
專注于編碼的 大語言模型(LLMs) 已穩步應用于開發者工作流程。從配對編程到自我改進的 AI 智能體 ,這些模型可幫助開發者完成各種任務,包括增強代碼、修復錯誤、生成測試和編寫文檔。
為促進開源 LLM 的開發,Qwen 團隊最近發布了 Qwen2.5-Coder,這是一系列先進的 LLM,用于跨熱門編程語言的代碼生成、推理和修復。本文將探討針對 NVIDIA TensorRT-LLM 支持 的 Qwen2.5-Coder 模型進行推理優化的優勢,以及借助 NVIDIA NIM 輕松部署以提升變革潛力和編碼效率的好處。
Qwen2.5-Coder 模型?
Qwen2.5-Coder 模型在熱門的學術基準測試中取得了出色的性能。 NVIDIA TensorRT-LLM 已對 Qwen2.5-Coder 系列的三種熱門模型 (1.5B、7B 和 32B 版本) 進行優化,以實現高吞吐量和低延遲。TensorRT-LLM 是一個用于快速、高效 LLM 推理的庫,包含動態機上 批處理 、 KV 緩存 、 KV 緩存重復使用 和幾種預測性解碼技術等優化功能。
這些優化有助于提高 Qwen2.5-Coder 模型在 Python、C++、Java、Bash、Javascript、TypeScript 和 Go 等熱門編程語言中的性能,從而使更多開發者受益。本文將探討 lookahead decoding 優化的前瞻性及其有助于實現的性能提升。開發者無需進行任何額外訓練,也無需額外的草圖模型,即可利用 TensorRT-LLM 高級 API 加速 Qwen2.5-Coder 推理,以生成多行自動代碼完成。

解碼前景展望?
解碼前瞻是一種預測性解碼技術,可解決 LLMs 緩慢自回歸的問題。每個自回歸解碼步驟一次僅生成一個 token,無法利用 NVIDIA GPUs 強大的并行處理能力,導致 GPU 利用率低、吞吐量低。我們之前討論過通過草稿目標預測解碼可以實現的吞吐量提升,在這里,我們討論了以 Qwen2.5-Coder 模型為例,利用 TensorRT-LLM lookahead decoding 實現的優勢。
與自回歸解碼中的單令牌生成不同,前瞻性解碼可同時生成多個令牌,充分利用 GPU 的并行處理能力,利用計算(FLOPs)降低延遲。此外,對于草稿目標預測性解碼,前瞻性解碼不需要使用單獨的草稿模型。
每個解碼步驟分為兩個并行分支,即 lookahead 分支和驗證分支。通過使用經典的非線性系統求解器 Jacobi 迭代法 ,lookahead 分支通過生成 n-grams 來對未來的 tokens 執行并行解碼。驗證分支選擇并驗證由 lookahead 分支生成的有前景的 n-gram 候選項。
前瞻性算法使用三個關鍵參數進行配置:窗口大小(W),n-gram 大小(N)和驗證集大小(G)。
- 窗口大小 (W):表示前瞻性窗口大小,它決定了算法在每個步驟中嘗試預測的未來令牌數量。窗口大小越大,模型的視野越廣,一次傳遞就能生成更多 token。這可有效提高吞吐量性能,同時高效利用 GPU 計算 FLOPs。
- N-gram size (N):表示前瞻性流程中使用的 N – gram 的大小。例如,5-gram 是由 5 個未來令牌組成的連續序列。它與窗口大小一起為前瞻性分支創建了一個大小固定的 2D 窗口,以便從 Jacobi 迭代軌跡生成 n-gram。
- 驗證集大小 (G):表示算法在每個驗證步驟中考慮的推測或候選 n-gram 的最大數量。它平衡了計算效率與探索更多可能性之間的權衡。

