在游戲市場持續增長和對更好的 3D 圖形的永不滿足的需求的推動下, NVIDIA ?已經將 GPU 發展成為許多計算密集型應用的世界領先的并行處理引擎。除了渲染高度逼真和身臨其境的 3D 游戲外, NVIDIA GPUs 還可以加速內容創建工作流、高性能計算( HPC )和數據中心應用程序,以及眾多人工智能系統和應用程序。新的 NVIDIA 圖靈 GPU 架構建立在 GPU 長期領導地位的基礎上。
圖靈代表了十多年來最大的體系結構飛躍,它提供了一個新的核心 GPU 體系結構,使 PC 游戲、專業圖形應用和深度學習推理的效率和性能有了重大提高。
使用新的基于硬件的加速器和混合渲染方法,圖靈融合了光柵化、實時光線跟蹤、人工智能和模擬技術,在電腦游戲中實現令人難以置信的真實感、由神經網絡驅動的驚人新效果、電影質量的交互體驗以及創建或導航復雜 3D 模型時的流體交互。
在核心架構中,圖靈顯著提升圖形性能的關鍵因素是一個新的 GPU 處理器(流式多處理器 SM )架構,它提高了著色器執行效率,以及一個新的內存系統架構,其中包括對最新 GDDR6 內存技術的支持。
圖像處理應用程序,如 ImageNet Challenge 是深度學習的首批成功案例之一,因此,人工智能有潛力解決圖形中的許多重要問題也就不足為奇了。圖靈的張量核心支持一套新的基于深度學習的 神經服務 ,除了為基于云的系統提供快速的人工智能推斷外,還為游戲和專業圖形提供驚人的圖形效果。
長期以來備受追捧的計算機圖形繪制的圣杯——實時光線跟蹤現在已經在具有 NVIDIA 圖靈 GPU 體系結構的單 GPU 系統中實現。圖靈 GPUs 引入了新的 RT 核心,加速器單元致力于以非凡的效率執行光線跟蹤操作,消除了過去昂貴的基于軟件仿真的光線跟蹤方法。這些新裝置與 NVIDIA RTX ? 軟件技術和復雜的過濾算法使圖靈能夠提供實時光線跟蹤渲染,包括具有物理精確陰影、反射和折射的真實感對象和環境。
在圖靈開發的同時,微軟在 2018 年初發布了 directmlforai 和 DirectX 光線跟蹤( DXR ) api 。通過圖靈 GPU 架構和微軟新的 AI 和光線追蹤 API 的結合,游戲開發者可以在他們的游戲中快速部署實時 AI 和光線追蹤。
除了具有開創性的人工智能和光線跟蹤功能外,圖靈還包括許多新的高級著色功能,這些功能可以提高性能,增強圖像質量,并提供更高層次的幾何復雜性。
圖靈 GPUs 還繼承了對 NVIDIA CUDA 的所有增強? Volta 體系結構中引入的平臺,可提高計算應用程序的能力、靈活性、生產力和可移植性。諸如獨立線程調度、多應用程序地址空間隔離的硬件加速多進程服務( MPS )和協作組等特性都是圖靈 GPU 體系結構的一部分。
一些新的 NVIDIA GeForce ?和 NVIDIA Quadro ? GPU 產品將由圖靈 GPUs 提供動力。在本文中,我們將重點介紹 NVIDIA 旗艦圖靈 GPU 的體系結構和性能,該產品代號為 TU102 ,將在 GeForce RTX 2080 Ti 和 Quadro RTX 6000 上交付。技術細節,包括 TU104 和 TU106 圖靈 GPUs 的產品規范,見附錄。
圖 1 展示了圖靈如何用一個全新的架構來重塑圖形,這個架構包括增強的張量核心、新的 RT 核心和許多新的高級著色功能。圖靈結合了可編程著色、實時光線跟蹤和人工智能算法,為游戲和專業應用程序提供了難以置信的真實感和物理精確的圖形。

NVIDIA 圖靈關鍵特性
NVIDIA 圖靈是世界上最先進的 GPU 體系結構。高端 TU102 GPU 包括
在臺積電 12 納米 FFN ( FinFET NVIDIA )高性能制造工藝上制造了 186 億個晶體管。
GeForce RTX 2080 Ti Founders Edition GPU 提供了以下卓越的計算性能:
 14 . 2 TFLOPS 公司1峰值單精度( FP32 )性能
14 . 2 TFLOPS 公司1峰值單精度( FP32 )性能
28 . 5 噸1半精度( FP16 )性能的峰值
14 . 2 提示1通過獨立的整數執行單元與 FP 并行
113 . 8 張量 TFLOPS1,2
10 千兆射線/秒
78 太拉 RTX – 操作
Quadro RTX 6000 提供了專為專業工作流程設計的卓越計算性能:
16 . 3 TFLOPS 公司1峰值單精度( FP32 )性能
32 . 6 TFLOPS 公司1半精度( FP16 )性能的峰值
16 . 3 TIPS1 與 FP 并行,通過獨立的整數執行單元
130 . 5 張量 TFLOPS1,2
10 千兆射線/秒
84 太拉 RTX – 操作
1基于 GPU 升壓時鐘。2FP16 矩陣數學與 FP16 累加。
下面的部分將以摘要格式描述圖靈的主要新創新。本白皮書提供了每個領域的更詳細描述。
新的流式多處理器( SM )
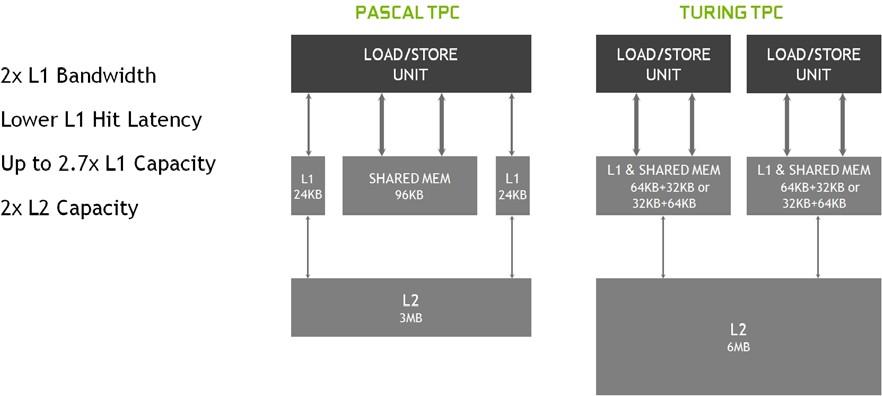
與圖靈新一代處理器相比,新一代圖靈處理器的效率提高了 50% 。這些改進是由兩個關鍵的體系結構更改實現的。首先,圖靈 SM 添加了一個新的獨立整數數據路徑,它可以與浮點數學數據路徑同時執行指令。在前幾代中,執行這些指令會阻止浮點指令的發出。其次, SM 內存路徑被重新設計,將共享內存、紋理緩存和內存負載緩存統一到一個單元中。這意味著普通工作負載的一級緩存可用帶寬增加 2 倍,容量增加 2 倍以上。
![]() 圖靈張量核
圖靈張量核
張量核心是專門為執行張量/矩陣運算而設計的專用執行單元,這些運算是深度學習中使用的核心計算功能。與 Volta 張量核類似,圖靈張量核在深度學習神經網絡訓練和推理操作的核心為矩陣計算提供了巨大的速度。圖靈 GPUs 包括了一個新版本的張量核心設計,它已經增強了推斷能力。圖靈張量核心增加了新的 INT8 和 INT4 精度模式來推斷可以容忍量化且不需要 FP16 精度的工作負載。圖靈張量核心首次為 GeForce 游戲 PC 和基于 Quadro 的工作站帶來了新的基于深度學習的人工智能能力。一種稱為深度學習超級采樣( DLSS )的新技術由張量核提供動力。 DLSS 利用深度神經網絡提取渲染場景的多維特征,并智能地結合多幀圖像中的細節來構造高質量的最終圖像。與傳統技術(如 TAA )相比, DLSS 使用更少的輸入樣本,同時避免了此類技術在透明度和其他復雜場景元素方面面臨的算法困難。
實時光線跟蹤加速
