作為發布合作伙伴,NVIDIA 與 Google 合作提供了Gemma,這是一個新優化的開放模型系列,它基于創建 Gemini 模型時所使用的相同研究和技術構建。通過使用 TensorRT-LLM 的優化版本,用戶只需配備NVIDIA RTX GPU,即可享受到這些優勢。
由 Google DeepMind 創建,Gemma 2B 和 Gemma 7B 作為該系列的首批模型,Gemma 可實現高吞吐量和先進性能。通過 TensorRT-LLM (用于優化推理性能的開源庫) 加速,Gemma 可兼容從數據中心、云到本地 PC 的各種 NVIDIA AI 平臺。
以前,LLM 的優化和部署非常復雜,令人望而卻步。使用 TensorRT-LLM 簡化的 Python API 可以輕松實現量化和內核壓縮。Python 開發者可以針對熱門 LLM 自定義模型參數、減少內存占用、提高吞吐量并降低推理延遲。Gemma 模型使用的詞匯量為 256K,支持的上下文長度高達 8K。
通過廣泛的數據管護和以安全為導向的訓練方法,將安全性內置于 Gemma 模型中。個人識別信息 (PII) 過濾可從預訓練和指令調整數據集中刪除標識符(例如社會安全號)。此外,根據人類反饋進行的大量微調和強化學習 (RLHF) 可將指令調整模型與負責任的行為保持一致。
開發者使用超過 6 萬億個令牌進行訓練,可以滿懷信心地構建和部署高性能、負責任的高級 AI 應用程序。
TensorRT-LLM 讓 Gemma 模型更快
TensorRT-LLM 具有大量優化和內核,可提高推理吞吐量和延遲。TensorRT-LLM 的三項獨特功能可提升 Gemma 的性能,即 FP8、XQA 和 INT4 激活感知權重量化 (INT4 AWQ)。
FP8 是加速深度學習應用程序的自然進展,超越了現代處理器中常見的 16 位格式。FP8 在不犧牲準確性的情況下實現了更高的矩陣乘法和內存傳輸吞吐量。在內存帶寬受限的模型中,它既有助于小批量處理,也在計算密度和內存容量至關重要時處理大批量表現出色。
TensorRT-LLM 還為 KV 緩存提供 FP8 量化。KV 緩存不同于在批量大或上下文長度較長的情況下占用不可忽略的持久內存的正常激活。切換到 FP8 KV 緩存可在提高性能的同時,運行 2-3 倍的批量大小。
XQA 是一個支持組查詢注意力和多查詢注意力的內核。XQA 是 NVIDIA AI 開發的新內核,可在生成階段提供優化,并優化波束搜索。 NVIDIA GPU 減少了數據加載和轉換時間,在相同的延遲預算內提高了吞吐量。
