
隨著 物理 AI 的興起,視頻內容生成呈指數級增長。一輛配備攝像頭的自動駕駛汽車每天可生成超過 1 TB 的視頻,而機器人驅動的制造廠每天可生成 1 PB 的數據。
要利用這些數據來訓練和微調 世界基礎模型 (WFMs) ,您必須首先高效地處理這些數據。
傳統的固定容量批量處理流水線難以應對這種規模,通常未充分利用 GPU,并且無法匹配所需的吞吐量。這些效率低下的情況減緩了 AI 模型的開發,并增加了成本。
為了應對這一挑戰, NVIDIA NeMo Curator 團隊 開發了一個靈活的 GPU 加速流式傳輸管道,用于大規模視頻管護,現在可在 NVIDIA DGX Cloud 上使用 。在本文中,我們將探討在管道中進行的優化,包括 自動擴展和負載均衡技術,以確保在充分利用可用硬件的同時優化各管道階段的吞吐量。
結果如何?更高的吞吐量、更低的總體擁有成本(TCO)和加速的 AI 訓練周期,從而加快最終用戶的成果。
通過自動擴展實現負載均衡
傳統的數據處理通常依賴于 批處理 ,即一次累積大量數據來處理,一次經歷一個階段。

這帶來了兩個主要問題:
- 效率:很難有效利用異構資源。當批處理工作在 CPU 密集型階段時,GPU 資源將被閑置,反之亦然。
- 延遲:在處理階段之間,存儲中間數據產品以及從集群存儲加載中間數據產品的需求會導致嚴重的延遲。
相比之下,流處理會直接在各個階段之間輸送中間數據產品,并在前幾個階段完成后立即開始對單個數據進行下一階段處理。
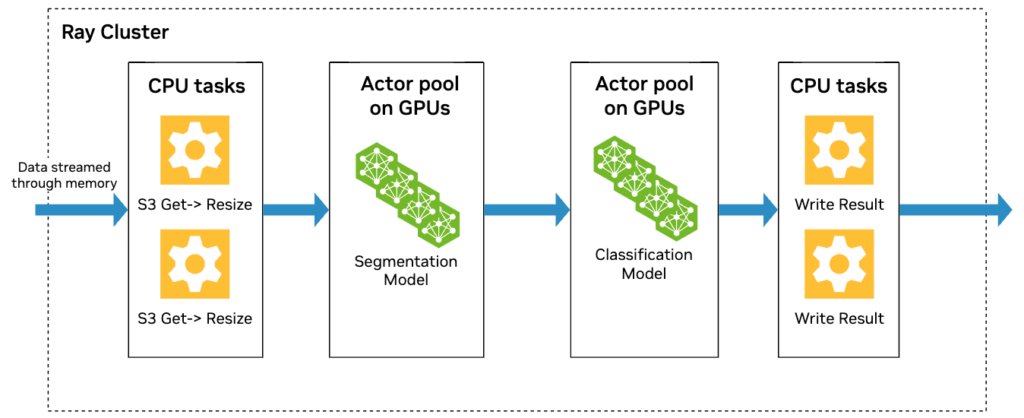
這里的挑戰是需要平衡階段之間的吞吐量,以及希望區分 CPU 主要和 GPU 主要工作負載。
平衡吞吐量
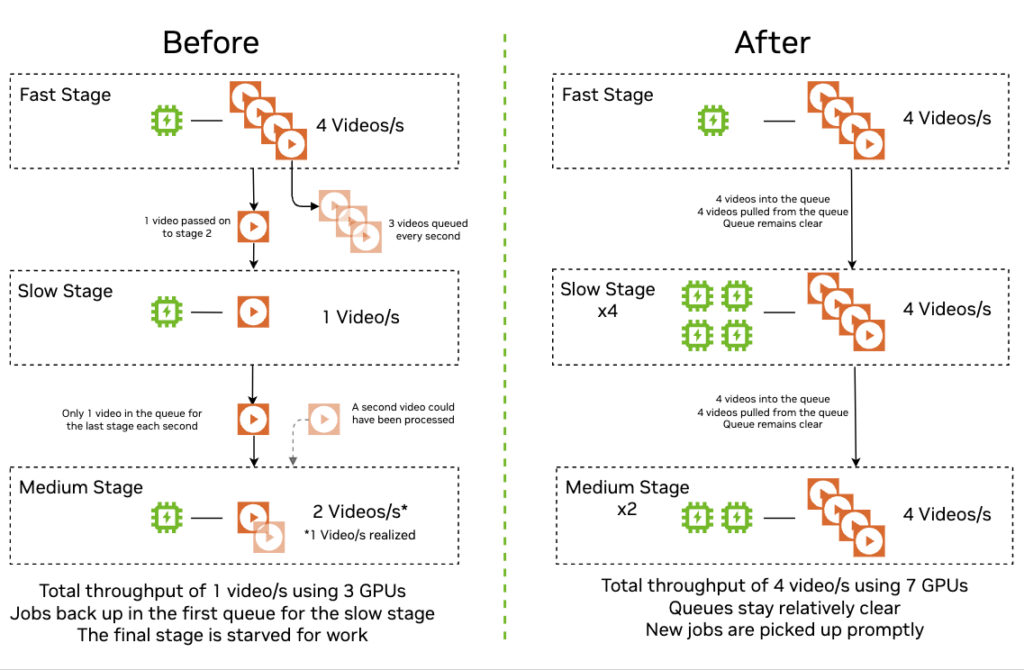
在最簡單的情況下,如果您有兩個階段,其中一個階段的運行速度是下一個階段的兩倍,那么慢階段就像是一個瓶頸,并且管道的整體吞吐量和性能僅限于慢階段。您還可能面臨內存中構建中間工作產品的風險,這需要耗費昂貴的趕超時間,因為計算資源可能處于空閑狀態。在這種情況下,您可以通過以數據并行方式運行兩倍數量的慢速階段副本來解決此問題。
從視覺上看,具有異構吞吐量且支持或不支持自動擴展和負載均衡的多階段視頻處理流水線可能具有顯著的性能和硬件使用差異:
區分 CPU 主要工作負載和 GPU 主要工作負載
另一個關鍵見解是,需要將視頻下載或剪輯轉碼等 CPU 主導任務從生成嵌入或運行 AI 分類器等 GPU 主導任務中分離出來。
