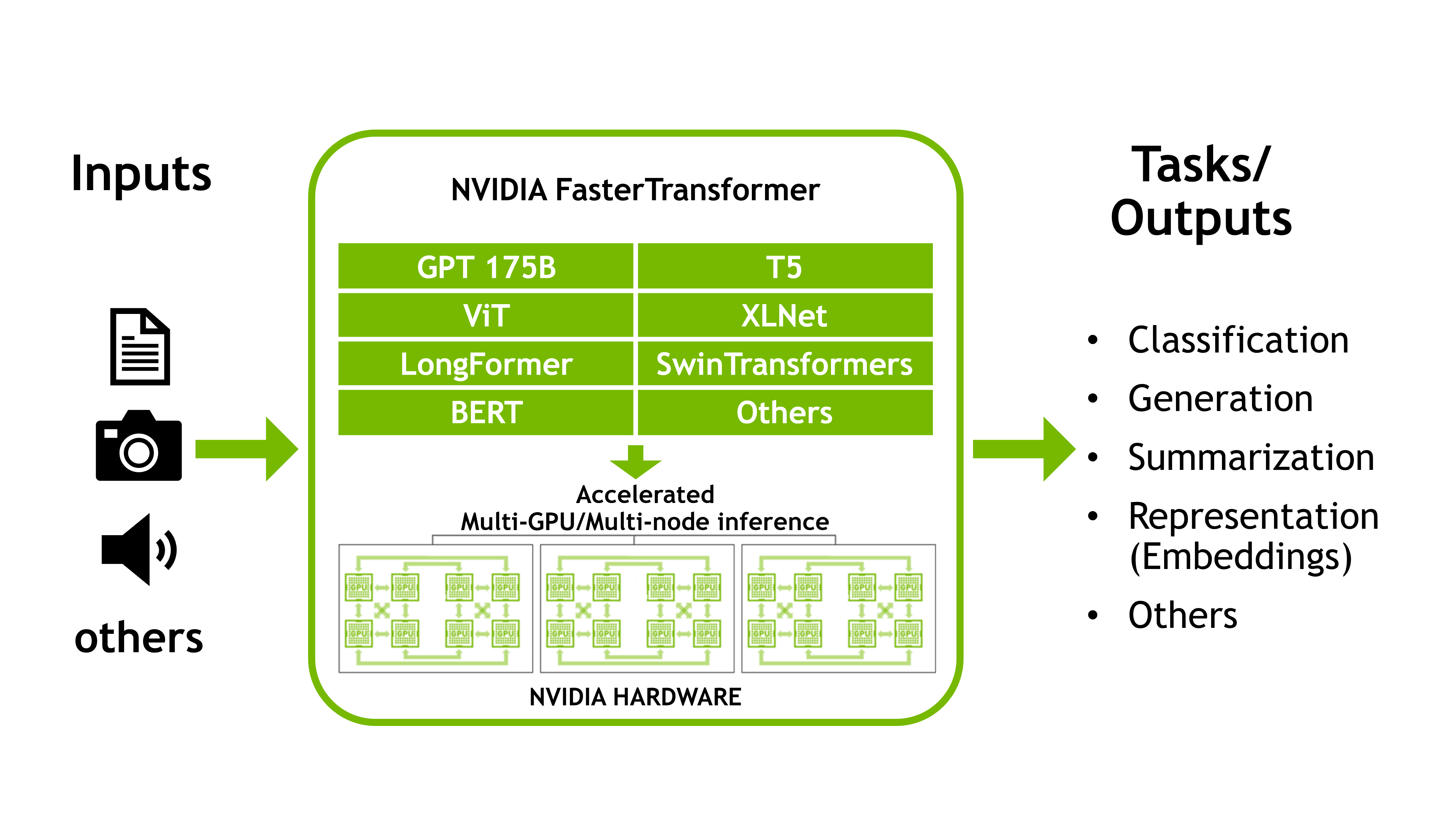
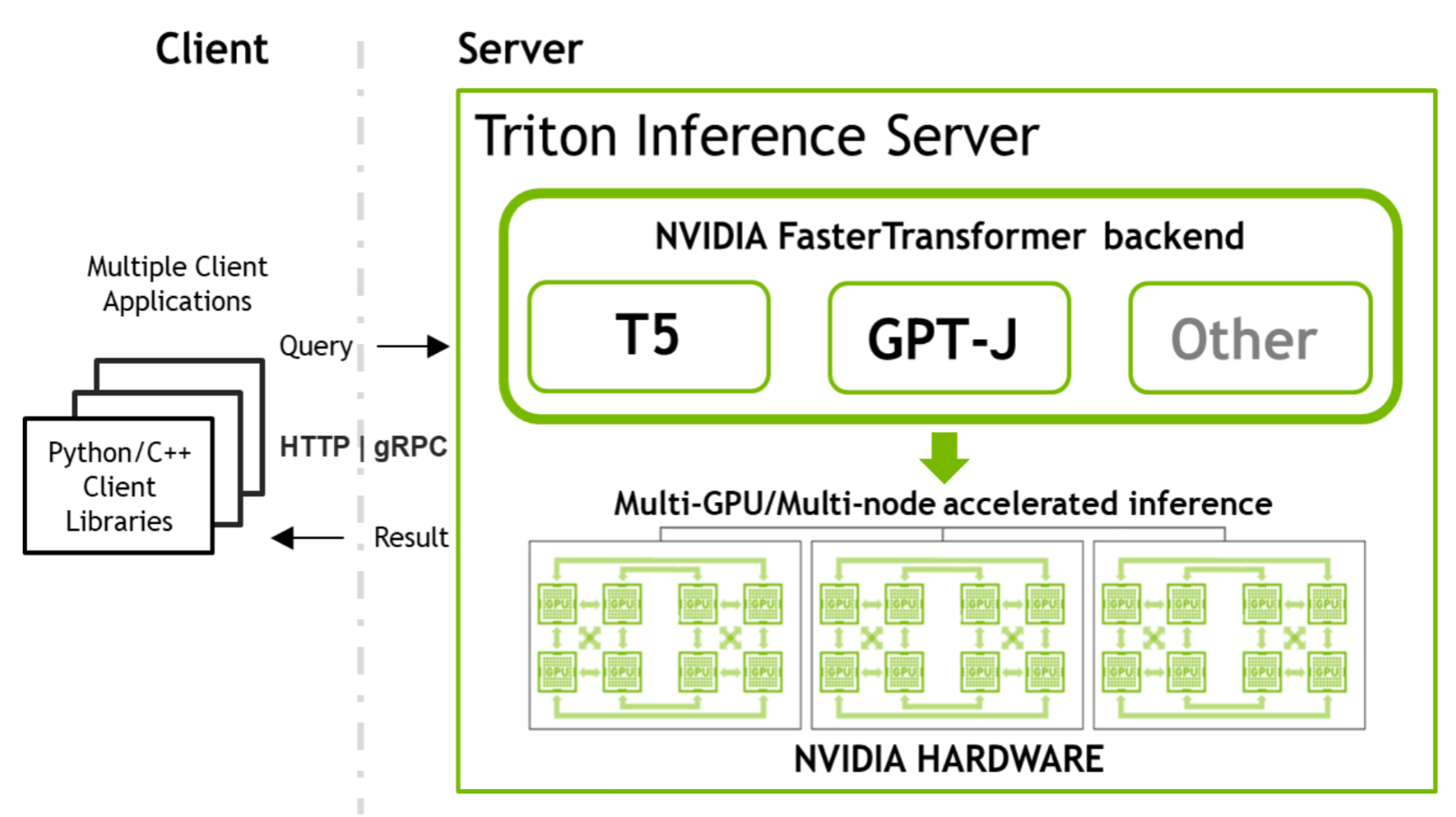
這個 transformer 體系結構 完全改變了(雙關語)自然語言處理( NLP )的領域。近年來,在 transformer 構建塊 BERT 、 GPT 和 T5 上構建了許多新穎的網絡體系結構。隨著品種的增加,這些型號的尺寸也迅速增加。
雖然較大的神經語言模型通常會產生更好的結果,但將它們部署到生產環境中會帶來嚴重的挑戰,尤其是對于在線應用程序,在這些應用程序中,幾十毫秒的額外延遲可能會對用戶體驗產生顯著的負面影響。
使用最新的 TensorRT 8.2 ,我們優化了 T5 和 GPT-2 模型,以實現實時推理。您可以將 T5 或 GPT-2 模型轉換為 TensorRT 引擎,然后將此引擎用作推理工作流中原始 PyTorch 模型的插件替換。與 PyTorch GPU 推理相比,此優化導致延遲減少 3-6 倍,與 PyTorch CPU 推理相比,延遲減少 9-21 倍。
在這篇文章中,我們將向您詳細介紹如何實現相同的延遲減少,使用我們最新發布的基于 Hugging Face transformers 的示例腳本和筆記本,使用 GPT-2 進行開放式文本生成,使用 T5 進行翻譯和摘要。
T5 和 GPT-2 簡介
在本節中,我們將簡要介紹 T5 和 GPT-2 模型。
T5 用于回答問題、總結、翻譯和分類
T5 或文本到文本傳輸 transformer 是谷歌最近創建的一種體系結構。它將所有自然語言處理( NLP )任務重新構造為統一的文本到文本格式,其中輸入和輸出始終是文本字符串。 T5 的體系結構允許將相同的模型、損失函數和超參數應用于任何 NLP 任務,如機器翻譯、文檔摘要、問答和分類任務,如情感分析。
T5 模式的靈感來源于遷移學習在 NLP 中產生了最先進的結果。遷移學習背后的原理是,基于大量可用的未經訓練的數據和自我監督任務的模型可以在較小的任務特定標記數據集上針對特定任務進行微調。事實證明,這些模型比從頭開始針對特定任務數據集訓練的模型具有更好的結果。
基于遷移學習的概念, Google 在 用統一的文本到文本轉換器探索遷移學習的局限性 中提出了 T5 模型。在本文中,他們還介紹了龐大的干凈爬網語料庫( C4 )數據集。在該數據集上預訓練的 T5 模型在許多下游 NLP 任務上實現了最先進的結果。已發布的預訓練 T5 車型的參數范圍高達 3B 和 11B 。
GPT-2 用于生成優秀的類人文本
生成性預訓練 transformer 2 ( GPT-2 )是 OpenAI 最初提出的一種自回歸無監督語言模型。它由 transformer 解碼器塊構建,并在非常大的文本語料庫上進行訓練,以預測段落中的下一個單詞。它生成優秀的類人文本。更大的 GPT-2 模型,最大參數達到 15 億,通常能寫出更好、更連貫的文本。
