
隨著數據集規模的不斷擴大,采用 Amazon S3 和谷歌云存儲( GCS )等云存儲平臺變得越來越流行。盡管節點本地存儲可能會帶來更好的 IO 性能,但在數據集超過單 TB 規模后,這種方法可能變得不切實際。
在遠程存儲是唯一實用的解決方案的情況下, PyData 生態系統的許多部分已經采用文件系統規范(fsspec)作為通用文件系統 API 。自從s3fs和gcsfs推出以來,fsspec已經為用戶提供了足夠的遠程存儲訪問權限,但內部字節傳輸和緩存算法還沒有對拼花等高性能文件格式進行特定于格式的優化。
關鍵教訓
在本文中,我們將介紹fsspec.parquet模塊,它為遠程拼花文件提供了一種支持格式的字節緩存優化。這個模塊是實驗性的,并且僅限于一個公共 API :open_parquet_file。
此 API 提供了更快的遠程文件訪問。與 cuDF 和 cuDF 數據幀庫中的默認read_parquet行為相比,對于大型拼花地板文件的部分 I / O (列塊和行組選擇),整體吞吐量有了一致的性能提升。
我們還討論了這個新模塊中使用的優化,并給出了初步的性能結果。
什么是 fsspec ?
文件系統規范(fsspec)是一個開源項目,為各種后端存儲系統提供統一的 Python 接口。fsspec對應于一個特定的fsspec Python 庫和一個更大的 GitHub 組織,其中包含許多特定于系統的存儲庫(例如s3fs和gcsfs)。
在基于 Python 的庫或應用程序中使用fsspec的優點是,類似于 POSIX 的文件 API 可以從遠程對象和本地文件進行讀寫。當一個基于云的對象被一個fsspec兼容的文件系統打開時,底層應用程序會得到一個AbstractBufferedFile對象,或者其他一些類似文件的對象,這些對象被設計為使用原生 Python 文件對象進行 duck type 操作。現在,這些類似文件的對象可以像本地 Python 文件句柄一樣處理。
一個明顯的區別是AbstractBufferedFile對象必須在內部使用特定于文件系統的命令,以便向遠程存儲系統輸入和從遠程存儲系統獲取字節。由于內部數據傳輸操作的延遲通常高于本地磁盤訪問,fsspec提供了幾種緩存策略來預取數據,同時避免了許多小請求。
在這篇文章的后面,我們將解釋為什么對于大型拼花地板文件,默認緩存策略通常不太理想,以及新的KnownPartsOfAFile(“部件”)選項如何顯著減少讀取延遲。
什么是拼花地板?
Parquet 是一種面向二進制列的數據存儲格式,設計時考慮了性能、壓縮和部分 I / O 。由于與 CSV 等文本格式文件相比具有顯著的性能優勢,自 2013 年首次發布以來,開源格式的受歡迎程度迅速增長。
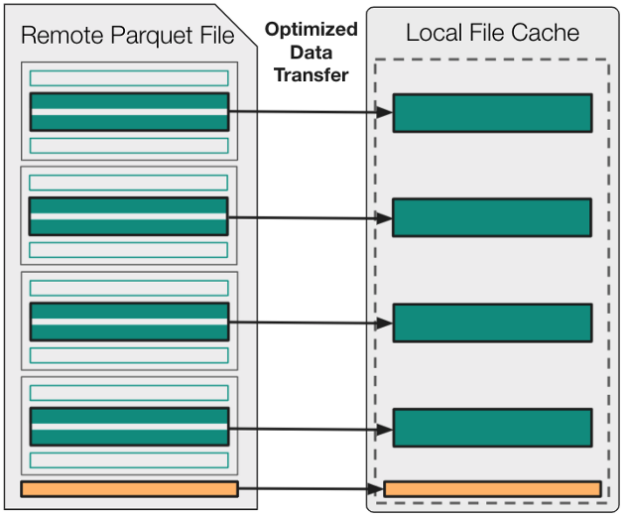
為了理解 Fsspec 拼花地板模塊中使用的優化,對拼花地板規范有一個高層次的理解是很有用的。圖 1 顯示,所有拼花文件都由一組連續存儲的行組組成,而這些行組中的每一個都包括一組連續存儲的列塊。
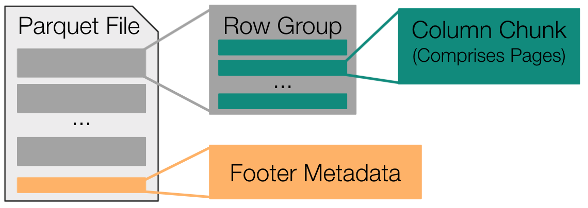
總之,拼花地板文件中的大部分字節都對應于這些列塊。剩余的字節用于將文件元數據存儲在舊格式的頁腳中。此頁腳元數據包括文件中每個列塊的字節偏移量和可選統計信息(min、max、valid count、null count)。
由于這些重要信息整合在頁腳中,因此只需對拼花地板文件的結尾進行采樣,即可確定文件中每個列塊的具體位置。
fsspec 新拼花模塊的用途是什么?
