由于 深度學習?的進步和矢量嵌入的使用,推薦模型近年來進展迅速。這些模型日益復雜,需要強大的系統來支持它們,在生產中部署和維護這些模型可能具有挑戰性。
在論文 Monolith: Real Time Recommendation System With Collisionless Embedding Table 中,字節跳動詳細介紹了他們如何構建一個推薦系統,以支持在線培訓、滾動嵌入更新、容錯等。
這篇文章詳細介紹了離線、在線和在線大型推薦系統架構。我們專注于部署,使用構建塊框架 NVIDIA Merlin 和實時數據層 Redis 構建端到端推薦系統的示例。最后,我們提供了云部署說明和管理的 Redis 選項,用于生產就緒和簡化架構。
下載 RedisVentures/Redis-Recsys GitHub 存儲庫中的代碼,并查看相關資產以遵循每個示例。提供了 Terraform 腳本和可解釋的劇本,以幫助在 Amazon Web 服務上部署此基礎設施。
請參加 GTC 2023 ,參加我們即將舉行的演講 Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton ,以獲得有關優化推薦系統以降低延遲的提示。
推薦系統架構
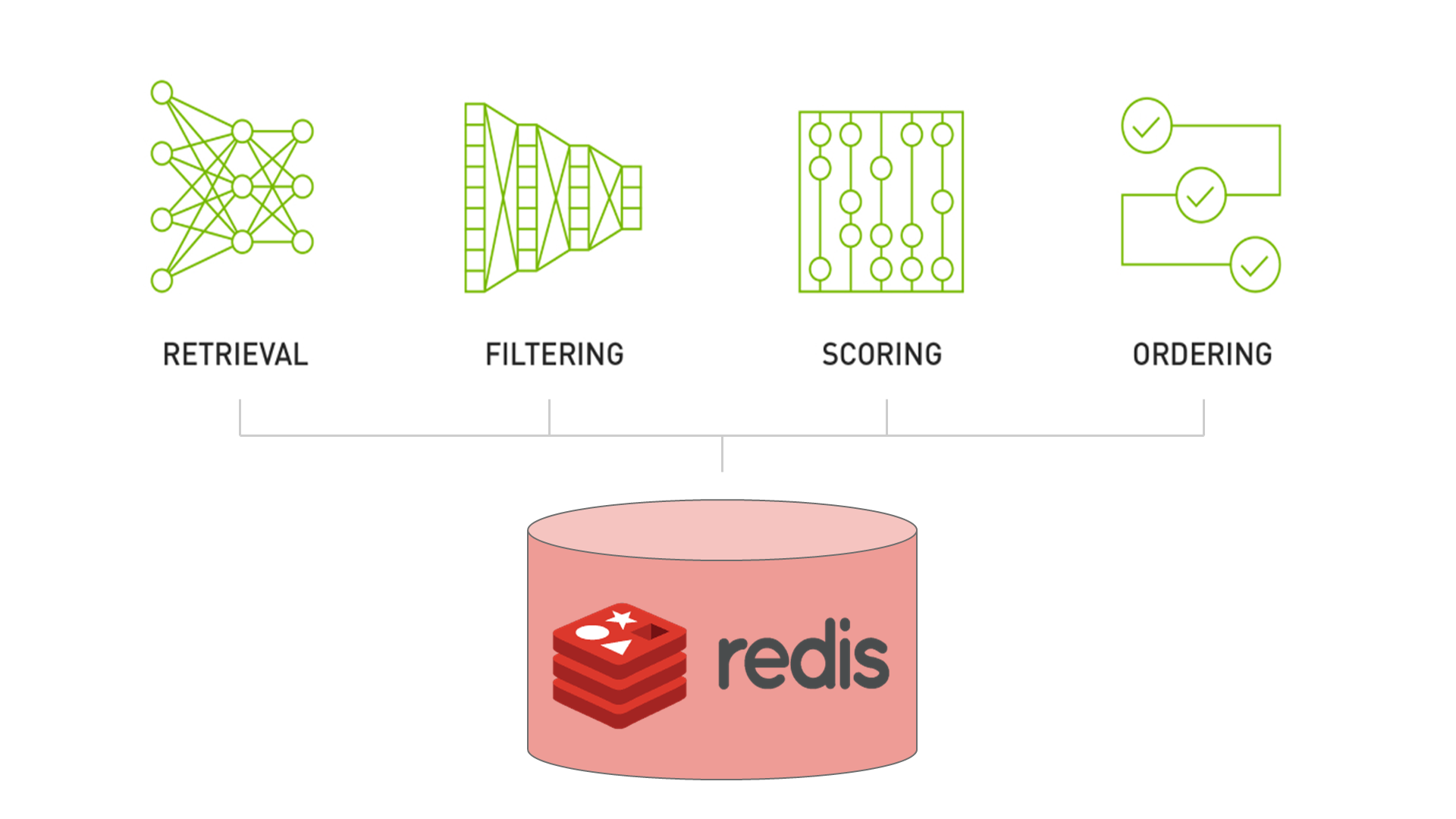
NVIDIA Merlin 推薦系統依賴于 Recommender Systems, Not Just Recommender Models 中討論的四階段模式:
- 檢索包含用戶最終將參與的項目的合理相關集合。
- 過濾模型幾乎不可能強制執行的不需要的項目。
- 對用戶可能對一組項目產生的興趣進行評分(或排名)。
- 對項目進行排序,使模型的輸出與業務的其他需求或約束保持一致。
這四個階段的檢索、過濾、評分和排序構成了一個設計模式,涵蓋了大多數推薦系統在生產中的外觀(圖 1 )。對于這篇文章,我們使用 scoring 和 ranking 同義。我們只關注檢索和評分階段,因為它們是推薦系統的計算密集型階段。
檢索階段
retrieval 過程通常很快,但粒度較粗。從大量潛在候選人中選擇相關子集。在這一步驟中,效率高于精度。
在現代檢索系統中,通過將所有潛在項目傳遞給深度學習模型,將候選目錄轉化為密集嵌入。當使用 RediSearch 或 FAISS 進行索引時,可以比較數百萬個嵌入,并且可以在低延遲下檢索最相似的候選嵌入。
排名階段