未來的性能很大程度上取決于基礎模型、硬件、批量大小、序列長度和數據集。建議分析各種配置,以找到給定設置的最佳 (W,N,G) 配置。最佳 (W,N,G) 元組配置支持 lookahead 解碼前瞻性,無需任何其他訓練、fine-tuning 或 draft 模型,即可提供更高的吞吐量性能。
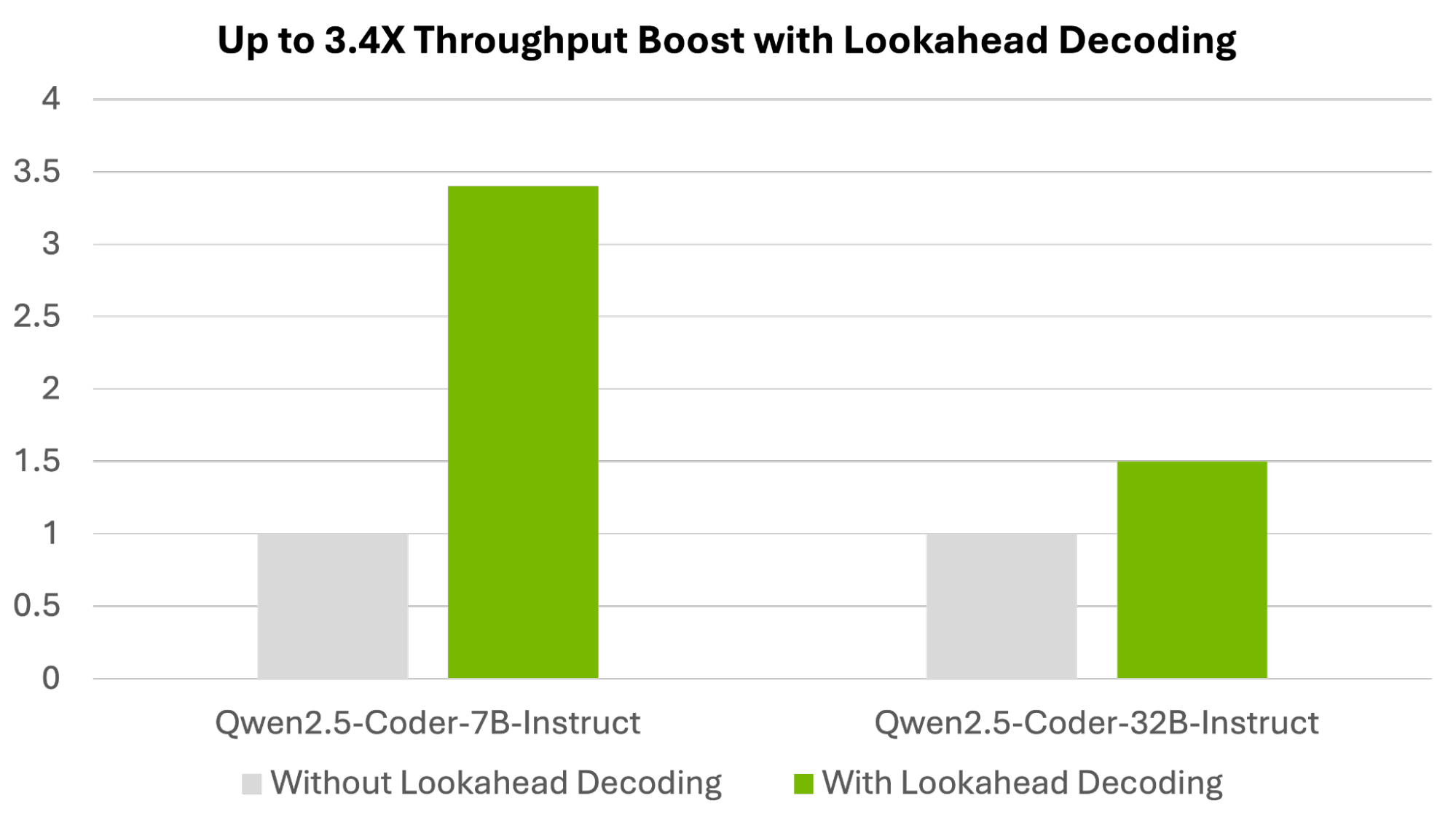
通過對 (W,N,G) 配置值掃描的實驗,我們分別為 Qwen2.5-Coder 7B Instruct 和 Qwen2.5-Coder 32B Instruct 模型實現了 3.6 倍和 1.6 倍的吞吐量加速。這些加速是通過 NVIDIA H100 Tensor Core GPUs 上的吞吐量 (tokens/second) 與基線 (無 lookahead speculative decoding) 的比較進行測量的,如 Figure 2 所示。

數據測量日期:2025 年 1 月 30 日。Qwen2.5-Coder 7B Instruct 和 Qwen2.5-Coder 32B Instruct 模型的推理吞吐量(輸出令牌/秒)加速。DGX H100,TP=1 | (W,N,G)= (8,8,8)| Qwen2.5-Coder 7B Instruct,TP=2 | (W,N,G)= (15,15,15)| Qwen2.5-Coder-32B-Instruct,批量大小=1,TensorRT-LLM 版本 0.15.0。
NVIDIA H200 Tensor Core GPU 也實現了類似的吞吐量加速。憑借更高的顯存帶寬,它們還有助于提高基準吞吐量性能,從而使速度略低于 H100 GPU (圖 3)。
數據測量日期:2025 年 1 月 30 日。Qwen2.5-Coder 7B Instruct 和 Qwen2.5-Coder 32B Instruct 模型的推理吞吐量(輸出令牌/秒)加速。DGX H200,TP=1 | (W,N,G)= (8,8,8)| Qwen2.5-Coder 7B Instruct,TP=2 | (W,N,G)= (15,15,15)| Qwen2.5-Coder 32B Instruct,批量大小=1,TensorRT-LLM 版本 0.15.0。
使用 TensorRT-LLM 進行解碼的前瞻性運行步驟
要在 TensorRT-LLM 中使用預測性解碼重現這些性能提升,請執行以下步驟。
# Install TensorRT-LLM. (Commands below are for Linux. Refer to TensorRT-LLM docs for Windows)sudo apt-get -y install libopenmpi-dev && pip3 install --upgrade setuptools && pip3 install tensorrt_llm --extra-index-url https://pypi.nvidia.com |
然后,使用高級 API 在 TensorRT-LLM 中運行 lookahead decoding。
