
在現代軟件開發中,時間是非常寶貴的資源,尤其是在編譯過程中。對于在大規模 GPU 加速應用程序上使用 CUDA C++的開發者而言,優化編譯時間可以顯著提高工作效率并簡化整個開發周期。
使用 nvcc 編譯器進行離線編譯時,高效的編譯時間使您能夠快速構建代碼并保持勢頭。在使用 nvrtc 的即時 (JIT) 編譯環境中,最小化編譯時間有助于減少執行或運行時延遲,并提高應用程序性能。如果您在實時系統或交互式應用程序上工作,您將從盡可能快的編譯時間中受益匪淺。
理解編譯瓶頸的來源并不總是那么簡單。CUDA 編譯過程十分復雜,因為編譯器會對代碼執行各種優化和轉換,幾乎看不到代碼的哪些部分需要很長時間才能編譯。
例如,看似簡單的代碼行可能會觸發復雜的模板實例化,從而導致其他模板的遞歸擴展,進而消耗過多的編譯時間。如果不清楚幕后發生了什么,您就不知道編譯時間較長的根本原因是什么,以及它是深度遞歸模板、特別大的頭文件還是效率低下的代碼模式。
CUDA 編譯流程本身就很復雜。這不是一個單一的單一流程,而是一系列互聯的子流程。例如,nvcc 可能會調用主機編譯器、生成設備特定的代碼或運行各種優化過程,每次都會延長總編譯時間。
如果不能正確了解編譯過程,就很難確定哪些子進程會導致漫長的編譯時間。主機側編譯期間是否會出現速度減慢的情況?設備端優化是否會消耗過多的周期?或者,是否還有其他問題完全阻礙了這一過程?這種缺乏透明度的情況可能會讓您束手無策,無法解決編譯時瓶頸的根本原因。