使用 TensorRT 部署 T5 和 GPT-2
使用 TensorRT 8.2 ,我們通過構建并使用 TensorRT 發動機作為原始 PyTorch 模型的替代品,優化了 T5 和 GPT-2 模型。我們將帶您瀏覽 scripts 和 Jupyter notebooks ,并重點介紹基于擁抱面部變形金剛的重要內容。有關更多信息,請參閱示例腳本和筆記本以獲取詳細的分步執行指南。
設置
最方便的開始方式是使用 Docker 容器,它為實驗提供了一個隔離、獨立和可復制的環境。
構建并啟動 TensorRT 容器:
git clone -b master https://github.com/nvidia/TensorRT TensorRgit clone -b master https://github.com/nvidia/TensorRT TensorRT cd TensorRT git checkout release/8.2 git submodule update --init --recursive ./docker/build.sh --file docker/ubuntu-18.04.Dockerfile --tag tensorrt-ubuntu18.04-cuda11.4 ./docker/launch.sh --tag tensorrt-ubuntu18.04-cuda11.4 --gpus all --jupyter 8888
這些命令啟動 Docker 容器和 JupyterLab 。在 web 瀏覽器中打開 JupyterLab 界面:
http://<host_name>:8888/lab/
在 JupyterLab 中,要打開終端窗口,請選擇 File 、 New 、 Terminal 。編譯并安裝 TensorRT OSS 包:
cd $TRT_OSSPATH mkdir -p build && cd build cmake .. -DTRT_LIB_DIR=$TRT_LIBPATH -DTRT_OUT_DIR=`pwd`/out make -j$(nproc)
現在,您已經準備好繼續使用模型進行實驗。在下面的順序中,我們將演示 T5 模型的步驟。下面的代碼塊并不意味著可以復制粘貼運行,而是引導您完成整個過程。為了便于復制,請參閱 GitHub 存儲庫上的 notebooks 。
在高層次上,使用 TensorRT 優化用于部署的擁抱面 T5 和 GPT-2 模型是一個三步過程:
- 從 HuggingFace 模型動物園下載模型。
- 將模型轉換為優化的 TensorRT 執行引擎。
- 使用 TensorRT 引擎進行推理。
使用生成的引擎作為 HuggingFace 推理工作流中原始 PyTorch 模型的插件替換。
從 HuggingFace 模型動物園下載模型
