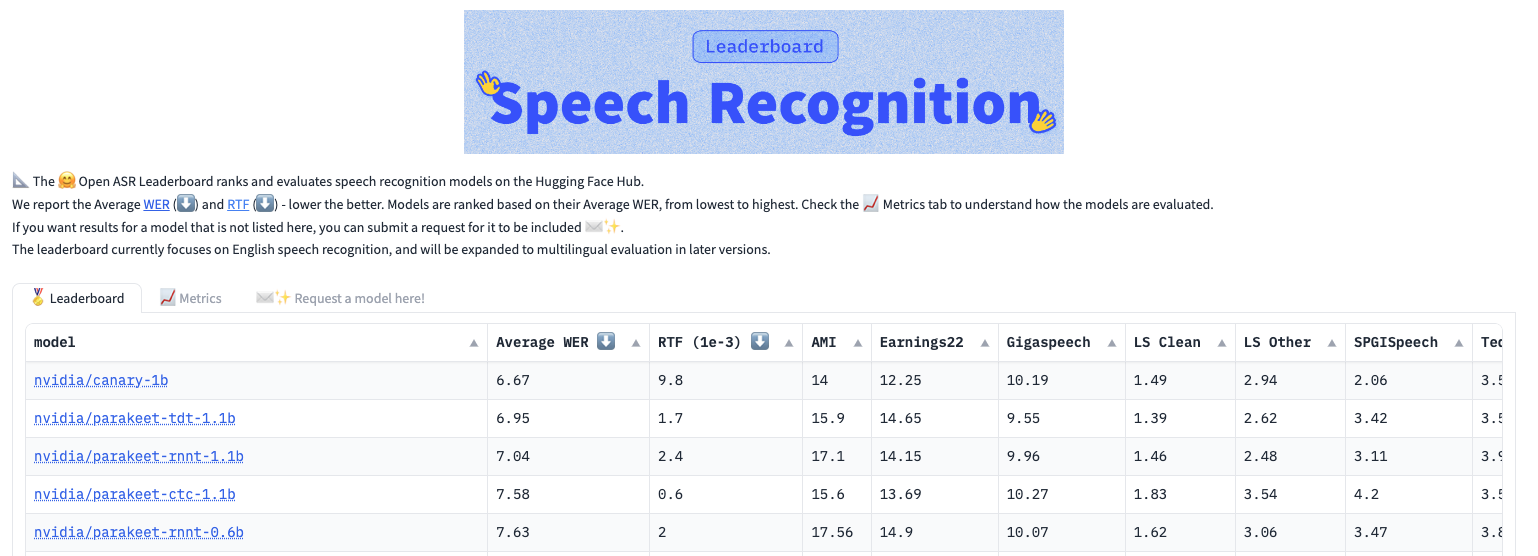
NVIDIA Parakeet 模型系列包括?Parakeet CTC 1.1 B,?Parakeet CTC 0.6 B,?Parakeet RNNT 1.1 B,?Parakeet RNNT 0.6 B?以及?Parakeet-TDT 1.1 B。這些模型提供可靠的英語語音轉錄,并針對不同的客戶應用、準確性、速度和其他要求提供各種選項。這些模型有兩種大小:6 億個和 11 億個參數。
Parakeet 模型的主要優勢包括:
- 高準確性在不同音頻來源和領域提供出色的詞錯誤率(WER)。
- 推理速度快使用 Parakeet CTC 1.1 B、Parakeet TDT 1.1 B 和 Parakeet RNN-T 1.1 B 時,可在一小時內完成 1336 小時的音頻轉錄。請注意,這些測量是在 Hugging Face 排行榜評估之外,使用額外的算法和 CUDA 級優化進行的。
- 出色的噪音魯棒性到背景語音和非語音片段。
- 無縫集成和自定義:由于模型提供了即用型的預訓練檢查點,因此可以輕松地部署推理和微調任務。
Parakeet CTC 和 RNNT 模型的有效性在于使用快速變形器 (FC) 編碼器、遞歸神經網絡傳感器 (RNNT) 和連接主義時序分類 (CTC) 解碼器進行端到端訓練。有關更多詳細信息,請參閱 研究用于長格式音頻轉錄的端到端 ASR 架構 和 具有線性可擴展注意力的快速變形器,可實現高效語音識別。
用于增強語音識別的 Parakeet-TDT 模型
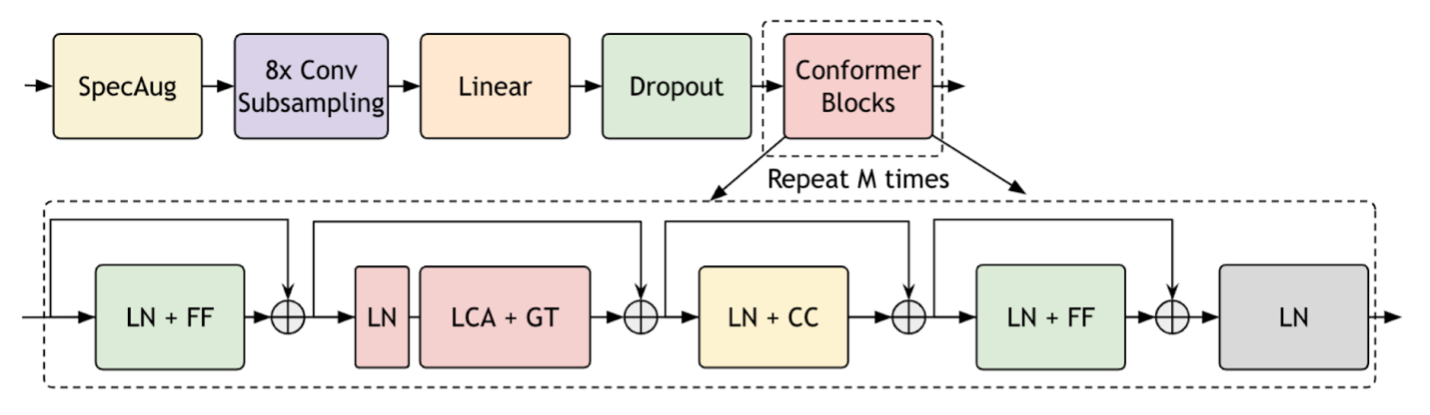
我們發布的 Parakeet-TDT (令牌和持續時間傳感器) 11 億 模型在 Parakeet 系列中表現出色,它在轉錄英語口語時實現了最佳準確性。此外,根據 Hugging Face 排行榜的評估,該模型的運行速度比排名第二的 Parakeet 模型快 64%。
Parakeet-TDT 1.1 B 在速度和準確性方面表現優異,這得益于其 TDT 模型架構,這是一種由 NVIDIA 開發的新型序列建模架構。如需了解更多信息,請參閱 通過聯合預測令牌和持續時間來高效進行序列轉導。
Parakeet-TDT 1.1 B 將令牌和持續時間預測解,并使用持續時間輸出跳過大多數空白預測。與傳統的傳感器模型相比,在識別過程中減少浪費性計算可顯著加速推理,并增強對雜語音的可靠性。
Canary 多語種語音識別和翻譯模型
