人工智能的快速發展正在推高數據集的規模,以及網絡的規模和復雜性。支持人工智能的應用程序,如電子商務產品推薦、基于語音的助手和呼叫中心自動化,需要數十到數百個經過培訓的人工智能模型。推理服務幫助基礎設施管理人員部署、管理和擴展這些模型,并在生產中保證實時服務質量( QoS )。此外,基礎架構經理希望提供和管理用于部署這些 AI 模型的正確計算基礎架構,最大限度地利用計算資源,靈活地放大或縮小規模,以優化部署的運營成本。將人工智能投入生產既是一項推理服務,也是一項基礎設施管理挑戰。
NVIDIA 與谷歌云合作,將 CPU 和 GPU 通用推理服務平臺 NVIDIA Triton Inference Server的功能與谷歌 Kubernetes 引擎( GKE )相結合,使企業更容易將人工智能投入生產。NVIDIA Triton Inference Server 是一個托管環境,用于在安全的谷歌基礎設施中部署、擴展和管理容器化人工智能應用程序。
使用 NVIDIA Triton 推理服務器在谷歌云上的 CPU 和 GPU 上提供推理服務
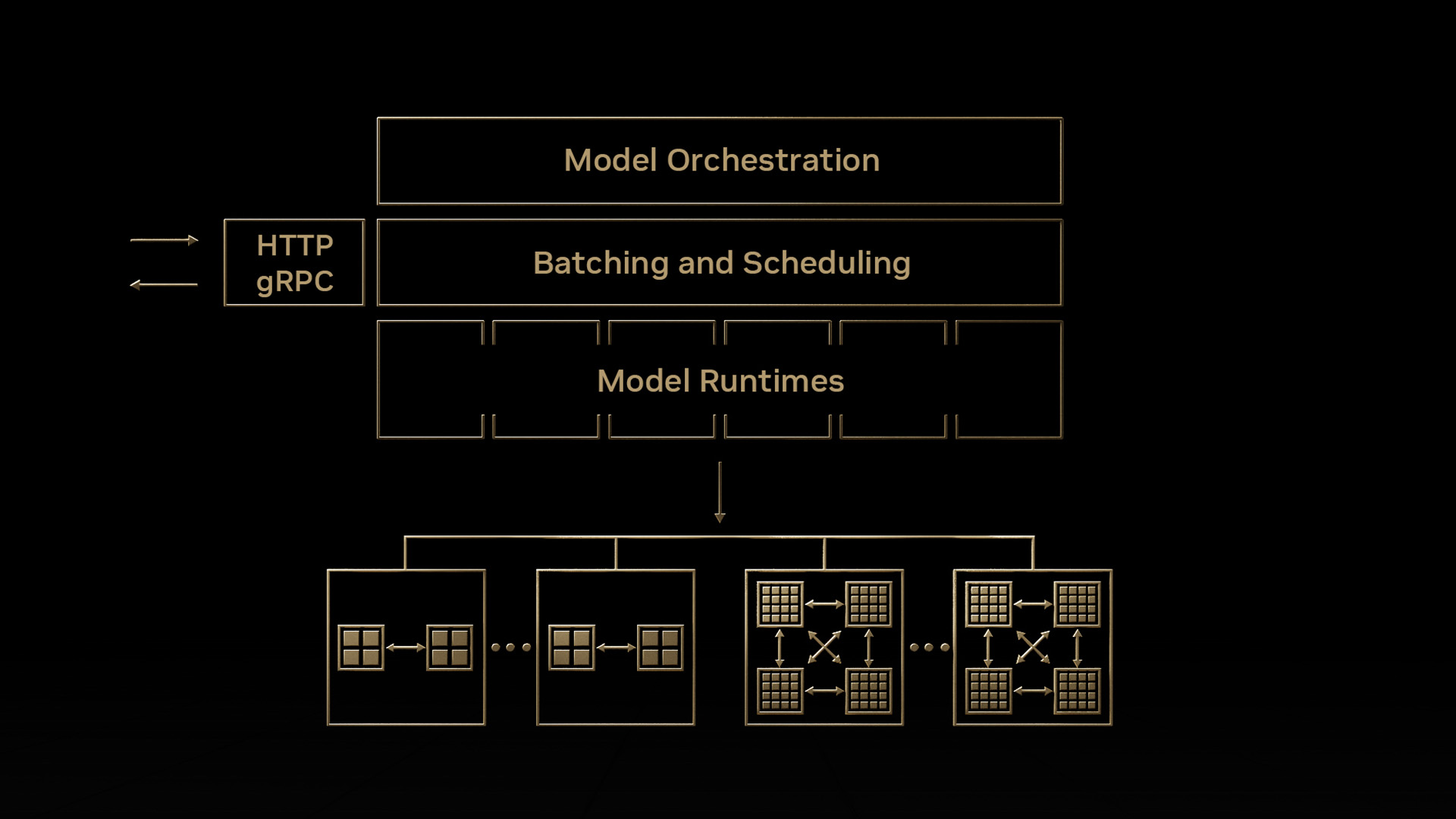
在企業應用程序中操作 AI 模型帶來了許多挑戰——為在多個框架中培訓的模型提供服務,處理不同類型的推理查詢類型,并構建一個能夠跨 CPU 和 GPU 等多個部署平臺進行優化的服務解決方案。