首先,從 HuggingFace 模型中心下載原始的 Hugging Face PyTorch T5 模型及其關聯的標記器。
T5_VARIANT = 't5-small' t5_model = T5ForConditionalGeneration.from_pretrained(T5_VARIANT) tokenizer = T5Tokenizer.from_pretrained(T5_VARIANT) config = T5Config(T5_VARIANT)
然后,您可以將此模型用于各種 NLP 任務,例如,從英語翻譯為德語:
print(tokenizer.decode(outputs[0], skip_special_tokens=Truinputs = tokenizer("translate English to German: That is good.", return_tensors="pt") # Generate sequence for an input
outputs = t5_model.to('cuda:0').generate(inputs.input_ids.to('cuda:0'))
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
TensorRT 8.2 支持 GPT-2 至“ xl ”版本( 1.5B 參數)和 T5 至 11B 參數,這些參數可在 HuggingFace model zoo 上公開獲得。根據 GPU 內存可用性,也可支持較大型號。
將模型轉換為優化的 TensorRT 執行引擎。
在將模型轉換為 TensorRT 引擎之前,請將 PyTorch 模型轉換為中間通用格式。 ONNX 是機器學習和深度學習模型的開放格式。它使您能夠將 TensorFlow 、 PyTorch 、 MATLAB 、 Caffe 和 Keras 等不同框架中的深度學習和機器學習模型轉換為單一的統一格式。
轉換為 ONNX
對于 T5 型號,使用實用功能分別轉換編碼器和解碼器。
encoder_onnx_model_fpath = T5_VARIANT + "-encoder.onnx"
decoder_onnx_model_fpath = T5_VARIANT + "-decoder-with-lm-head.onnx" t5_encoder = T5EncoderTorchFile(t5_model.to('cpu'), metadata)
t5_decoder = T5DecoderTorchFile(t5_model.to('cpu'), metadata) onnx_t5_encoder = t5_encoder.as_onnx_model( os.path.join(onnx_model_path, encoder_onnx_model_fpath), force_overwrite=False
)