鑒于 CUDA 編譯管道的復雜性,您可以使用工具分析代碼與編譯器的交互方式。您需要一種方法來衡量代碼對編譯過程的性能影響,并確定哪些領域的優化時機已經成熟。這就是 CUDA 的 --fdevice-time-trace 功能為 CUDA 和 CUDA 來發揮作用的地方。
--fdevice-time-trace 是在 CUDA 12.8 中發布的工具,可直觀呈現整個編譯過程。它會生成各個編譯階段的詳細時間線,讓您能夠清晰地了解所花費的時間。
無論是特別昂貴的模板實例化還是耗時的頭文件,--fdevice-time-trace 都會詳細說明該過程,并突出顯示導致編譯時間過長的確切區域。這種級別的可見性使您能夠控制代碼對編譯器的影響,從而為更高效的構建和更快的開發周期鋪平道路。
在本文中,我們將探討此功能的工作原理、提供的見解,以及它如何通過識別和緩解編譯時瓶頸來幫助您優化 CUDA 項目。
啟用 --fdevice-time-trace 功能
要利用 CUDA C++編譯器中的 --fdevice-time-trace 功能,啟用該功能非常簡單。對于 nvcc,可以使用以下命令激活該功能:
nvcc --fdevice-time-trace <output_filename> |
在這種情況下,<output_filename> 是指編譯完成時生成的文件的名稱。這將生成遵循“Trace Event”(一種廣泛認可的用于分析的格式) 格式的 .json 文件。可以打開 .json 追蹤文件并在公共查看器中查看:
edge://tracing/chrome://tracing/- Perfetto 界面
這些工具提供了編譯各個階段的可視化分解,使您能夠逐步分析編譯過程。圖 1 展示了如何使用 chrome://tracing/ 打開 trace.json 文件。
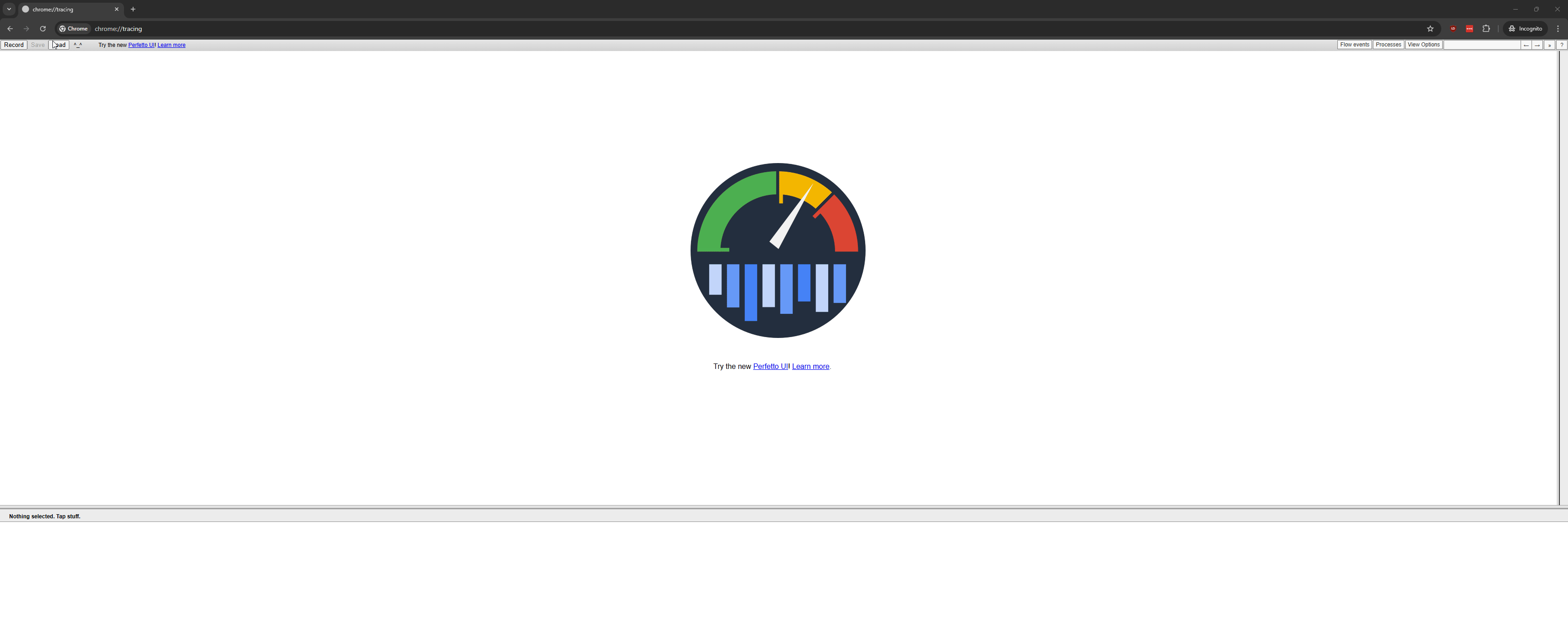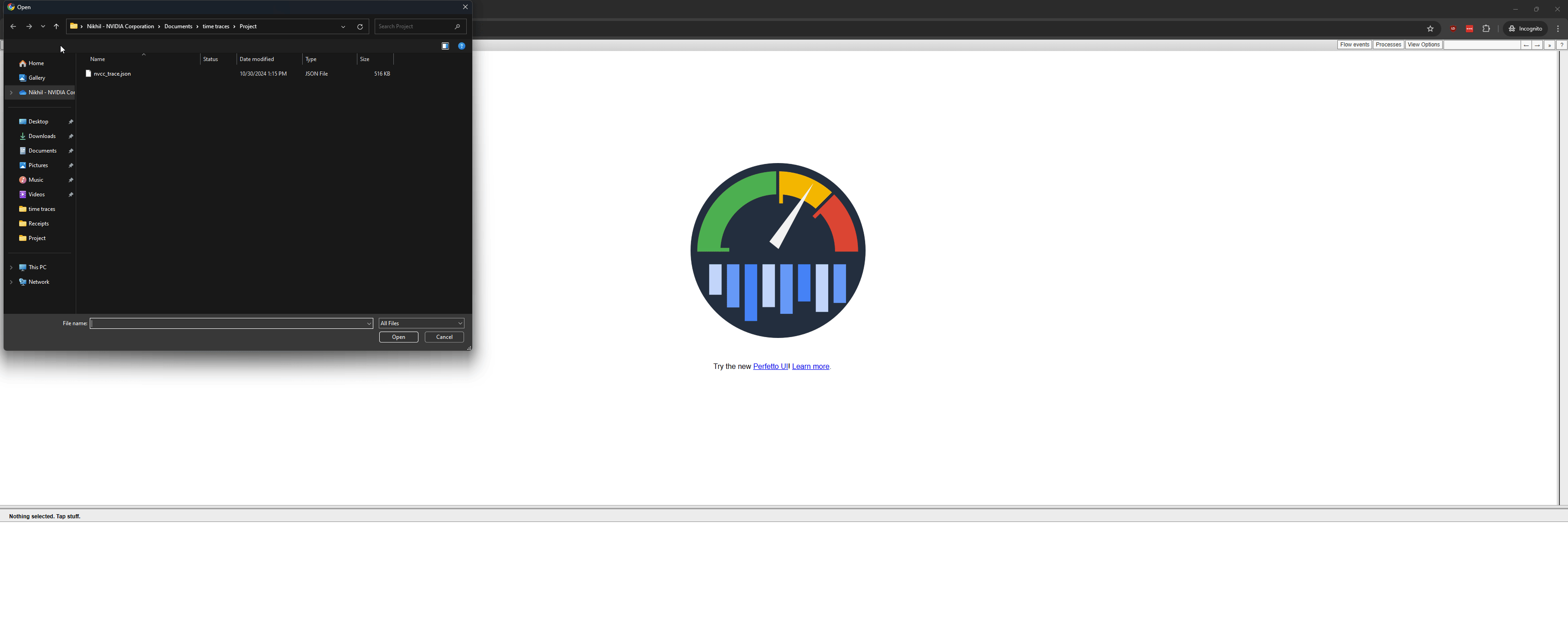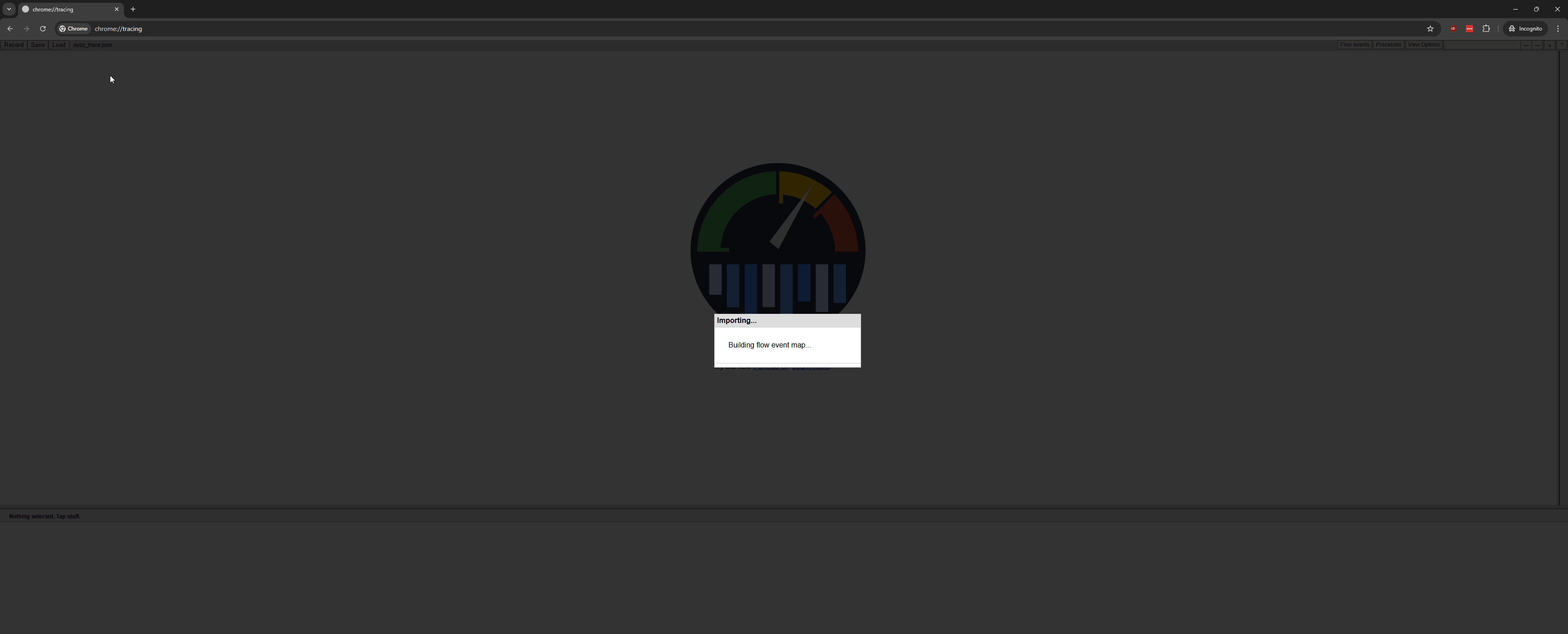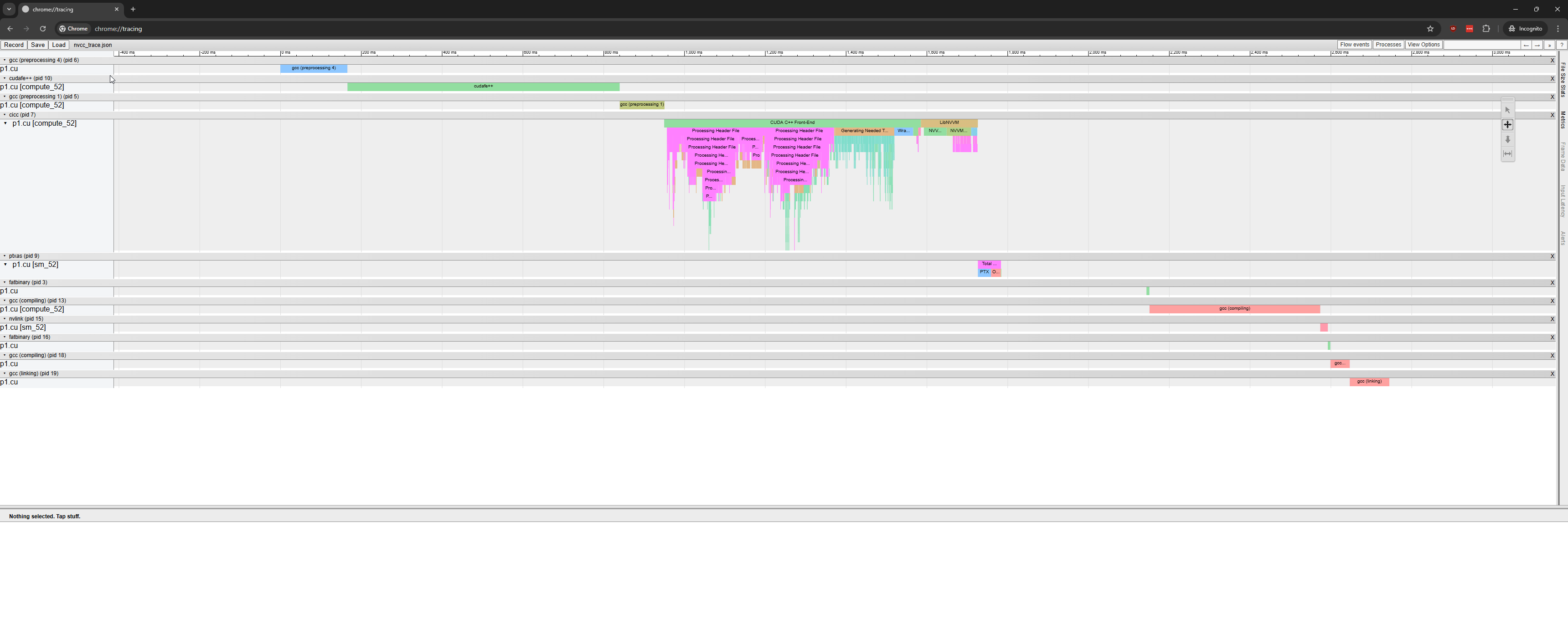
about://tracing 在 Web 瀏覽器中加載追蹤文件 為大型構建系統啟用 --fdevice-time-trace
默認情況下,追蹤文件涵蓋對 nvcc 的一次調用。但是,在實際項目中,您可能需要在多個編譯單元或多次調用 nvcc 的大型構建系統中捕獲追蹤。為此,nvcc 提供了為每個編譯單元生成唯一追蹤文件的功能:
nvcc --fdevice-time-trace=- <input_file> |
使用此選項時,nvcc 會生成 .json 追蹤文件,其基礎名稱與每次調用的輸出文件相同,從而防止手動追蹤文件重命名。如果重復使用輸出文件名,nvcc 會覆蓋追蹤文件,以便每個追蹤對應于一次編譯器調用。
