
新 Volta GPU 架構的一個定義性特征是它的 張量核 ,它使 Tesla V100 加速器的峰值吞吐量是上一代 Tesla P100 的 32 位浮點吞吐量的 12 倍。張量核心使人工智能程序員能夠使用 混合精度 來實現更高的吞吐量而不犧牲精度。
張量核心已經在主版本或許多深度學習框架(包括 PyTorch 、 TensorFlow 、 MXNet 和 Caffe2 )中通過 pull 請求支持 深度學習 培訓。有關在使用這些框架時啟用張量核心的更多信息,請查看 混合精度訓練指南 。
在這篇博客文章中,我們展示了如何使用 CUDA 庫在自己的應用程序中使用張量核,以及如何直接在 CUDA C ++設備代碼中編程。
什么是張量核?
Tesla V100 的張量核心是可編程的矩陣乘法和累加單元,可為訓練和推理應用提供多達 125 個張量 TFLOP 。 Tesla V100GPU 包含 640 個張量核心:每平方米 8 個。張量核心及其相關數據路徑都是定制的,可以顯著提高浮點計算吞吐量,只需適度的面積和功耗成本。時鐘門控廣泛用于最大限度地節省電力。
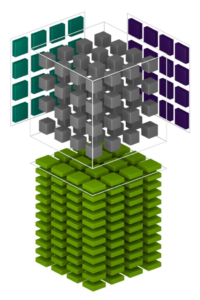
每個張量核提供一個 4x4x4 矩陣處理數組,該數組執行運算 D = A * B + C ,其中 答:, B 、 C 和 D 是 4 × 4 矩陣,如圖 1 所示。矩陣乘法輸入 A 和 B 是 FP16 矩陣,而累加矩陣 C 和 D 可以是 FP16 或 FP32 矩陣。
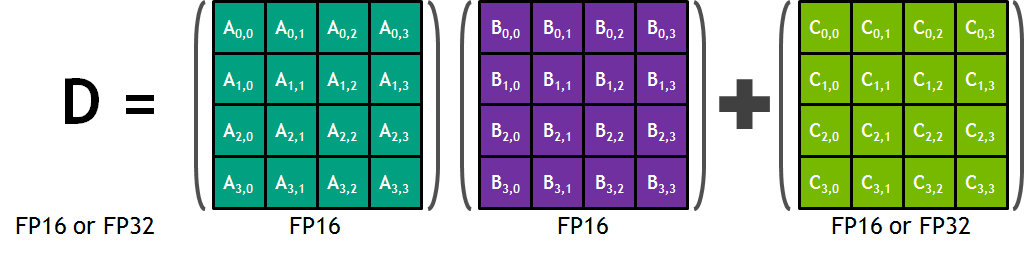
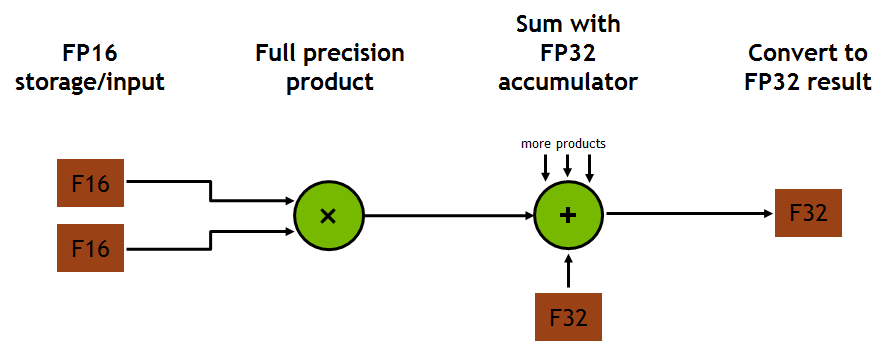
每個張量核心對每個時鐘執行 64 個浮點 FMA 混合精度運算( FP16 輸入乘法全精度乘積, FP32 累加,如圖 2 所示),一個 SM 中的 8 個張量核心每個時鐘執行 1024 個浮點運算。與使用標準 FP32 操作的 Pascal GP100 相比,每 SM 深度學習應用程序的吞吐量顯著提高了 8 倍,導致 Volta V100 GPU 的吞吐量比 Pascal P100 GPU 提高了 12 倍。張量核對 FP16 輸入數據進行 FP32 累加運算。對于 4x4x4 矩陣乘法, FP16 乘法會產生一個全精度的結果,該結果在 FP32 運算中與給定點積中的其他乘積累加,如圖 8 所示。
在程序執行過程中,多個張量核被一個完整的執行過程并發使用。扭曲中的線程提供了一個更大的 16x16x16 矩陣運算,由張量核心處理。 CUDA 將這些操作暴露為 CUDA C ++ WMMA API 中的扭曲級別矩陣操作。這些 C ++接口提供專門的矩陣加載、矩陣乘法和累加運算以及矩陣存儲操作,以有效地利用 CUDA C ++程序中的張量核。
但是在我們深入了解張量核心的低級編程細節之前,讓我們看看如何通過 CUDA 庫訪問它們的性能。
CUDA 庫中的張量核
使用張量核的兩個 CUDA 庫是 cuBLAS 和 cuDNN 。 cuBLAS 使用張量核來加速 GEMM 計算( GEMM 是矩陣矩陣乘法的 BLAS 項); cuDNN 使用張量核來加速卷積和 遞歸神經網絡 。
許多計算應用都使用 GEMMs :信號處理、流體力學和許多其他的。隨著這些應用程序的數據大小呈指數級增長,這些應用程序需要匹配地提高處理速度。圖 3 中的混合精度 GEMM 性能圖表明張量核明確地滿足了這一需求。
提高卷積速度的需求同樣大;例如,今天的深度 神經網絡 ( DNNs )使用了許多層卷積。人工智能研究人員每年都在設計越來越深的神經網絡;現在最深的網絡中的卷積層數量已經有幾十個。訓練 dnn 需要在前向和反向傳播期間重復運行卷積層。圖 4 中的卷積性能圖顯示張量核滿足了卷積性能的需要。(您或許也對 混合精度神經網絡訓練的有效技術 上的這篇文章感興趣)
兩個性能圖表都顯示, Tesla V100 的張量核心的性能是上一代 Tesla P100 的數倍。性能改進這一巨大的改變了計算領域的工作方式:使交互成為可能,啟用“假設”場景研究,或者減少服務器場的使用。如果您在應用程序中使用 GEMMs 或卷積,請使用下面的簡單步驟來加速您的工作。
如何在 cuBLAS 中使用張量核
您可以利用張量核心,對現有的 cuBLAS 代碼進行一些更改。這些更改是您使用 cuBLAS API 時所做的微小更改。