圖靈引入了實時光線跟蹤,使單個 GPU 能夠渲染具有視覺真實感的 3D 游戲和復雜的專業模型,具有物理上精確的陰影、反射和折射。圖靈的新 RT 核心加速射線追蹤,并被系統和接口所利用,如 NVIDIA 的 RTX 射線追蹤技術,以及微軟 DXR , NVIDIA OptiX 等 API ?,以及 Vulkan 光線跟蹤,提供實時光線跟蹤體驗。
新的著色技術
網格著色
網格著色改進了 NVIDIA 的幾何處理架構,為圖形管道的頂點、細分和幾何體著色階段提供了一個新的著色器模型,支持更靈活和高效的幾何體計算方法。這種更靈活的模型,例如,通過將對象列表處理的關鍵性能瓶頸從 CPU 移開,并轉移到高度并行的 GPU 網格著色程序中,使每個場景支持數量級更多的對象成為可能。網格著色還支持先進的幾何合成和對象 LOD 管理的新算法。
可變速率著色( VRS )
VRS 允許開發人員動態控制著色速率,每 16 像素著色一次,或者每像素 8 次著色。應用程序使用著色速率曲面和每基本體(三角形)值的組合指定著色速率。 VRS 是一個非常強大的工具,它允許開發者更有效地進行陰影處理,減少了在全分辨率陰影處理不會給任何可見圖像質量帶來好處的屏幕區域的工作,從而提高了幀率。已經確定了幾種基于 VRS 的算法,這些算法可以根據內容細節級別(內容自適應著色)、內容運動速率(運動自適應著色)以及 VR 應用、鏡頭分辨率和眼睛位置( Foveated Rendering )來改變著色工作。
紋理空間著色
使用紋理空間著色,對象在保存到內存的專用坐標空間(紋理空間)中著色,像素著色器從該空間采樣,而不是直接計算結果。通過在內存中緩存著色結果并重用/重新采樣的能力,開發人員可以消除重復的著色工作或使用不同的采樣方法來提高質量。
多視圖渲染( MVR )
MVR 有力地擴展了 Pascal 的單聲道立體聲( SP )。雖然 SPS 允許渲染除 X 偏移外的兩個常見視圖,但 MVR 允許在一個過程中渲染多個視圖,即使這些視圖基于完全不同的原點位置或視圖方向。訪問是通過一個簡單的編程模型來實現的,在這個模型中,編譯器自動將視圖無關的代碼分解出來,同時確定視圖相關的屬性以實現最佳執行。
圖形的深度學習功能
NVIDIA NGX 公司? 是 NVIDIA RTX 技術的新的基于深度學習的神經圖形框架。 NVIDIA NGX 利用深度神經網絡( DNNs )和一組“神經服務”來執行基于人工智能的功能,這些功能可以加速和增強圖形、渲染和其他客戶端應用程序。 NGX 將圖靈張量核心用于基于深度學習的操作,并加速向最終用戶直接交付 NVIDIA 深度學習研究。功能包括超高質量的 NGX DLSS (深度學習超級采樣)、 AI 修復內容感知圖像替換、 AI Slow-Mo 非常高質量和平滑的慢動作,以及 AI-Super-Rez 智能分辨率調整。
推理的深度學習特性
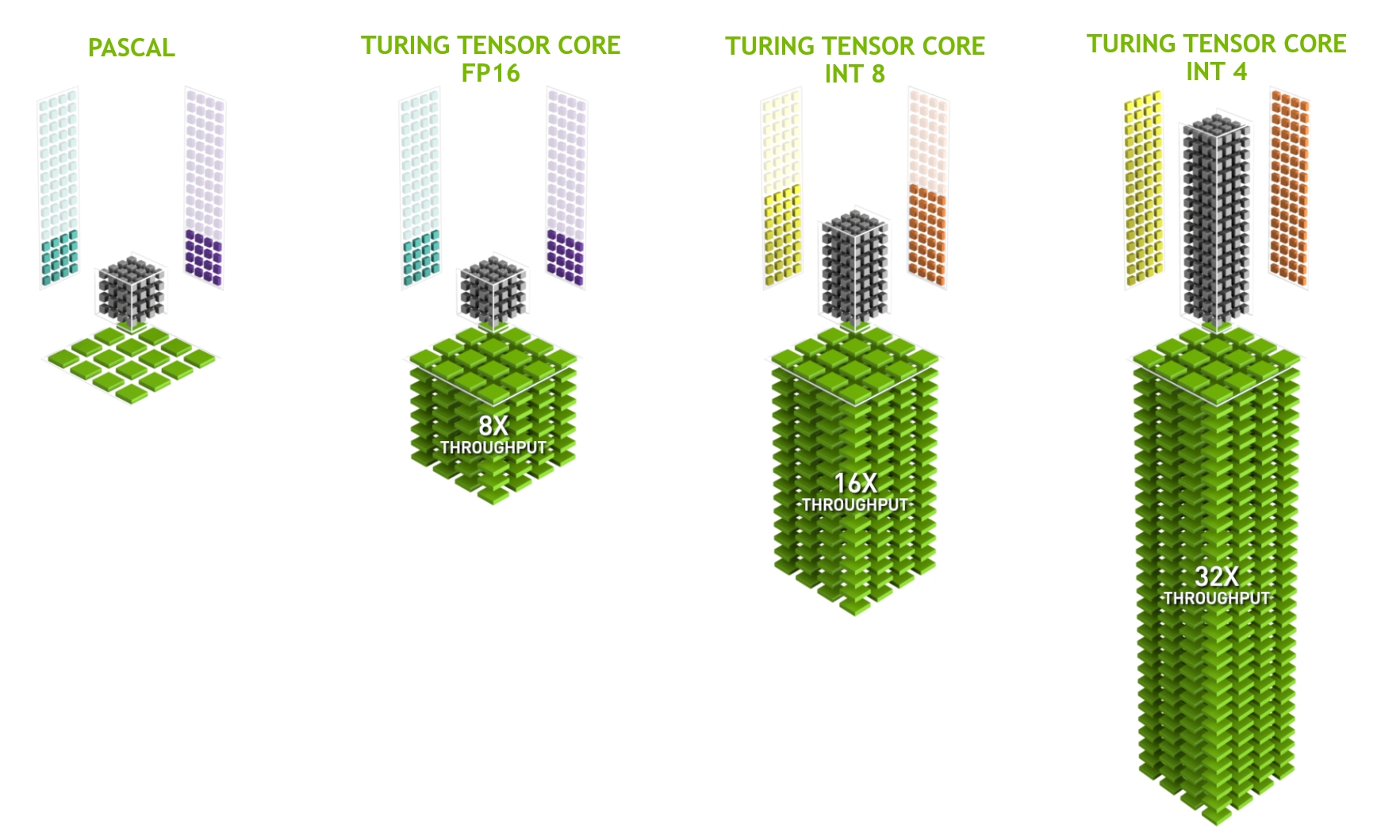
圖靈 GPUs 提供了卓越的推理性能。圖靈張量核心,加上 TensorRT ( NVIDIA 的運行時推斷框架)、 CUDA 和 cuDNN 庫的不斷改進,使圖靈 GPUs 能夠為推理應用程序提供出色的性能。圖靈張量核還增加了對快速 INT8 矩陣運算的支持,以最大程度地提高推理吞吐量,同時減少精確度損失。新的低精度 INT4 矩陣運算現在有可能與圖靈張量核心,并將使研究和開發到亞 8 位神經網絡。
GDDR6 高性能內存子系統
圖靈是第一個支持 GDDR6 內存的 GPU 體系結構。 GDDR6 是高帶寬 GDDRAM 內存設計的下一個重大進步。圖靈 GPUs 中的 GDDR6 內存接口電路在速度、功率效率和噪音降低方面進行了徹底的重新設計,與 Pascal GPUs 中使用的 GDDR5X 內存相比,實現了 14 Gbps 的傳輸速率,功率效率提高了 20% 。
第二代 NVIDIA NVLink
圖靈 TU102 和 TU104 GPUs 合并了 NVIDIA 的 NVLink ? 高速互連,提供可靠、高帶寬和低延遲連接對圖靈 GPUs 。 NVLink 具有高達 100GB / s 的雙向帶寬,使定制的工作負載能夠在兩個 GPUs 之間高效地分割并共享內存容量。對于游戲工作負載, NVLink 增加的帶寬和專用的 inter- GPU 通道為 SLI 提供了新的可能性,例如新的模式或更高分辨率的顯示配置。對于大型內存工作負載,包括專業的光線跟蹤應用程序,場景數據可以在 GPUs 的幀緩沖區中分割,提供高達 96 GB 的共享幀緩沖區內存(兩個 48 GB Quadro RTX 8000 GPUs ),內存請求由硬件根據內存分配的位置自動路由到正確的 GPU 。
USB-C 和 VirtualLink
圖靈 GPUs 包括對 USB Type-C 的硬件支持? 和 VirtualLink ?. (為了準備新出現的 VirtualLink 標準,圖靈 GPUs 已經根據 VirtualLink 高級概述 實現了硬件支持。要了解有關 VirtualLink 的更多信息,請參閱 http://www.virtuallink.org )VirtualLink 是一種新的開放式行業標準,旨在通過單個 USB-C 連接器滿足下一代 VR 耳機的功率、顯示和帶寬需求。除了減輕目前 VR 耳機的安裝麻煩之外, VirtualLink 還將把 VR 應用到更多的設備中。
![]() 深度圖靈體系結構
深度圖靈體系結構
圖靈 TU102 GPU 是圖靈 GPU 線路中性能最高的 GPU ,也是本節的重點。 TU104 和 TU106 GPUs 采用與 TU102 相同的基本架構,針對不同的使用模式和市場細分,進行了不同程度的縮減。 TU104 和 TU106 芯片架構和目標用途/市場的詳細信息見 圖靈體系結構白皮書 。
圖靈 TU102 GPU
TU102 GPU 包括 6 個圖形處理群集( GPC )、 36 個紋理處理群集( TPC )和 72 個流式多處理器( SMs )。(參見 圖 2 了解帶有 72 個 SM 單元的 TU102 full GPU 的圖示。)每個 GPC 包括一個專用光柵引擎和六個 TPC ,每個 TPC 包括兩個 SMs 。每個 SM 包含 64 個 CUDA 內核、 8 個張量內核、一個 256 KB 的寄存器文件、 4 個紋理單元和 96 KB 的 L1 /共享內存,這些內存可根據計算或圖形工作負載配置為各種容量。
