NVIDIA AI Enterprise 是一個端到端、安全的云原生 AI 軟件套件。最近發布的 NVIDIA AI Enterprise 3.0 引入了新功能,以幫助優化生產 AI 的性能和效率。本文提供了以下新功能及其工作原理的詳細信息。
- Magnum IO GPUDirect Storage
- GPU virtualization with VMware vSphere 8.0
- Red Hat Enterprise Linux ( RHEL ) KVM 8 和 9
- 分數多 v GPU 支架
- 擴展對 NVIDIA AI 的支持
生產 AI 功能
NVIDIA AI Enterprise 3.0 版本中的新 AI 工作流有助于縮短生產 AI 的開發時間。這些工作流是常見 AI 用例的參考應用程序,包括聯絡中心智能虛擬助理、音頻轉錄和數字指紋。
未加密的預訓練模型也首次包括在內,確保了 AI 的可解釋性,并使開發人員能夠查看模型的權重和偏差,了解模型偏差。
NVIDIA AI Enterprise 現在支持 NGC catalog 中發布的所有 NVIDIA 人工智能軟件。開始 NGC 之旅的開發者現在可以無縫過渡到 NVIDIA AI Enterprise 訂閱,并利用 NVIDIA Enterprise 支持 50 多個 AI 框架、預訓練模型和 SDK 。
基礎結構性能特征
NVIDIA AI Enterprise 3.0 包含許多有助于優化基礎設施性能的新功能,因此您可以充分利用您的 AI 投資,并最大限度地節省成本和時間。下面將更詳細地解釋這些功能。
Magnum IO GPU 直接存儲
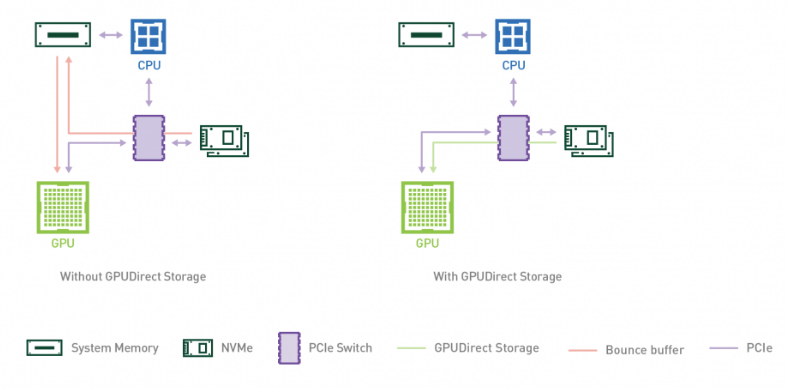
