今天的機器學習( ML )解決方案很復雜,很少只使用一個模型。有效地訓練模型需要大量多樣的數據集,這些數據集可能需要多個模型才能有效地進行預測。此外,在生產中部署復雜的多模型 ML 解決方案可能是一項具有挑戰性的任務。一個常見的例子是,不同框架的兼容性問題可能導致見解延遲。
一個易于服務于深度神經網絡和基于樹的模型的各種組合并且與框架無關的解決方案將有助于簡化 ML 解決方案的部署,并在 ML 解決方案采用多層時對其進行擴展。
本文將討論如何利用 NVIDIA 軟件的多功能性處理不同類型的模型,并將它們集成到應用程序中。我將演示 NVIDIA RAPIDS 如何支持大型數據集的數據準備和 ML 訓練,以及如何NVIDIA Triton Inference Server無縫服務于兩個深度神經網絡PyTorch和基于樹的模XGBoost,用于預測信用違約。
以美國運通信用卡違約預測競賽為例,我解釋了如何在 GPU 或 CPU 上部署多模型解決方案,GPU 部署可以顯著加快推理時間。這個解決方案在Kaggle 美國運通信用卡違約預測競賽中的 4874 支隊伍中排名前十。查看解決方案。
未來信用違約預測
信用違約預測是管理消費貸款業務風險的核心。美國運通,世界上最大的支付卡發行商,提供了一個工業規模的數據集,其中包含時間序列行為數據和匿名客戶檔案信息。該數據集高度代表了真實世界的場景:它很大,包含數值列和分類列,并且涉及一個時間序列問題。
成功解決這個業務問題的關鍵是揭示數據中的時間模式。
為什么要關注樹和神經網絡?
基于樹的模型和深度神經網絡被廣泛認為是 ML 從業者最受歡迎的選擇。
基于樹的模型,如 XGBoost,主要用于表格數據集,因為它們可以處理嘈雜和冗余的特征,使得解釋和理解預測背后的邏輯變得容易。
另一方面,深度神經網絡擅長學習數據中的長期時間依賴性和序列模式。它們還可以從原始數據中自動提取特征。最近,深度神經網絡被廣泛應用生成高質量的新數據,利用它們從現有數據中學習分布的能力。
現在,我將描述我的團隊如何在我們的 American Express 默認故障預測解決方案中使用此技術。
數據準備和部署的基本工具
當您準備一個復雜的 ML 模型時,有許多步驟可以準備、訓練和部署一個有效的模型。 RAPIDS 和 Triton 推理服務器都支持 ML 過程中的關鍵階段。
RAPIDS是一套開源軟件庫和 API,旨在加速 GPU 上的數據科學工作流程。它提供了用于數據預處理、機器學習和可視化的各種工具和庫。在這種情況下,它可以在工作流開始時進行數據預處理和探索性數據分析。
NVIDIA Triton 是一種高性能的多模型推理服務器,支持 GPU 和 CPU,以支持部署。它可以輕松部署來自各種框架的模型,例如TensorFlow,PyTorch和ONNX,詳情請參閱此處。
NVIDIA Triton 支持樹形模型,如 XGBoost、LightGBM等,使用Forest Inference Library 后端。這使得它非常適合我們正在編寫的模型。
問題概述
其目的是利用客戶過去的月度客戶檔案數據預測客戶未來是否會拖欠信用卡余額。二元目標變量,默認或無默認,由客戶是否在對賬單日期后 120 天內償還其未償信用卡余額決定。
圖 1 顯示了問題和數據集的概述,突出了信用違約預測的關鍵方面和數據集特征。測試數據集龐大,有 900K 個客戶, 1100 萬行, 191 列,包括數字和分類特征。
目標是創建一個模型,該模型可以基于數據集中的其他變量和要管理的任務關鍵時間值來預測分類二元變量。在建模之前,這個大型數據集需要進行重要的特征工程,使其成為 RAPIDS cuDF 數據準備的理想候選者。數據集的大小對實時推理提出了進一步的挑戰,高性能 NVIDIA Triton 服務器解決了這一問題。

