
開源 llama.cpp 代碼庫最初于 2023 年發布,是一種輕量級但高效的框架,用于在 Meta Llama 模型上執行推理。llama.cpp 基于去年發布的 GGML 庫構建,由于專注于 C/C++ 而無需復雜的依賴項,因此很快就吸引了許多用戶和開發者(尤其是在個人工作站上使用)。
自首次發布以來,Llama.cpp 已得到擴展,不僅支持各種模型、量化等,還支持多個后端,包括支持 NVIDIA CUDA 的 GPU。在撰寫本文之時,Llama.cpp 在所有 GitHub 庫中排名第 123 位,在所有 C++ GitHub 庫中排名第 11 位。
在 NVIDIA GPU 上使用 Llama.cpp 執行 AI 推理已經帶來了顯著的優勢,因為它們能夠以極高的性能和能效執行基礎 AI 推理的計算,同時在消費設備和數據中心中也很普遍。NVIDIA 和 Llama.cpp 開發者社區繼續合作,以進一步提高性能。本文介紹了最近通過在 Llama.cpp 中引入 CUDA 圖形功能而實現的改進。
CUDA 圖形
GPU 會隨著每一代產品的推出而不斷加速,而且通常情況下,GPU 上的每個活動(例如內核或內存復制)都會很快完成。過去,每個活動都必須由 CPU 單獨調度(啟動),相關的開銷可能會累積成為性能瓶頸。
CUDA Graphs 工具通過將多個 GPU 活動調度為單個計算圖形來解決此問題。在上一篇文章“Getting Started with CUDA Graphs”中,我介紹了 CUDA Graphs 并演示了入門方法。在后續的博文“A Guide to CUDA Graphs in GROMACS 2023”中,我將介紹如何將 CUDA Graphs 成功應用于 GROMACS 生物分子模擬科學軟件包。
使用傳統流模型時,每個 GPU 活動都是單獨調度的,而 CUDA 圖形支持對多個 GPU 活動進行一致調度。這減少了調度開銷。調整現有基于流的代碼以使用圖形相對簡單。該功能通過幾次額外的 CUDA API 調用將流執行“捕獲”到圖形中。
本文將介紹如何利用此工具,使用圖形(而非流)來執行預先存在的 llama.cpp 代碼。
在 Llama.cpp 中實現 CUDA 圖形
本節重點介紹現有代碼中的開銷,并描述如何引入 CUDA Graphs 來減少這些開銷。
現有代碼中的開銷
圖 1 顯示了在引入 CUDA Graphs 之前,使用 Linux 在 NVIDIA A100 GPU 上執行 Llama 7B Q4 推理的現有代碼的配置文件片段。它是通過 NVIDIA Nsight Systems 獲得的。圖中頂部配置文件中的每個 GPU 活動塊都對應于對單個令牌的評估,其中縮放設置為顯示正在評估的兩個完整令牌。可以看到,每個令牌的評估(對應于與采樣和計算圖形準備相關的 CPU 活動)之間存在間隙。(我將在博文結束后返回到這一點)

圖 1 底部顯示了相同的配置文件,但放大以顯示令牌評估中的幾個活動。令牌評估中的內核之間存在差距是由于啟動開銷引起的。正如本文所展示的,使用 CUDA Graphs 消除這些開銷可顯著提高性能。突出顯示的事件是從 CPU 啟動內核(左下角),并在 GPU 上執行相應的內核(右上角):CPU 能夠在 GPU 上執行之前很長時間成功啟動。
因此,此處的 CPU 端啟動開銷并不在關鍵路徑上,而是由于每次內核啟動相關的 GPU 端活動而產生的開銷。此行為可能因不同的模型和硬件而異,但 CUDA 圖形適用于減少 CPU 和/或 GPU 啟動開銷。
引入 CUDA 圖形以減少開銷