在 ranking 工藝中,精度比效率更受青睞。因此,排名模型通常比檢索階段更復雜。由于深度學習的進步,排名階段可以包含比以前更多的數據。
Meta 生產的深度學習推薦模型( DLRM )等模型用于排名階段,可以學習對給定用戶的數百萬候選人進行排名。然而,輸入僅限于幾千個候選項。
大規模排名系統通常應用兩個或多個子階段,即粗略排名和精細排名或重新排名,以利用更復雜的方法或注入額外的信息來影響最終結果。結合起來,隨著計算成本的增加,他們進一步縮小了候選人數。
有關推薦系統體系結構的更多信息,請參見 System Design for Recommendations and Search 。本文介紹了一些頂級公司部署的示例。
雖然我們使用術語 offline 來指代整個推薦系統的部署架構,但 Eugene Yan 將 offline 稱為模型訓練階段。
離線推薦系統
Offline recommendation systems 使用批處理計算來處理大型數據集并存儲建議以供以后檢索。
批量計算對于那些負擔不起托管實時多階段推薦系統的復雜性或必須快速啟動和運行的開發人員來說尤其有用。這些系統非常適合于業務目標,這些業務目標只能在一定時間間隔內刷新,但需要高精度,因此需要額外的計算時間。示例包括定期新聞通訊或電子郵件活動。
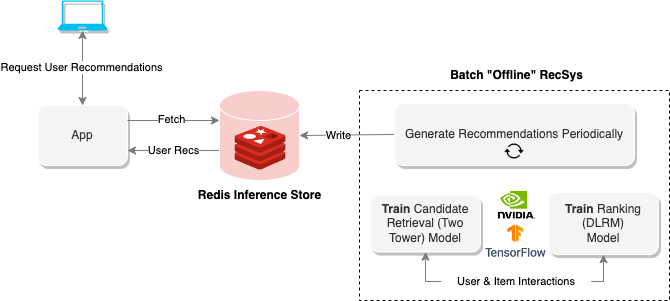
圖 2 顯示了 Redis 純粹用于推薦存儲和檢索的離線體系結構。筆記本 Offline Batch Recommender System 演示了如何為 Alibaba Click and Conversion Prediction dataset 創建這樣的系統。
檢索:雙塔
候選檢索模型是雙塔神經網絡結構。 user tower 為用戶偏好建模,而 item tower 為項目特性建模。
筆記本示例在訓練期間使用負抽樣。該模型使用隱式反饋 , ,例如用戶交互或點擊,而不是使用顯式反饋,例如用戶評分或分數。經過訓練的嵌入用于將整個項目目錄縮小到給定用戶最可能與之交互的項目目錄。嵌入還可以用于其他電子商務用例中的項目或用戶用戶相似性,例如基于內容的推薦或客戶細分。
等級: DLRM
排名模型是推薦系統中常用的一種 機器學習?模型,用于基于用戶交互的相關性或可能性對項目進行排名。這些模型可以通過考慮用戶偏好和過去的交互(如點擊、購買或評分)來生成個性化推薦。
Jupyter 筆記本示例使用 DLRM ,這是一種混合模型架構,可對用戶項對進行評分和排序。有關 DLRM 體系結構的更多信息,請參閱 Exporting Ranking Models 筆記本。
