想象一下:你正在網上商店里瀏覽,尋找一雙完美的跑鞋。但是有成千上萬的選擇,你從哪里開始呢?突然,一個“為您推薦”區域吸引了你的眼球。你很感興趣,點擊一下,幾秒鐘內,就會出現一個根據你獨特喜好定制的跑鞋列表。就好像網站了解你的品味、需求和風格。
歡迎來到推薦系統,這里尖端技術結合了數據分析,人工智能(AI),以及改變我們數字體驗的魔力。
這篇文章深入探討了推薦系統的迷人領域,并探討了構建兩階段候選重新排序的建模方法。我提供了如何在代表性不足的語言中克服數據短缺的專業提示,以及如何實現這些最佳實踐的技術演練。
構建兩階段候選人重新評級概述
對于每個用戶,推薦系統必須從可能數百萬個項目中預測出該用戶感興趣的幾個項目。這是一項艱巨的任務。一種強大的建模方法稱為兩階段候選重新排序。
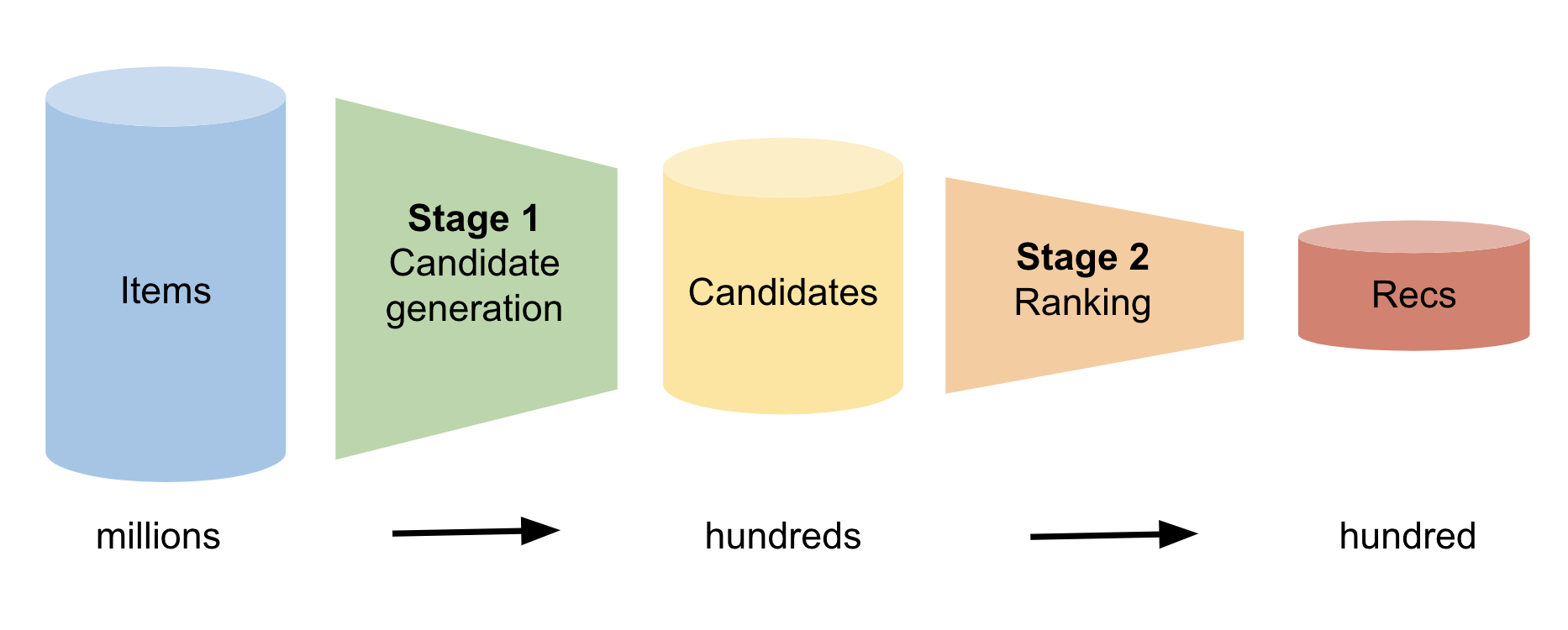
圖 1 顯示了這兩個階段。在第一階段,模型識別用戶可能感興趣的數百個候選項目。在第二階段,模型將該列表從最有可能到最不可能進行排序。最后,該模型向用戶建議最有可能的項目。
第 1 階段:候選人生成
生成候選者的方法有很多,包括統計方法和深度學習方法。生成候選者的一種統計技術是構建共訪問矩陣。您遍歷所有用戶歷史會話,并維護每對項目在用戶會話中共存的頻率的累積計數。因此,您就知道了與每個項目經常配對的前 100 個項目。
現在,給定一個特定的用戶,您可以通過迭代其用戶歷史記錄并組合與其歷史記錄中每個項目相關聯的所有前 100 個列表來生成候選項目。許多項目出現多次。候選者是這個由數百個項目組成的串聯列表中最常見的項目。
第二階段:排名