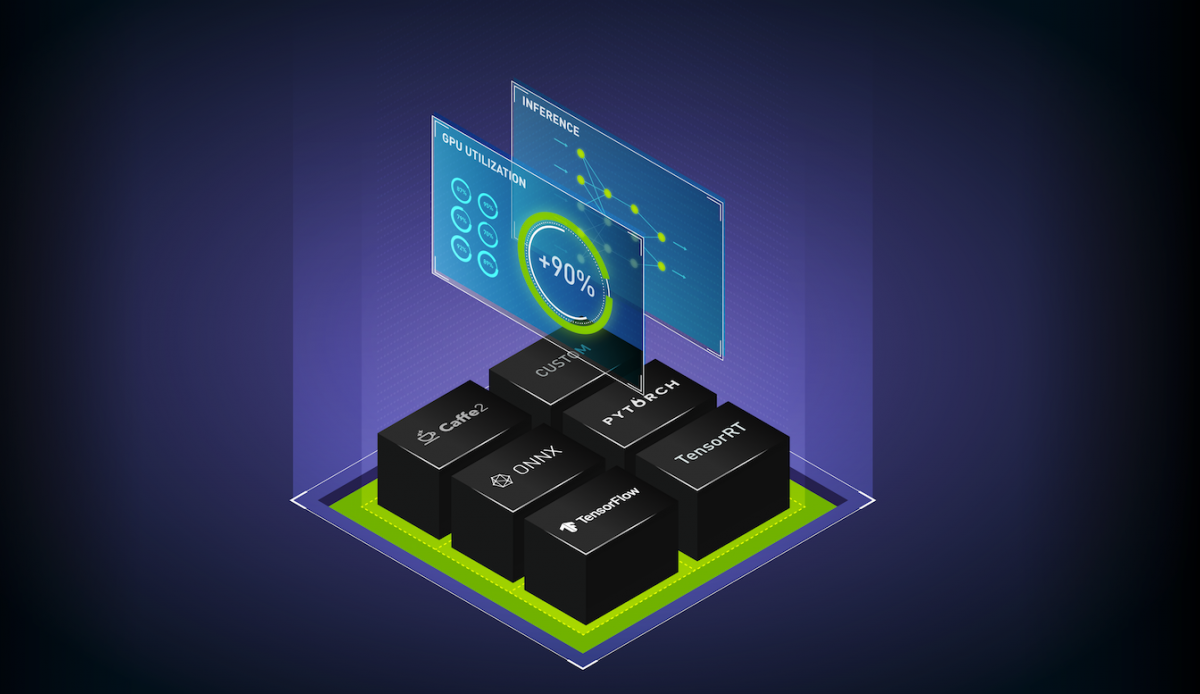
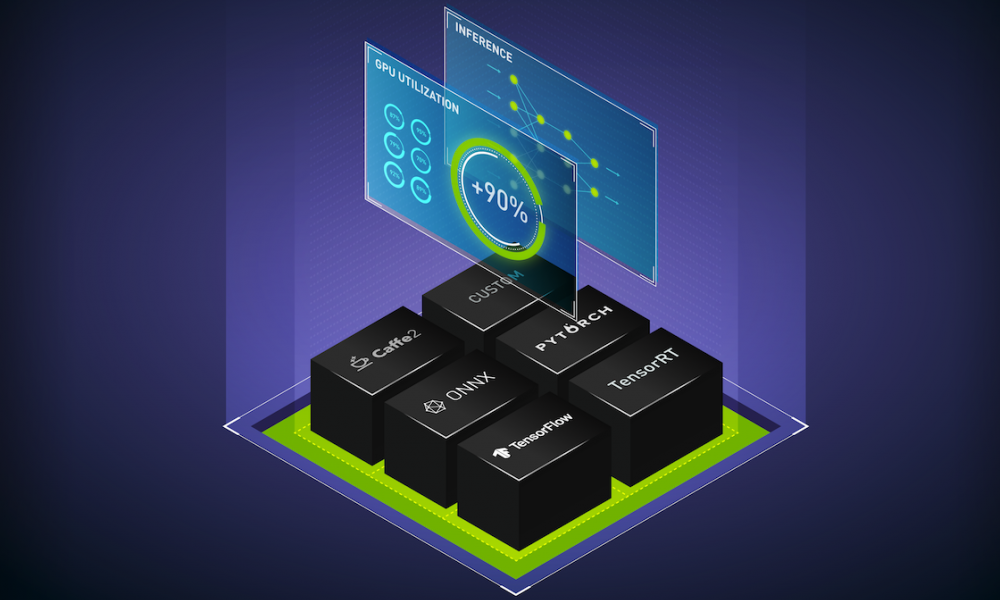
Triton 推理服務器通過提供一個單一的標準化推理平臺來解決這些挑戰,該平臺可以從任何基于 TensorFlow 、TensorRT、 PyTorch 、 ONNX 運行時、 OpenVINO 或自定義 C ++/ Python 框架的本地存儲或谷歌云的托管存儲在任何基于 GPU 或 CPU 的基礎設施上部署經過培訓的 AI 模型。
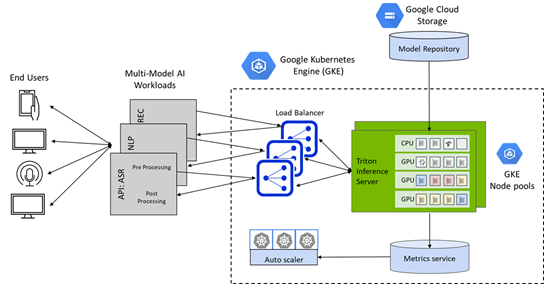
在 GKE 集群上一鍵部署 NVIDIA Triton 推理服務器
Google Kubernetes Engine ( GKE )上的 Triton 為部署在 CPU 和 GPU 上的 AI 模型提供了通用推理服務平臺,并結合了 Kubernetes 群集管理、負載平衡和基于需求的自動縮放計算的方便性。
使用谷歌市場上新的一鍵式 Triton GKE 推理服務器應用程序,可以將 Triton 無縫部署為 Google Kubernetes Engine ( GKE )管理的集群上的容器化微服務。