Canary 1B 是一個多語言多任務模型,在多個基準測試上表現出色。它能夠轉錄英語、德語、法語和西班牙語的語音,無論是否有標點符號和大寫(PnC)。它還支持德語、法語和西班牙語之間的雙向英語翻譯。Canary 的平均 WER 為 6.67%,這一表現遠超目前所有其他模型,并在 Hugging Face 開放 ASR 排行榜 上名列前茅。
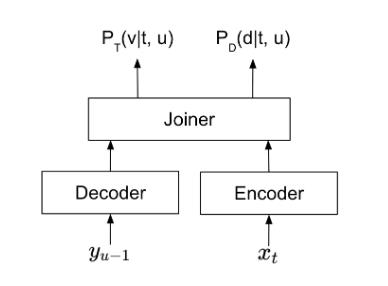
Canary 是一種基于多項創新而構建的編碼器 – 解碼器模型。編碼器是一種快速的構象器,與構象器編碼器相比,它已優化,可節省大約 3 倍的計算量和大約 4 倍的內存。
Canary 編碼器處理音頻的方式是對數梅爾頻譜圖,而 Transformer 解碼器則以自動回歸的方式生成輸出文本標記。系統通過使用獨特的標記來控制 Canary 是執行轉錄還是翻譯。Canary 還包括連接的標記器,這使得對輸出標記空間進行顯式控制成為可能。想要了解更多信息,請參閱 基于連接標記器的代碼交換語音識別和語言識別統一模型。
用于自定義語音創建的 P-Flow
NVIDIA 在 LIMMITS 的 24 小時語音挑戰賽中奪冠,利用 P-Flow 零射 TTS 模型為揚聲器創建定制的高質量個性化語音。P-Flow 可以使用短至 3 秒的語音提示。零射是指生成具有模型訓練數據中未包含的揚聲器語音特征的語音。P-Flow 模型創建的語音與語音提示中的語音相匹配,并且在人類肖像和語音相似性方面,與先進的同類產品相比,更受歡迎。
P-Flow 由兩部分組成:用于說話者語音適應的語音提示文本編碼器,以及用于快速、高質量語音合成的流匹配生成式解碼器。編碼器使用語音提示和文本輸入來生成說話者特定的文本表示。解碼器使用這種說話者特定的文本表示來合成高質量的個性化語音,其速度遠超過實時語音。如需了解詳情,請參閱 P-Flow:通過語音提示實現快速且數據高效的零樣本 TTS。
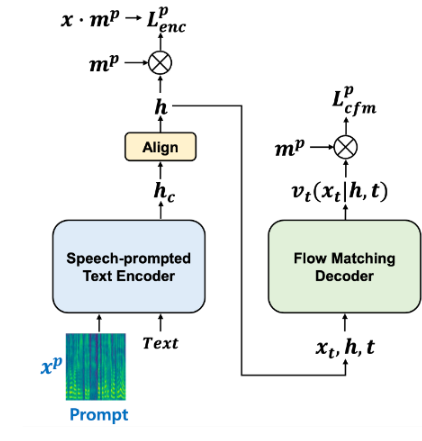
P-Flow 無需超大型數據集、復雜訓練設置、表示量化步驟、預訓練任務或慢自回歸公式,即可創建高質量語音。
在語音挑戰賽中, NVIDIA 團隊將 P-Flow 的零樣本 TTS 功能從其原始語言英語擴展到額外的七種印度語言。這有效地創建了一個多語言 TTS 系統,以便在 3 秒的語音提示下,不可見的說話者可以使用帶有本地口音的七種目標語言中的任何一種。