使用階段 1 中的候選者,構建一個表格數據幀(圖 2),用于訓練重新排序器。想象一下,第 1 階段為每個用戶生成 100 個候選者。然后,對于每個經過訓練的數據用戶,您的表格數據框架有 100 行。一列是用戶,另一列是候選項。為目標添加第三列。具有與該行用戶正確匹配的候選項的每一行在目標列中都有一個 1,否則為 0。
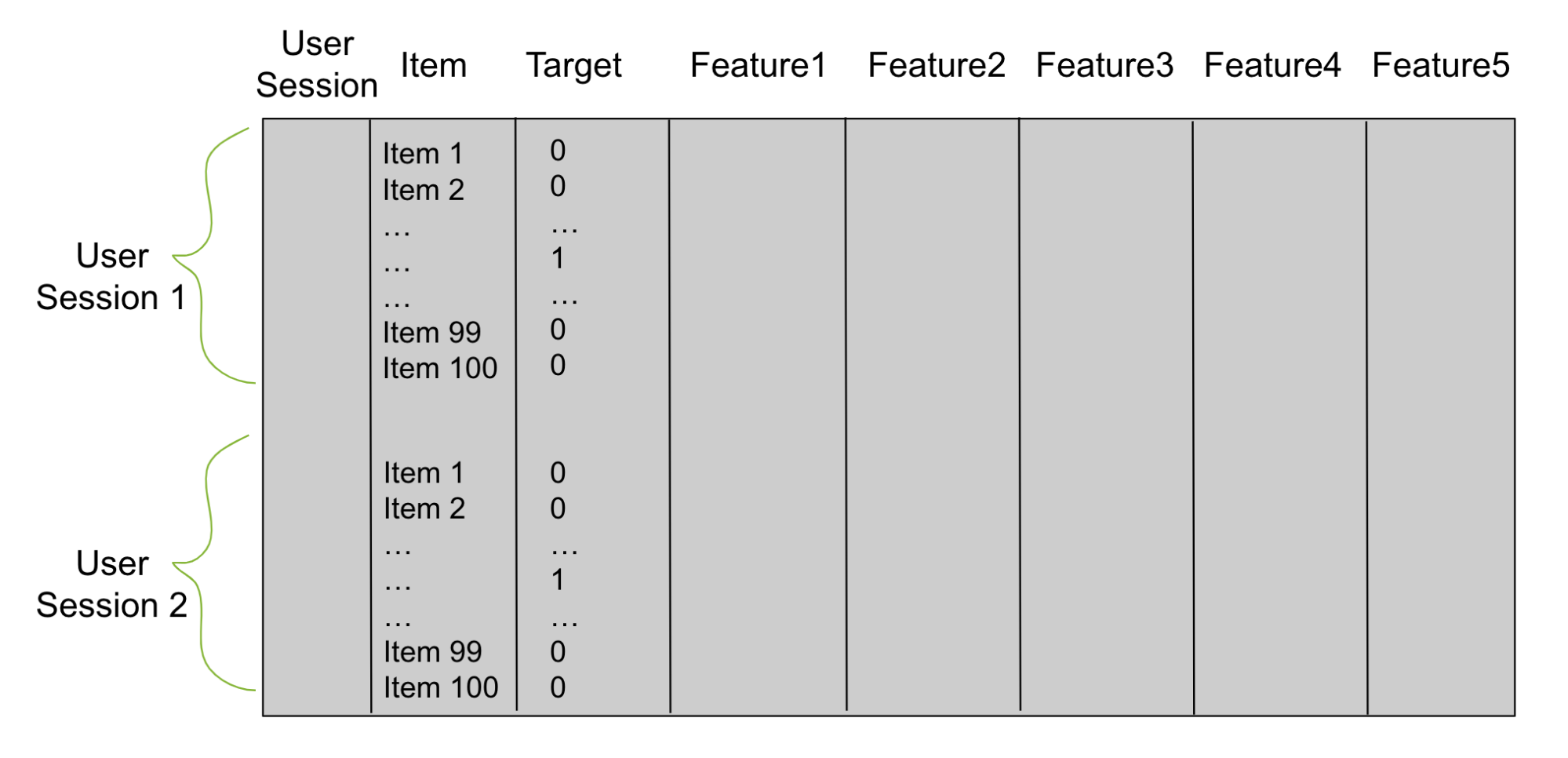
接下來,添加描述用戶會話的列和稱為功能列的項目。這些特征列是重新排序器用來學習模式和預測目標列的。你用二元分類目標或成對或列表排名目標來訓練你的重新排名者。之后,您使用這個經過訓練的模型來預測看不見的測試用戶會話的項目。
代表性不足的語言的數據匱乏
兩階段候選重新排序方法(以及任何其他方法)需要大量的訓練數據來正確地訓練機器學習或深度學習模型。流行語言通常有很多現有的數據,但對于歷史上代表性不足的語言來說,情況并非如此。
倡導服務不足的語言至關重要,原因有幾個,例如促進包容性、增加全球影響力以及提高在線用戶的參與度和滿意度。
為了構建對代表性不足的語言的推薦系統,我建議使用遷移學習。通過利用通用語言的數據集,模型可以識別現有的模式,并將這些學習應用于支持未被廣泛使用的語言。這有助于您克服小型數據集的挑戰,并創建一個更具包容性的數字世界。
開發多語言推薦系統的專業技巧
為了克服數據短缺,在第一階段和第二階段,使用遷移學習將信息從一種語言應用到另一種語言。許多項目具有多種語言的等價項。因此,一種語言中的用戶-項目交互行為可以被翻譯成另一種語言。
以下是加快多語言推薦引擎開發過程的重要提示。
候選人生成提示
- 首先,通過使用流行語言和代表性不足語言中存在的用戶歷史記錄,為代表性不足的語言創建共同訪問矩陣。
- 一定要使用預先訓練好的多語言表達項目 大語言模型(LLM)進行嵌入。然后,使用余弦相似度來查找代表性不足語言中的候選項。