fsspec已經是 Python 下加載拼花地板文件的最常用方法。新fsspec.parquet模塊的主要目的是為這項任務提供優化的實用程序。
在內部,這個新的實用程序(open_parquet_file)基本上將一個傳統的開放調用封裝在特定于拼花地板的邏輯中,該邏輯設計用于在用戶啟動顯式讀取操作之前,開始將所有相關數據從遠程文件傳輸到本地內存。
盡管任何大小的讀取都可能受益于此新實用程序,但當讀取操作僅針對所有列和行組的子集時,可以看到最顯著的改進。例如,當遠程讀取使用列投影時,相同的列列表可以直接傳遞給open_parquet_file:
from fsspec.parquet import open_parquet_file
import pandas as pd path = “<protocol>://my-bucket/my-data”
columns = [“col1”, “col2”]
options = {“necessary”: ”credentials”} with open_parquet_file( path, columns=columns, storage_options=options,
) as f: df = pd.read_parquet(path, columns=columns)
如前所述,fsspec新open_parquet_file函數的主要目的是通過在AbstractBufferedFile.open中使用支持格式的緩存策略,提高大型拼花地板文件的讀取性能。
要理解拼花地板模塊使用的特定優化為什么是有益的,首先了解簡單的無緩存方法以及默認的預讀策略是有幫助的。
了解無緩存和預讀方法
圖 2 顯示了對于 naive 和 naive 讀調用序列,無緩存文件訪問可能如何映射到read_parquet操作中的遠程 get 調用(在遠程文件已經打開之后)。
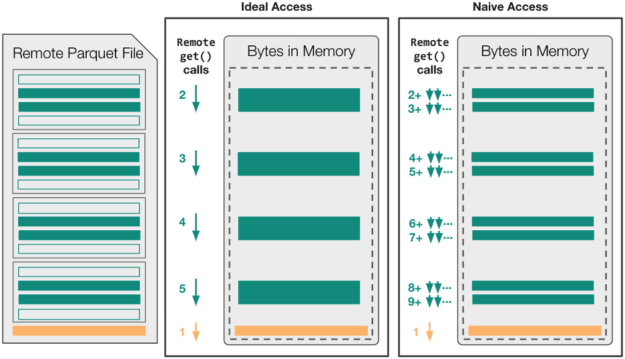
在這個特定的示例中,假設拼花文件足夠大(~ 400MB +)以包含四個不同的行組,read_parquet調用的目標是四個可用列中的兩個。這意味著AbstractBufferedFile對象最終必須將八個不同的列塊范圍以及頁腳元數據傳輸到本地內存中。
在禁用緩存的情況下,經過良好調整的拼花地板庫可以使用五個不同的請求僅將必要的數據移動到本地內存中。然而,由于fsspec的類文件接口包含state,這五個讀取調用始終是串行的,每次調用都會產生一整段延遲時間。
這種 ideal-access 場景無法利用并發性來最小化延遲,即使該策略可能會最小化文件系統請求的數量并產生高的總體吞吐量。對于采用 naive-access 方法且未明確最小化讀取調用數的拼花地板庫,read_parquet操作可能會出現高延遲和低總體吞吐量!
此時,我們已經確定,在文件已經打開進行讀取之后, I / O 庫無法利用文件系統的并發性。更重要的是,當涉及部分 I / O 時,默認的預讀緩存策略可能會進一步降低觀察到的性能。這是因為預讀緩存的固有假設是,順序文件訪問可能是連續的。
Figure 3 shows that read-ahead caching is likely to transfer about 20 MB of unnecessary data, 5 MB of read-ahead for each row-group.