光線跟蹤加速由每個 SM 內的新 RT 核心處理引擎執行( RT 核心和光線跟蹤功能在完整的 NVIDIA 圖靈體系結構白皮書 中有更深入的討論)。
TU102 GPU 的全面實施包括以下內容:
4608 CUDA 顏色
72 個 RT 芯
576 張量核
288 個紋理單位
12 個 32 位 GDDR6 內存控制器(總計 384 位)。
每個內存控制器都有 8 個 ROP 單元和 512 KB 的二級緩存。完整的 TU102 表 1 由 96 個 ROP 單元和 6144 KB 的二級緩存組成。參見 GPU 表 1 中的圖靈 TU102 GPU 比較了 Pascal GP102 的 GPU 特性和圖靈 TU102 。
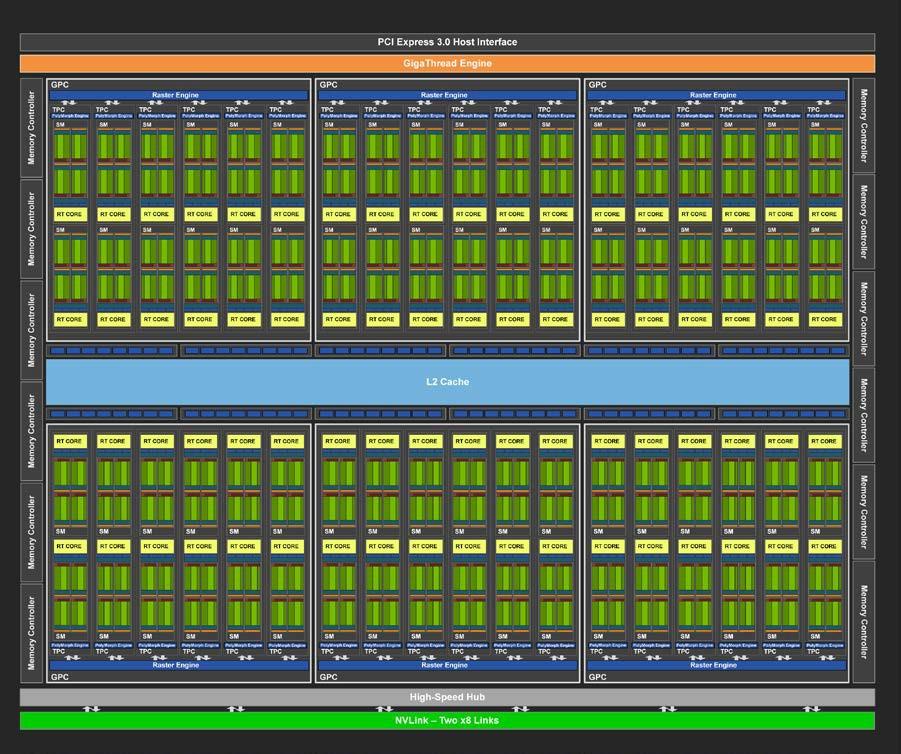
注: TU102 GPU 還具有 144 個 FP64 單元(每平方米兩個),這在本圖中沒有描述。 FP64 TFLOP 速率是 FP32 操作的 TFLOP 速率的 1 / 32 。包含少量的 FP64 硬件單元,以確保任何使用 FP64 代碼的程序都能正確運行。
| GPU Features | GTX 1080Ti | RTX 2080 Ti | Quadro 6000 | Quadro RTX 6000 |
| Architecture | Pascal | Turing | Pascal | Turing |
| GPCs | 6 | 6 | 6 | 6 |
| TPCs | 28 | 34 | 30 | 36 |
| SMs | 28 | 68 | 30 | 72 |
| CUDA Cores / SM | 128 | 64 | 128 | 64 |
| CUDA Cores / GPU | 3584 | 4352 | 3840 | 4608 |
| Tensor Cores / SM | NA | 8 | NA | 8 |
| Tensor Cores / GPU | NA | 544 | NA | 576 |
| RT Cores | NA | 68 | NA | 72 |
| GPU Base Clock MHz (Reference / Founders Edition) | 1480 / 1480 | 1350 / 1350 | 1506 | 1455 |
| GPU Boost Clock MHz (Reference / Founders Edition) | 1582 / 1582 | 1545 / 1635 | 1645 | 1770 |
| RTX-OPS (Tera-OPS)
? (Reference / Founders Edition) |
11.3 / 11.3 | 76 / 78 | NA | 84 |
| Rays Cast (Giga Rays/sec) (Reference / Founders Edition) | 1.1 / 1.1 | 10 / 10 | NA | 10 |
| Peak FP32 TFLOPS?
? (Reference/Founders Edition) |
11.3 / 11.3 | 13.4 / 14.2 | 12.6 | 16.3 |
| Peak INT32 TIPS?
? (Reference/Founders Edition) |
NA | 13.4 / 14.2 | NA | 16.3 |
| Peak FP16 TFLOPS?
? (Reference/Founders Edition) |
NA | 26.9 / 28.5 | NA | 32.6 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate??(Reference/Founders Edition) | NA | 107.6 / 113.8 | NA | 130.5 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate??(Reference/Founders Edition) | NA | 53.8 / 56.9 | NA | 130.5 |
| Peak INT8 Tensor TOPS??(Reference/Founders Edition) | NA | 215.2 / 227.7 | NA | 261.0 |
| Peak INT4 Tensor TOPS?
? (Reference/Founders Edition) |
NA | 430.3 / 455.4 | NA | 522.0 |
| Frame Buffer Memory Size and Type | 11264 MB GDDR5X | 11264 MB GDDR6 | 24576 MB GDDR5X | 24576 MB GDDR6 |
| Memory Interface | 352-bit | 352-bit | 384-bit | 384-bit |
| Memory Clock (Data Rate) | 11 Gbps | 14 Gbps | 9 Gbps | 14 Gbps |
| Memory Bandwidth (GB/sec) | 484 | 616 | 432 | 672 |
| ROPs | 88 | 88 | 96 | 96 |
| Texture Units | 224 | 272 | 240 | 288 |
| Texel Fill-rate (Gigatexels/sec) | 354.4 / 354.4 | 420.2 / 444.7 | 395 | 510 |
| L2 Cache Size | 2816 KB | 5632 KB | 3072 KB | 6144 KB |
| Register File Size/SM | 256 KB | 256 KB | 256 KB | 256 KB |
| Register File Size/GPU | 7168 KB | 17408 KB | 7680 KB | 18432 KB |
| TDP★
? (Reference/Founders Edition) |
250 / 250 W | 250 / 260 W | 250 W | 260 W |
| Transistor Count | 12 Billion | 18.6 Billion | 12 Billion | 18.6 Billion |
| Die Size | 471 | 754 | 471 | 754 |