- 使用預先訓練的多語言 LLM 嵌入初始化 NN 嵌入。然后,對用戶和項目嵌入之間的余弦相似性進行微調,以在代表性不足的語言中找到候選項目。
排名提示
- 在重新排序的表格數據框架中,可以使用流行語言的項目功能作為代表性不足語言的項目特征。
- 通過將從流行語言學習的用戶項目模式轉移到代表性不足的語言來創建用戶項目交互功能。
- 最后,使用流行語言中的用戶項數據幀行來訓練代表性不足的語言的重新排序器。
教程:多語言推薦系統
為了幫助您測試這些方法,我將為您介紹構建多語言推薦系統的優化過程。
候選生成實現
候選生成的目標是為每個用戶生成數百個項目建議。兩種流行的技術是使用共訪問矩陣和使用表示學習。將遷移學習與共訪問矩陣一起使用是很簡單的。
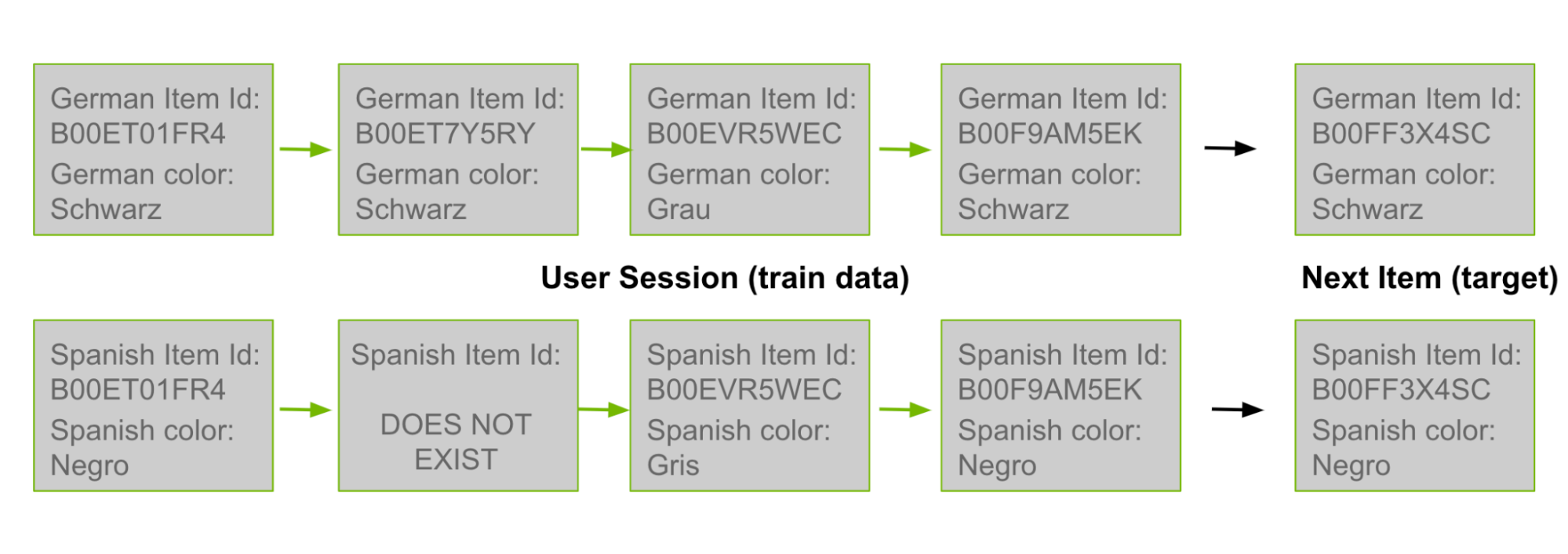
在這篇文章的前面,我討論了共同訪問候選生成是如何基于對用戶歷史中共存的產品 ID 對進行計數的。由于許多產品 ID 存在于多種語言中,您可以使用德語用戶歷史記錄中的對作為西班牙語共同訪問矩陣中的計數。在圖 3 中,最上面的德語行來自訓練數據。然后將其“翻譯”為西班牙語,如下面一行所示。
程序如下。
- 給定一對西班牙語產品 ID,您可以迭代其他五種語言的用戶:英語、德語、日語、意大利語和法語。
- 每當您在其中一個用戶的歷史記錄中觀察到西班牙產品 ID 對時,請將此西班牙商品對的計數加 1。或者你可以使用不同的權重,比如在計數上加 0.5。
- 累積所有西班牙語項目對的計數后,繼續像以前一樣生成候選項,方法是將新的共同訪問矩陣應用于每個西班牙語用戶的歷史記錄,為西班牙語用戶生成候選項。
使用 RAPIDS cuDF 創建共訪問矩陣是最快、最有效的方法。要了解更多,請參閱帶有示例代碼的 Jupyter 筆記本使用手工規則的候選者重新排名模型。
