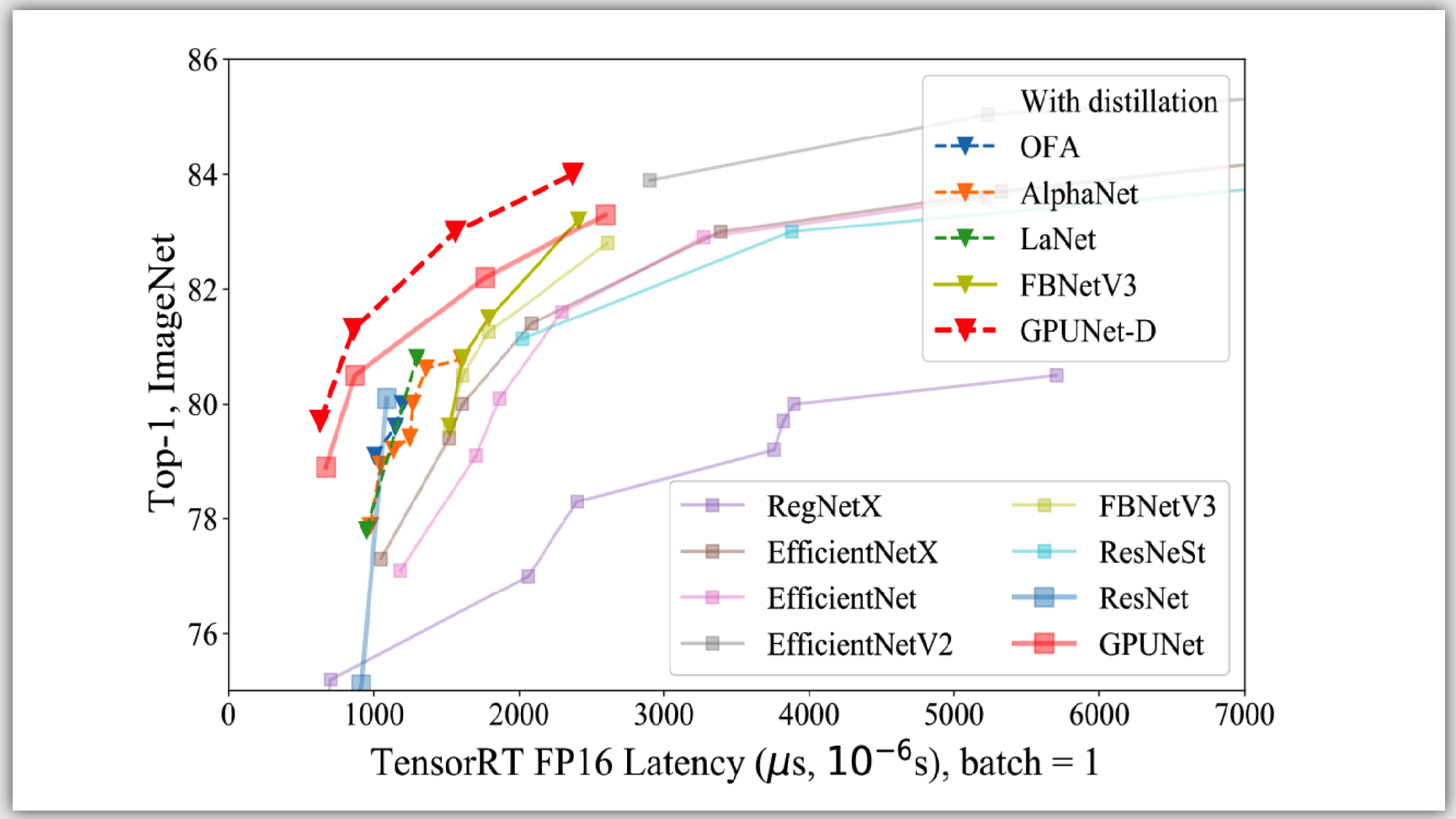
案例簡介
- GALA Sports 的 Arena4D 方案使用多個高清攝像機,將數據傳輸到一個本地 HPC 中,經過一系列的神經網絡流水線,實時計算出每個運動員的位置與姿態,從而將整個比賽場景數字化。
(圖片來源于望塵科技授權)
- Arena4D 的中央處理 HPC 需要以 30FPS 的速度處理 4-12 個 4K 相機的數據,流水線包括圖像前處理、運動員追蹤與識別、球的追蹤識別、骨骼關鍵點識別,多幀時間軸降噪等多個算法模塊,為了達到實時計算,Arena4D 使用了 NVIDIA A100 GPU 加速神經網絡計算,并使用 Tensor RT、CUDA 進行深度優化,經過優化部署的算法計算速度相對于早期算法原型有 10 倍以上的性能提升。
- 本案例主要應用到 NVIDIA A100 GPU、TensorRT和CUDA。
客戶簡介及應用背景
望塵科技(GALA Sports)于 2013 年在深圳成立,是一家以技術為驅動的互聯網公司,多年來一直專注于體育游戲和賽場數字化,致力于為用戶提供高品質的體育在線娛樂體驗,目前團隊成員 300 余人,分別于深圳、成都設有辦公地點。
憑借歷年來在體育游戲市場的深耕與穩定的高質量產品研發,望塵科技推出了《足球大師》、《NBA 籃球大師》、《最佳 11 人》等多款體育類手游,與 FIFPro、NBA、中超、拜仁、巴薩、曼聯、皇馬、國米等體育聯盟及豪門俱樂部保持著長期的合作關系。目前,擁有全球超過 2000 萬的下載用戶,全球日活躍用戶量超 50 萬人次;在賽場三維重構、人體運動模擬、球類競技 AI、表情與肌肉物理模擬、超寫實數字人、大場景渲染等幾個領域處于國內外領先地位。

客戶挑戰
- 多臺高清攝像頭每幀圖像需上傳到顯卡進行實時轉碼、降噪等前處理工作,數據吞吐量較大。
- 基于神經網絡的計算流水線,需要實時進行多個視角、多個運動員的追蹤、識別、姿態估計與降噪計算。
- 在多個 AI 模型級聯計算流水線中,每個 AI 模型之間的數據處理與拷貝占用了大量的時間。
應用方案
基于以上挑戰,GALA Sports 選擇了 NVIDIA 提供的 AI 加速解決方案——TensorRT。
- 針對多相機從內存到顯存大量數據拷貝 IO bound 問題,我們使用 CUDA 多流技術實現了內存拷貝與數據處理并行化,降低了 overhead,4 路 4k 相機數據的拷貝與轉碼從約 50ms 減少到 30ms。
- 針對神經網絡流水線的計算延遲問題,首先我們根據體育比賽的使用場景與相機視角對模型結構進行了優化,根據不同體育類型的相機機位和球場尺度,設計了專門針對特定比賽的識別網絡,大大降低了網絡的復雜度;然后使用量化工具對網絡進行 fp16 量化加速,最后使用 TensorRT 針對 A100 編譯,在 A100 上能達到最優性能的模型。
