
NVIDIA NeMo Parakeet 是一個端到端平臺,用于在任何地方(任何云端和本地)大規模開發多模態生成式 AI 模型,包括自動語音識別 (ASR) 模型。這些最先進的 ASR 模型是與 Suno.ai 合作開發的,能夠極其準確地轉錄英語口語。
本文詳細介紹了 Parakeet ASR 模型在語音識別領域的新突破。
隆重推出 Parakeet ASR 系列?
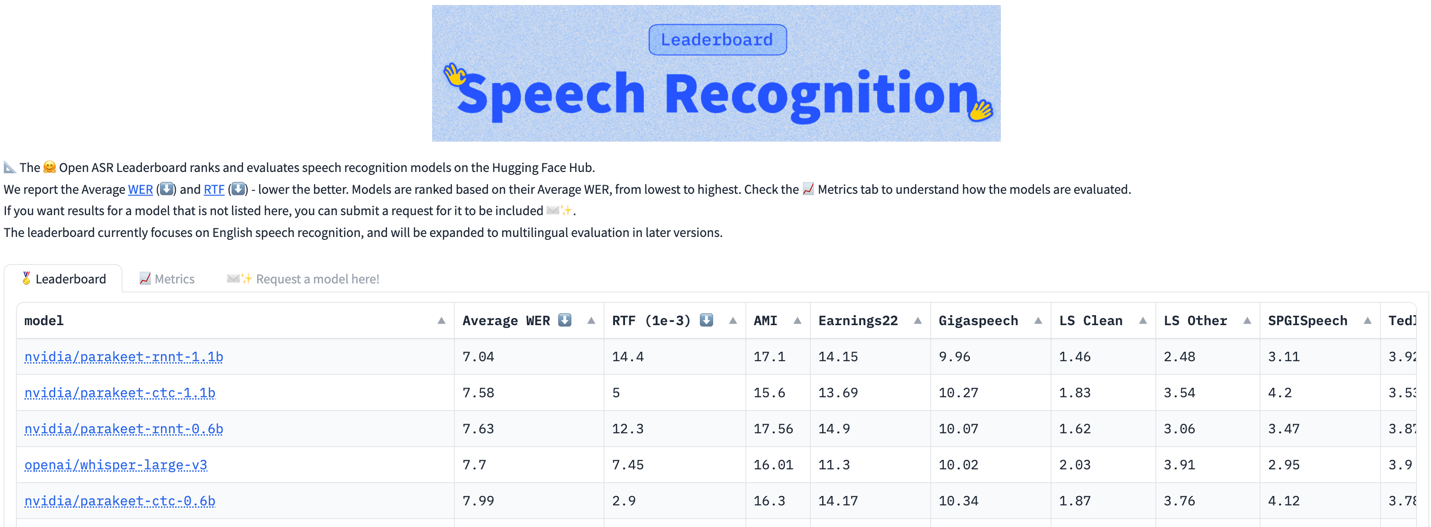
四個已發布的 Parakeet 模型基于遞歸神經網絡傳感器 (RNNT) 或 connectionist Temporal Classification (CTC) 解碼器。它們擁有 0.6 B 和 11 B 參數,可處理各種音頻環境,表現出對音樂和靜音等非語音片段的彈性。
這些模型基于廣泛的 64000 小時公有和專有數據集進行訓練,在各種口音和方言、人聲范圍以及不同的域和噪音條件下表現出出色的準確性。
| 模型 | 準確性/速度權衡 | 用例 |
| Parakeet CTC 1.1 B Parakeet CTC 0.6 B |
|
|
| Parakeet RNNT 1.1 B Parakeet RNNT 0.6 B |
|
|
使用 Parakeet ASR 模型的優勢?
Parakeet 模型使用 NeMo 框架構建,優先考慮用戶友好性和靈活性。預訓練檢查點隨時可用,因此可以輕松將這些模型集成到項目中。可以立即按原樣部署這些模型,或針對特定任務進行進一步微調。
以下是 Parakeet 模型的主要優勢:
- 卓越的準確性:在不同的音頻源和領域中實現了出色的詞錯誤率 (WER) 準確性,并對非語音片段具有強大的可靠性。
- 開源和可擴展性:無縫集成和定制化功能。
- 預訓練檢查點:可隨時用于推理或進一步微調。
- 不同的模型規模:模型規模分別為 0.6 GB 和 1.1 GB,足以有效地理解復雜的語音模式。
- 許可:模型檢查點在 CC-BY-4.0 許可下發布,可用于任何商業應用。
嘗試 parakeet-rnnt-1.1B 模型的 Gradio 演示。有關工具包的更多信息,請參閱 NVIDIA/NeMo GitHub 庫。
深入了解 Parakeet 架構?
