NVIDIA CUDA-Q(以前稱為 NVIDIA CUDA Quantum)是一個開源編程模型,用于構建充分利用 CPU、GPU 和 QPU 計算能力的混合量子經典應用程序。目前開發這些應用程序具有挑戰性,需要靈活、易于使用的編碼環境以及強大的量子模擬功能,以高效地評估和提高新算法的性能。
CUDA-Q 是專門為實現這一點而構建的平臺。它能夠在模擬和各種實際 QPU 硬件后端之間輕松切換,這使其成為量子應用開發的長期解決方案。最近的 v0.8 版本進一步提高了 CUDA-Q 模擬性能、開發者體驗和靈活性。
在本文中,我們將討論CUDA-Q v0.8:
- 狀態處理
- 泡利語詞
- 自定義單元運算
- 可視化工具
- NVIDIA Grace Hopper 集成
狀態處理
量子態準備是有用的量子算法的核心組件,但它通常是最復雜、最昂貴的模擬元素之一。在內存中保留相同的狀態并對其進行重復使用,可以在使用不同參數的狀態多次或遵循經典的預處理和后處理步驟時優化模擬。
您現在可以根據提供的狀態向量構建 CUDA-Q 核函數。以下代碼示例通過指定對應于 2 量子位狀態的 4 個條目狀態向量來說明這一點。
c = [.707, 0, 0, .707]@cudaq.kerneldef initial_state(): q = cudaq.qvector(c) |
執行量子電路后,該狀態現在可以保留在 GPU 內存上,并使用優化的內存傳輸工具輕松傳遞給未來的內核。
狀態處理工具對于本質上具有遞歸或迭代性的量子算法尤其有用。
圖 1 是后續量子運算的示例示例,

如果沒有狀態處理,?
在 GPU 顯存中保留先前的狀態,無需執行之前的所有操作,從而顯著提高性能

模擬 Trotter 動力學是一個狀態處理性能提升的很好的量化示例。在 Heisenberg Hamiltonian 模擬的 25 量子位基準測試中(圖 2),保存先前的狀態意味著每個步驟所需的時間大致相同。如果沒有狀態處理,步驟會變得越來越繁瑣。對于 100 個步驟的模擬,狀態處理會使總模擬時間加快 24 倍,令人印象深刻。

Pauli 語詞
Pauli 語詞單量子位 X、Y、Z、I 泡利運算符 (P) 的張量積。表示這些運算符 (
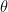
某些算法需要從整個 Pauli 語詞的指數化中衍生出更復雜的運算。
CUDA-Q v0.8 現在包含一個新的pauli_word可以輸入到量子核的類型,并將其轉換為量子電路運算,exp_pauli.以下代碼示例展示了如何使用 Pauli 詞及其相關系數列表應用以下運算:

words = ['XYZ', 'IXX']coefficients = [0.432, 0.324]@cudaq.kerneldef kernel(coefficients: list[float], words: list[cudaq.pauli_word]): q = cudaq.qvector(3) for i in range(len(coefficients)): exp_pauli(coefficients[i], q, words[i]) |
Pauli 語詞及其各自的系數作為列表輸入核,然后轉換為量子電路運算,exp_pauli。上一節中討論的 Trotter 模擬示例將此功能用于 Hamiltonian 模擬。有關更多信息,請參閱trotter_kernel_mode.pyGitHub 上的腳本。
自定義單元運算
在設計更抽象、有 oracles 或沒有確切已知的門集的量子算法時,使用單元運算有時比使用gate更受歡迎。
您現在可以在 CUDA-Q 內核中執行自定義單元操作。以下代碼示例展示了如何將自定義單元操作指定為 NumPy 數組,并將其命名,然后在核函數中使用。自定義標準 X 門指定為包含行的 2 × 2 單元矩陣[0,1]和[1,0].該示例還演示了如何使用一個或多個量子位的受控運算來應用自定義元。
import numpy as npcudaq.register_operation("custom_x", np.array([0, 1, 1, 0]))@cudaq.kerneldef kernel(): qubits = cudaq.qvector(2) h(qubits[0]) custom_x(qubits[0]) custom_x.ctrl(qubits[0], qubits[1])counts = cudaq.sample(kernel)counts.dump() |
可視化工具
可視化工具對于學習量子計算概念、設計算法和協作開展研究非常重要。2024 年 Unitary Hack 活動的參與者為 CUDA-Q 提供了增強的量子電路和 Bloch 球體可視化。
任何內核都可以使用print(cudaq.draw(kernel))命令。默認情況下,ASCII 表示在終端中打印 (圖 4)。

LaTeX 是一種文本準備和排版工具,通常用于準備科學出版物。以下命令打印 LaTeX 字符串:
print(cudaq.draw(‘latex’, kernel)) |
要準備排版量子電路,請將字符串復制到任何 LaTeX 編輯器(例如 Overleaf)中,然后將其導出為 PDF。

CUDA-Q v0.8 現在還使用 QuTip(用于動態模擬的開源 Python 包)來可視化與單量子位狀態對應的 Bloch 球體。圖 6 顯示了一個或多個 Bloch 球體的可視化詳細示例。有關更多信息,請參閱 Qubit Visualization。

NVIDIA Grace Hopper 集成
現在,您可以使用 CUDA-Q 充分利用 NVIDIA GH200 超級芯片的全部性能,進一步突破量子模擬的極限。大內存帶寬可顯著加快量子系統的模擬速度,而在 GH200 超級芯片上進行模擬只需之前所需節點數量的四分之一。這對于通常受到內存限制的量子模擬尤為重要,因為它們通常受到內存帶寬的限制。
CUDA-Q 入門
CUDA-Q 的持續改進為您提供了一個更高性能的平臺,用于構建量子加速的超級計算應用程序。這是一個更高性能的模擬平臺,基于 CUDA-Q 構建的應用程序也可以部署在未來實際量子計算所需的混合 CPU、GPU 和 QPU 環境中。
有關更多信息,請參閱以下資源:
- CUDA-Q 快速入門指南:快速設置環境。
- CUDA-Q 基礎知識:編寫首個 CUDA-Q 應用程序。
- CUDA-Q 示例和 CUDA-Q 教程:為您自己的量子應用程序開發獲取靈感。
如需提供反饋和建議,請參閱/NVIDIA/cuda-quantumGitHub 庫。
?