Llama.cpp 已使用 GGML 格式的“圖形”概念。每個令牌的生成涉及以下步驟:
- 根據所用模型準備 GGML 圖形結構。
- 評估正在使用的后端結構(在本例中為 NVIDIA GPU),以獲取“logits”,記錄下一個令牌在詞匯表中的對數概率分布。
- 在 CPU 上執行采樣,使用 Logits 從詞匯表中選擇令牌。
通過截取 GPU 圖形評估階段引入了 CUDA 圖形。添加了代碼以將現有流捕獲到圖形中,將捕獲的圖形實例化為可執行圖形,并將其啟動到 GPU 以執行單個令牌的評估。
為了獲得適當的效率,必須多次重復使用相同的圖形;否則,新引入的捕獲和實例化所涉及的開銷將大于收益。但是,圖形會隨著推理的進行而動態演變。面臨的挑戰是開發一種機制,以跨令牌對圖形進行微調(低開銷),從而實現整體收益。
隨著推理的進行,操作長度會隨著上下文大小的增加而增加,從而導致計算圖形發生實質性的(但不頻繁)更改。GGML 圖形會接受檢查,并僅在需要時重新捕獲。cudaGraphExecUpdate 用于更新先前實例化的可執行文件圖形,其開銷遠遠低于完全重新實例化。
計算圖形也有頻繁但非常微小的更改,其中每個令牌的某些節點(與 KV 緩存相關)的內核參數會發生變化。NVIDIA 開發了一種機制,僅在可重復使用的 CUDA 圖形中更新這些參數。在啟動每個圖形之前,我們利用 CUDA 圖形 API 功能來識別圖形中需要更新的部分,并手動替換相關參數。
請注意,CUDA 圖形目前僅限于批量大小為 1 的推理(Llama.cpp 的關鍵用例),并計劃針對更大的批量大小開展進一步的工作。有關這些進展以及為解決問題和限制而正在進行的工作的更多信息,請參閱 GitHub 問題、NVIDIA 為在 Llama.cpp 中使用 CUDA 圖形而進行的新優化,以及此處鏈接的拉取請求。
CUDA 圖形在降低開銷方面的影響
在引入 CUDA Graphs 之前,由于 GPU 端啟動開銷,內核之間存在顯著差距,如圖 1 底部配置文件所示。
圖 2 顯示了與 CUDA Graphs 的等效關系。所有內核都作為同一計算圖形的一部分(通過單個 CUDA API 啟動調用)提交給 GPU。這極大地減少了開銷:圖形中每個內核之間的差距現在非常小。

性能結果
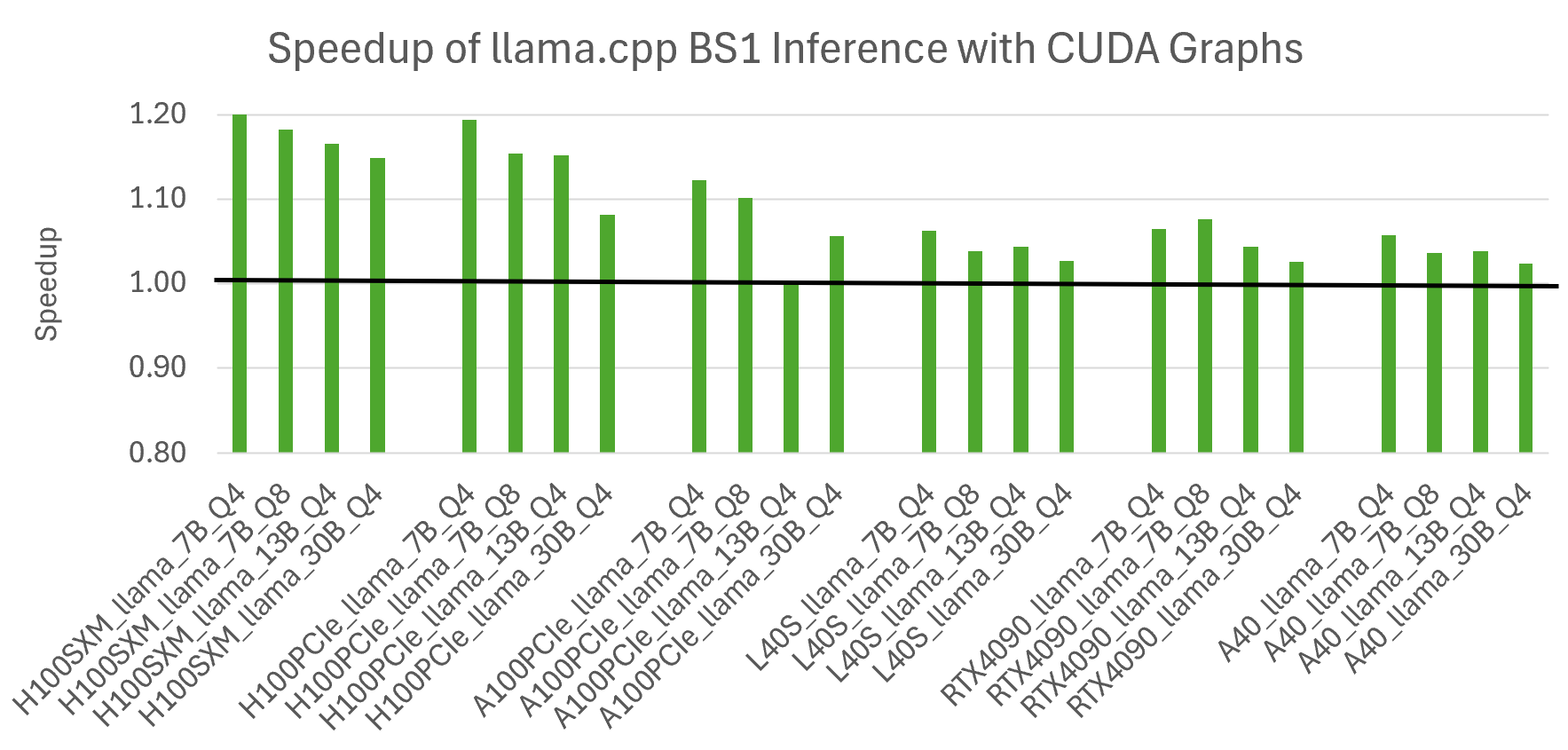
圖 3 顯示了 llama.cpp 中新的 CUDA Graphs 功能的優勢。測量到的加速因模型大小和 GPU 變體而異,隨著模型大小的減少和 GPU 功能的增加,收益也在增加。這符合預期,因為使用 CUDA Graph 可減少與快速 GPU 上的小問題相關的開銷。在速度最快的 NVIDIA H100 GPU 上,最小的 Llama 7B 模型實現的最高加速是 1.2 倍。所有結果都使用 Linux 系統。
在 Llama.cpp 主分支中,NVIDIA GPU 上的批量大小為 1 的推理現在默認啟用 CUDA 圖形。
減少 CPU 開銷的持續工作
圖 1 中的頂部配置文件顯示了時間軸中令牌評估之間的差距(GPU 處于空閑狀態)。這些差距是與準備 GGML 圖形和采樣相關的 CPU 活動造成的。正如此 GitHub 問題及其鏈接的拉取請求中所述,減少這些開銷的工作處于高級階段。這項工作預計將提供高達 10% 的進一步改進。
總結
在本文中,我展示了在熱門的 Llama.cpp 代碼庫中引入 CUDA Graph 如何顯著提高了 NVIDIA GPU 上的 AI 推理性能,并且正在進行的工作有望實現進一步的增強。要將這項工作用于您自己的 AI 支持的工作流,請按照使用說明進行操作。