生成和提供建議
推薦系統的最后一部分是在低延遲數據層中托管生成的推薦。關鍵價值存儲(如 Redis )使您能夠接近實時地訪問推薦,而無需為在線推薦系統托管基礎設施。
下一節將解釋如何使用剛才描述的管道并部署實時服務層以在線生成建議。
在線推薦系統
在線推薦系統按需生成推薦。與面向批處理的系統不同,可擴展性和端到端延遲(通常< 100-300ms )通常是最重要的因素。
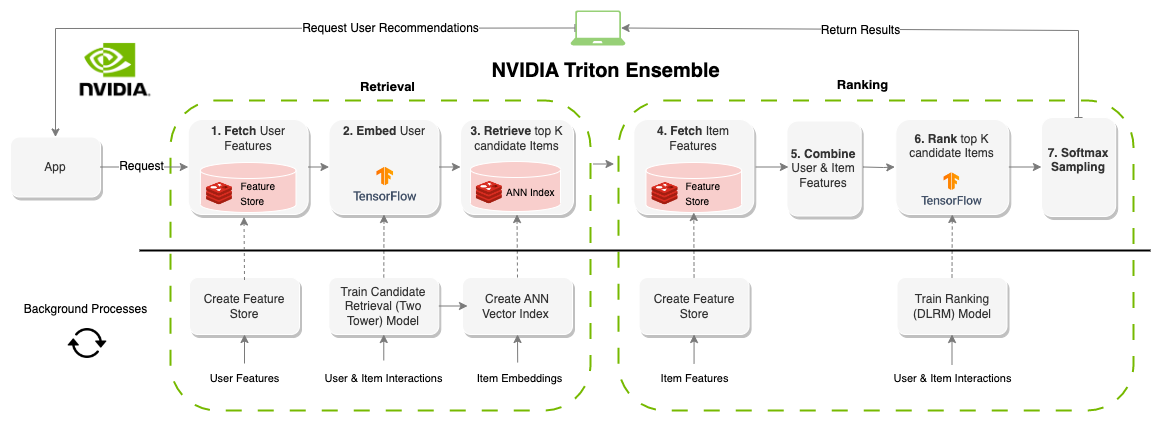
本節介紹了構建具有功能存儲( Redis )、編排( Feast )、矢量數據庫和搜索( Redi )以及推理( NVIDIA Triton )的在線推薦系統所需的基礎設施。
然后,我們介紹了一個 set of notebooks ,它概述了如何使用 NVIDIA Triton 推理服務器 ensemble 功能將這個基礎設施聯系在一起。
功能存儲
兩種廣泛部署的 feature stores 與推薦系統的二分法非常相似,分別是離線和在線商店。
脫機功能存儲
offline feature store 通常是一個持久的、基于磁盤的數據庫,具有大容量(> 10 TB )。所有模型功能,包括歷史功能,都保存在離線商店中。像 Apache Spark 這樣的批處理框架通常用于以指定的間隔將功能從離線商店具體化到在線功能商店。例如, Spark-Redis 經常用于將功能加載到 Redis 。
在線功能商店
Online feature stores 權衡容量以減少延遲,通常將功能保留在內存中。一部分功能從離線商店具體化到在線商店中,這樣“最新鮮”的功能就可以保留下來。在線商店在服務管道中被直接查詢,以提供具有豐富特征向量的機器學習模型用于推斷。
在第二個示例中, Redis 被用作在線功能商店,用戶和項目功能從拼花文件(離線商店)中具體化。 Feast 是一個功能編排框架,用于在運行時定義功能、配置具體化和查詢模型功能。
服務嵌入
在離線示例中,使用雙塔模型將用戶和項目編碼為嵌入。然而,對于在線服務,僅通過使用用戶塔并部署矢量數據庫來托管和搜索項目嵌入,可以減少系統的總體延遲。
除了減少延遲外,矢量數據庫還可以在不中斷查詢服務的情況下更新嵌入。脫機筆記本將創建的項目嵌入保存到文件中,以便聯機筆記本可以演示如何設置此系統。
Redis 除了用作在線功能商店外,還用作 RediSearch 模塊的近似最近鄰居 index of the item embeddings 。 RediSearch 在 2.4 版中增加了對向量索引的支持。