| Manufacturing Process | 16 nm | 12 nm FFN | 16 nm | 12 nm FFN |
隨著 GPU 加速計算變得越來越流行,具有多個 GPUs 的系統正越來越多地部署在服務器、工作站和超級計算機上。 TU102 和 TU104 GPUs 包括第二代 NVIDIA 的 NVLink ? 高速互連,最初設計為 Volta GV100 GPU ,為 SLI 和其他多 GPU 用例提供高速多 GPU 連接。 NVLink 允許每個 GPU 直接訪問其他連接的 GPUs 的內存,提供更快的 GPU – GPU 通信,并允許組合來自多個 GPUs 的內存以支持更大的數據集和更快的內存計算。
TU102 包括兩個 NVLink x8 鏈路,每個鏈路在每個方向上的傳輸速率高達 25gb / s ,雙向總帶寬為 100gb / s 。

圖靈流式多處理器( SM )體系結構
圖靈架構的特點是一個新的 SM 設計,它包含了我們在 Volta GV100 SM 架構中引入的許多功能。每個 TPC 包括兩個 SMs ,每個 SM 共有 64 個 FP32 核和 64 個 INT32 核。相比之下, Pascal GP10x GPUs 每個 TPC 有一個 SM ,每 SM 有 128 個 FP32 核。圖靈 SM 支持 FP32 和 INT32 操作的并發執行(更多細節見下文),獨立的線程調度類似于 voltagv100 GPU 。每個圖靈 SM 還包括八個混合精度的圖靈張量核心,在 ? 下面的 圖靈張量核 一節中有更詳細的描述,還有一個 RT 核心,其功能在 圖靈射線追蹤技術 below . 中有描述,圖靈 TU102 、 TU104 和 TU106 SM 的說明見 圖 4 。
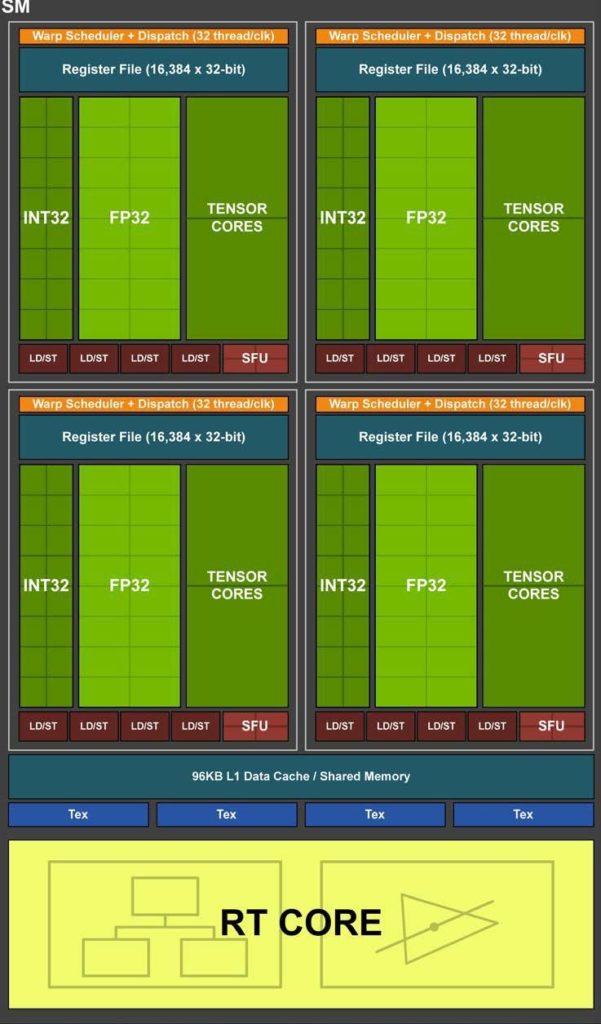
圖靈 SM 被劃分為四個處理塊,每個處理塊有 16 個 FP32 核、 16 個 INT32 核、兩個張量核、一個 warp 調度器和一個調度單元。每個塊包括一個新的 L0 指令緩存和一個 64kb 的寄存器文件。四個處理塊共享一個組合的 96kbl1 數據緩存/共享內存。傳統圖形工作負載將 96 KB L1 /共享內存劃分為 64 KB 的專用圖形著色器 RAM 和 32 KB 的紋理緩存和寄存器文件溢出區域。計算工作負載可以將 96 KB 劃分為 32 KB 共享內存和 64 KB L1 緩存,或 64 KB 共享內存和 32 KB L1 緩存。
圖靈實現了核心執行數據路徑的重大改進。現代著色器工作負載通常將 FP 算術指令(如 FADD 或 FMAD )與更簡單的指令(如用于尋址和獲取數據的整數加法、用于處理結果的浮點比較或最小/最大值)混合在一起。在以前的著色器體系結構中,每當這些非 FP 數學指令之一運行時,浮點數學數據路徑就處于空閑狀態。在第二個并行執行單元 kzc0 上,用一個并行的 CUDA 執行一個浮點指令。
圖 5 表明整數管道指令與浮點指令的混合情況各不相同,但在一些現代應用程序中,我們通常會看到每 100 條浮點指令增加 36 條整數管道指令。將這些指令移動到一個單獨的管道中,這意味著浮點的有效吞吐量增加了 36% 。
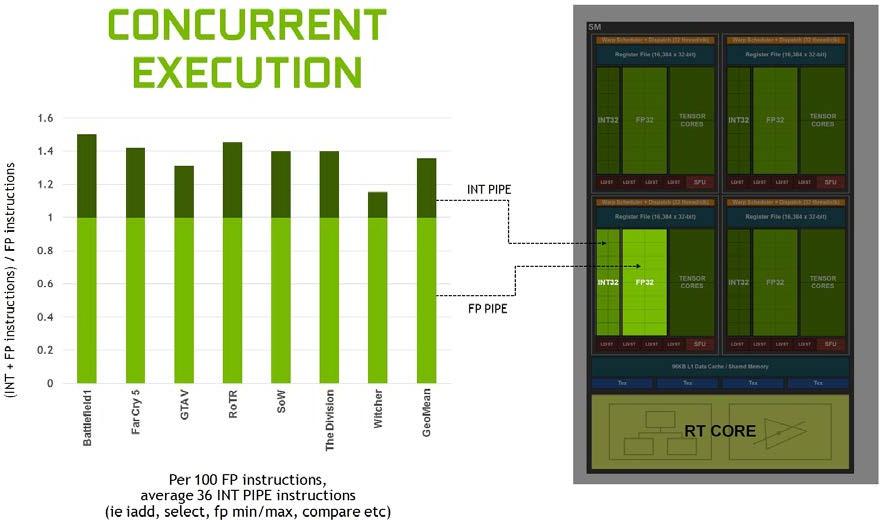
分析許多工作負載時,平均每 100 個浮點操作就有 36 個整數操作。
圖靈還為 L1 的共享內存引入了統一的紋理緩存和架構。這種統一的設計允許一級緩存利用資源,與 Pascal 相比,每 TPC 增加 2 倍的命中帶寬,并允許在共享內存分配未使用所有共享內存容量時對其進行重新配置,使其更大。圖靈 L1 的大小可以達到 64kb ,再加上每個 SM 共享內存分配 32kb ,或者它可以減少到 32kb ,允許 64kb 的分配用于共享內存。圖靈的二級緩存容量也有所增加。
圖 6 展示了圖靈 SM 新的組合 L1 數據緩存和共享內存子系統如何顯著提高性能,同時簡化編程并減少達到或接近峰值應用程序性能所需的調整。將一級數據緩存與共享內存相結合可以減少延遲,并提供比先前在 Pascal GPUs 中使用的一級緩存實現更高的帶寬。
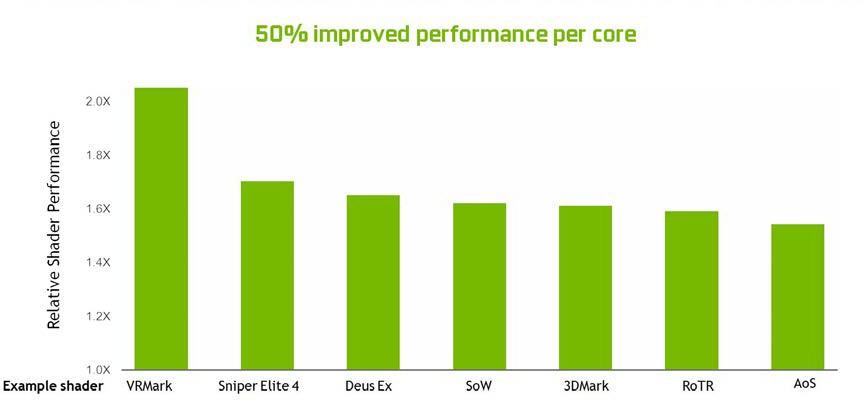
總的來說, SM 的變化使圖靈能夠在每個 CUDA 核心上實現 50% 的性能改進。 圖 7 顯示當前游戲應用程序的一組著色器工作負載的結果。
圖靈張量核
圖靈 GPUs 包括一個增強版的張量核心首次引入 voltagv100 GPU 。圖靈張量核心設計增加了 INT8 和 INT4 精確模式,用于推斷可以容忍量化的工作負載。對于需要更高精度的工作負載, FP16 也完全受支持。
在基于圖靈的 GeForce 游戲 GPUs 中引入張量核,使得首次將實時深度學習引入游戲應用成為可能。圖靈張量核心加速了 NVIDIA NGX 神經服務基于人工智能的特性,增強了圖形、渲染和其他類型的客戶端應用。 NGX 人工智能功能的例子包括深度學習超級采樣( DLSS )、 AI 修復、 AI 超級 Rez 和 AI Slow-Mo 。關于 DLSS 的更多細節可以在本文后面找到。您可以在完整的 NVIDIA 圖靈體系結構白皮書 中找到有關其他 NGX 功能的附加信息。
圖靈張量核加速矩陣乘法是神經網絡訓練和推理功能的核心。圖靈張量核特別擅長推理計算,在推理計算中,有用的和相關的信息可以由一個訓練好的深層神經網絡( DNN )基于給定的輸入進行推斷和傳遞。推理的例子包括識別 Facebook 照片中朋友的圖像,識別和分類不同類型的汽車、行人和自動駕駛汽車中的道路危險,實時翻譯人類語言,以及在在線零售和社交媒體系統中創建個性化的用戶推薦。
TU102 GPU 包含 576 個張量核心:每個 SM 8 個, SM 內每個處理塊 2 個。每個張量核心可以執行多達 64 個浮點融合乘法加法( FMA )操作,每個時鐘使用 FP16 輸入。一個 SM 中的八個張量核心每時鐘執行 512 個 FP16 乘法和累加運算,或每個時鐘總共執行 1024 次浮點運算。新的 INT8 精度模式以兩倍的速率工作,即每時鐘 2048 次整數運算。
圖靈張量核為矩陣運算提供了顯著的加速,除了新的神經圖形功能外,還用于深度學習訓練和推理操作。有關基本張量核心操作細節的更多信息,請參閱 NVIDIA Tesla V100 GPU 體系結構白皮書 .