通過將包含所有用戶歷史記錄的數據幀(即,具有列 user 和歷史記錄項的數據幀)合并到關鍵用戶上的自身,可以創建所有歷史對。然后按項目對分組并聚合計數。
import cudf df = cudf.DataFrame(ALL_USER_HISTORIES)df = df.merge(df, on='user')df['wgt'] = 1df = df.groupby(['item_x','item_y']).wgt.sum() |
表示學習、LLM 和深度學習嵌入是當前的熱門話題。除了共同訪問矩陣之外,為每個用戶生成候選項的另一種選擇是創建有意義的距離嵌入。如果你為每個項目都有有有意義的距離嵌入,那么你可以使用一個模型來預測每個用戶的嵌入。接下來,找到與該預測嵌入最接近的 100 個嵌入(通過余弦相似性),并將其用作候選嵌入(圖 4)。
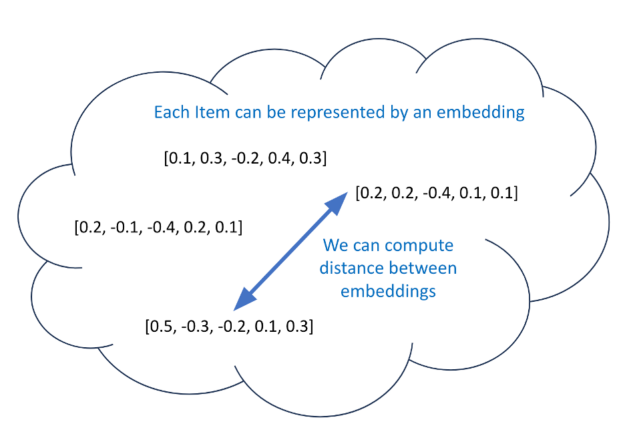
為項目訓練有意義的距離嵌入的過程稱為表示學習。嵌入N中的維度向量N維度空間。在訓練過程中,相似項目的嵌入被修改為更靠近(通過一些距離度量),而不同項目的嵌入則被修改為至少具有預定義的間隙距離(邊緣)他們之間。
在表示學習過程中使用遷移學習的一種方法是用多語言句子嵌入來預初始化嵌入。每個項目都有一個標題,無論是英文、德文、日文、西班牙文、意大利文還是法文。例如,您可以從 Hugging Face 的 stsb-xlm-r 多語言模型中預初始化每個項目,并嵌入其標題。這個模型已經在許多不同的語言上進行了訓練,并從所有語言中轉移了學習。之后,您可以使用圖 5 所示的模型使用訓練數據對嵌入進行微調。
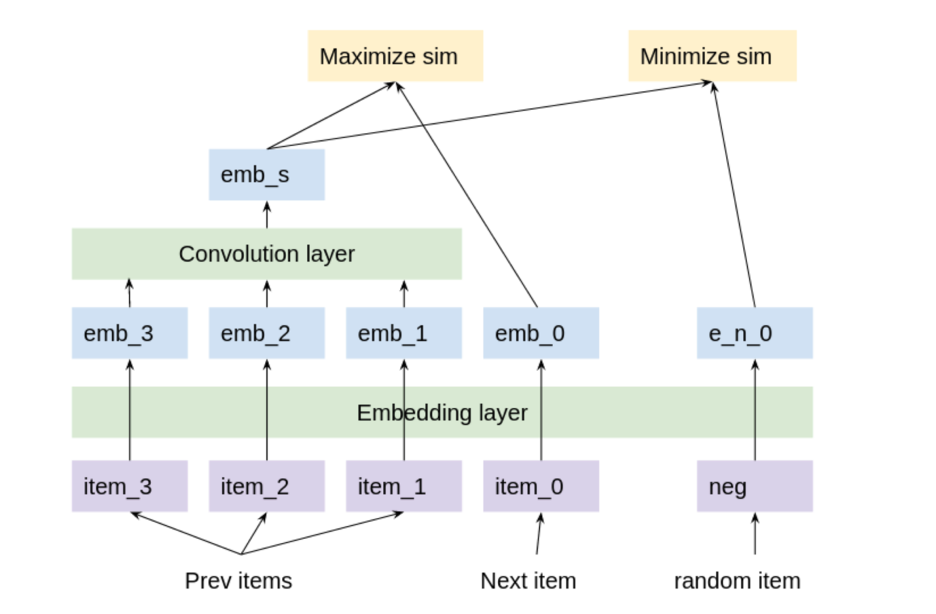