方法
我們將模型開發過程分解為一系列步驟:
- 數據集準備
- 功能工程
- 數據集探索
- 自回歸遞歸神經網絡( RNN )模
- 數據集性能
數據集準備
給定的美國運通數據是一個時間序列,由按客戶 ID 和時間戳排序的客戶的多個檔案組成:
- 數據集中的每一行代表一個客戶 1 個月的配置文件。
- 每個客戶在數據中有 13 個連續的行,這些行表示他們在連續 13 個月內的配置文件。
- 數據中有 214 列。
- 列是匿名的,除了
customer_id和month,并分為以下一般類別:拖欠、支出、付款、余額、風險
表 1 總結了每個類別中的列數。除了其類別之外,沒有關于每一列的含義的信息。這些匿名列大多是浮點數。
| ? | 客戶 id | 月 | 犯罪 | 花費 | 付款 | 均衡 | 危險 |
| #共列 | 1 | 1 | 106 | 25 | 10 | 43 | 28 |
對于訓練數據,無論是否默認,基本事實都存儲在另一個表格數據中,其中每個客戶對應一行。共有兩列:customer_id和default.
與 RAPIDS cuDF 的特征工程
該項目始于特征工程,為模型準備時間序列數據集。眾所周知,時間序列數據需要大量處理,而對于基于 CPU 的數據科學解決方案來說,這變得更加困難。為了有效地運行這一階段的數據準備,我們利用 GPU 的力量RAPIDS cuDF。
我們將每個客戶檔案的月數減少到數據集中的最后一個月,重點是將數據集精簡為最重要的數據點。上個月在預測未來默認事件方面具有最高的相關性,并將行數減少到 900K 。這是由drop_duplicates(keep=’last’)在 cuDF 中。
RAPIDS cuDF 可以通過為每個創建差異和聚合特征來進一步幫助加速customer_id價值雖然 RAPIDS cuDF 用于在前面的筆記本中設計額外的功能,但我忽略了這些功能,以保持這個單一的 GPU 演練的簡單性。

探索數據集
每個客戶檔案的功能都是在第 13 個月測量的,而默認檢查的日期是第 31 個月。考慮到違約客戶的數據集中有 17 個月的時間間隔,該團隊為缺失的月份(第 14 個月至第 30 個月)生成了新的客戶檔案,以提高模型的預測率。該團隊在直觀地探索數據后受到啟發,實現了自回歸 RNN 技術。
想了解更多關于識別自回歸 RNN 技術的信息,請參閱Amex EDA 數值特征隨時間的演變筆記本。
在探索數據集時,團隊將數據可視化為圖表。圖 3 繪制了列的子集隨時間的變化趨勢。 x 軸表示月份, y 軸表示列名。
例如,左上角的子圖顯示了拖欠類別的第 53 列 D _ 53 列在幾個月內的變化情況。紅色虛線是正樣本的 D _ 53 列的平均值,其中 Default = True ,綠色實線分別是負樣本的平均值。
對于大多數列,都有明顯的時間模式。可以訓練模型來推斷和預測列的未來值。使用此模型,為數據集生成附加值有助于提高模型的可預測性。

當您計劃增強數據集時,另一個關鍵是每列的模式可能不同。線性趨勢、非線性趨勢、擺動和更多的變化都是可以觀察到的。數據生成模型必須是通用的、靈活的,可以學習和概括所有這些不同的模式。
用自回歸 RNN 模型生成新的簡檔
基于這些數據特征,我們的團隊提出了一個自回歸 RNN 模型來同時學習所有這些模式。自回歸的意味著當前時間步長的輸出是下一個時間步長的輸入。圖 4 顯示了自回歸生成的工作原理。