為數據中心應用程序優化的圖靈
除了為高端游戲和專業圖形帶來革命性的新功能外,圖靈還為下一代 Tesla ? GPUs 提供卓越的性能和能效。 NVIDIA 目前在數據中心用于推斷應用程序的基于 Pascal 的 GPUs 已經比基于 CPU 的服務器提供了高達 10 倍的性能和 25 倍的能效。在圖靈張量核心的支持下,下一代基于圖靈的 Tesla GPUs 將在數據中心提供更高的推斷性能和能源效率。基于圖靈的 Tesla GPUs 優化后可在 70 瓦以下運行,這將為超大規模數據中心帶來顯著的效率和性能提升。
除了圖靈張量核心之外,圖靈 GPU 體系結構還包括一些提高數據中心應用程序性能的特性。一些關鍵功能包括:
增強視頻引擎
與上一代 Pascal 和 Volta GPU 架構相比,圖靈支持額外的視頻解碼格式,如 HEVC 4 : 4 : 4 ( 8 / 10 / 12 位)和 VP9 ( 10 / 12 位)。圖靈中增強的視頻引擎能夠解碼比等效的基于 Pascal 的 Tesla GPUs 多得多的并發視頻流。(見 視頻顯示引擎 下面的 . 一節)
圖靈多進程服務
圖靈 GPU 體系結構繼承了 Volta 體系結構中首次引入的增強型多進程服務( MPS )特性。與基于 Pascal 的 Tesla GPUs 相比,基于圖靈的 Tesla 板上的 MPS 提高了小批量的推理性能,減少了啟動延遲,提高了服務質量,可以處理更多的并發客戶端請求。
更高的內存帶寬和更大的內存大小
即將推出的基于圖靈的 Tesla 板具有更大的內存容量和更高的內存帶寬,而上一代基于 Pascal 的 Tesla 板針對相似的服務器段,為虛擬桌面基礎設施( VDI )應用提供了更高的用戶密度。
圖靈存儲器結構和顯示特性
本節將深入探討圖靈體系結構的關鍵新內存層次結構和顯示子系統特性。
內存子系統的性能對于應用程序加速至關重要。圖靈改進了主內存、緩存和壓縮架構,以增加內存帶寬并減少訪問延遲。改進和增強的 GPU 計算功能有助于加速游戲和許多計算密集型應用程序和算法。新的顯示和視頻編碼/解碼功能支持更高分辨率和 HDR 功能的顯示器、更先進的 VR 顯示器、數據中心不斷增加的視頻流需求、 8K 視頻制作和其他視頻相關應用。詳細討論了以下特點:
GDDR6 內存子系統
隨著顯示分辨率不斷提高,著色器功能和渲染技術變得更加復雜,內存帶寬和大小在 GPU 性能中扮演著更大的角色。為了保持最高的幀速率和計算速度, GPU 不僅需要更多的內存帶寬,還需要一個大的內存池來提供持續的性能。
NVIDIA 與 DRAM 行業密切合作,開發了世界上第一款使用 HBM2 和 GDDR5X 內存的 GPUs 。現在圖靈是第一個使用 GDDR6 內存的 GPU 架構。
GDDR6 是高帶寬 GDDRAM 內存設計的下一個重大進步。隨著許多高速 SerDes 和 RF 技術的增強,圖靈 GPUs 中的 GDDR6 內存接口電路已經完全重新設計,以實現速度、功率效率和降噪。這種新的接口設計帶來了許多新的電路和信號訓練改進,最大限度地減少了噪聲和工藝、溫度和電源電壓的變化。廣泛的時鐘門控被用來最小化低利用率期間的功耗,從而顯著提高整體功率效率。與 Pascal GPUs 中使用的 GDDR5X 內存相比, Turing 的 GDDR6 內存子系統提供了 14 Gbps 的信令速率和 20% 的能效改進。
實現這種速度提升需要端到端的優化。利用廣泛的信號和電源完整性仿真, NVIDIA 精心設計了圖靈的封裝和電路板設計,以滿足更高的速度要求。例如,信號串擾降低 40% ,這是大型存儲系統中最嚴重的損傷之一。
為了實現 14 Gbps 的速度,內存子系統的各個方面都經過精心設計,以滿足如此高頻率操作所需的高要求標準。設計中的每個信號都經過了仔細的優化,以提供盡可能干凈的內存接口信號(參見 圖 9 )。

二級緩存和 ROPs
圖靈 GPU 除了新的 GDDR6 內存子系統之外,還增加了更大更快的二級緩存。 TU102 GPU 附帶 6mb 的二級緩存,是上一代 GP102 GPU 在 Xp 中使用的 3mb 二級緩存的兩倍。 TU102 還提供比 GP102 更高的二級緩存帶寬。
和上一代 NVIDIA GPU 一樣,圖靈圖靈中的每個 ROP 分區包含 8 個 ROP 單元,每個單元可以處理一個單一的顏色樣本。一個完整的 TU102 芯片包含 12 個 ROP 分區,總共 96 個 ROP 。
圖靈存儲器壓縮
NVIDIA GPUs 利用幾種無損內存壓縮技術,在數據被寫入幀緩沖存儲器時減少對內存帶寬的需求。 GPU 的壓縮引擎有各種不同的算法,這些算法根據數據的特性來確定最有效的壓縮方法。這減少了寫入內存和從內存傳輸到二級緩存的數據量,并減少了客戶端(如紋理單元)和幀緩沖區之間傳輸的數據量。圖靈對 Pascal 最先進的內存壓縮算法進行了進一步的改進,在 GDDR6 的原始數據傳輸速率提高之外,提供了更大的有效帶寬。如 圖 10 , 所示,原始帶寬的增加和通信量的減少意味著圖靈上的有效帶寬比 Pascal 增加了 50% ,這對于保持架構平衡和支持新圖靈 SM 架構提供的性能至關重要。
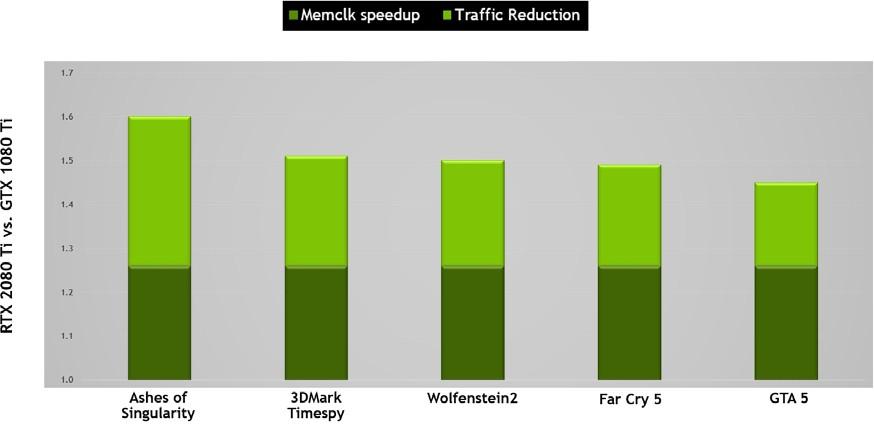
基于圖靈 TU102 的存儲子系統和壓縮(流量減少)改進
RTX 2080 Ti 比基于 Pascal GP102 的 1080 Ti 提供大約 50% 的有效帶寬改進。
視頻顯示引擎
消費者對高分辨率顯示器的需求逐年增加。例如, 8K 分辨率( 7680 x 4320 )需要的像素是 4K ( 3820 x 2160 )的四倍。游戲玩家和硬件發燒友也希望顯示器除了更高的分辨率外,還有更高的刷新率,以體驗盡可能平滑的圖像。
圖靈 GPUs 包括一個全新的顯示引擎,為新一輪的顯示設計,支持更高的分辨率,更快的刷新率,以及 HDR 。圖靈支持 DisplayPort1 . 4a ,在 60Hz 下支持 8K 分辨率,并包括 VESA 的顯示流壓縮( DSC ) 1 . 2 技術,提供更高的壓縮,視覺無損。 表 2 顯示了圖靈 GPUs 中對 DisplayPort 的支持。