使用所有列車數據用戶歷史對模型進行微調。每三個連續的歷史項目與一個正項目目標配對,該正項目目標是下一個連續項目。每個三元組與 4096 個負面項目目標配對,這些目標是隨機選擇的項目。反向傳播最大化了預測嵌入和正目標之間的余弦相似性。并且它最小化了預測嵌入和負目標之間的余弦相似性。之后,您可以為每個項目進行有意義的距離嵌入,并為每個用戶進行預測嵌入。
使用 NVIDIA Merlin 框架是創建基于 transformer 的會話感知推薦系統的一種快速簡便的方法,該系統可以使用預訓練嵌入。想要了解更多信息,請參閱 時尚電商的基于會話的下一項預測 和 使用預訓練嵌入進行訓練 的 Jupyter 筆記本。
您也可以使用 NVIDIA Merlin Dataloader。
排名實施
階段 2 的目標是訓練重新排序器,該重新排序器預測每個用戶的所有可能候選項目中每個候選項目正確的可能性。為了成功地訓練模型,除了用戶、項目和目標列之外,還需要特征列。要素列有三種類型:
- 項目功能
- 用戶功能
- 用戶項目交互功能
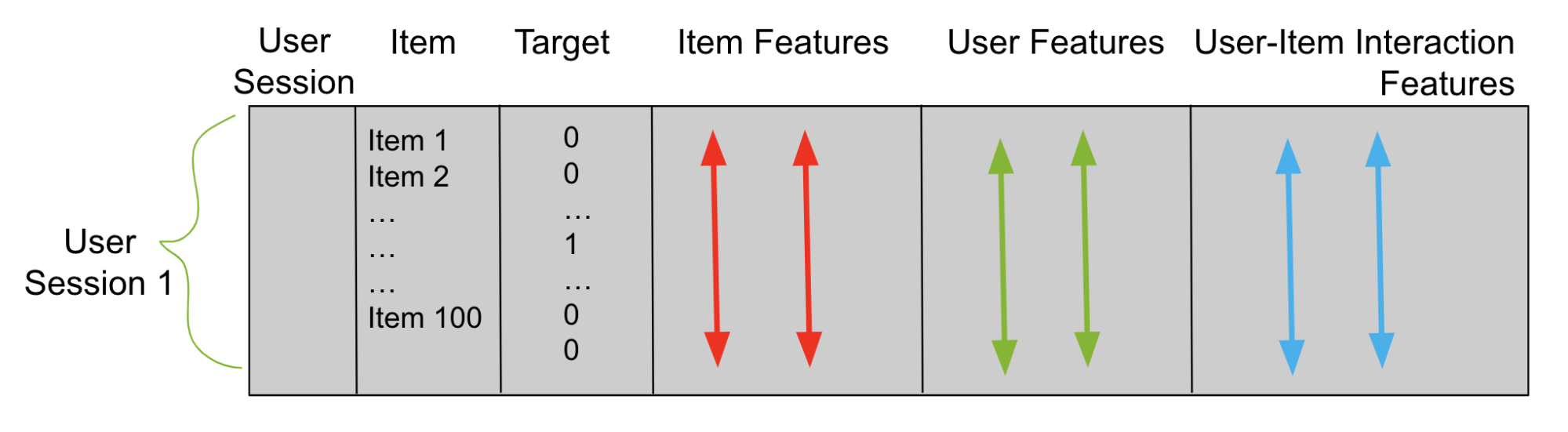
項目特征描述項目。例如,您可以添加商品價格功能。然后,在項目價格列中,具有項目 A 的重新排序數據幀中的每一行都有相應的價格 A(圖 6)。
在項目特征上使用遷移學習很容易。要將學習從德語轉移到西班牙語,可以從德語用戶歷史數據創建項目功能,然后將其合并到西班牙語項目。
例如,對于每個商品的產品 ID,計算它在所有德國用戶歷史記錄中出現的頻率。然后,在你的帶有西班牙語項目 A 的重新排序數據幀中的每一行,在德語項目流行度列中都有相應的德語流行度 A。這之所以有效,是因為許多商品的產品 ID 同時存在于德語和西班牙語中。如果某個西班牙語產品 ID 在德語中不存在,則在德語商品流行度欄中插入 Nan 。