下面的示例代碼應用了一些簡單的規則來指示 cuBLAS 應該使用張量核;這些規則在代碼后面顯式地枚舉。
示例代碼
下面的代碼在很大程度上與以前的架構上用于調用 cuBLAS 中 GEMM 的通用代碼相同。
// First, create a cuBLAS handle: cublasStatus_t cublasStat = cublasCreate(&handle); // Set the math mode to allow cuBLAS to use Tensor Cores: cublasStat = cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH); // Allocate and initialize your matrices (only the A matrix is shown): size_t matrixSizeA = (size_t)rowsA * colsA; T_ELEM_IN **devPtrA = 0; cudaMalloc((void**)&devPtrA[0], matrixSizeA * sizeof(devPtrA[0][0])); T_ELEM_IN A = (T_ELEM_IN *)malloc(matrixSizeA * sizeof(A[0])); memset( A, 0xFF, matrixSizeA* sizeof(A[0])); status1 = cublasSetMatrix(rowsA, colsA, sizeof(A[0]), A, rowsA, devPtrA[i], rowsA); // ... allocate and initialize B and C matrices (not shown) ... // Invoke the GEMM, ensuring k, lda, ldb, and ldc?are all multiples of 8, // and m is a multiple of 4: cublasStat = cublasGemmEx(handle, transa, transb, m, n, k, alpha, A, CUDA_R_16F, lda, B, CUDA_R_16F, ldb, beta, C, CUDA_R_16F, ldc, CUDA_R_32F, algo);
一些簡單的規則
cuBLAS 用戶會注意到他們現有的 cuBLAS GEMM 代碼有一些變化:
- 例程必須是 GEMM ;目前,只有 GEMM 支持 Tensor 核心執行。
- 數學模式必須設置為
CUBLAS_TENSOR_OP_MATH。浮點數學是非關聯的,因此張量核心數學例程的結果與類似的非張量核心數學例程的結果不完全對等。 cuBLAS 要求用戶選擇使用張量核。 k、lda、ldb和ldc都必須是 8 的倍數;m必須是 4 的倍數。張量核心數學例程以八個值的步長跨越輸入數據,因此矩陣的維數必須是 8 的倍數。- 矩陣的輸入和輸出數據類型必須是半精度或單精度。(上面只顯示了
CUDA_R_16F,但也支持CUDA_R_32F。)
不滿足上述規則的 gemm 將返回到非張量核心實現。
GEMM 性能
如前所述, Tensor 內核提供的 GEMM 性能是以前硬件的數倍。圖 3 顯示了 GP100 ( Pascal )與 GV100 ( Volta )硬件的比較性能。

如何在 cuDNN 中使用張量核
在 cuDNN 中使用張量核也很簡單,而且只涉及對現有代碼的細微更改。
示例代碼
在 cuDNN 中使用張量核心的示例代碼可以在 cuDNN samples 目錄的 conv_sample.cpp 中找到;我們復制了下面的一些摘錄。( cuDNN 樣本目錄 與文檔一起打包。)
// Create a cuDNN handle:
checkCudnnErr(cudnnCreate(&handle_)); // Create your tensor descriptors:
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnIdesc ));
checkCudnnErr( cudnnCreateFilterDescriptor( &cudnnFdesc ));
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnOdesc ));