| ? | Bandwidth/Lane | Max Resolution Supported |
| DisplayPort 1.2 | 5.4 Gbps | 4K @ 60 Hx |
| DisplayPort 1.3 | 8.1 Gbps | 5K @ 60 Hx |
| DisplayPort 1.4a | 8.1 Gbps | 8K @ 60 Hx |
圖靈 GPUs 可以驅動兩個 60hz 的 8K 顯示器,每個顯示器有一根電纜。 8K 分辨率也可以通過 USB-C 發送(有關更多詳細信息,請參見 ? 下面的 USB-C 和 VirtualLink 部分)。
圖靈的新顯示引擎支持顯示管道中的 HDR 本地處理。色調映射也被添加到了 HDR 管道中。色調映射是一種用于在標準動態范圍顯示器上近似顯示高動態范圍圖像的技術。圖靈支持 ITU-R 建議 BT . 2100 標準定義的色調映射公式,以避免不同 HDR 顯示器上的顏色偏移。
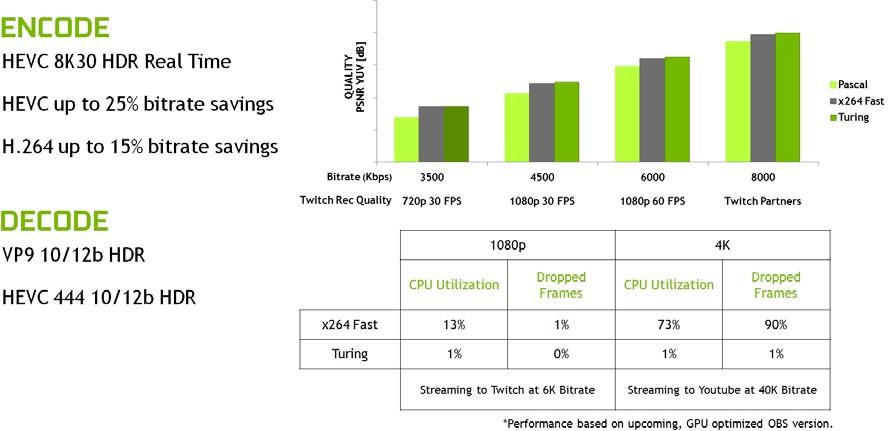
圖靈 GPUs 還附帶了一個增強的 NVENC 編碼器單元,它增加了對 H . 265 ( HEVC ) 8K 編碼的支持,每秒 30 幀。新的 NVENC 編碼器為 HEVC 提供了高達 25% 的比特率節省,為 H . 264 提供了高達 15% 的比特率節省。
圖靈的新 NVDEC 解碼器也已更新,以支持在 30 幀/秒、 H . 264 8K 和 VP9 10 / 12b HDR 解碼 HEVC YUV444 10 / 12b HDR 。
與上一代 Pascal GPU 和軟件編碼器相比,圖靈改進了編碼質量。 圖 11 顯示,在常見的 Twitch 和 YouTube 流媒體設置中, Turing 的視頻編碼器超過了使用 快速的 編碼設置的基于 x264 軟件的編碼器的質量,同時 CPU 利用率顯著降低。在典型的 CPU 設置上, 4K 流對于編碼來說是一個太重的工作負載,但是圖靈的編碼器使 4K 流成為可能。
USB-C 和 VIRTUALLINK
在今天的 PC 機上支持 VR 耳機需要在耳機和系統之間連接多條電纜;一條顯示電纜將圖像數據從 GPU 發送到耳機中的兩個顯示器,一條電纜用于為耳機供電,以及一個 USB 連接,用于傳輸攝像機流并從耳機讀取后頭姿勢信息(以更新由 GPU 渲染的幀)。電纜的數量可能會讓最終用戶感到不舒服,并限制了他們在使用耳機時四處走動的能力。耳機制造商需要適應電纜,使其設計復雜化,并使其體積更大。
為了解決這個問題, Turing GPUs 設計了支持 USB Type-C 的硬件? 和 VirtualLink ?. VirtualLink 是一種新的開放式行業標準,包括領先的硅、軟件和耳機制造商,由 NVIDIA 、 Oculus 、 Valve 、 Microsoft 和 AMD 領銜。
VirtualLink 是為了滿足當前和下一代 VR 耳機的連接需求而開發的。 VirtualLink 采用了一種新的 USB-C 替代模式,旨在通過一個 USB-C 接口提供為 VR 耳機供電所需的電源、顯示器和數據。
VirtualLink 同時支持四個通道的高比特率 3 ( HBR3 )顯示端口,以及連接到耳機的超高速 USB 3 鏈路,用于運動跟蹤。相比之下, USB-C 只支持四個通道的 HBR3 顯示端口 或者 兩個通道的 HBR3 顯示端口+兩個通道的超高速 USB 3 。
除了減輕目前 VR 耳機的安裝麻煩之外, VirtualLink 還將把 VR 應用到更多的設備中。單連接器解決方案將虛擬現實技術帶到可以容納單個、小尺寸 USB-C 連接器(如輕薄筆記本)的小型設備上,而不是現在的虛擬現實基礎設施,后者需要一臺能夠容納多個連接器的 PC 機。
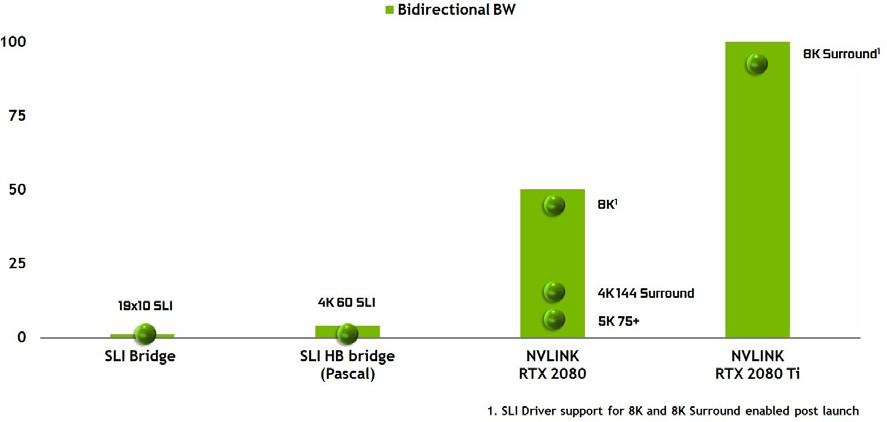
NVLINK 改善了 SLI
在 Pascal GPU 架構之前, NVIDIA GPUs 使用單個多輸入/輸出( MIO )接口作為 SLI 橋接技術,允許第二個(或第三個或第四個) GPU 將其最終渲染幀輸出傳輸到物理連接到顯示器的主 GPU 。帕斯卡通過使用更快的雙 MIO 接口增強了 SLI 橋,提高了 GPUs 之間的帶寬,允許更高分辨率的輸出,以及 NVIDIA 環繞的多個高分辨率監視器。
圖靈 TU102 和 TU104 GPUs 使用 NVLink 代替 MIO 和 PCIe 接口進行 SLI GPU – GPU 數據傳輸。圖靈 TU102 GPU 包括兩個 x8 第二代 NVLink 鏈路, Turing TU104 包括一個 x8 第二代 NVLink 鏈路。每條鏈路在兩個 GPUs 之間的每個方向提供 25 GB / s 的峰值帶寬( 50 GB / s 雙向帶寬)。雙向鏈路為 100 GB /秒,或每秒鐘提供兩個 GB /秒的雙向鏈路。具有 NVLink 的圖靈 GPUs 支持雙向 SLI ,但不支持 3 路和 4 路 SLI 配置。
與以前的 SLI 網橋相比,新的 NVLink 網橋的帶寬增加了以前不可能實現的高級顯示拓撲(參見 圖 12 )。
啟動和 8POST 驅動支持將啟用。
圖靈射線追蹤技術
光線跟蹤是一種計算密集的渲染技術,可以真實地模擬場景及其對象的照明。基于圖靈 GPU 的光線跟蹤技術可以實時渲染物理上正確的反射、折射、陰影和間接照明。有關光線跟蹤如何工作的詳細信息可以在完整的 圖靈白皮書 中找到。
在過去, GPU 體系結構無法使用單個 GPU 為游戲或圖形應用程序執行實時光線跟蹤。盡管 NVIDIA 的 GPU 加速 NVIDIA Iray ?插件和 OptiX 光線跟蹤引擎多年來一直為設計師、藝術家和技術總監提供逼真的光線跟蹤渲染,但高質量的光線跟蹤效果無法實時執行。類似地,當前的 NVIDIA Volta GPUs 可以渲染逼真的電影級光線跟蹤場景,但不能在單個 GPU 上實時渲染。由于其處理密集的性質,光線跟蹤在游戲中尚未用于任何重要的渲染任務。相反,需要 30 到 90 幀/秒動畫的游戲多年來一直依賴快速 GPU 加速光柵化渲染技術,而犧牲了完全逼真的場景。