onnx_t5_decoder = t5_decoder.as_onnx_model( os.path.join(onnx_model_path, decoder_onnx_model_fpath), force_overwrite=False
)
轉換為 TensorRT
現在,您已經準備好解析 T5 ONNX 編碼器和解碼器,并將它們轉換為優化的 TensorRT 引擎。由于 TensorRT 執行了許多優化,例如融合操作、消除轉置操作和內核自動調優,以在目標 GPU 體系結構上找到性能最佳的內核,因此此轉換過程可能需要一些時間。
t5_trt_encoder_engine = T5EncoderONNXt5_trt_encoder_engine = T5EncoderONNXFile( os.path.join(onnx_model_path, encoder_onnx_model_fpath), metadata ).as_trt_engine(os.path.join(tensorrt_model_path, encoder_onnx_model_fpath) + ".engine") t5_trt_decoder_engine = T5DecoderONNXFile( os.path.join(onnx_model_path, decoder_onnx_model_fpath), metadata ).as_trt_engine(os.path.join(tensorrt_model_path, decoder_onnx_model_fpath) + ".engine")
使用 TensorRT 引擎進行推理
最后,您現在有了一個針對 T5 模型的優化 TensorRT 引擎,可以進行推斷。
t5_trt_encoder = T5TRTEncoder( t5_trt_encoder_engine, metadata, tfm_config ) t5_trt_decoder = T5TRTDecoder( t5_trt_decoder_engine, metadata, tfm_config ) #generate output encoder_last_hidden_state = t5_trt_encoder(input_ids=input_ids) outputs = t5_trt_decoder.greedy_search( input_ids=decoder_input_ids, encoder_hidden_states=encoder_last_hidden_state, stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length)]) ) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
