大規模圖形神經網絡 (GNN) 訓練帶來了艱巨的挑戰,特別是在圖形數據的規模和復雜性方面。這些挑戰不僅涉及神經網絡的正向和反向計算的典型問題,還包括帶寬密集型圖形特征收集和采樣以及單個 GPU 容量限制等問題。
在上一篇文章中,WholeGraph 被作為 RAPIDS cuGraph 庫中的一項突破性功能,旨在優化大規模 GNN 訓練的內存存儲和檢索。
在我的簡介文章奠定的基礎上,本文將更深入地探討 WholeGraph 的性能評估。我的重點還擴展到它作為存儲庫和 GNN 任務促進器的作用。借助 NVIDIA NVLink 技術的強大功能,我將探討 WholeGraph 如何應對 GPU 間通信帶寬的挑戰,有效打破通信瓶頸并簡化數據存儲。
通過檢查其性能和實際應用,我的目標是展示 WholeGraph 在克服大規模 GNN 訓練中固有障礙方面的有效性。
作為存儲的 WholeGraph 性能
為了評估使用 WholeGraph 作為存儲的性能,我測量了固定長度內存隨機采集的帶寬。固定長度組織為具有固定嵌入維度的浮點嵌入向量。
測試在 NVIDIA DGX-A100 系統上進行,涵蓋了 WholeGraph 支持的所有內存類型:
- 8 塊 NVIDIA A100 GPU 通過 NVIDIA NVSwitch 互聯。
- 每個 GPU 的雙向帶寬為 600 GB/s,轉換為每個 GPU 每個方向的 300 GB/s 帶寬。
- 每兩個 GPU 連接到一個 PCIe 4.0 交換機,共享一個 PCIe 4.0 x16 主機帶寬,因此每兩個 GPU 到主機顯存的共享帶寬為 32GB/s。
- 理論上,跨多個 GPU 的內存聚合帶寬為 300 GB/s 每個 GPU 8/7=343 GB/s.關于主機內存,理論上每個 GPU 的聚合帶寬為 32 GB/s/2=16 GB/s。
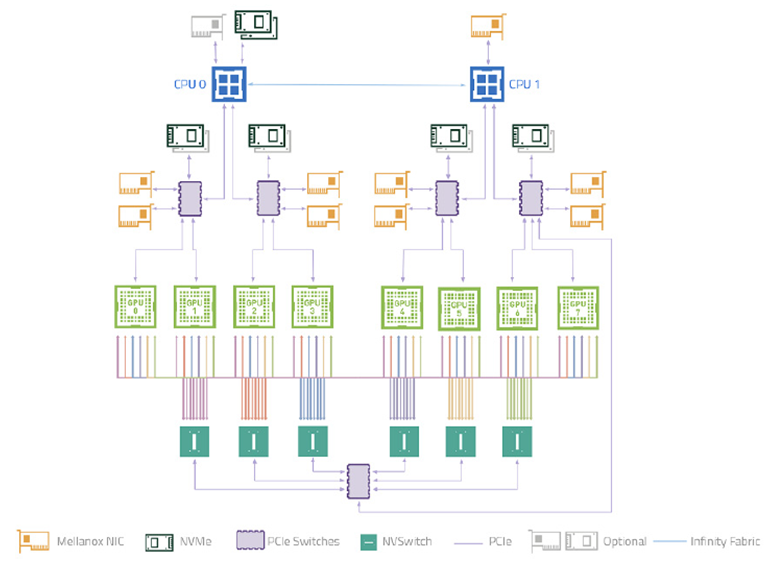
表 1 顯示了基準測試結果。由于連續和分塊類型的主機內存現在使用相同的實現,因此它們使用相同的列。如您所見,對于分塊設備內存,您可以獲得 75%的 NVLink 帶寬。對于主機內存,您可以獲得約 80%的 PCIe 帶寬。
| 嵌入維度 | 連續設備 | 分塊設備 | 分布式設備 | 非分布式+主機 | 分布式主機 |
| 32 | 2.78 | 264.16 | 113.29 | 2.47 | 11.73 |
| 64 | 5.35 | 260.99 英鎊 | 133.25 | 4.91 | 12.2 |
| 128 | 10.35 | 501.03 | 144.61 | 9.73 | 12.31 |
| 256 | 19.74 | 501.18 | 14951 | 13.18 | 12.34 |
| 512 | 36.93 | 264.45 | 151.82 | 12.89 | 12.34 |