企業現在可以利用 NVIDIA AI Enterprise 3.0 部署中 Magnum IO GPUDirect Storage 的性能優勢來加速和擴展其 AI 工作負載。 GPUDirect Storage 1.4 在本地或遠程存儲和 GPU 內存之間提供了直接數據路徑,為復雜的工作負載提供了無與倫比的性能。
GPUDirect Storage 為在 GPU 上消費或生成數據而不需要 CPU 處理的應用程序簡化了存儲和 GPU buffer 之間的數據流。它使用遠程直接內存訪問( RDMA )在直接路徑上快速將數據從存儲移動到 GPU 內存,通過消除通過緩沖區進行的額外復制,減少了延遲并減輕了 CPU 的負擔。
GPUDirect Storage 提供了顯著的性能改進,與基線 NumPy 相比, NVIDIA DALI 的深度學習推理性能提高了 7.2 倍。有關詳細信息,請參見 NVIDIA Magnum IO 。
NASA Mars Lander 演示?使用 NVIDIA IndeX 和 GPUDirect Storage 以及 27000 多個 NVIDIA GPU 來模擬反向推進,當利用 PCIe 交換機和 NVLinks 與 GPUDirect 存儲時,帶寬增益為 5 倍。
要了解更多信息,請參閱 guide for running NVIDIA AI Enterprise with GPUDirect Storage 。
GPU VMware vSphere 8.0 的虛擬化功能
NVIDIA AI Enterprise 3.0 引入了對 VMware vSphere 8 的支持,其中包括一些可加快性能和提高操作效率的功能。 VMware 環境現在可以將最多八個虛擬 GPU 添加到一個 VM 中,使 v GPU 的數量比以前的版本增加了一倍。這提高了大型 ML 模型的性能,并為復雜的 AI 和 ML 工作負載提供了更高的可擴展性。
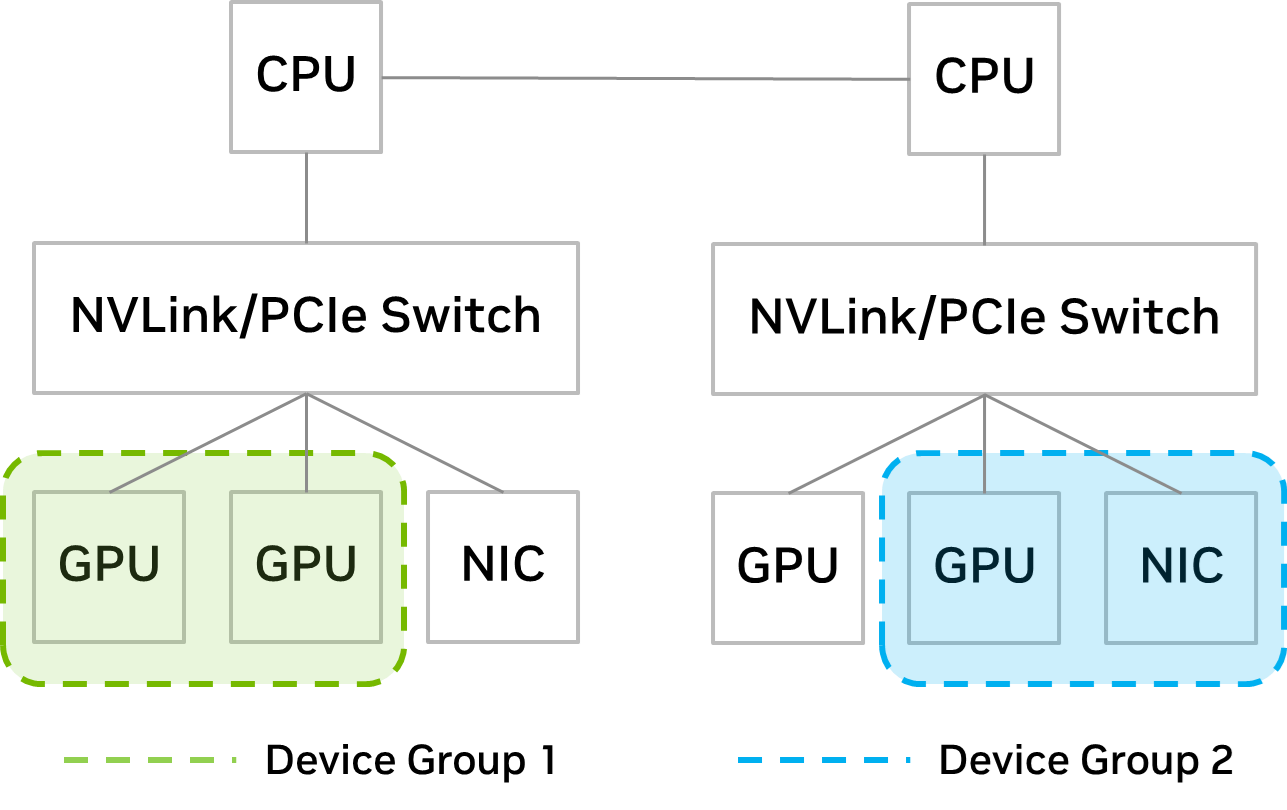