為 nvrtc 啟用 --fdevice-time-trace
要使用 nvrtc 進行即時 (JIT) 編譯,啟用 --fdevice-time-trace 功能同樣簡單。調用 nvrtcCompileProgram 時,傳遞以下選項:
--fdevice-time-trace <output_filename> |
與 nvcc 不同,nvrtc 不支持 --fdevice-time-trace=-。但是,它有一個特殊的優勢:對于多次調用 nvrtcCompileProgram (在 JIT 上下文中很常見) 的程序,所有追蹤文件都會自動附加。這使您能夠在所有 nvrtcCompileProgram 調用中使用相同的 <output_filename> 值,并將所有火焰圖形收集到單個報告中,從而提供整個 JIT 編譯過程的綜合視圖。
此功能在運行時編譯多個內核的復雜應用程序中特別有用,使您能夠收集每個內核的詳細性能見解,而無需手動管理多個 trace files。
用例
現在我們已經介紹了這項有助于分析編譯流程的新功能,我們將展示一些有用的用例:
- 可視化編譯的端到端工作流程
- 識別模板實例化瓶頸
- 識別昂貴的頭文件
- 識別異常瓶頸
可視化編譯的端到端工作流程
借助 --fdevice-time-trace 功能,您可以可視化編譯過程的端到端工作流程,并提供所有主要階段的全面時間表:
- 預處理
- 主機和設備代碼編譯
- 設備鏈接
- 二進制生成
這種整體視圖對于了解不同階段如何交互以及對總編譯時間的影響尤為重要。通過檢查此可視化,您可以確定主導工作流程的階段,確定延遲是由特定代碼結構還是編譯器管道本身造成的,并確定需要優化的區域的優先級。
可視化工具還會顯示編譯器的多線程模式,例如 --threads 或 --split-compile。圖 2 和 3 顯示了使用和不使用 nvcc0 時可視化的差異。
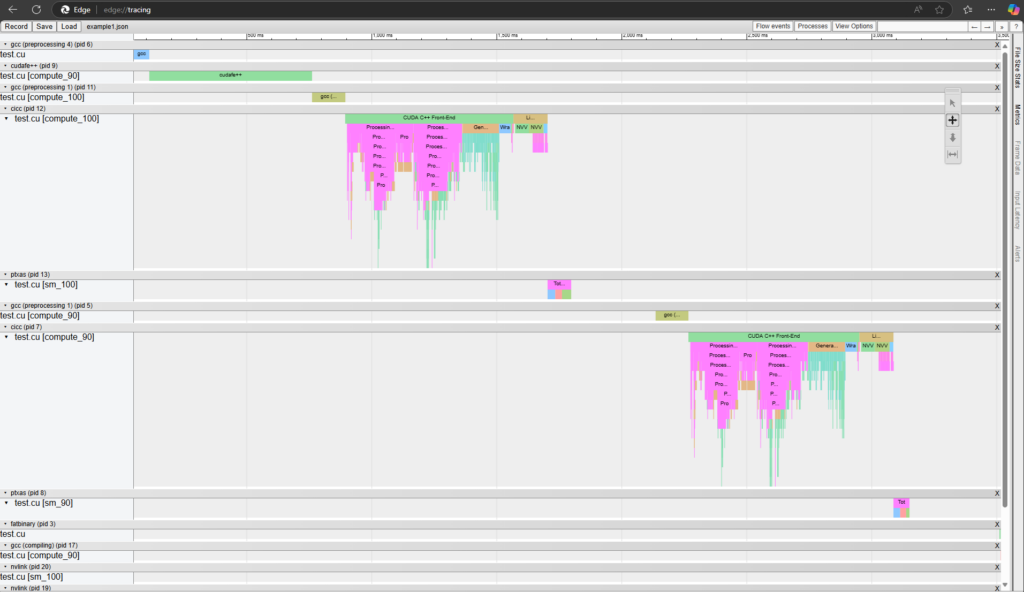
nvcc 編譯流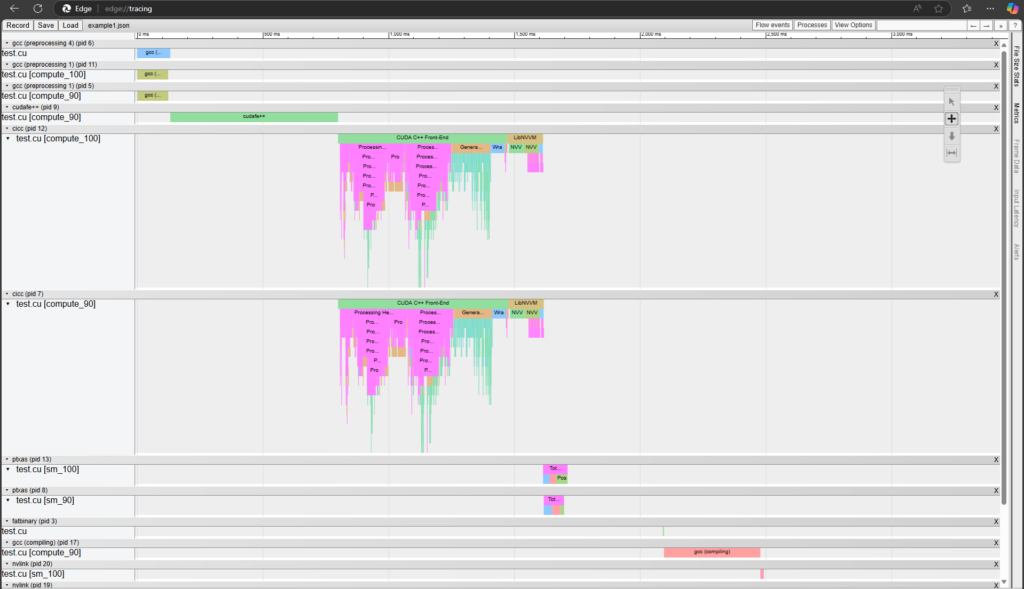
--threads 的 端到端 nvcc 編譯流 識別模板實例化瓶頸
模板元編程是一種強大的實踐,可讓您編寫靈活且可重復使用的代碼。Thrust 和 Cutlass 等熱門 CUDA 項目通常使用模板來實現編譯時的靈活性,使這些庫能夠適應各種數據類型、執行策略和硬件功能。
雖然這種靈活性可讓您更輕松地編寫高性能 GPU 代碼,但也會產生成本。復雜的模板,尤其是具有遞歸或深度嵌套實例化的模板,可以顯著增加編譯時間。
由于編譯器必須使用特定類型和參數對每個模板進行實例化,因此復雜的模板會增加編譯時間,而這一過程可以級聯為深度遞歸或分層模板的多個嵌套實例化。每個實例化都需要額外的編譯器資源,因為它會為每個可能的變體評估和生成代碼,最終會消耗大量時間和內存,尤其是在高度模板化的代碼中。