類似地,對于 GPT-2 模型,您可以按照相同的過程生成 TensorRT 引擎。優化的 TensorRT 引擎可作為 HuggingFace 推理工作流中原始 PyTorch 模型的插件替代品。
TensorRT transformer 優化細節
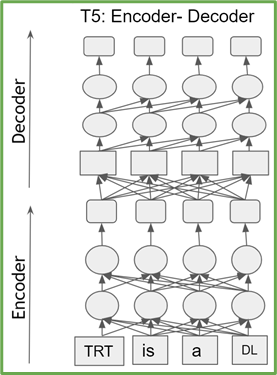
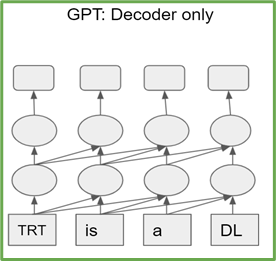
基于轉換器的模型是 transformer 編碼器或解碼器塊的堆棧。編碼器(解碼器)塊具有相同的結構和參數數量。 T5 由 transformer 編碼器和解碼器的堆棧組成,而 GPT-2 僅由 transformer 解碼器塊組成(圖 1 )。
每個 transformer 塊,也稱為自我注意塊,通過使用完全連接的層將輸入投影到三個不同的子空間,稱為查詢( Q )、鍵( K )和值( V ),由三個投影組成。然后將這些矩陣轉換為 QT和 KT用于計算標準化點積注意值,然后與 V 組合T生成最終輸出(圖 2 )。
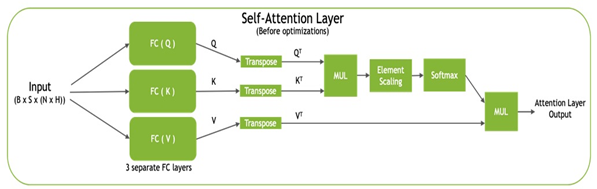
TensorRT 通過逐點層融合優化自我注意塊:
- 還原與電源操作相融合(用于圖層模板和剩余添加圖層)。
- 電子秤與 softmax 融合在一起。
- GEMM 與 ReLU / GELU 激活融合。
此外, TensorRT 還優化了推理網絡:
- 消除轉置操作。
- 將三個 KQV 投影融合為一個 GEMM 。
- 當指定 FP16 模式時,控制逐層精度以保持精度,同時運行 FP16 中計算最密集的運算。
TensorRT 對 PyTorch CPU 和 GPU 基準
通過 TensorRT 進行的優化,我們看到 PyTorch GPU 推理的加速比高達 3-6 倍,而 PyTorch CPU 推理的加速比高達 9-21 倍。
圖 3 顯示了批量為 1 的 T5-3B 模型的推理結果,該模型用于將短短語從英語翻譯成德語。 A100 GPU 上的 TensorRT 引擎與在雙插槽 Intel Platinum 8380 CPU 上運行的 PyTorch 相比,延遲減少了 21 倍。
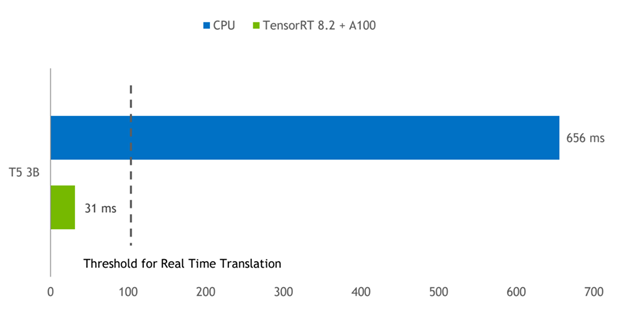
CPU :英特爾白金 8380 , 2 個插槽。
GPU:NVIDIA A100 PCI Express 80GB 。軟件: PyTorch 1.9 , TensorRT 8.2.0 EA 。
任務:“將英語翻譯成德語:這很好。”
結論
在這篇文章中,我們向您介紹了如何將擁抱臉 PyTorch T5 和 GPT-2 模型轉換為優化的 TensorRT 推理引擎。 TensorRT 推理機用作原始 HuggingFace T5 和 GPT-2 PyTorch 模型的替代品,可提供高達 21x CPU 的推理加速比。要為您的模型實現此加速, 從 TensorRT 8.2 開始今天的學習 .
?