筆記本 Building Online Multi-Stage Recsys Components 展示了如何設置 Feast 和 Redis 以進行特征存儲和向量嵌入搜索。
提供實時建議
NVIDIA Triton 是一款 inference serving platform ,具有 number of backends 以支持不同的型號和管道。集成后端允許您定義在有向非循環圖( DAG )中運行的多個步驟。設置 Feast 和 Redis 后,您可以定義一個 NVIDIA Triton 集成(圖 3 ),該集成在給定user_id值的情況下按需執行推薦系統管道。
Deploying Online Multi-Stage RecSys with Triton Inference Server 筆記本顯示了如何定義 NVIDIA Triton 集成,并提供了如何使用 NVIDIA Triton Python 客戶端查詢該集成的示例。
設計注意事項
盡管該系統支持實時推薦,但仍有一些設計考慮因素需要考慮。
首先,用戶功能必須定期從離線功能商店發布到在線功能商店。例如,在電子商務網站上執行操作的用戶可能會看到靜態推薦,除非功能物化足夠頻繁。但是,如果執行得太頻繁,對 Redis 的寫入次數會降低讀取吞吐量,并降低服務管道的速度。找到平衡是關鍵。
其次,必須監控訓練模型的特征漂移。隨著特征從訓練集所包含的內容更新,模型性能可能會隨著時間的推移而改變。為了保持性能,模型應經過重新培訓并隨時間更新。此外,在更新模型時,應更新向量索引中存儲的嵌入。使用 Redis ,可以直接對索引進行增量向量更新,也可以在后臺創建新的向量索引,并使用 FT.ALIASADD 命令進行交換。
在線、大規模
大型企業通常擁有數百萬用戶和項目。模型的整個嵌入表可能不適合單個 GPU 。
為此, NVIDIA Merlin 創建了 HugeCTR 后端,該后端支持分布式培訓、更新和推薦模型服務
筆記本 Large-Scale Recommender Models 專注于 HugeCTR 部署,并提供了可用于示例的 DLRM 的預訓練版本。有關 HugeCTR 分布式培訓的更多信息,請參見 Scaling Recommendation System Inference with Merlin Hierarchical Parameter Server 。
與 HugeCTR 一起服務
