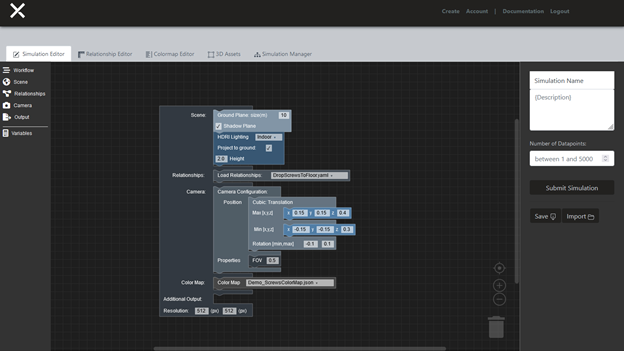
漫長而繁瑣的數據采購工作一直在阻礙人工智能的創新,特別是在計算機視覺領域,因為計算機視覺依賴于標記的圖像和視頻進行訓練。但是現在你可以通過使用人工智能快速生成合成數據來啟動你的機器學習過程。
有了 AI . revire 綜合數據平臺 ,你可以在找到和標注正確的真實照片所需時間的一小部分時間內創建你需要的精確訓練數據。在 AI . Revire 的照片級真實感 3D 環境中,您可以為所有可能的場景生成數據,包括難以到達的地方、不尋常的環境條件以及罕見或獨特的事件。
訓練數據生成 包括標簽。選擇所需的類型,例如二維或三維邊界框、深度遮罩等。測試模型后,可以返回到平臺以快速生成其他數據以提高準確性。以快速、反復的循環進行測試和重復。
我們想在 NVIDIA 遷移學習工具包 3 . 0 中測試人工智能的性能。最初,我們著手復制研究論文 RarePlanes :合成數據飛行 中的結果,該論文使用合成圖像創建目標檢測模型。我們在 TLT 中發現了新的工具,使得創建更輕量級的模型成為可能,這些模型與原始論文中的模型一樣精確,但速度要快得多。
在這篇文章中,我們將向您展示如何使用 TLT 量化感知訓練和模型修剪來實現這一點,以及如何自己復制結果。我們將向您展示如何創建飛機探測器,但您應該能夠針對自己的各種衛星探測場景對模型進行微調。

訪問衛星探測模型
要復制這些結果,您可以克隆 GitHub 存儲庫,并使用附帶的 Jupyter 筆記本。
克隆以下 repo :
git clone git@github.com:aireveries/rareplanes-tlt.git ~/Code/rareplanes-tlt
創建 conda 環境:
conda create -f env.yaml
激活模型:
source activate rareplanes-tlt
啟動 Jupyter :
jupyter notebook
學習目標
- 使用 AI . revire 平臺生成合成數據并與 NVIDIA TLT 一起使用。
- 使用合成數據訓練高精度模型。
- 使用 TLT 優化推理模型。
先決條件
我們使用 python3 . 8 . 8 測試了代碼,使用 anaconda4 . 9 . 2 管理依賴項和虛擬環境。這些代碼可能適用于不同版本的 Python 和其他虛擬環境解決方案,但我們尚未測試這些配置。我們使用了 ubuntu18 . 04 . 5lts 和 NVIDIA 驅動程序 460 . 32 . 03 和 CUDA 版本 11 . 2 。 TLT 需要驅動程序 455 . xx 或更高版本。
- 設置 NVIDIA 容器工具箱/ NVIDIA -docker2 。有關更多信息,請參閱 NVIDIA 容器工具包安裝指南 。
- 設置 NGC 以下載 NVIDIA Docker 容器。遵循 TLT 用戶指南 中的步驟 4 和 5 。有關 NGC CLI 工具的更多信息,請參閱 CLI 安裝 。
- 至少有 250 GB 的可用硬盤空間來存儲數據集和模型權重。
下載數據集
有關 RarePlanes 數據集內容的更多信息,請參閱 RarePlanes 公共用戶指南 。
對于本教程,您只需要下載數據的一個子集。下面的代碼示例將在 Jupyter 筆記本 中執行。首先,創建文件夾:
!mkdir -p data/real/tarballs/{train,test}
!mkdir -p data/synthetic
現在使用此函數從 Amazon S3 下載數據集,提取它們,并驗證:
def download(s3_path, out_folder, out_file_count):
??? rel_file_path = Path('data') / Path(s3_path.replace('s3://rareplanes-public/', ''))
??? rel_folder = rel_file_path.parent / out_folder
??? num_files = !ls $rel_folder | wc -l
??? try:
??????? if int(num_files[0]) == out_file_count:
??????????? print(f'{s3_path} already downloaded and extracted')
??????? else:
??????????? raise Exception
??? except:
??????? if not rel_file_path.exists():
??????????? print('Starting download')
??????????? !aws s3 cp $s3_path $rel_file_path;??