checkCudnnErr( cudnnCreateConvolutionDescriptor( &cudnnConvDesc )); // Set tensor dimensions as multiples of eight (only the input tensor is shown here):
int dimA[] = {1, 8, 32, 32};
int strideA[] = {8192, 1024, 32, 1}; checkCudnnErr( cudnnSetTensorNdDescriptor(cudnnIdesc, getDataType(), convDim+2, dimA, strideA) ); // Allocate and initialize tensors (again, only the input tensor is shown):
checkCudaErr( cudaMalloc((void**)&(devPtrI), (insize) * sizeof(devPtrI[0]) ));
hostI = (T_ELEM*)calloc (insize, sizeof(hostI[0]) ); initImage(hostI, insize); checkCudaErr( cudaMemcpy(devPtrI, hostI, sizeof(hostI[0]) * insize, cudaMemcpyHostToDevice)); // Set the compute data type (below as CUDNN_DATA_FLOAT):
checkCudnnErr( cudnnSetConvolutionNdDescriptor(cudnnConvDesc, convDim, padA, convstrideA, dilationA, CUDNN_CONVOLUTION, CUDNN_DATA_FLOAT) ); // Set the math type to allow cuDNN to use Tensor Cores:
checkCudnnErr( cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH) ); // Choose a supported algorithm:
cudnnConvolutionFwdAlgo_t algo = CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM; // Allocate your workspace:
checkCudnnErr( cudnnGetConvolutionForwardWorkspaceSize(handle_, cudnnIdesc, cudnnFdesc, cudnnConvDesc, cudnnOdesc, algo, &workSpaceSize) ); if (workSpaceSize > 0) { cudaMalloc(&workSpace, workSpaceSize);
} // Invoke the convolution:
checkCudnnErr( cudnnConvolutionForward(handle_, (void*)(&alpha), cudnnIdesc, devPtrI, cudnnFdesc, devPtrF, cudnnConvDesc, algo, workSpace, workSpaceSize, (void*)(&beta), cudnnOdesc, devPtrO) );
一些簡單的規則
注意一些與普通 cuDNN 用法不同的地方:
- 卷積算法必須是
ALGO_1(IMPLICIT_PRECOMP_GEMM表示正向)。除了ALGO_1之外的其他卷積算法可能在未來的 cuDNN 版本中使用張量核。 - 數學類型必須設置為
CUDNN_TENSOR_OP_MATH。與 cuBLAS 一樣,張量核心數學例程的結果與類似的非張量核心數學例程的結果并不完全等價,因此 cuDNN 要求用戶“選擇”使用張量核心。 - 輸入和輸出通道尺寸都必須是 8 的倍數。同樣,在 cuBLAS 中,張量核心數學例程以八個值的步長跨越輸入數據,因此輸入數據的維數必須是 8 的倍數。
- 卷積的輸入、過濾和輸出數據類型必須為半精度。
不滿足上述規則的卷積將返回到非張量核心實現。