| 1024 | 68.66 | 260.25 | 155.28 | 13.18 | 12.34 |
*Non-Distributed host (非分布式主機) 是指 Continuous host (連續主機) 和 Chunked host (分塊主機),因為它們使用相同的實現。
WholeGraph 在 GNN 任務中的性能
為了評估 WholeGraph 在 GNN 任務中的性能,我使用了 OGBN-Papers100M 數據集 作為測試數據集。該數據集包含約 1.11 億個節點和 32 億個邊緣,每個節點具有 128-dim 特征,并包含 172 類節點分類任務。
在本次評估中,我將 WholeGraph 23.10 用于圖形和特征存儲,并將 cuGraphOps 用于 GNN 層實現。與之前一樣,測試也在 DGX-A100 服務器上進行。
計算性能提升
首先,我想重點介紹一下使用 cuGraph-Ops 的最新版 WholeGraph 23.10 與之前版本的 WholeGraph 相比的性能提升。
我使用相同的訓練配置和訓練樣本數,其中樣本數為[3030,30],并訓練了 24 次,以驗證準確性是否良好 (測試準確率約為 65%)。改進如圖 2 所示。
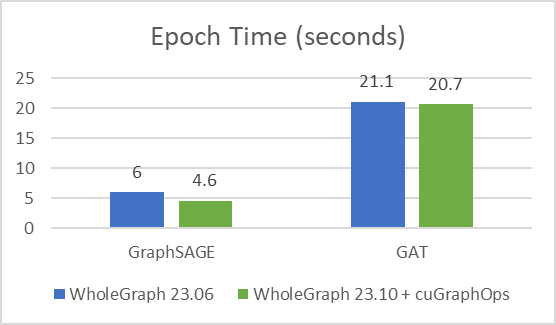
收優化時間
對于任何數據集,都可能存在最佳樣本數量或其他超參數,從而為目標精度提供最佳時間。增加樣本數量可能會導致大量計算,但準確度幾乎沒有提高。
我發現,對于目標測試準確率為 65% 的 ogmbn-papers100M 數據集,可以使用 [15,10, 5] 作為訓練樣本數。這與 Intel 在其論文中所報道的類似結果一致。
使用類似的樣本計數對于比較很重要,因為減少樣本數量可以顯著減少計算負載。例如,通過將樣本數量從[3030,30]減少到[15, 10, 5],計算工作負載的減少量可多達 36 倍。為了實現約 65%的測試準確率,也可能不需要執行 24 次迭代。我還調整了批量大小和學習率等超參數。
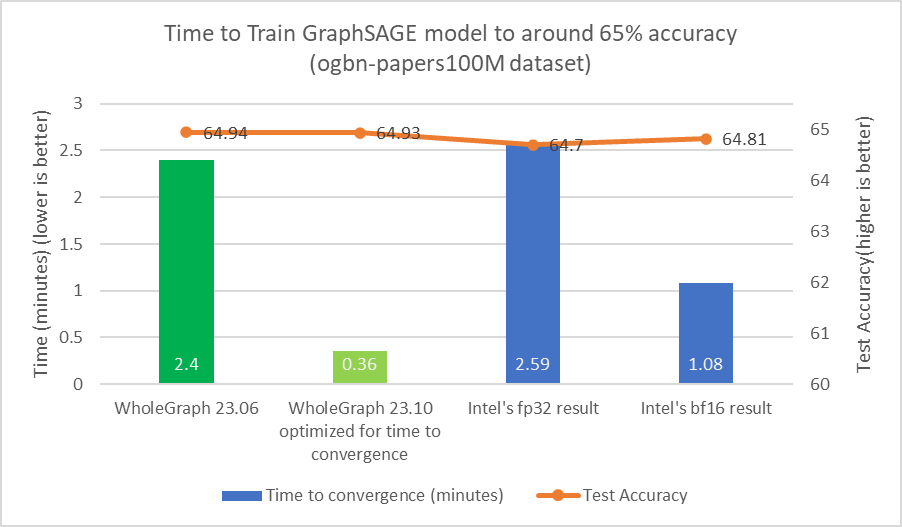
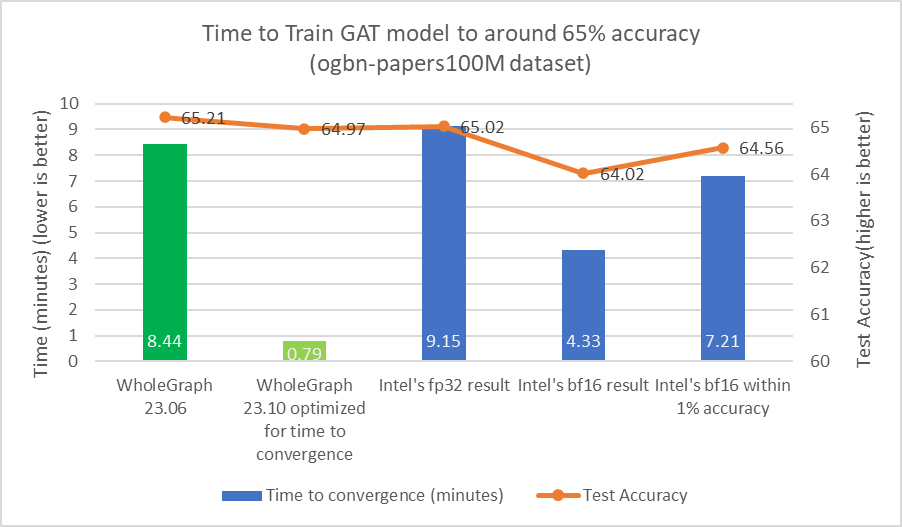
從圖 3 和圖 4 中可以看出,WholeGraph 在收時間方面實現了顯著的加速。有關與 8 節點雙路英特爾 8480+CPU 服務器比較的更多信息,請參閱以創紀錄的速度設置圖形神經網絡模型。收時間可能因計算環境不同而有所差異。
結束語
在本文中,我展示了 WholeGraph 的性能,它與硬件的理論性能非常接近。我展示了它在現實世界的 GNN 任務中的性能,重點介紹了它顯著加速 GNN 工作負載的能力。作為底層硬件, NVIDIA GPU 和 NVLink 技術為 GNN 任務提供了出色的硬件平臺。
?