
為了實現光線跟蹤的高效率,您必須構建一個在每個階段都能很好地縮放的管道。這從網格實例選擇及其數據處理開始,以優化跟蹤和著色您遇到的每個命中。
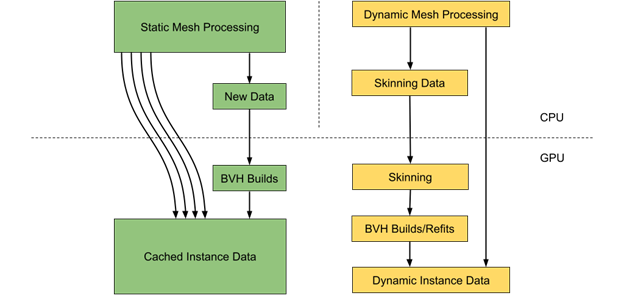
實例數據生成
在普通場景中,靜態對象可能比動態對象多得多。然而,每個動態對象的處理可能需要更多的時間,因為它需要更新頂點數據和相應的 BVH 結構。
在 CPU 上并行執行靜態和動態對象數據處理可能是一個好主意。這通常涉及實例數據提取以及所需的加速結構的構建和更新。
靜態網格數據可以高效地緩存在 GPU 上,包括每個實例的轉換矩陣,以避免額外的數據處理和內存傳輸。僅每個實例就需要 64 字節的內存。使用直接映射的視頻存儲器( BAR1 )也是執行數據上傳到 GPU 的良好策略。
動態對象選擇
某些光線跟蹤效果(如反射或陰影)需要支持非平截頭體對象以提高渲染精度。在許多情況下,這需要將相機周圍的所有對象都包含在一定半徑內。
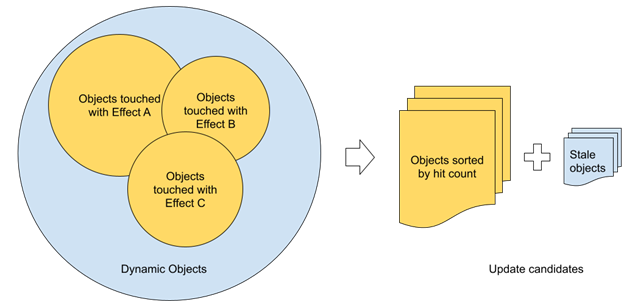
即使對于那些位于視錐體中的對象,對每個幀執行所需的更新也可能不可行。這迫使您為動態對象制定某種形式的優先級,以選擇每幀要處理的對象的子集。
例如,對于需要更新的每個對象,可以嘗試根據邊界球體定義的立體角和到攝影機的距離來定義優先級。為了確保所有對象都經過一段時間的處理,還應考慮自上次更新以來的幀數。
雖然立體角聽起來對優先級定義來說是合理的,但它可能不會導致為更新選擇一組最佳對象。在大多數情況下,這是因為沒有考慮可見性項。對于光線跟蹤,可以直接根據照射每個對象的光線數來估計可見性。對象更新優先級可以直接從中導出。
與動態網格的循環更新相比,這種方法可以在復雜場景中更好地工作,因為它將更新預算本地分配給網格。這是光線跟蹤的最大區別。
使用多個光線跟蹤效果時,可以計算每個效果的所有光線,并為每個對象使用一個值。從技術上講,如果需要,可以使用著色器原子增量來計算每幀上的所有光線。實際上,如果此時性能非常關鍵,在屏幕空間中使用稀疏采樣可以減少潛在沖突的數量。
每個對象都會分配一個唯一的標識符,該標識符可用作緩沖區中的偏移量,以存儲每幀每個對象的光線計數。此緩沖區使用一組相應的 CPU 可見緩沖區進行數據讀回。回讀調用可以在最后一個光線跟蹤效果完成后立即發出,并且數據應該可以在下一幀中使用。
此管道至少引入了一幀延遲,由于連續幀之間的高數據相關性,這不是問題。對于需要最高優先級立即更新的新可見對象,應采取特殊處理。
一些復雜對象可能由多個網格組成,這些網格可能會以不同的頻率進行更新。在某些情況下,由于遮擋而不可見的特寫部分可能會在沒有應用所需更新的情況下突然導致視覺偽影。為了減輕這種情況,可以將光線對象相交驅動的可見性與其他度量相結合,以確保其余網格的延遲更新。
批量頂點數據處理
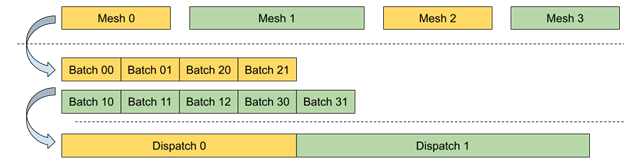
動態網格頂點數據處理需要高度并行性,單個調用之間的狀態變化數量最少,以在 CPU 和 GPU 側獲得更好的性能。這可以使用無綁定資源模型部分實現,其中所有所需資源都可以直接從 GPU 上的著色器代碼獲得,而無需顯式的 CPU 端綁定。
對 GPU 占用率低的潛在任務的另一個優化是將整個工作負載分解為可以并行高效處理的統一批次。每個批次都包含處理一系列頂點和應用變換所需的所有屬性。這樣,可以使用單個Dispatch調用處理共享同一著色器的多個動態網格。
著色器表數據和更新
著色器表包含一組著色器記錄,這些記錄由著色器標識符和一組可選屬性組成。這些屬性與通過本地根簽名訪問的資源綁定和著色的每個幾何部分相關聯。
僅著色器標識符就需要 32 字節的存儲空間。在許多情況下,唯一記錄的數量遠遠少于 TLAS 中的幾何結構,并且數據可以直接在 GPU 上高效地并行填充。