# Command for Qwen2.5-Coder-7B-Instructfrom tensorrt_llm import LLM, SamplingParamsfrom tensorrt_llm.llmapi import (LLM, BuildConfig, KvCacheConfig, LookaheadDecodingConfig, SamplingParams)def main(): """The end user can customize the build configuration with the build_config class. # Max draft length is based on (W,N,G) values and calculated as: (W + G -1) * (N-1) + ( N<=1 ? 0: N-2)""" build_config = BuildConfig(max_batch_size = 128,max_input_len = 2048, max_seq_len = 4096,max_num_tokens = 16384, max_draft_len = 111) build_config.plugin_config.reduce_fusion = True build_config.plugin_config.use_paged_context_fmha = True build_config.plugin_config.multiple_profiles = True # The configuration for lookahead decoding lookahead_config = LookaheadDecodingConfig(max_window_size=8, max_ngram_size=8, max_verification_set_size=8) kv_cache_config = KvCacheConfig(free_gpu_memory_fraction=0.4) llm = LLM(model="Qwen/Qwen2.5-Coder-7B-Instruct", kv_cache_config=kv_cache_config, build_config=build_config, speculative_config=lookahead_config) prompt = """Write a C++ program to find the nth Fibonacci number using recursion. Now we define a sequence of numbers in which each number is the sum of the three preceding ones. The first three numbers are 0, -1, -1. Write a program to find the nth number.""" sampling_params = SamplingParams(lookahead_config=lookahead_config) output = llm.generate(prompt, sampling_params=sampling_params) print(output)if __name__ == '__main__': main() |
總結?
前瞻性預測解碼可提高 LLMs 的吞吐量,而無需任何其他訓練、微調或草稿模型。我們展示了 Qwen2.5-Coder 模型的基準性能改進。 訪問 build.nvidia.com,免費試用通過 NVIDIA TensorRT-LLM 優化的 Qwen2.5-Coder 模型。 為便于部署, 我們還將通過 TensorRT-LLM 優化的 Qwen2.5-Coder 模型打包為可下載的 NVIDIA NIM 微服務。
致謝?
在此, 我們要感謝馬立偉、李凡融、Nikita Korobov 和 Martin Marciniszyn Mehringer 為支持這篇博文所付出的努力 。
?