上面的示例代碼顯示了 NCHW 數據格式,請參見 conv_sample.cpp NHWC 支持示例。
卷積性能
如前所述,張量核心的卷積性能是以前硬件的數倍。圖 4 顯示了 GP100 ( Pascal )與 GV100 ( Volta )硬件的比較性能。

CUDA 9 . 0 中張量核的編程訪問
通過 CUDA 9 . 0 訪問內核中的張量核是一個預覽功能。這意味著本節中描述的數據結構、 api 和代碼在未來的 CUDA 版本中可能會發生變化。
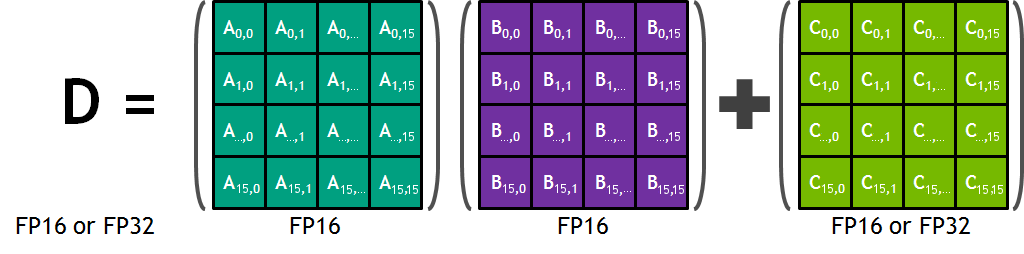
雖然 cuBLAS 和 cuDNN 覆蓋了張量核的許多潛在用途,但是您也可以直接在 nvcuda::wmma C ++中編程它們。張量核心通過 CUDA 命名空間中的一組函數和類型在 CUDA 9 . 0 中公開。它們允許您將值加載或初始化為張量核心所需的特殊格式,執行矩陣乘法累加( MMA )步驟,并將值存儲回內存。在程序執行過程中,一個完整的扭曲同時使用多個張量核。這允許 warp 在非常高的吞吐量下執行 16x16x16mma (圖 5 )。
讓我們看一個簡單的例子,它展示了如何使用 WMMA ( Warp Matrix Multiply Accumulate ) API 來執行矩陣乘法。注意,這個例子并沒有針對高性能進行調整,主要是作為 API 的演示。為了獲得更好的性能, MIG ht 應用于此代碼的優化示例,請查看 CUDA 工具箱中的 cudaTensorCoreGemm 示例。為了獲得最高的生產性能,應該使用 cuBLAS 代碼,如上所述。
標題和命名空間
WMMA API 包含在 mma.h 頭文件中。完整的名稱空間是 nvcuda::wmma::* ,但是在代碼中保持 wmma 的顯式是很有用的,所以我們只使用 nvcuda 名稱空間。
#include <mma.h> using namespace nvcuda;
設計和初始化
完整的 GEMM 規范允許算法處理 a 或 b 的換位,并使數據跨距大于矩陣中的跨距。為了簡單起見,讓我們假設 a 和 b 都不是換位的,并且內存和矩陣的前導維度是相同的。
我們將采用的策略是讓一個 warp 負責輸出矩陣的單個 16 × 16 部分。通過使用二維網格和線程塊,我們可以有效地在二維輸出矩陣上平鋪扭曲。
// The only dimensions currently supported by WMMA
const int WMMA_M = 16;
const int WMMA_N = 16;
const int WMMA_K = 16; __global__ void wmma_example(half *a, half *b, float *c, int M, int N, int K, float alpha, float beta) { // Leading dimensions. Packed with no transpositions. int lda = M; int ldb = K; int ldc = M; // Tile using a 2D grid int warpM = (blockIdx.x * blockDim.x + threadIdx.x) / warpSize; int warpN = (blockIdx.y * blockDim.y + threadIdx.y);
在執行 MMA 操作之前,操作數矩陣必須在 GPU 的寄存器中表示。由于 MMA 是一個 warp 范圍的操作,這些寄存器分布在 warp 的線程中,每個線程持有整個矩陣的 片段 。單個矩陣參數與片段之間的映射是不透明的,因此您的程序不應對此進行假設。
在 CUDA 中,片段是一種模板化類型,其模板參數描述了片段持有的矩陣( a 、 B 或累加器)、整體 WMMA 操作的形狀、數據類型,以及對于 a 和 B 矩陣,數據是行還是列主。最后一個參數可用于執行 A 或 B 矩陣的換位。這個例子沒有換位,所以兩個矩陣都是列 major ,這是 GEMM 的標準。
// Declare the fragments wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> a_frag; wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> b_frag; wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag; wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