參考筆記本中部署的 DLRM 模型與上一節中的排名模型在線推薦系統相同。本節將進一步探討排名階段,以描述 HugeCTR 如何實現多級推薦系統排名階段所需的能力水平。
HugeCTR 使排名模型成為可能,該模型可以解釋數百萬用戶項交互,從而創建精確但計算成本高昂的模型。如上所述,排名階段通常比檢索更慢、更精確,通常占分配給給定用例的可用時間預算的很大一部分。
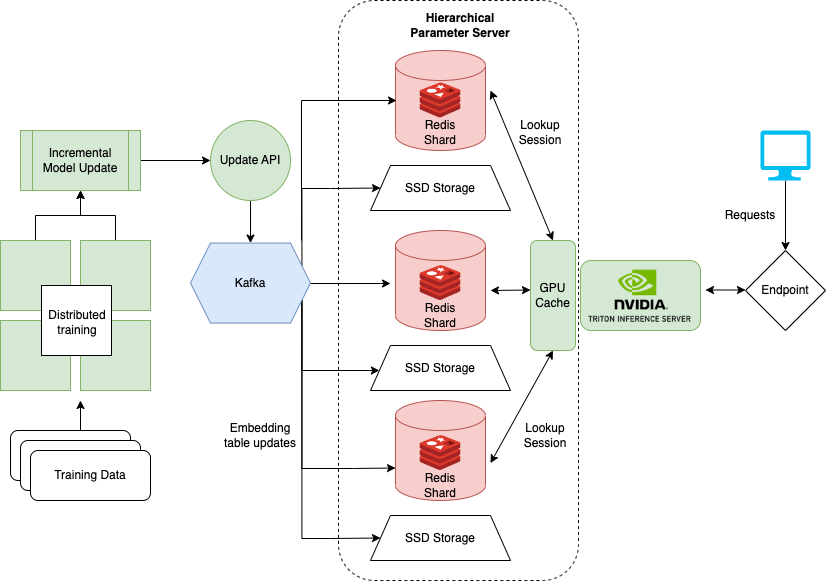
分級參數服務器
HugeCTR 通過使用分層參數服務器( HPS )在多個服務器上分發嵌入,如圖 4 所示。 HPS 是一個分層存儲系統,它在三個不同的位置緩存嵌入內容,逐漸以速度換取容量。
GPU 緩存層
GPU 緩存保存最頻繁訪問的嵌入,這些嵌入最接近于它們將用于推斷的位置。由于 GPU 上已有嵌入,因此在推斷時數據移動延遲會減少。通常,嵌入的訪問模式模仿冪律,通過用盡可能多的嵌入填充 GPU 緩存來獲得最大的好處。
CPU 存儲層
CPU 存儲層的容量大于 GPU 緩存。然而,在推斷之前,數據必須移動到 GPU ,并且在推斷時訪問速度較慢。 HPS 中的 CPU 內存層實現了多種方法,例如分布式哈希映射。筆記本示例使用 Redis 在內存中緩存嵌入。 HugeCTR 完全支持 Redis 集群在服務器之間分配嵌入表內存。
SSD 層
SSD 層是 HPS 中最大和最慢的層。整個嵌入表保存在 SSD 層中。該層保證了分布式嵌入表在發生故障時不會丟失,因為每個服務器都包含所有模型的一整套嵌入表。
滾動更新
更新嵌入是托管在線推薦系統的必要部分。在在線推薦系統示例中,我們依靠 Redis 功能在后臺進行更新。然而,更新沒有解決訓練的 DLRM 模型所使用的嵌入表。
相反,必須更新模型以避免特性和模型漂移問題。通過將新版本的 DLRM 上載到 NVIDIA Triton ,可以實現更新。然而,大型模型(如使用 HugeCTR 框架訓練的模型)不容易更新,因為它們的總大小可達 TB 。
為了解決大規模模型, NVIDIA 使用 Kafka 實現了一個滾動更新系統,該系統將更新的嵌入作為 Kafka 管道中的消息發送到運行 HugeCTR 后端的 NVIDIA Triton 服務器。因此, DLRM 模型的在線訓練可以與發球同時進行。這種在線的大規模架構與 Monolith: Real-Time Recommendation System with Collisionless Embedding Table 中討論的架構非常相似。