用戶特征列和項目特征列通常使用數據框架創建groupby命令。為每個用戶或項創建一個屬性,然后將其合并到數據幀中。最快捷、最有效的方法是使用 RAPIDS cuDF 。
import cudfitem_features = data.groupby(‘item’)\.agg({‘item:count’,’user:nunique’,’price:first’})df = df.merge(item_features, left_on=’item’, right_index=True, how=’left’)user_features = data.groupby(‘user’)\.agg({‘user:count’,’item:nunique’})df = df.merge(user_features, left_on=’user’, right_index=True, how=’left’) |
用戶-項目交互特性描述了行的候選項目和該行的用戶之間的關系。這些特征對于每一行都有不同的值。生成用戶-項目交互特征的一種常見方法是描述用戶的最后一個歷史項目與其候選項目之間的關系。
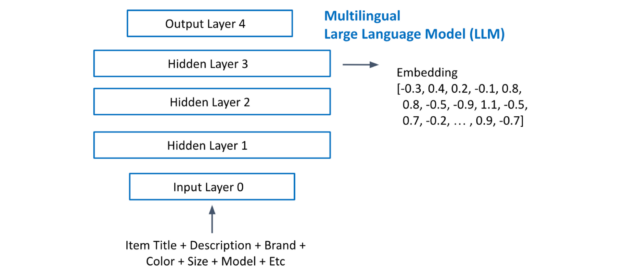
使用從流行語言到代表性不足語言的遷移學習的一種方法是使用多語言信息為所有項目創建有意義的距離嵌入。然后,用戶-項目交互特征可以是用戶的最后歷史項目和基于嵌入的候選項目之間的余弦相似性得分。
圖 7 顯示了從多語言 LLM 中提取項目嵌入。您將每個項目的所有文本連接起來,并將其輸入到 LLM 中。提取最后一個隱藏層激活作為嵌入。
使用流行語言中的信息來改進代表性不足的語言推薦的第三種方法是使用流行語言的數據幀行來訓練你的代表性不足 GBT 重新庫。首先,對所有語言的數據幀使用相同的列功能,然后將所有數據幀合并為一個新的數據幀。之后,您的數據幀很大。