思考此問題的一種實用方法是將每個 pipeline 階段想象成二維資源空間中的一個向量,其中一個軸代表 CPU 需求,另一個軸代表 GPU 需求。如果您將所有繁重的工作組合到一個需要(例如)70% CPU 和 30% GPU 的階段,則只能向上或向下擴展相同的比例,只需將該使用向量乘以不同的數量即可。當集群資源與該比率不匹配時,這通常會導致資源未得到充分利用。
相比之下,如果將任務劃分為不同的 CPU 主導階段和 GPU 主導階段,則要處理的向量會更多。這可讓您混合、匹配和重疊多個向量,以更緊密地與基礎設施的實際 CPU 和 GPU 容量保持一致。因此,您可以同時使用 CPU 和 GPU 資源,從而避免一種資源閑置而另一種資源過載的情況。
架構和實現詳情
我們的整個工作流將視頻管護任務劃分為 基于 Ray 構建的 幾個階段:

視頻管護流程涉及多個階段 (圖 4) ,首先是提取原始視頻文件并將其拆分成多個片段 (視頻解碼和拆分) 、將片段轉碼為一致的格式、應用質量過濾器生成元數據、在標注階段生成文本描述,最后是計算嵌入——包括文本描述和視頻內容的嵌入。
對于每個階段,主編排線程管理一個 Ray 行為者池,每個行為者都是該階段的工作實例。多個 actor 可以并行處理不同的輸入視頻,因此階段的吞吐量會隨著 actor 池的大小呈線性擴展。
編排線程還管理每個階段的輸入隊列和輸出隊列。當編排線程將已處理的 pipeline 負載 (即視頻及其元數據) 從一個階段移至下一個階段時,它可以持續測量每個階段的整體吞吐量。
編排線程根據相對吞吐量,以相應的 3 分鐘間隔擴展每個階段的演員池大小,因此較慢的階段有更多的演員。然后,可以對純 CPU 階段進行過度配置,這樣即使在管道中出現波動時,GPU 階段也會保持忙碌狀態。
值得一提的是,主編排線程不會在各個階段之間移動實際數據。它是對象引用,可理解為指向全局 Ray 對象存儲中實際數據的指針,該引用正從階段 N 的輸出隊列移動到階段 N+1 的輸入隊列。因此,編排線程的負載較低。
結果和影響
在比較批量執行與流數據流水線時,您可以使用流數據實現更優化的系統資源使用(圖 5)。

在這種情況下,流式傳輸 pipeline 需要約 195 秒來處理每個 GPU 一個小時的視頻,而批量處理 pipeline 需要約 352 秒來執行同樣的操作:結果是速度提高了約 1.8 倍。
后續步驟
我們在自動擴展和負載均衡方面的努力只是性能優化工作的一部分,該工作使我們迄今為止的性能比基準提高了 89 倍,從而使工作流能夠在一天內在 2k 個 H100 GPUs 上處理約 100 萬小時的 720p 視頻數據。