??????? else:
??????????? print(f'{s3_path} already downloaded')
??????? print('Extracting...')
??????? !cd {rel_folder.parent}; pv {rel_file_path.name} | tar xz;
??????? print('Removing compressed file.')
??????? !rm $rel_file_path
然后下載數據集:
download('s3://rareplanes-public/real/tarballs/metadata_annotations.tar.gz',
???????? 'metadata_annotations', 9)
download('s3://rareplanes-public/real/tarballs/train/RarePlanes_train_PS-RGB_tiled.tar.gz',
???????? 'PS-RGB_tiled', 11630)
download('s3://rareplanes-public/real/tarballs/test/RarePlanes_test_PS-RGB_tiled.tar.gz',
????????? 'PS-RGB_tiled', 5420)
!aws s3 cp --recursive s3://rareplanes-public/synthetic/ data/synthetic
從 COCO 轉換成 KITTI 格式
TLT 使用 KITTI 格式進行目標檢測模型訓練。 RarePlanes 是 COCO 格式的,因此必須從 Jupyter 筆記本中運行轉換腳本。這將轉換真實列車/測試和合成列車/測試數據集。
%run convert_coco_to_kitti.py
data/kitti 中的每個數據集都應該有一個文件夾,其中包含 KITTI 格式的注釋文本文件和指向原始圖像的符號鏈接。
設置 TLT 安裝
筆記本有一個生成 ~/.tlt_mounts.json 文件的腳本。有關各種設置的詳細信息,請參閱 運行啟動器 。
{
??? "Mounts": [
??????? {
??????????? "source": "/home/patrick.rodriguez/Code/rareplanes-tlt",
??????????? "destination": "/workspace/tlt-experiments"
??????? }
??? ],
??? "Envs": [
??????? {
??????????? "variable": "CUDA_VISIBLE_DEVICES",
??????????? "value": "0"
??????? }
??? ],
??? "DockerOptions": {
??????? "shm_size": "16G",
??????? "ulimits": {
??????????? "memlock": -1,
??????????? "stack": 67108864
??????? },
??????? "user": "1001:1001"
??? }
}
將數據集處理為 TFR 記錄
必須將 KITTI 標簽轉換為 TLT 使用的 TFRecord 格式。筆記本中的 convert_split 函數可幫助您批量轉換所有數據集:
def convert_split(name):
??? !tlt detectnet_v2 dataset_convert --gpu_index 0 \
??????? -d /workspace/tlt-experiments/specs/detectnet_v2_tfrecords_{name}.txt \
??????? -o /workspace/tlt-experiments/data/tfrecords/{name}/{name}
You can then run the conversions:
convert_split('kitti_real_train')
convert_split('kitti_real_test')
convert_split('kitti_synthetic_train')
convert_split('kitti_synthetic_test')
下載 ResNet18 卷積主干
使用 NGC 帳戶和命令行工具,您現在可以下載模型:
下載 ResNet18 卷積主干
使用 NGC 帳戶和命令行工具,您現在可以下載模型:
!ngc registry model download-version nvidia/tlt_pretrained_detectnet_v2:resnet18
模型現在位于以下路徑:
./tlt_pretrained_detectnet_v2_vresnet18/resnet18.hdf5
使用真實數據進行基準測試
以下命令將啟動訓練并將結果記錄到可跟蹤的文件中:
!tlt detectnet_v2 train --key tlt --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_real.txt \ ??? -r /workspace/tlt-experiments/detectnet_v2_outputs/resnet18_real_amp16 \ ??? -n resnet18_real_amp16 \ ??? --use_amp > out_resnet18_real_amp16.log
執行以下命令:
tail -f ./out_resnet18_real_amp16.log
培訓完成后,您可以使用筆記本中定義的函數獲取模型的相關統計信息:
get_model_param_counts('./out_resnet18_real_amp16.log')
best_epoch = get_best_epoch('./out_resnet18_real_amp16.log')
best_epoch
您可以得到如下輸出:
Total params: 11,197,893 Trainable params: 11,188,165 Non-trainable params: 9,728 Best epoch and map50 metric: (79, 94.2296)
要在測試集或其他數據集上重新評估經過訓練的模型,請運行以下操作:
!tlt detectnet_v2 evaluate --gpu_index 0 \
??? -e /workspace/tlt-experiments/specs/detectnet_v2_evaluate_real.txt \
??? -m /workspace/tlt-experiments/{best_checkpoint} \
? ??-k tlt
輸出應該如下所示:
Validation cost: 0.001133 Mean average_precision (in %): 94.2563 ? class name????? average precision (in %) ------------? -------------------------- aircraft???????????????????????? 94.2563 ? Median Inference Time: 0.003877 2021-04-06 05:47:00,323 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:27.031500. 2021-04-06 05:47:02,466 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
用合成數據做實驗
!tlt detectnet_v2 train --key tlt --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_synth.txt \ ??? -r /workspace/tlt-experiments/detectnet_v2_outputs/resnet18_synth_amp16 \ ??? -n resnet18_synth_amp16 \ ??? --use_amp > out_resnet18_synth_amp16.log
您可以通過運行: !cat out_resnet18_synth_amp16.log | grep -i aircraft 來查看每個歷元的結果
輸出示例:
aircraft???????????????????????? 58.1444 aircraft???????????????????????? 65.1423 aircraft???????????????????????? 64.3203 aircraft???????????????????????? 68.1934 aircraft???????????????????????? 71.5754 aircraft???????????????????????? 68.5568
用實際數據對綜合訓練模型進行微調
現在,用 10% 的真實數據來微調最佳性能的合成數據訓練模型。為此,必須首先創建 10% 分割。
%run ./create_train_split.py
convert_split('kitti_real_train_10')
然后使用此函數將模板規范中的檢查點替換為僅合成訓練中性能最佳的模型。
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10.txt', 'r') as f_in:
??? with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_replaced.txt', 'w') as f_out:
??????? out = f_in.read().replace('REPLACE', best_checkpoint)
??????? f_out.write(out)
你現在可以開始 TLT 訓練了。在上一節中,僅對合成數據進行訓練的模型的最佳性能歷元開始微調。
!tlt detectnet_v2 train --key tlt --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_replaced.txt \ ??? -r /workspace/tlt-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_amp16 \ ??? -n resnet18_synth_finetune_10_amp16 \ ??? --use_amp > out_resnet18_synth_finetune_10_amp16.log
訓練完成后,您將看到 91-93%mAP50 之間的最佳 epoch ,這將使您接近僅真實模型的性能,只有 10% 的真實數據。
在筆記本中,有一個命令用于評估測試集上性能最佳的模型檢查點:
!tlt detectnet_v2 evaluate --gpu_index 0 \
??? -e /workspace/tlt-experiments/specs/detectnet_v2_evaluate_real.txt \
??? -m /workspace/tlt-experiments/{best_checkpoint} \
??? -k tlt
您應該看到如下輸出:
2021-04-06 18:05:28,342 [INFO] iva.detectnet_v2.evaluation.evaluation: step 330 / 339, 0.05s/step Matching predictions to ground truth, class 1/1.: 100%|█| 14719/14719 [00:00<00:00, 15814.87it/s] ? Validation cost: 0.001368 Mean average_precision (in %): 91.8094 ? class name????? average precision (in %) ------------? -------------------------- aircraft???????????????????????? 91.8094 ? Median Inference Time: 0.004137 2021-04-06 18:05:30,327 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:30.677440. 2021-04-06 18:05:32,469 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
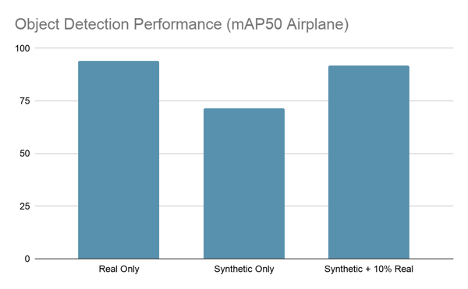
數據增強 正在對人工智能的模型訓練進行微調。遐想的合成數據僅占原始真實數據集的 10% 。如您所見,這種技術生成的模型與僅對真實數據進行訓練的模型一樣精確。這意味著在真實的標記數據上大約節省了 90% 的成本,并且使您不必忍受冗長的標記和 QA 過程。
修剪模型
訓練了一個性能良好的模型之后,現在可以減少權重的數量,以減少文件大小和推理時間。 TLT 包括 易于使用的修剪工具 。
其中一個值得玩味的參數是 -pth ,它設置了神經元修剪的閾值。設置得越高,修剪的參數就越多,但在某一點之后,精度指標可能會降得太低。我們發現 0 . 5 的值對這些實驗有效,但在其他數據集上可能會發現不同的結果。
!mkdir -p detectnet_v2_outputs/pruned
?