圖 4 顯示了使用深度模板遞歸樹的程序概要。可視化可以輕松識別遞歸樹,并提供足夠的信息供您識別源代碼中存在問題的代碼。然后,您可以重構代碼以最小化模板復雜性,使用技術如使用 extern 模板避免冗余實例化、使用迭代方法替換深度遞歸模板、對常用模板進行顯式實例化等。
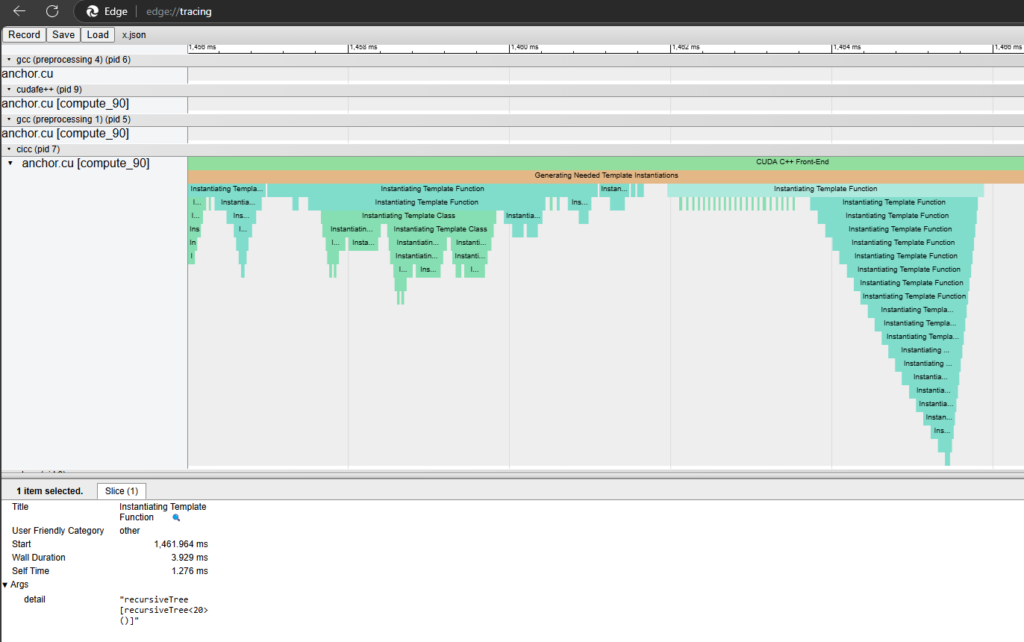
--fdevice-time-trace 識別深度模板樹 識別昂貴的頭文件
對編譯時間有顯著影響的標頭通常包含跨多個翻譯單元的復雜模板或宏。這些標頭可能會導致編譯器重復工作,因為它會為每個包含內容處理相同的定義和實例化。
借助 --fdevice-time-trace 功能,您可以通過分析頭文件事件的時間軸來識別需要大量處理時間的頭文件。借助這種見解,您可以使用預編譯頭文件、減少不必要的包含項或模塊化大型頭文件等技術來優化構建流程,從而最大限度地減少冗余編譯工作并提高整體性能。
識別異常瓶頸(Anomalous Bottlenecks)
除了模板和標頭等外部因素之外,在編譯過程的特定階段,編譯器本身也可能會出現瓶頸。
例如,編譯單元的 NVVM 優化器、代碼生成器、設備鏈接器或后端 PTX 優化可能會意外地消耗大量時間。如果不詳細了解編譯器的工作流程,通常很難檢測到這些內部異常。