INT4 AWQ ?也獲得 TensorRT-LLM 提供支持。AWQ 可為批量大小不超過 4 的小工作負載提供卓越的性能。它可減少網絡的內存占用,并顯著提高內存帶寬受限的應用程序的性能。AWQ 是一種僅采用低位權重的量化方法,可減少量化誤差。它通過利用激活函數保護重要的權重。
通過結合 INT4 和 AWQ 的優勢,適用于 INT4 AWQ 的 TensorRT-LLM 自定義內核可根據 LLM 的相對重要性將其權重壓縮到 4 位,并在 FP16 中執行計算。這有助于提供比其他 4 位方法更高的準確性,同時減少內存占用并顯著加速。
實時性能,每秒超過 7.9 萬個令牌
搭載 NVIDIA H200 Tensor Core GPU 的 TensorRT-LLM 可在 Gemma 2B 和 Gemma 7B 模型上提供出色的性能。單個 H200 GPU 在 Gemma 2B 模型上每秒可提供超過 79000 個令牌,在較大的 Gemma 7B 模型上每秒可提供近 19000 個令牌。
結合這種性能,僅在一個 H200 GPU 上部署的搭載 TensorRT-LLM 的 Gemma 2B 模型可以為 3000 多個并發用戶提供實時延遲服務。
立即開始
通過您的瀏覽器直接體驗 Gemma,訪問 NVIDIA AI Playground。您還可以在 NVIDIA 與 RTX 聊天 演示應用中體驗即將推出的 Gemma。
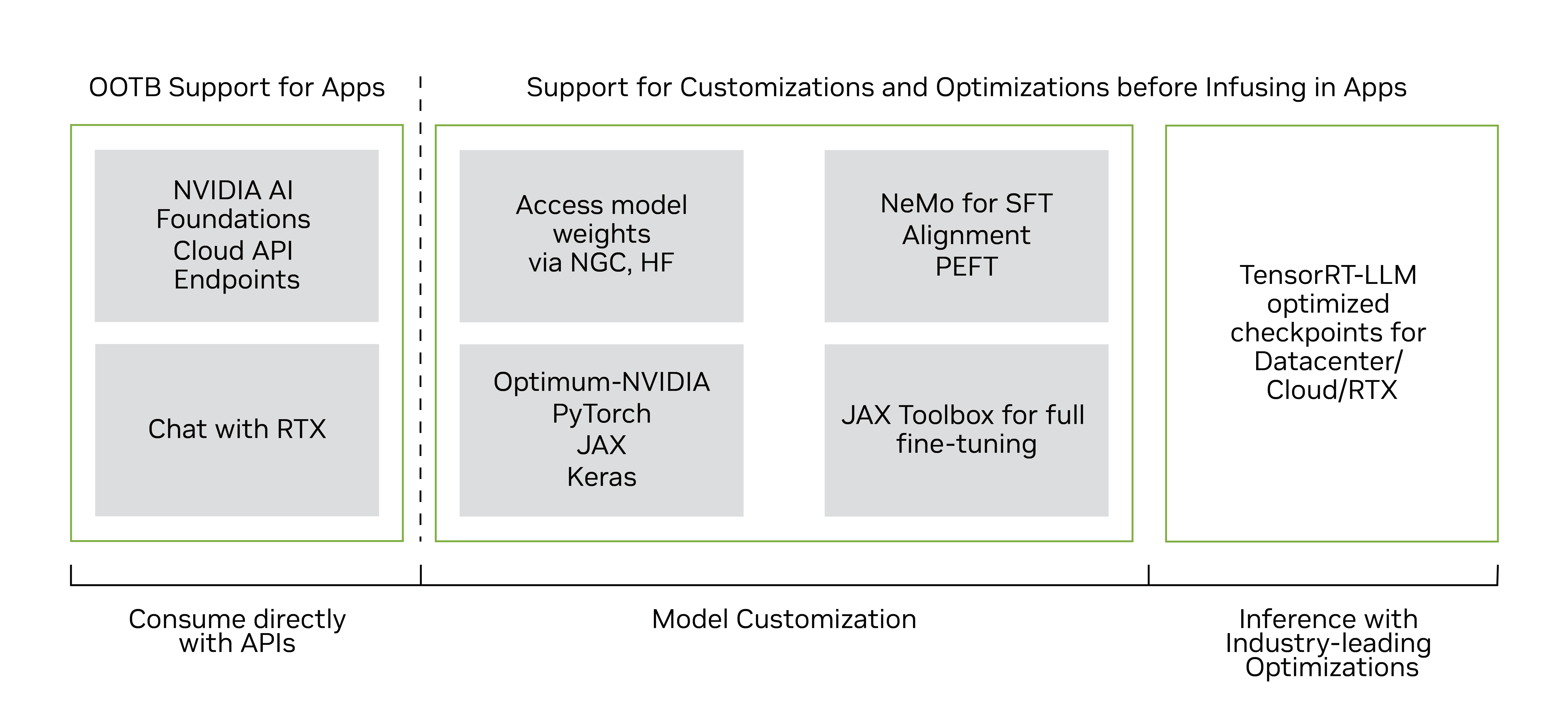
多個經過優化的 TensorRT-LLM Gemma-2B 和 Gemma-7B 模型檢查點(包括預訓練和指令調優版本)現已在 NGC 上提供,用于在 NVIDIA GPU(包括消費級 RTX 系統)上運行優化模型。
很快,您將能夠在 Omniverse 中體驗到 TensorRT-LLM 優化的 FP8 量化模型版本,這些模型基于最佳 NVIDIA 庫,并且只需一行代碼即可集成快速 LLM 推理。
開發者可以使用NVIDIA NeMo 框架來定制和部署 Gemma 在生產環境中。NeMo 框架提供了多種自定義技術,如監督微調、使用 LoRA 和 RLHF 的參數高效微調,以及支持訓練的 3D 并行性。通過 Notebook 開始使用 Gemma 和 NeMo 進行編碼。
立即開始使用 NeMo 框架自定義 Gemma。
?