通過引入設備組, IT 管理員現在可以更好地控制 VM 的放置。 Distributed Resource Scheduler ( DRS )是 vSphere 中包含的一個管理工具,用于確定最佳虛擬機位置。
新的設備組功能提供了在硬件級別(通過 NVLink 或 PCIe 交換機)彼此配對的 PCIe 設備的詳細信息, IT 管理員可以從中選擇一個子集,以向 VM 提供 DRS 放置決策。
通過設備組, IT 管理員可以確保將設備的子集一起分配給 VM 。例如,如果用戶希望擴大 GPU 以加速大型模型, IT 管理員可以創建一個包含 GPU 的設備組,其中包含 NVLinks 。如圖 2 所示,如設備組 1 所示。
如果用戶希望跨多個服務器擴展以進行分布式培訓,設備組可以由共享同一 PCIe 交換機的 GPU 和 NIC 組成。這在圖 2 中顯示為設備組 2 。
Red Hat Enterprise Linux KVM
NVIDIA AI Enterprise 3.0 擴展了虛擬化支持,包括 Red Hat Enterprise Linux 8.4 、 8.6 、 8.7 、 9.0 和 9.1 ,使企業能夠將 KVM 功能擴展到其 AI 工作負載。使用 RHEL KVM ,管理員可以將多達 16 個虛擬 GPU 添加到一個 VM 中,為計算密集型工作負載提供了指數級的更快處理。有關使用 RHEL KVM 部署 NVIDIA AI Enterprise 的更多信息,請訪問 NVIDIA AI Enterprise Documentation Center 。
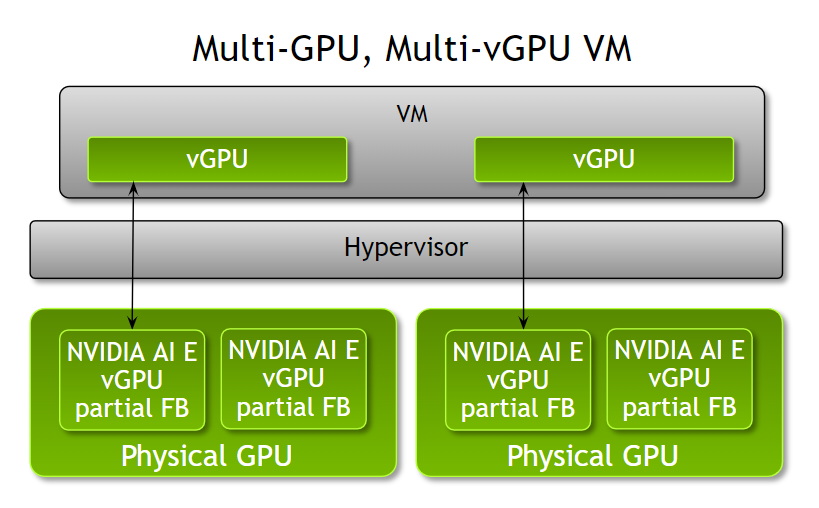
分數多 v GPU 支架