使用 RAPIDS Dask cuDF XGB 在多個 GPU 上訓練具有數百萬行的 GBT 是最佳方法!想要了解更多詳細信息,請參閱KDD cup 解決方案代碼。
代碼的關鍵行如下:
import xgboost as xgbimport dask, dask_cudffrom dask.distributed import Clientclient = Client(cluster)df = dask_cudf.read_parquet(FILES).persist()dtrain = xgb.dask.DaskQuantileDMatrix(client, df[FEATURES], df[TARGET])xgb.dask.train(client, xgb_parms, dtrain) |
結論
在網上瀏覽時,推薦系統可能看起來很神奇,但正如你在這篇文章中所了解到的,多語言推薦引擎的內部工作是確定的,可以理解。
在這篇文章中,我將分享 NVIDIA 和 NVIDIA Merlin 團隊的 Kaggle 大師們在最近的KDD cup 2023 多語言推薦系統競賽中的表現,該競賽由 Amazon 主持。
我還介紹了推薦系統的兩階段候選重新排序技術。這是一種強大的技術,有助于解決許多推薦系統的需求。接下來,我為您提供了一些專業提示,幫助您為代表性不足的語言培訓推薦系統。我分享了 RAPIDS 和 NVIDIA Merlin 框架如何幫助您構建推薦系統。
我希望你能在下一個推薦系統項目中使用其中的一些想法。通過改進針對代表性不足語言的在線推薦系統,我們都可以讓互聯網更具包容性,擴大全球影響力,提高用戶參與度和滿意度。
?