GKE 的 Triton 推理服務器應用程序是一個 helm chart 部署程序,可自動安裝和配置 Triton ,以便在具有 NVIDIA GPU 節點池的 GKE 集群上使用,包括 NVIDIA A100 Tensor Core GPU s 和 NVIDIA T4 Tensor Core GPU s ,并利用谷歌云上的 Istio 進行流量進入和負載平衡。它還包括一個水平 pod autoscaler ( HPA ),它依賴堆棧驅動程序自定義度量適配器來監控 GPU 占空比,并根據推理查詢和 SLA 要求自動縮放 GKE 集群中的 GPU 節點。
要了解有關 Google Kubernetes Engine ( GKE )中一鍵式 Triton 推理服務器的更多信息,請查看此谷歌云和 NVIDIA 的深度博客,了解解決方案如何擴展以滿足嚴格的延遲預算,并優化 AI 部署的運營成本。
您還可以在 8 月 25 日注冊參加“使用 NVIDIA NGC 和谷歌云構建計算機視覺服務”網絡研討會,學習如何通過結合 NGC 目錄中的 NVIDIA GPU – 優化預訓練模型和轉移學習工具包( TLT )以及 GKE 的 Triton 推理服務器應用程序,在谷歌云上構建端到端的計算機視覺服務。