--fdevice-time-trace 功能提供了一個時間軸,可將編譯器的執行分解為細化階段,突出顯示花費時間最多的區域。如果某個特定階段 (例如 NVVM Optimizer 或 PTX 生成) 特別耗時,則表示有機會進一步研究。
這種透明度有助于您確定瓶頸是由于代碼結構還是編譯器中的特定行為造成的,從而實現更明智的優化策略。它還可以讓您識別異常行為并向編譯器團隊 提交錯誤 。
圖 5 展示了在 PTXAS 中優化一個內核時編譯時間過度瓶頸的真實示例。這表明,PTXAS 在嘗試優化 "_Z9NopKernelPi" 時花費了大量時間。此報告可幫助您了解潛在問題,并為您提供必要的見解,以便根據需要向工程團隊提交詳細的錯誤報告。
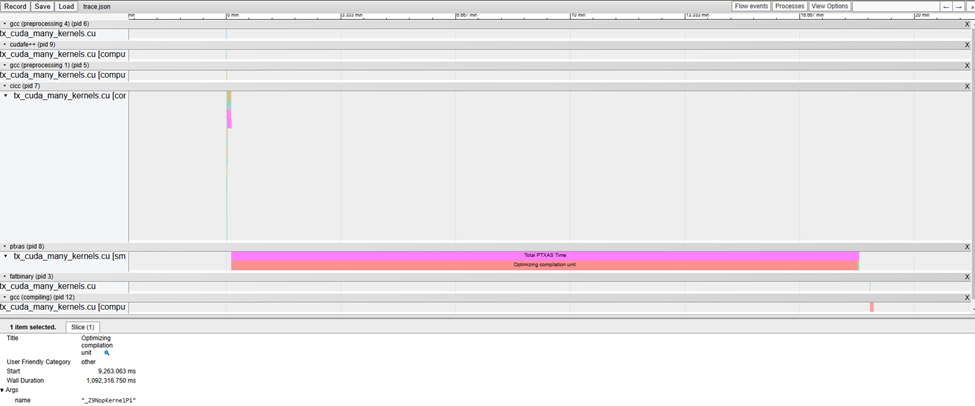
--fdevice-time-trace 識別異常瓶頸 結語
--fdevice-time-trace 功能代表著在提高開發者工作效率和優化 CUDA C++ 中的編譯工作流方面邁出的重要一步。它提供有關模板實例化、頭文件處理、內部編譯器階段和整個編譯工作流程的詳細見解,使您能夠精確識別和解決瓶頸,并且可以成為開發過程中不可或缺的一部分。
我們鼓勵您在項目中試用 --fdevice-time-trace,探索其潛力,并與社區分享您的反饋。您的反饋對于完善此功能并確保其滿足全球 CUDA 開發者的需求至關重要。讓我們攜手合作,讓 CUDA 開發更快、更高效!
?
?