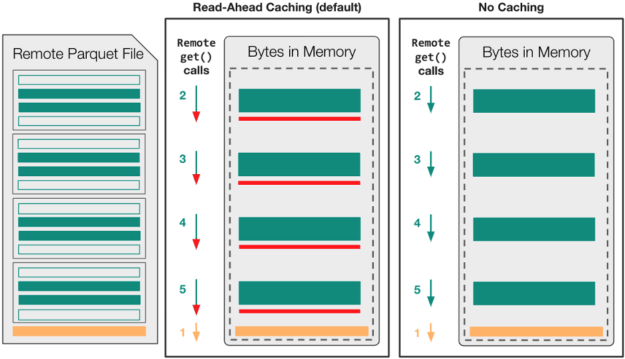
正如您在以下性能結果中看到的,禁用緩存優于預讀緩存的好處取決于read_parquet中使用的引擎和特定的存儲系統。
如果引擎已經包含了支持格式的優化,可以將必要的字節范圍移動到本地內存中(即pyarrow和fastparquet),那么無緩存選項可能是更好的選擇。當引擎假定本地文件訪問速度很快( cuDF )時,某種形式的fsspec級緩存可能非常關鍵。
在這兩種情況下,引擎都無法開始傳輸所需的字節范圍,直到創建fsspec文件對象之后。它受到順序數據傳輸附加延遲的限制。
現在,我們已經對典型的 read _ parquet 調用中的默認和無緩存 AbstractBufferedFile 行為有了較高的理解,現在我們可以解釋open_parquet_file為提高總體讀取吞吐量而使用的兩種通用優化。
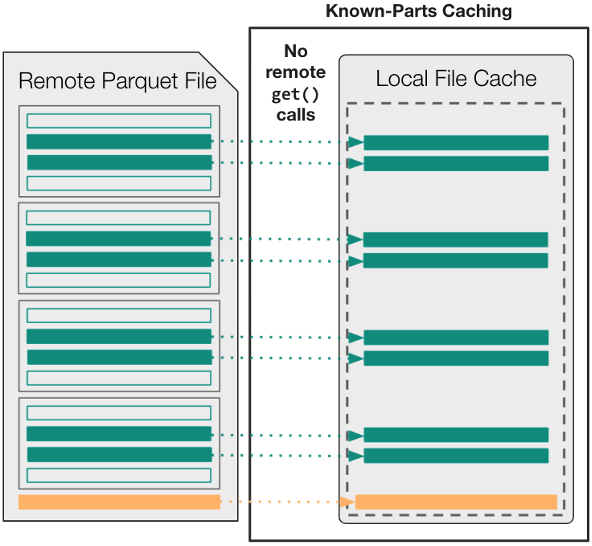
優化 1 :使用“部件”緩存策略
默認情況下,與AbstractBufferedFile中使用的格式無關的緩存策略不同,您可以使用新的KnownPartsOfAFile(“部件”)選項在文件打開之前精確緩存所需內容。
In other words, begin by using an external Parquet engine (either fastparquet or pyarrow) to parse the footer metadata up-front. Then, transfer the necessary byte-ranges into local memory, and use the parts’ cache to ensure that downstream applications never have to wait for remote data after an open fsspec file object is acquired.