RNN 模型的輸入是當前月份的客戶檔案,包括所有 214 列。 RNN 模型的輸出是下個月的預測客戶概況。該方法中使用的自回歸 RNN 是以自我監督的方式進行訓練的,這意味著它只使用客戶檔案進行訓練,不需要“默認與否”目標列。
這種增強數據集的自我監督訓練使您能夠使用大量未標記的數據——這在現實世界的應用中是一個顯著的優勢,因為標記的數據通常很難獲得,而且成本很高。
新數據集的性能
RNN 可以準確地預測未來的概況。均方根誤差用于地面實況剖面和預測剖面之間。將 RNN 與簡單的基線進行比較,并假設未來的剖面與上次觀測到的剖面相同。
| ? | 自回歸 RNN | 上次觀察到的剖面基線 |
| 所有 214 列的 RMSE | 0 . 019 | 0 . 03 |
在表 2 中, RNN 將 RMSE 從 0 . 03 降低到 0 . 019 (提高了 33% )。這是對原始數據集的顯著增強。
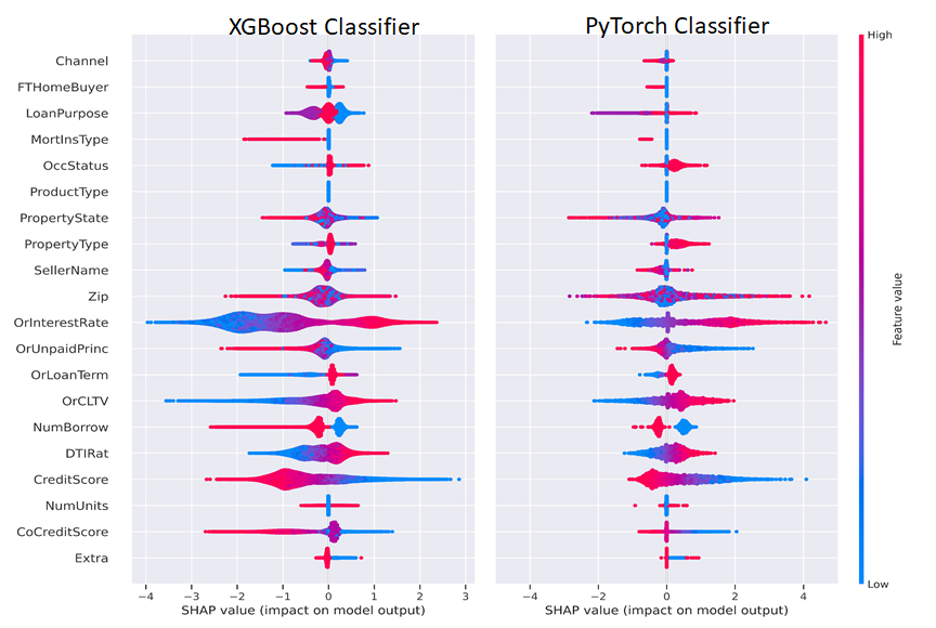
圖 2 顯示,生成用于訓練的數據集的最后一步是將最后的概要文件和生成的概要文件組合成一個矩陣。使用 RAPIDS cuDF 中的聯接函數執行此操作,并將它們提供給下游 XGBoost 分類器以預測默認值。生成的配置文件大大提高了模型的性能。
表 3 顯示,通過組合最新的配置文件和生成的未來配置文件,XGBoost 分類器可以更準確地預測未來默認值 0.003。這是對默認檢測問題的顯著改進,可能會使解決方案在 美國運通信用卡默認預測競賽 中取得更好的成績!
| ? | xgb 在上次配置文件上進行了訓練 | xgb 在最后的配置文件和 自回歸 RNN 生成的簡檔 |
| American Express metric用于預測違約 | 0 . 7797 | 0 . 7830 |
將模型部署到 Triton 推理服務器
圖 5 顯示,在推理過程中, NVIDIA Triton 推理服務器能夠在 GPU 或 GPU 上托管 PyTorch 中實現的自回歸 RNN 模型和 XGBoost 中實現的基于樹的模型。
首先,將預訓練的 PyTorch RNN 模型和 XGBoost 模型保存在具有正確文件夾層次結構的單獨文件夾中。接下來,為每個模型編寫配置文件。 PyTorch 模型處理這批輸入數據以生成未來的簡檔,然后將級聯的簡檔輸入 XGBoost 模型以進行進一步推斷。
在不到 6 秒的時間里,已經推斷出 115K 個客戶檔案rnn-xgb管道上的單個 GPU 。

即使有這種復雜的模型管道,包括 13 個時間步長的自回歸 RNN 和用于分類的 XGBoost ,推理時間也非常快。在 1130 萬美國運通客戶檔案上運行 NVIDIA Triton 推理服務器管道,在單個 NVIDIA V100 GPU 上只需 45 秒。
總結
本文中提出的信貸違約預測解決方案成功地利用了深度神經網絡和樹模型的力量,通過補充數據來提高預測的準確性。
RAPIDS cuDF 使時間序列數據的數據處理更容易、更快。模型的部署與 Triton 推理服務器無縫銜接,該服務器可以在 CPU 或 GPU 上托管深度神經網絡和樹模型。這使它成為實時推理的強大工具。
該演示還突出了 GPU 和 Triton 推理服務器在信用違約預測中應用高性能計算能力的潛力,為金融服務領域的進一步探索和改進開辟了途徑。
本文使用 notebooks:
?