| 球員識別與追蹤網絡 | 姿態估計網絡 | ||||
| YoloV4 | Optimized Yolo V4 | Multi-frame CenterNet | HRNet | Optimized PoseNet | |
| Pytorch CUDA fp32 V100 | 0.582 s | 0.062 s | 0.05 s | 0.25 s | 0.045 s |
| Pytorch CUDA fp16 V100 | 0.32 s | 0.052 s | 0.035 s | 0.19 s | 0.03 s |
| TensorRT fp16 V100 | 0.25 s | 0.028 s | 0.018 s | 0.14 s | 0.035 s |
| TensorRT fp16 A100 | 0.0050 s | 0.0228 s | |||
| 優化比 | 58倍 | 10.9倍 |
- 針對計算流水線模型之間數據處理耗時的問題,首先我們通過合并部分神經網絡模型重新訓練,然后對于必須保留的數據處理代碼,我們用 CUDA C++ 重寫了大部分數據處理的 kernel,并針對 A100 的硬件結構對并行參數進行調優,最終將數據處理 30ms 的計算時間降低到 5ms。

最終,以足球場場景為例,追蹤目標為 1 個足球 + 22 名球員 + 3 名教練的位置與骨骼,在 1 張 A100 設備上我們實現了平均 50ms/幀的速度,在 2 張 A100 設備上能達到平均 30ms/幀的速度,整個流水線比原型提升了 18 倍。
方案效果及影響
將整個推理端算法流水線經過上述方法優化后,相較于未用 TensorRT 與 CUDA 優化的算法原型,我們實現了 18 倍的性能提升,使超大規模體育場景的姿態捕捉與重建的實時計算成為可能,在體育比賽過程中的實時計算產生了許多新的用途,我們的客戶能夠將這些數字化內容用于直播解說、實時戰術分析、自由視角回放、比賽結果預測等新場景,提升了系統方案的價值。
我們的硬件方案也從 4 臺 HPC 縮減到 1 臺 HPC 搭載 2 張 A100 GPU,不僅顯著地降低了成本,也顯著降低了系統維護和使用的復雜度,提升了系統可靠度。
后續,我們計劃:
- 通過將流水線中部分網絡使用 Int8 量化以進一步提升性能;
- 將整體流水線遷移到 CUDA C++ 代碼中進一步提升性能;
- 把性能提升空余的計算資源用于提升網絡模型的復雜度以提升精度;
- 將 CenterNet 與 Dense Sematic 網絡特征提取部分替換成 Vision Transformer 以提升精度;
- 使用 Nsight 在 A100 真實環境中進一步 profile,減少 overhead。