圖 4 顯示,用于訪問read_parquet中數據的邏輯與用于遠程數據訪問的get調用的數量或大小之間不再存在任何關系。從拼花引擎的角度來看,任何讀取操作幾乎都是瞬時的,因為所有必需的數據都已緩存在內存中。
優化 2 :異步并行傳輸“部件”
盡管之前的優化使您能夠避免read_parquet中的許多小型 get 操作和不必要的數據傳輸,但在初始化AbstractBufferedFile之前,您仍然必須填充KnownPArtsOfAFile緩存。
為了盡可能高效地執行此操作,請使用cat_ranges一次性獲取所有必需的列塊,包括異步獲取和使用asyncio并行獲取。因為對于包含多個字段或多個行組的文件,傳輸的列塊的總數可能很大,所以只要聚合的請求的大小保持在上限以下,就可以聚合相鄰的字節范圍請求。
圖 5 顯示,這種方法最終會導致并發傳輸多個字節范圍的最佳大小。
初步 fsspec 。拼花地板基準測試結果
要將open_parquet_file的性能與其他基于fsspec和pyarrow的文件處理方法進行比較,請使用 可用 Python 腳本 :
pyarrow-6.0.1fastparquet-0.8.0cudf-22.04fsspec/s3fs/gcfs-2022.2.0
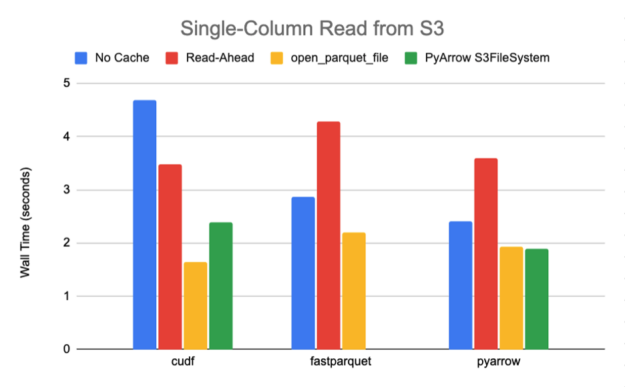
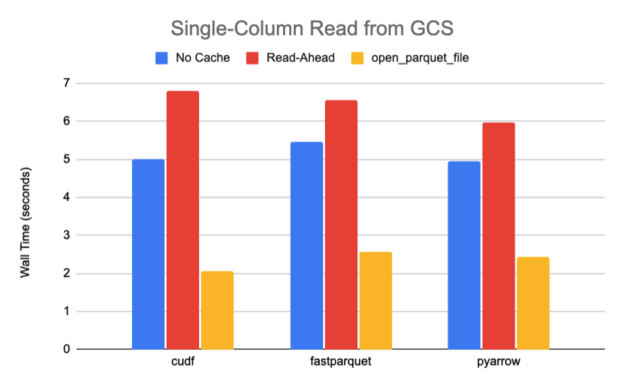
使用這個腳本,我們從一個 789M 的拼花地板文件中讀取一列,該文件共包含 10 個行組和 30 個列,具有快速壓縮,需要傳輸大約 27M 的數據。圖 6-7 中總結的 S3 和 GCS 的結果清楚地表明,當從默認緩存策略轉向open_parquet_file時,性能顯著提升 85% 或更高。
事實上,新功能有效地匹配了 PyArrow 的原生S3FileSystem實現的性能,該實現是專門為其鑲木地板引擎的最佳性能而設計的。在本文中,我們僅將其與 Amazon S3 基準測試的本機 PyArrow 文件系統進行比較,因為 PyArrow 在發布時僅提供 Amazon S3 和 Hadoop 的公共支持實現。
為了說明使用open_parquet_file縮放文件的好處,我們還從一個 12 GB 的拼花地板文件中讀取了一列,其中包含禁用壓縮的公共 GCS 存儲中 Criteo 數據集的第一天。圖 8 顯示,新的fsspec函數可以提供比默認緩存 10 倍或更多的加速。

自己測試一下
在本文中,我們介紹了fsspec.parquet模塊,它為打開遠程拼花文件open_parquet_file提供了一種支持格式的字節緩存優化。基準測試清楚地表明,與fsspec中的默認文件打開行為相比,新的優化可以提供顯著的性能改進,甚至可以接近 PyArrow 中針對部分 I / O 的優化 C ++文件系統實現的性能。
自從在 2021.11.0 版本的 fsspec 中正式發布以來,open_parquet_file實用程序已經被 RAPIDS cuDF 庫和 Dask -Dataframe 采用。
由于基于 cuDF 的工作流得到了顯著且一致的改進,此新功能已被cudf.read_parquet和dask_cudf.read_parquet采用為默認的文件打開方法。
對于沒有 GPU 資源的 Dask 用戶,現在可以通過向read_parquet傳遞open_file_options參數來選擇優化的緩存方法。例如,以下代碼示例指示 Dask 使用parquet預緩存方法打開所有拼花地板數據文件:
import dask.dataframe as dd ddf = dd.read_parquet( path, open_file_options={“precache_options”: {“method”: “parquet”}}
)鑒于這一早期的成功,我們希望擴展和簡化fsspec中可用的預緩存選項,并在所有文件打開函數中建立一個清晰的 precache_options API 。
這里的社區反饋至關重要。請訪問 GitHub 或在下面發表評論,并讓我們知道您的想法!