基于云的部署
隨附的筆記本提供了如何配置和部署 NVIDIA Triton 以及 HugeCTR 后端和 HPS 以及 Docker (本地)和 AWS 上的 Terraform (云)的示例。然而,在某些情況下,自行管理 HPS 基礎設施的部署可能不太理想。
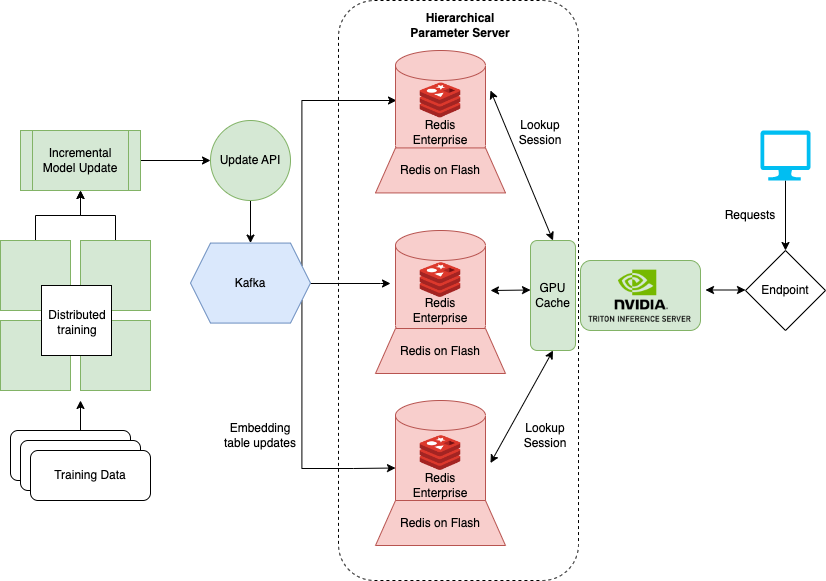
有許多 Redis 提供商推出并管理大規模運行 HPS 所需的大部分基礎設施。一個選項 Redis Enterprise 提供了部署在云中的 Redis 的托管版本,并簡化了 HPS 的基礎架構。
在圖 5 中,基于 RocksDB 的 SSD 層被 Redis Enterprise flash capability ( RoF )所取代。使用 RoF ,您可以直接在 Redis 中調整 SSD 和閃存之間的比率,而無需在 NVIDIA Triton 中重新部署 HugeCTR 型號。這在調整交通高峰和低谷時是有益的。
對于現有的 RocksDB 層,每個模型的嵌入表都存儲在每個推理節點上,以提高系統可用性。這樣,在發生災難性事件時,可以恢復模型參數和推理服務,前提是至少有一個計算實例處于活動狀態。相反, RoF 通過跨 Redis 數據庫的碎片分發復制來降低總體 HPS 存儲需求。
Redis Enterprise 通過進一步切分數據庫,為故障切換時間、可用性( 99.999% )、 active-active geo distribution 和可擴展 IOPS 提供 SLA 。用于更新嵌入的 Kafka 消息的訂閱者數量也減少到單個端點。提供了這種體系結構,整個服務器變得更簡單、更易于維護。
RedisVentures/Redis-Recsys GitHub 存儲庫提供 Terraform scripts and Ansible playbooks 在 AWS 上啟動此基礎設施。
總結
本文描述了使用 NVIDIA Merlin 框架創建推薦系統的三種不同用例,其中 Redis 是實時數據層。每個用例都提供了低延遲解決方案,即使在數據擴展時,尤其是對于計算復雜的應用程序。
在 GTC 即將舉行的演講 Optimizing Data Systems for NVIDIA Merlin and NVIDIA Triton 中,將討論提高推薦系統整體性能的方法。有關這些用例的更多信息,請聯系 sam.partee@redis.com 或在 Twitter 上關注我 @sampartee 。
?