初始化步驟的最后一部分是用零填充累加器片段。
wmma::fill_fragment(acc_frag, 0.0f);
內環
我們用一個矩陣來計算每一個輸出的扭曲策略。為此,我們需要循環 A 矩陣的行和 B 矩陣的列。這是沿著兩個矩陣的 K 維生成一個 MxN 輸出塊。 loadmatrix 函數從內存(在本例中是全局內存,盡管可以是任何內存空間)中獲取數據并將其放入片段中。加載的第三個參數是矩陣內存中的“前導維度”;我們加載的 16 × 16 塊在內存中是不連續的,因此函數需要知道連續列(或行,如果這些是行的主要片段)之間的跨距。
MMA 調用就地累積,因此第一個參數和最后一個參數都是我們先前初始化為零的累加器片段。
// Loop over the K-dimension for (int i = 0; i < K; i += WMMA_K) { int aRow = warpM * WMMA_M; int aCol = i; int bRow = i; int bCol = warpN * WMMA_N; // Bounds checking if (aRow < M && aCol < K && bRow < K && bCol < N) { // Load the inputs wmma::load_matrix_sync(a_frag, a + aRow + aCol * lda, lda); wmma::load_matrix_sync(b_frag, b + bRow + bCol * ldb, ldb); // Perform the matrix multiplication wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag); } }
完成
acc_frag 現在基于 A 和 B 的乘法保存此扭曲的輸出塊的結果。完整的 GEMM 規范允許縮放此結果,并將其累積到適當的矩陣頂部。實現這種縮放的一種方法是對片段執行元素級操作。雖然沒有定義從矩陣坐標到線程的映射,但是元素級操作不需要知道這個映射,所以仍然可以使用片段來執行。因此,對片段執行縮放操作或將一個片段的內容添加到另一個片段是合法的,只要這兩個片段具有相同的模板參數。如果片段具有不同的模板參數,則結果未定義。使用這個特性,我們將現有的數據加載到 C 語言中,并使用正確的縮放比例來累積到目前為止的計算結果。
// Load in current value of c, scale by beta, and add to result scaled by alpha int cRow = warpM * WMMA_M; int cCol = warpN * WMMA_N; if (cRow < M && cCol < N) { wmma::load_matrix_sync(c_frag, c + cRow + cCol * ldc, ldc, wmma::mem_col_major); for(int i=0; i < c_frag.num_elements; i++) { c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i]; }
最后,我們將數據存儲到內存中。同樣,目標指針可以是 GPU 可見的任何內存空間,并且必須指定內存中的前導維度。還有一個選項可以指定輸出是寫在行還是列 major 。
// Store the output wmma::store_matrix_sync(c + cRow + cCol * ldc, c_frag, ldc, wmma::mem_col_major); } }
這樣,矩陣乘法就完成了。我在這篇博文中省略了主機代碼,不過是一個 完整的工作示例可以在 Github 上找到 。
今天就從 CUDA 9 中的張量核心開始吧
希望這個例子能讓您了解如何在應用程序中使用張量核。如果您想了解更多,請參閱 MIG 。
CUDA 9tensorcoreapi 是一個預覽特性,所以我們很樂意聽取您的反饋。如果您有任何意見或問題,請不要猶豫在下面留下評論。
CUDA 9 免費提供,因此 立即下載 。
?