在 GPUs 上實現實時光線跟蹤是一個巨大的技術挑戰,需要 NVIDIA 的研究、 GPU 的硬件設計和軟件工程團隊進行近 10 年的合作。通過在圖靈 TU102 、 TU104 和 TU106 GPUs 中加入稱為 RT Cores 的多個新的基于硬件的光線跟蹤加速引擎,結合 NVIDIA RTX 軟件技術 . ,使得游戲和其他應用中的實時光線跟蹤成為可能
在圖靈 TU102 GPU 上實時運行的采用 RTX NVIDIA 技術的 NVIDIA SOL ray Tracking demo 的 SOL MAN 如 圖 13 ( 參見演示 )。
如前所述,光柵化技術多年來一直是實時渲染的規范,尤其是在計算機游戲中,雖然許多光柵化場景看起來非常好,但基于光柵化的渲染有很大的局限性。例如,僅使用光柵化渲染反射和陰影需要簡化可能導致許多不同類型瑕疵的假設。類似地,靜態光照貼圖可能看起來是正確的,直到有東西移動,光柵化陰影通常會出現鋸齒和光泄漏,屏幕空間反射只能反射屏幕上可見的對象。這些人工制品有損于游戲體驗的真實感,對于開發者和藝術家來說,試圖用額外的效果來修復是非常昂貴的。
圖 13 。來自 NVIDIA 的 SOL MAN 太陽射線追蹤演示
雖然光線跟蹤可以產生比柵格化更真實的圖像,但它也需要大量的計算。我們發現最好的方法是混合渲染,光線跟蹤和光柵化的結合。使用這種方法,光柵化用于最有效的地方,而光線跟蹤用于與光柵化相比提供最大視覺好處的地方,例如渲染反射、折射和陰影。 圖 14 顯示混合渲染管道。
混合渲染結合了渲染管道中的光線跟蹤和光柵化技術,以充分利用每種技術在渲染場景時的最佳效果。 SEED 為他們的 PICA-PICA 實時光線跟蹤實驗使用了一個混合的渲染模型,該實驗在程序化組裝的世界中具有自學習代理。 PICA-PICA 使用 SEED 的研發引擎 Halcyon 構建,使用 microsoftdxr 和 NVIDIA GPUs 實現實時光線跟蹤。

光柵化和 z 緩沖在確定對象可見性方面要快得多,并且可以替代光線跟蹤過程中的主要光線投射階段。然后,可以使用光線跟蹤來拍攝次光線,以生成高質量的物理校正反射、折射和陰影。
開發人員還可以使用材質屬性閾值來確定要在場景中執行光線跟蹤的區域。一種技術是規定只有具有一定反射率水平(比如 70% )的表面才會觸發是否應在該表面上使用光線跟蹤來生成二次光線。
我們期望許多開發人員使用混合光柵化/光線跟蹤技術來獲得高幀速率和出色的圖像質量。或者,對于圖像保真度是最高優先級的專業應用程序,我們希望看到在整個渲染工作負載中使用光線跟蹤,投射主光線和次光線以創建令人驚嘆的逼真渲染。
圖靈 GPUs 不僅包括專用的光線跟蹤加速硬件,還使用了下一節描述的高級加速結構。本質上,一個全新的渲染管道可以使用單個圖靈 GPU 在游戲和其他圖形應用程序中實現實時光線跟蹤(參見 圖 15 )。
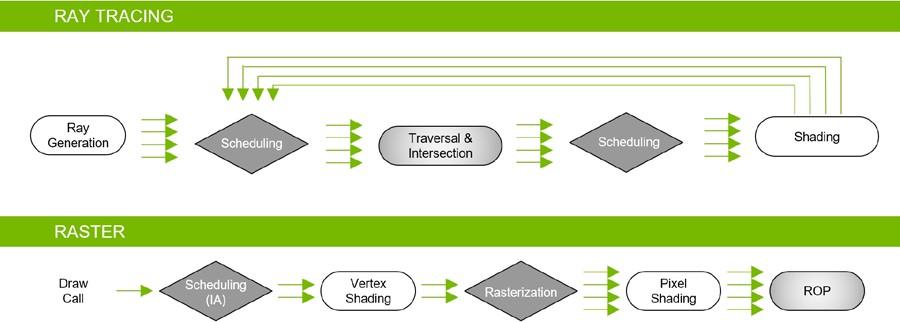
在圖靈 GPUs 中使用的混合繪制模型中,光線跟蹤和光柵化流水線同時工作并協同工作。
雖然圖靈 GPUs 支持實時光線跟蹤,但每個像素或曲面位置投射的主光線或次光線數量會根據許多因素而變化,包括場景復雜性、分辨率、場景中渲染的其他圖形效果,當然還有 GPU 馬力。不要期望每像素實時投射數百條光線。事實上,當使用圖靈 -RT 核心加速與先進的去噪濾波技術相結合時,每像素所需的光線要少得多。
NVIDIA 實時光線跟蹤去噪模塊可以顯著減少每個像素所需的光線數,并且仍然可以產生出色的效果。
對選定對象的實時光線跟蹤可以使游戲和應用程序中的許多場景看起來與高端電影特效一樣逼真,或與使用基于專業軟件的非實時渲染應用程序創建的光線跟蹤圖像一樣逼真。 圖 16 顯示了 Epic Games 與 ILMxLAB 和 NVIDIA 合作創建的反射演示示例。
光線跟蹤反射、光線跟蹤區域光陰影和光線跟蹤環境光遮擋可以在單個四邊形 RTX 6000 或 GeForce RTX 2080 Ti GPU 上運行,提供幾乎無法與電影區分的渲染質量,如這個不真實的引擎演示所示。
圖 16 。虛幻引擎反射光線跟蹤演示
圖靈光線跟蹤硬件與 NVIDIA 的 RTX 光線跟蹤技術、 NVIDIA 實時光線跟蹤庫、 NVIDIA OptiX 、 Microsoft DXR API 和即將推出的 Vulkan 光線跟蹤 API 一起工作。用戶將在游戲中以可播放的幀速率體驗實時、電影級的光線跟蹤對象和角色,或者在專業圖形應用程序中體驗到視覺真實感,而這在以前的 GPU 架構中是不可能實現的。
圖靈 GPUs 可以加速光線跟蹤技術,用于以下許多渲染和非渲染操作:
反射和折射
陰影和環境光遮擋
全局照明
即時離線光照圖烘焙
美女照片和高質量預覽
用于中心凹虛擬現實繪制的主光線
遮擋剔除
物理學,碰撞檢測,粒子模擬
音頻模擬(例如, NVIDIA VRWorks 音頻構建在 OptiX API 之上)
AI 可見性查詢
引擎內路徑跟蹤(非實時)生成參考屏幕截圖,用于調整實時渲染技術和去噪器、材質合成和場景照明。
在下面的章節中,將詳細介紹使用圖靈光線跟蹤加速渲染光線跟蹤陰影、環境光遮擋和反射。 NVIDIA 開發者網站 有更詳細的描述可以用圖靈光線跟蹤加速的渲染操作。
圖靈 RT 核
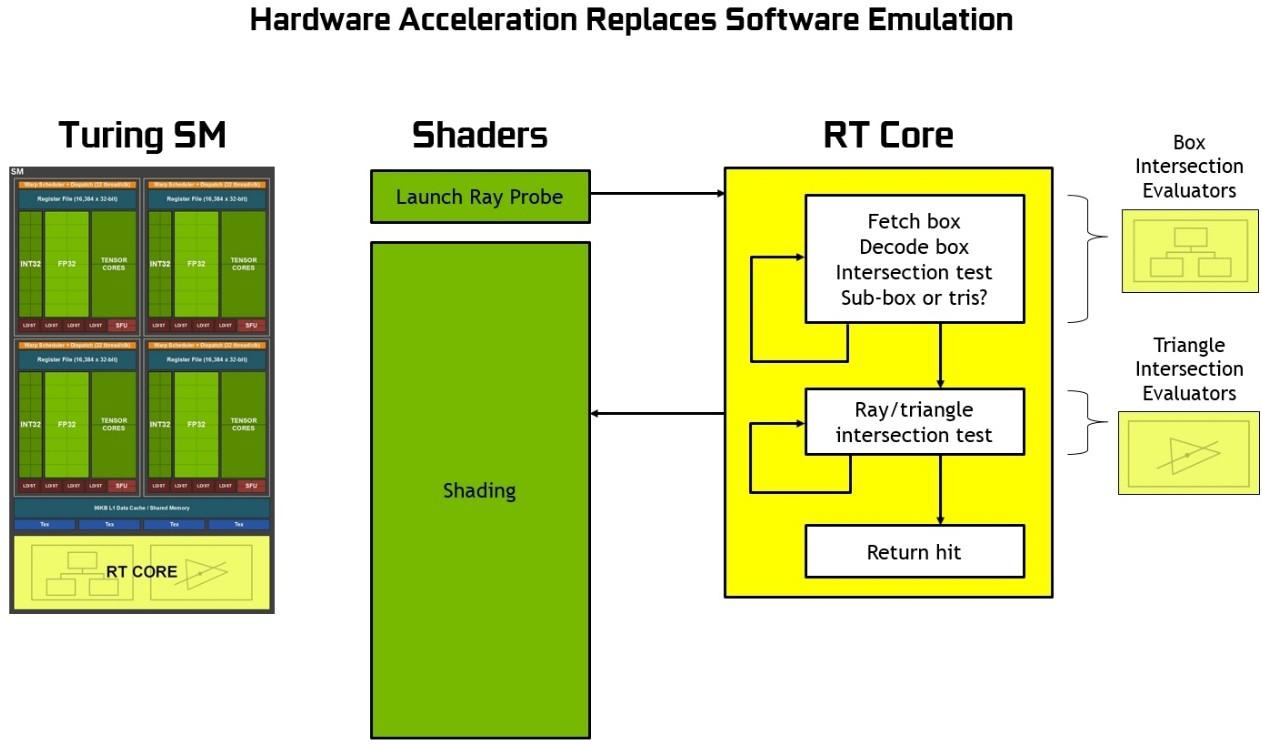
圖靈基于硬件的光線跟蹤加速的核心是每個 SM 中包含的新 RT 核心。 RT 核心加速邊界層( BVH )遍歷和光線/三角形相交測試(光線投射)功能。 RT 核心代表在 SM 中運行的線程執行可見性測試。
RT 核與先進的去噪濾波、由 NVIDIA 研究所開發的高效 BVH 加速結構以及與 RTX 兼容的 api 一起工作,以在單個圖靈 GPU 上實現實時光線跟蹤。 RT 核心自動遍歷 BVH ,通過加速遍歷和光線/三角形相交測試,他們卸載了 SM ,允許它處理其他頂點、像素和計算著色工作。諸如 BVH 構建和重新安裝等功能由驅動程序處理,光線生成和著色由應用程序通過新型著色器進行管理。