CPU 僅跟蹤幾何圖形和相應材料標識符的列表。頂點緩沖區訪問和材質屬性的所有數據都可以永久存儲在視頻存儲器中,每幀上新創建或更新的網格都會進行增量更新。
考慮壓縮所有記錄以節省內存,并根據幾何體的最大數量而不是實例計數乘以每個實例的最大幾何體來分配著色器表存儲。
如果材質數據不包含在記錄中,并且可以通過實例描述符中的 InstanceID 訪問,則記錄總數可以等于僅表示幾何體部分的唯一底層加速結構的數量。
對于具有幾何體和材質數據的特定排列的一般情況,請考慮在著色器記錄中直接打包額外的每網格屬性,以避免在執行與命中組關聯的著色器時出現額外的內存間接尋址。

每個網格(實例)具有固定幾何體的方法可以簡化內存分配和數據重用,但所需的內存總量高度取決于每個網格的最大幾何體數量。
優化 TLAS 旋轉
如果 TLAS 實例的局部邊界框是軸對齊的,則其跟蹤效率會更高。您無法控制單個實例轉換,但可以為所有實例提供全局轉換,以縮短跟蹤時間。
在運行時,您可以分析特寫實例轉換,并根據它們的相對旋轉將它們分類到多個容器中。為了進一步簡化,只考慮繞垂直軸的旋轉。分類后,可以使用最小化所有實例的相對旋轉角度的容器。
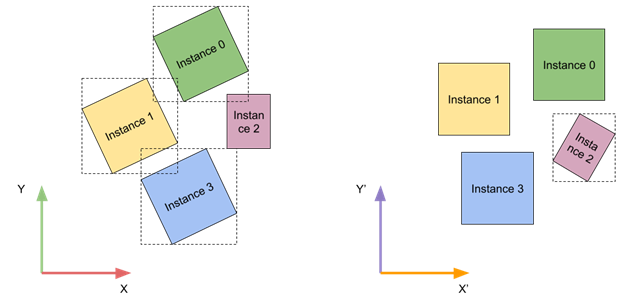
這種方法可能不適用于每種類型的內容。一個很好的例子是城市環境中有統一的城市街區方向。現實世界中的一個例子是紐約市的曼哈頓區,它的街道網格與日落方向對齊。
頂點數據訪問
在光柵化和光線跟蹤管道之間共享頂點數據通常是一個好主意。在某些情況下,可以嘗試僅為光線跟蹤使用優化的布局。可以在光線命中時直接計算位置,紋理坐標可能是任何命中著色器執行過程中唯一需要的屬性。
其他屬性可以以較低的精度存儲,甚至可以按基元定義,這不需要通過索引緩沖區進行額外的間接尋址。
Alpha 測試幾何體
具有頭發和毛發等 alpha 測試的高多邊形幾何體對于直接跟蹤來說可能具有挑戰性。在許多情況下,它可能工作得很好,但有時應該采取額外的措施,以確保性能開銷得到控制。
降低跟蹤成本的一種方法是從預跟蹤開始,即跟蹤屏幕空間中每個像素的局部鄰域,類似于屏幕空間陰影或環境遮擋技術。您不必對屏幕上的每個像素執行此步驟,以確保沒有額外的開銷。為此,可以使用 G 緩沖區曲面中存儲的其他數據來標記屬于頭發或毛發的像素。
粗糙表面上的漫反射全局照明或反射可能不需要精確的反照率或阿爾法測試結果。可以存儲每個基本體的平均材質值。這樣,可以通過在 any-hit 著色器執行期間隨機評估不透明度來獲得良好的結果,而無需額外的逐頂點屬性提取和插值或紋理采樣。
如果仍然需要精確的 alpha 測試,那么最好創建一個簡化的、通用的任意命中著色器,并在可能的情況下使用它。在許多情況下,使用一組紋理坐標和紋理索引進行采樣就足夠了。
屏幕空間數據采樣
有時在拍攝光線時,您可能會在屏幕上看到一個原始的相交點。這使您有機會在重新投影后使用前一幀的照明數據,并提高輸出的性能和質量。它可以很好地用于漫反射照明傳播,因為光線方向對照明沒有影響。
在著色器中執行任何其他代碼之前,可以檢查屏幕空間數據采樣。可以跳過任何進一步的照明代碼,以提高性能。
或者,您可以僅從 G 緩沖區中采樣材質數據,然后仍然運行著色管道。對于較薄的物體,應采取一定的精度,這可能需要在重新投影后對其正常情況進行額外檢查。確保從右側對曲面進行采樣。此外,與主視圖相比,當光線跟蹤效果使用簡化的材質或著色時,該方法值得嘗試改善照明質量。
總結
使用這些提供的指南作為構建高性能光線跟蹤渲染管道的基礎,重點關注 GPU 和 CPU 性能。與 API 相關的常見最佳實踐仍然有效,也應予以考慮。其他步驟可以包括添加頂級功能,例如對 micro-meshes 和 Shader Execution Reo r dering 的支持。
?
?