!tlt detectnet_v2 prune \
??? -m /workspace/tlt-experiments/{best_checkpoint} \
??? -o /workspace/tlt-experiments/detectnet_v2_outputs/pruned/pruned-model.tlt \
??? -eq union \
??? -pth 0.5 \
??? -k tlt
現在可以計算修剪后的模型:
!tlt detectnet_v2 evaluate --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_evaluate_real.txt \ ??? -m /workspace/tlt-experiments/detectnet_v2_outputs/pruned/pruned-model.tlt \ ??? -k tlt > out_pruned.txt
現在您可以看到還有多少參數:
get_model_param_counts('./out_pruned.txt')
您應該看到如下輸出:
Total params: 3,372,973 Trainable params: 3,366,573 Non-trainable params: 6,400
這是 70% ,比原來的模型,其中有 1120 萬個參數小!當然,刪除這么多參數會降低性能,您可以驗證:
!cat out_pruned.txt | grep -i aircraft ? aircraft???????????????????????? 68.8865
幸運的是,您可以通過重新訓練修剪后的模型來恢復幾乎所有的性能。
再培訓模特
與前面一樣,有一個模板規范來運行此實驗,它只需要您填寫修剪模型的位置:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain.txt', 'r') as f_in:
??? with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_replaced.txt', 'w') as f_out:
??????? out = f_in.read().replace('REPLACE', 'detectnet_v2_outputs/pruned/pruned-model.tlt')
??????? f_out.write(out)
現在可以重新訓練修剪后的模型:
!tlt detectnet_v2 train --key tlt --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_replaced.txt \ ??? -r /workspace/tlt-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_pruned_retrain_amp16 \ ??? -n resnet18_synth_finetune_10_pruned_retrain_amp16 \ ??? --use_amp > out_resnet18_synth_finetune_10_pruned_retrain_amp16.log
在本實驗的運行中,表現最好的 epoch 達到 91 . 925map50 ,與原來的非運行實驗基本相同。
2021-04-06 19:33:39,360 [INFO] iva.detectnet_v2.evaluation.evaluation: step 330 / 339, 0.05s/step Matching predictions to ground truth, class 1/1.: 100%|█| 17403/17403 [00:01<00:00, 15748.62it/s] Validation cost: 0.001442 Mean average_precision (in %): 91.9849 ? class name????? average precision (in %) ------------? -------------------------- aircraft???????????????????????? 91.9849 ? Median Inference Time: 0.003635 2021-04-06 19:33:41,479 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:31.869671. 2021-04-06 19:33:43,607 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
量化模型
這個過程的最后一步是量化修剪后的模型,這樣您就可以使用 TensorRT 獲得更高級別的推理速度。我們提供量化感知培訓( QAT )規范模板:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat.txt', 'r') as f_in:
??? with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt', 'w') as f_out:
??????? out = f_in.read().replace('REPLACE', 'detectnet_v2_outputs/pruned/pruned-model.tlt')
??????? f_out.write(out)
進行 QAT 培訓:
!tlt detectnet_v2 train --key tlt --gpu_index 0 \ ??? -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt \ ??? -r /workspace/tlt-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_pruned_retrain_qat_amp16 \ ??? -n resnet18_synth_finetune_10_pruned_retrain_qat_amp16 \ ??? --use_amp > out_resnet18_synth_finetune_10_pruned_retrain_qat_amp16.log
使用 TLT 導出工具導出為 INT8 量化 TensorRT 格式:
!tlt detectnet_v2 export \
? -m /workspace/tlt-experiments/{best_checkpoint} \
? -o /workspace/tlt-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.etlt \
? -k tlt? \
? --data_type int8 \
? --batch_size 64 \
? --max_batch_size 64\
? --engine_file /workspace/tlt-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.trt.int8 \
? --cal_cache_file /workspace/tlt-experiments/detectnet_v2_outputs/qat/calibration_qat.bin \
? --verbose
此時,您可以使用 TensorRT 評估量化模型:
!tlt detectnet_v2 evaluate -e /workspace/tlt-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt \ ?????????????????????????? -m /workspace/tlt-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.trt.int8 \ ?????????????????????????? -f tensorrt
查看輸出:
2021-04-06 23:08:28,471 [INFO] iva.detectnet_v2.evaluation.tensorrt_evaluator: step 330 / 339, 0.33s/step Matching predictions to ground truth, class 1/1.: 100%|█| 21973/21973 [00:01<00:00, 16161.54it/s] ? Validation cost: 0.549463 Mean average_precision (in %): 91.5516 ? class name????? average precision (in %) ------------? -------------------------- aircraft???????????????????????? 91.5516 ? Median Inference Time: 0.000840 2021-04-06 23:08:33,182 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:02:13.453132. 2021-04-06 23:08:34,768 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
結論
我們對這些結果印象深刻。 AI . reviree 的 綜合數據平臺 只有真實數據集的 10% ,使我們能夠獲得與在完整真實數據集上訓練時相同的性能。這意味著大約節省了 90% 的成本,更不用說在采購上節省的時間了。現在生成所需的合成數據需要幾天,而不是幾個月。
TLT 還使參數計數減少了 25 . 2 倍,文件大小減少了 33 . 6 倍,性能( QPS )提高了 174 . 7 倍,同時保留了 95% 的原始性能。 TLT 的功能對于修剪和量化特別有價值。
轉到 AI.Reverie ,為您的項目下載 綜合訓練數據 ,然后開始 TLT 培訓。