* 在 2K CPU 和 128 個 DGX 節點上與 ISO 功耗相比的性能。
通過跟蹤執行期間 NeMo Curator 工作流 GPU 階段的工作者利用率,可以進一步證明 GPU 資源的高效利用。
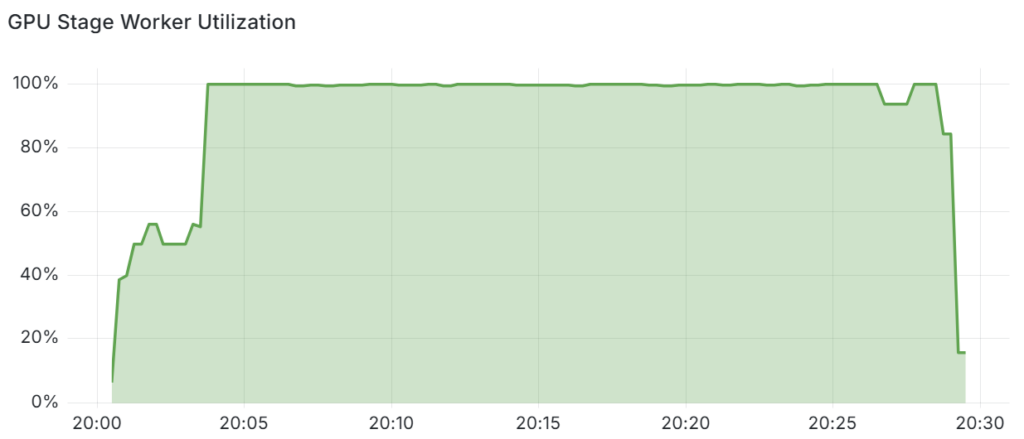
圖 7 顯示,在初始預熱期結束后,自動縮放器可以重新排列資源,使 GPU 階段工作人員在超過 99.5% 的時間內保持忙碌狀態。
我們在四個節點上使用 32 個 GPU 完成了這一實驗。如果您使用更少的 GPU 運行,則 GPU 工作節點的使用量會更低,因為自動擴展程序的 GPU 分配粒度較粗。如果您使用更多 GPU 運行,GPU 工作進程的使用率將更接近 100%。
要通過示例進行解釋,假設 GPU 階段 X 比其他 GPU 階段 Y 快 20 倍:
- 在當前的 32-GPU 實驗中,我們為 X 階段分配了兩個 GPU,為 Y 階段分配了 30 個 GPU。
- 在只有 8 個 GPU 的情況下,我們仍需為 X 階段分配 1 個 GPU,為 Y 階段分配 7 個 GPU,從而導致 X 階段的 GPU 更頻繁地閑置。
- 借助 64 個 GPU,我們在 X 階段使用了 3 個 GPU,在 Y 階段使用了 61 個 GPU,實現了近乎完美的分解。GPU 階段工作人員的總體利用率幾乎達到 100%。
這正是我們在一項作業中增加 GPU 數量時觀察到超線性吞吐量可擴展性的原因。
申請搶先體驗
我們一直積極與各種早期訪問賬戶合作伙伴合作,為視頻數據管護實現出色的 TCO,為物理 AI 和其他領域解鎖新一代多模態模型:
- Blackforest Labs
- Canva
- Deluxe Media
- Getty Images
- Linker Vision
- Milestone Systems
- Nexar
- Twelvelabs
- 優步
您可以通過在 NVIDIA DGX Cloud 上搶先體驗 NeMo Video Curator,無需自己的計算基礎架構即可開始使用。將您對視頻數據管護和模型微調的興趣提交至 NVIDIA NeMo Curator 搶先體驗計劃,并在提交興趣時選擇“托管服務”。
NeMo Video Curator 也可以通過早期訪問作為可下載的 SDK,適合在您自己的基礎設施上運行,也可以通過早期訪問計劃獲得。
?
?