管理員現在可以使用 NVIDIA AI Enterprise 3.0 為單個虛擬機提供多個分數 v GPU ,從而提高了根據工作負載優化虛擬機配置的靈活性。在此版本之前, VM 只能通過 GPU 的單個部分、完整 GPU 或每個 VM 的多個 GPU 來加速。
管理員現在有了更大的靈活性,可以根據工作負載計算需求為 VM 分配多個部分 v GPU 配置文件。例如,當運行具有不同計算需求的多個推理工作負載時,管理員可以根據工作負載內存需求為 VM 分配 NVIDIA A100 Tensor Core GPUs 的部分配置文件和不同數量的幀緩沖區。
請注意,所有部分型材必須是相同的板類型和系列。這些部分 v GPU 配置文件可以從一個或多個物理 GPU 中分配。此功能在 VMware vSphere 8 和 RHEL KVM 8 和 9 上都可用。
擴展對 NVIDIA AI 的支持
NVIDIA AI Enterprise 為 NGC 目錄中發布的所有 NVIDIA 人工智能軟件提供支持,該目錄現在包含 50 多個框架和模型。所有受支持的型號都標有“ NVIDIA AI Enterprise supported ”,以幫助用戶輕松識別受支持的軟件。
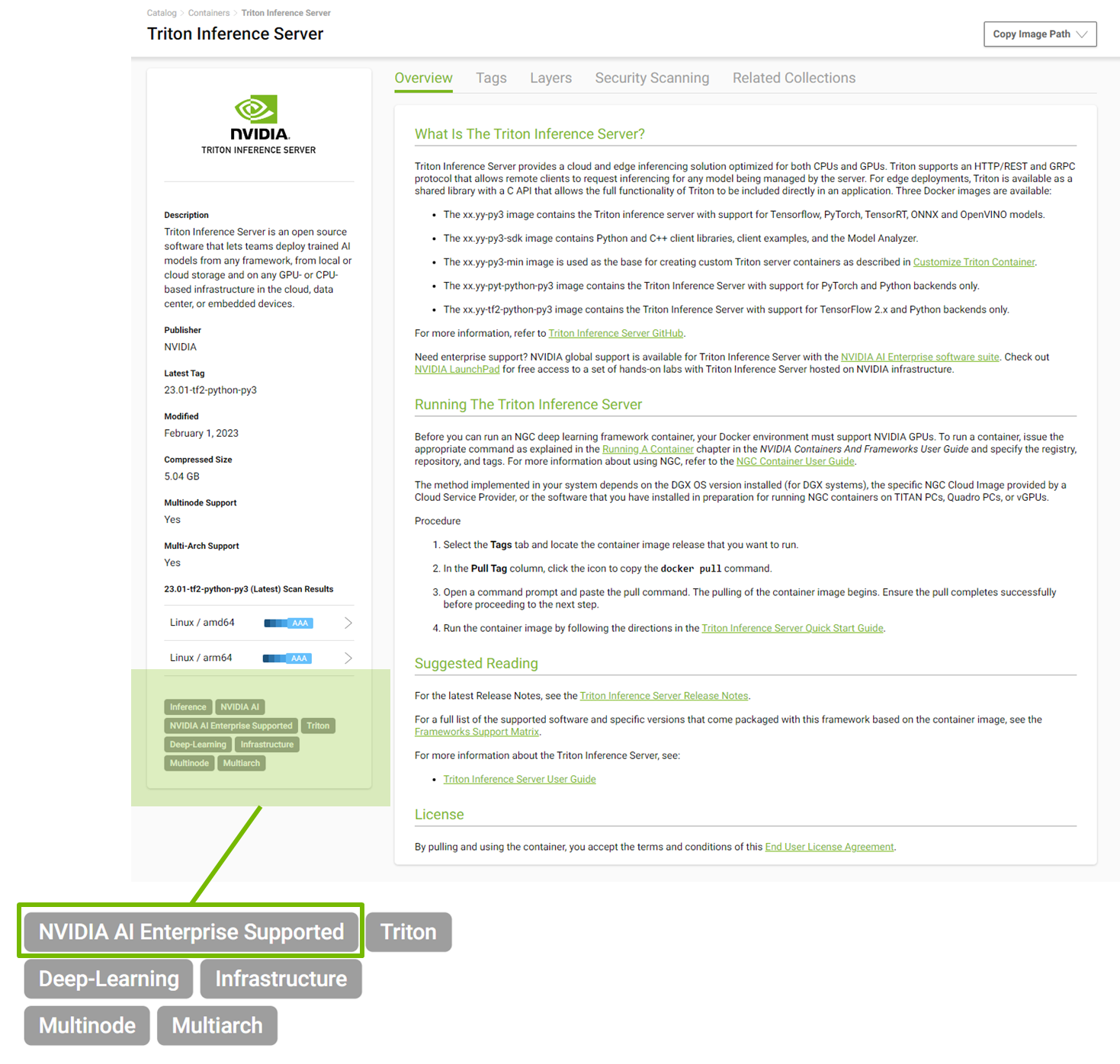
結論
借助 NVIDIA AI Enterprise 的最新 3.0 版本,企業可以通過最新的性能和效率優化縮短生產 AI 的開發時間。 NVIDIA LaunchPad 上的 Get Started with NVIDIA AI Enterprise 。 LaunchPad 可在私人加速計算環境(包括動手實驗室)中即時、短期訪問 NVIDIA AI Enterprise 軟件套件。
Register for NVIDIA GTC 2023 for free 并于 3 月 20 日至 23 日加入我們,了解 NVIDIA AI Enterprise 和其他技術如何用于解決棘手的 AI 挑戰。
?