以下示例展示了 NVIDIA 構建的基于 P-Flow 的多語種 TTS.首先是 Kannada 人的 3 秒鐘語音樣本,該模型產生的聲音質量與本地印地語和英語口音相同。
輸入
輸入的內容是以 Kannada 為母語的人的 3 秒鐘樣本,他說:“得益于他們推動 AI 發展的工作,Akshit Arora 和 Rafael Valle 有朝一日可以用自己的母語與配偶的家人交談。”
輸出
輸出是以印地語和英語提供的聲音相似的合成語音讀取輸入文本。
印地語:
英語:
結束語
NVIDIA 的語音和翻譯 AI 模型正在推動性能和創新的發展。借助 RNNT 和 CTC 變體,Parakeet 模型系列提供了一系列選項,可平衡準確性和速度,以滿足不同的部署需求。TDT 模型將出色的準確性與前所未有的速度相結合,樹立了新的基準,集中體現了語音識別的效率。
Canary 多語種模型 作為一個新的標準出現,在多種語言的語音識別和翻譯方面表現出色,并且具有非常高的準確度。
我們使用 P-Flow 多語種模型支持創建自定義語音,為個性化語音合成提供快速且數據高效的解決方案。通過利用 P-Flow,NVIDIA 以出色的保真度和效率合成了多種語言的揚聲器語音。
開創性的 Parakeet-CTC 和 P-Flow 模型現已推出,專為企業打造。此限制旨在防止 P-Flow 零射 TTS 可能被誤用,例如,以公眾人物和未經同意的個人的語音模擬的形式。
Parakeet-RNNT、Parakeet-TDT 和 Canary 模型即將作為 NVIDIA Riva 的一部分提供。通過 NVIDIA API 目錄,這些模型可以在任何地方使用,無論是云、數據中心、工作站還是 PC。此外,NVIDIA NIM 提供了優化推理微服務,用于大規模部署 AI 模型。NVIDIA LaunchPad 提供了必要的硬件和軟件堆棧,以便在私有基礎設施上進行更多探索。
親自或通過虛擬方式加入我們,參加 NVIDIA GTC 2024 會議,以深入了解 AI 驅動的通信的潛力:
- 語音 AI 揭秘
- 使用每種語言進行對話:TTS 模型的快速入門指南,用于有重音的多語種溝通
- 構建由 RAG 驅動的應用:使用人類語音界面
- 掌握語音 AI,實現多語種多媒體轉型
- 視頻會議中的安全 AI 驅動翻譯
- 優化基于 Transformer 的 ASR 模型以適應電話對話
- 揭秘在 3D 場景中運行對話角色的幕后故事
- 使用 NVIDIA NeMo 工具包的多說話者 ASR:訓練與推理
?
?
?