為了更好地理解 RT 核心的功能,以及它們究竟加速了什么,我們首先應該解釋在沒有專用硬件光線跟蹤引擎的情況下如何在 GPUs 或 CPU 上執行光線跟蹤。本質上, BVH 遍歷的過程需要通過著色操作來執行,并且每光線投射需要數千個指令槽來測試 BVH 中的包圍盒相交,直到最后碰到一個三角形,并且相交點的顏色對最終像素顏色有貢獻(或者如果沒有碰到三角形,則背景顏色可用于著色像素)。
沒有硬件加速的光線跟蹤需要每個光線數千個軟件指令槽來連續測試 BVH 結構中較小的邊界框,直到可能碰到三角形為止。這是一個計算密集的過程,如果沒有基于硬件的光線跟蹤加速,就不可能在 GPUs 上進行實時操作(請參見 圖 17 )。
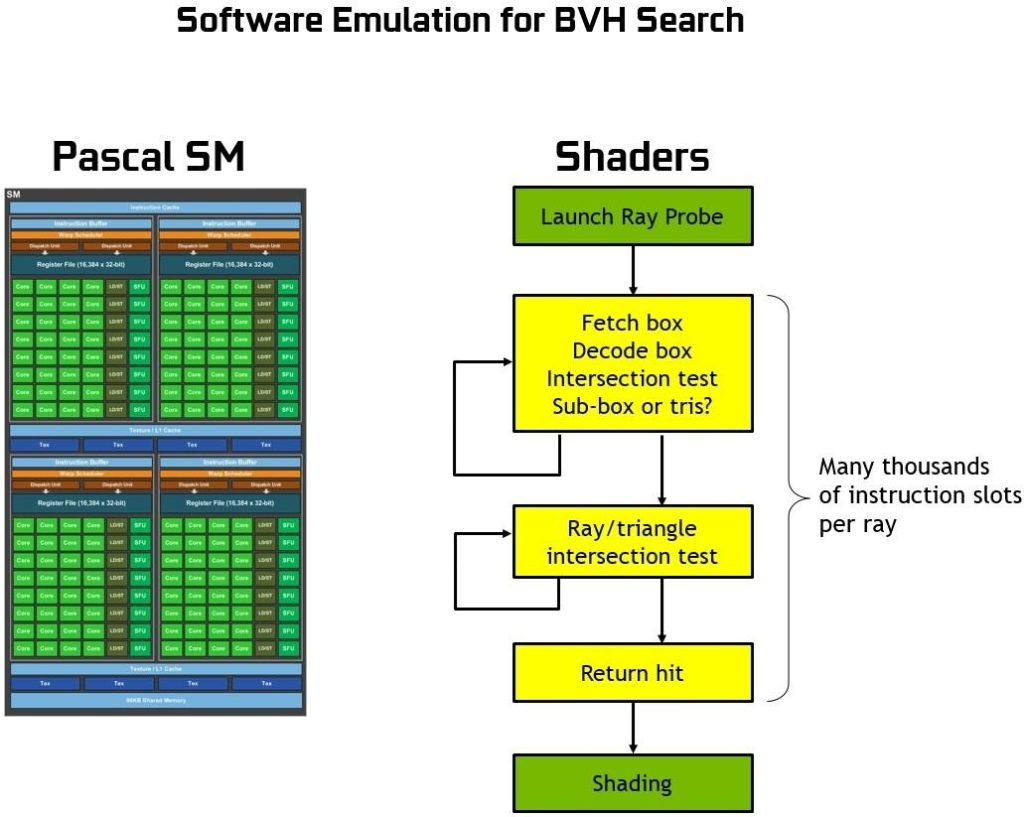
圖靈中的 RT 核可以處理所有的 BVH 遍歷和射線三角形相交測試,從而節省了 SM 在每條光線上花費數千個指令槽的開銷,這可能是整個場景的大量指令。 RT 核心包括兩個專門單元。第一個單元執行邊界框測試,第二個單元執行光線三角形相交測試。 SM 只需啟動一個光線探測器, RT 核心進行 BVH 遍歷和光線三角形測試,并返回一個命中或未命中 SM 。 SM 在很大程度上被騰出去做其他的圖形或計算工作。參見圖 18 或使用 RT 核心的圖靈射線追蹤圖。
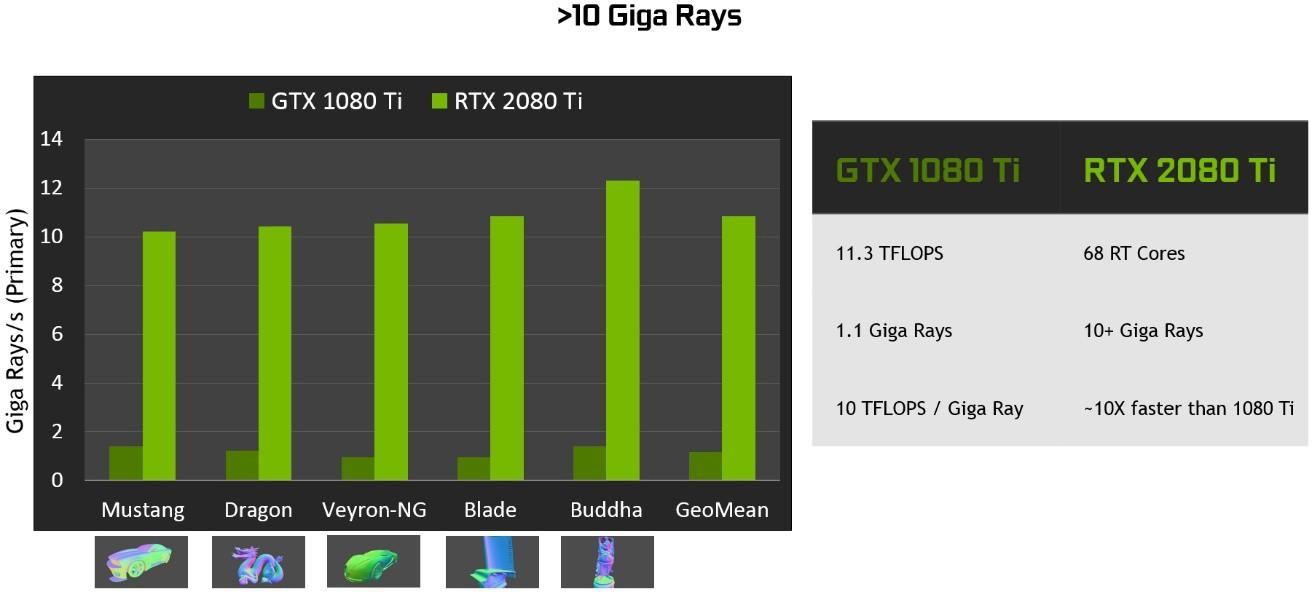
在 Pascal GPUs 中, RT 核的圖靈射線跟蹤性能明顯快于光線跟蹤。在不同的工作負載下,圖靈可以比 Pascal 提供更多的千兆射線/秒,如 圖 19 。 所示, Pascal 在軟件中花費大約 1 . 1 千兆射線/秒,或 10 TFLOPS / gigaray 來進行光線跟蹤,而圖靈可以使用 RT 核來實現 10 + Giga 射線/秒,并且運行光線跟蹤的速度是 Pascal 的 10 倍。
深度學習超級抽樣( DLSS )
在現代游戲中,渲染幀不是直接顯示的,而是經過一個后處理圖像增強步驟,該步驟將來自多個渲染幀的輸入合并在一起,試圖在保留細節的同時去除諸如鋸齒之類的視覺偽影。例如,時間反走樣( TAA )是一種基于著色器的算法,它使用運動矢量將兩個幀組合在一起,以確定在何處對前一幀進行采樣,這是當今最常用的圖像增強算法之一。然而,這種圖像增強過程從根本上說是很難實現的。
NVIDIA 的研究人員認識到,這類問題——一個沒有清晰算法解決方案的圖像分析和優化問題——將是人工智能的完美應用。正如本文前面所討論的,圖像處理案例(例如 ImageNet )是深度學習最成功的應用之一。深度學習現在已經取得了超人的能力,可以通過觀察圖像中的原始像素來識別狗、貓、鳥等。在這種情況下,目標將是結合渲染圖像,基于觀察原始像素,以產生高質量的結果 – 一個不同的目標,但使用相似的能力。
為解決這一難題而開發的深度神經網絡( DNN )被稱為深度學習超級采樣( DLSS )。 DLSS 從一組給定的輸入樣本中產生比 TAA 更高質量的輸出,我們利用這種能力來提高整體性能。
雖然 TAA 在最終目標分辨率下渲染,然后合并幀,減去細節, DLSS 允許以較低的輸入采樣數進行更快的渲染,然后推斷出在目標分辨率下質量與 TAA 結果相似的結果,但著色工作只有一半。
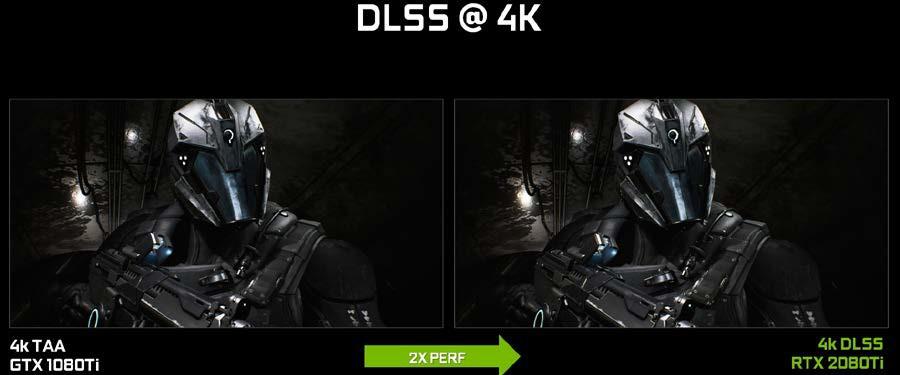
下面的 圖 20 , 顯示了 UE4 滲透器演示的結果示例。 DLSS 提供了與 TAA 類似的圖像質量,并大大提高了性能。 RTX 2080 Ti 更快的原始渲染馬力,加上 DLSS 和張量核心的性能提升,使 RTX 2080 Ti 的性能達到 GTX 1080 Ti 的兩倍。
這一結果的關鍵是 DLSS 的培訓過程,在培訓過程中, DLSS 有機會學習如何根據大量超高質量的示例生成所需的輸出。為了訓練網絡,我們收集了數以千計的“真實”參考圖像,這些參考圖像采用了完美圖像質量的黃金標準方法 64x 超采樣( 64xSS )。 64x 超采樣意味著我們不必對每個像素進行一次著色處理,而是在像素內以 64 個不同的偏移量進行著色處理,然后結合輸出,生成具有理想細節和抗鋸齒質量的結果圖像。我們還捕捉匹配的原始輸入圖像正常渲染。接下來,我們開始訓練 DLSS 網絡以匹配 64xSS 輸出幀,方法是遍歷每個輸入,要求 DLSS 生成一個輸出,測量其輸出與 64xSS 目標之間的差異,并根據差異通過稱為反向傳播的過程調整網絡中的權重。
經過多次迭代后, DLSS 會自行學習生成接近 64xs 質量的結果,同時也會學習避免影響 TAA 等經典方法的模糊、混淆和透明性問題。
除了上述 DLSS 功能(標準 DLSS 模式)之外,我們還提供了第二種模式,稱為 DLSS 2X 。在這種情況下, DLSS 輸入將以最終目標分辨率呈現,然后由更大的 DLSS 網絡組合,生成接近 64x 超級采樣渲染級別的輸出圖像–這一結果將用任何傳統方法都不可能實時實現。圖 21 顯示了 DLSS 2X 模式的運行,提供的圖像質量非常接近參考 64x 超級采樣圖像。

最后,圖 22 說明了多幀圖像增強的一個具有挑戰性的案例。在這種情況下,一個半透明的屏幕漂浮在移動不同的背景前面。 TAA 傾向于盲目跟蹤運動對象的運動矢量,模糊了屏幕上的細節。 DLSS 能夠識別出場景中的變化更為復雜,并以更智能的方式組合輸入,從而避免模糊問題。

總結
圖形剛剛被革新。新的 NVIDIA Turing GPU 架構是有史以來最先進、最高效的 GPU 架構。圖靈實現了一種新的混合渲染模型,它結合了實時光線跟蹤、柵格化、人工智能和模擬。圖靈與下一代圖形 API 相結合,為 PC 游戲和專業應用程序帶來了巨大的性能提升和難以置信的逼真圖形。
未來的博客文章將包括更多關于圖靈高級著色器技術的細節。如果您想深入研究圖靈架構,請下載完整的 NVIDIA 圖靈體系結構白皮書 。您也可以在 RTX 開發者頁面 上找到有關 RTX 技術的更多信息,或者閱讀如何 RTX 和 directx12 射線跟蹤工作 here 。
?