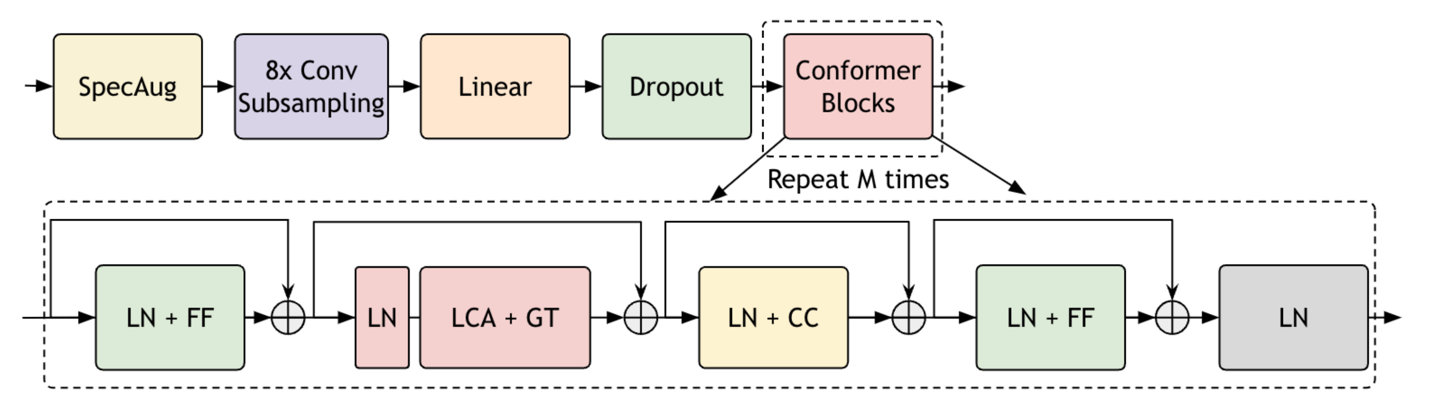
Parakeet 模型基于 FastConformer?優化的 Conformer 模型,其特點包括 8 倍的深度可分離卷積下采樣、修改卷積核大小以及高效子采樣模塊。
Parakeet 架構旨在支持使用本地注意力在 NVIDIA A100 GPU 80GB 卡上對長音頻片段 (長達 11 小時的語音) 進行推理。使用 RNNT 或 CTC 解碼器對模型進行端到端訓練。
想要了解更多有關長音頻推理的信息,請參閱 ICASSP 2024 論文,該論文研究用于長格式音頻轉錄的端到端 ASR 架構。
基于 Parakeet FC 的模型在推理和訓練速度方面表現出色,可無縫應對內存限制。通常情況下,模型在不同的推理場景下通常具有不同的實時系數 (RTF) 分數。
我們通常會在整個數據集上測量 RTF,這些數據集由具有固定批量大小的不同音頻文件組成。在這種情況下,我們將 RTF 計算為 ASR 系統轉錄單個音頻片段所需的時間除以不同大小的 Parakeet 模型的語音總持續時間。在這種情況下,我們會測量模型轉錄長音頻文件的速度,由于注意力模型相對于音頻長度的二次計算復雜性,該文件通常無法被注意力模型處理。
表 2 顯示了 RTF 和 NVIDIA A100 80GB 卡上用于推理的輸入音頻的最大持續時間 (一次傳遞)。
| 大小 | 全注意力模式下的音頻最大持續時間[分鐘] | RTF 30 秒音頻 (RNNT) | RTF 30 秒音頻 (CTC) | 上下文受限時的最長持續時間[小時] |
| 120M | 30 | 11.8 e-3 | 1.5 e-3 | 14 |
| 60 億 | 30 | 13.3 e-3 | 2.0 e-3 | 13 |
| 11 億 | 30 | 14.6 e-3 | 3.4 e-3 | 12.5 |
在上下文注意力有限的情況下,即使是最大的模型也可以一次推理長達 13 小時的音頻。
具有 1B 參數的 Parakeet 模型一次可以處理 12.5 小時的音頻,而中型 (0.6 B) 模型可以處理 13 小時。CTC 模型在推理速度方面表現出色,CTC RTF 為 2e-3,30 秒音頻,是轉錄會議音頻的理想選擇。
FastConformer 在上下文注意力有限的情況下使用全局令牌進行微調,即使在處理大量長格式音頻數據集時也能實現更高的準確性 (表 3)。
| 模型 | TED-LIUM3 | 收益 21 | 收益 22 | CORAAL |
| 上下文注意力受限的 FC | 5.88 | 17.08 | 24.67 | 37.35 |
| *微調 | 5.08 | 14.82 | 20.44 | 30.28 |
| 全局令牌 | 4.98 | 13.84 | 19.49 | 28.75 |
如何使用 Parakeet 模型?
要使用 Parakeet 模型,請將 NeMo 安裝為 pip 包。在安裝 NeMo 之前安裝 Cython 和 PyTorch (2.0 及更高版本)。然后將 NeMo 安裝為 pip 包:
pip install nemo_toolkit['asr'] |
安裝 NeMo 后,評估音頻文件列表:
import nemo.collections.asr as nemo_asrasr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-rnnt-1.1b")transcript = asr_model.transcribe(["some_audio_file.wav"]) |
用于長形式語音推理的 Parakeet 模型?
加載 Fast Conformer 模型后,您可以在構建模型后輕松地將注意力類型修改為有限的上下文注意力。您還可以為子采樣模塊應用音頻分塊,對大型音頻文件執行推理。
這些模型經過全局注意力訓練,切換到本地注意力會降低其性能。但是,它們仍然可以合理地轉錄長音頻文件。
對于大型文件的有限上下文注意力 (在 A100 GPU 上最多需要 11 小時),請執行以下步驟:
# Enable local attentionasr_model.change_attention_model("rel_pos_local_attn", [128, 128])? # local attn?
# Enable chunking for subsampling moduleasr_model.change_subsampling_conv_chunking_factor(1)? # 1 = auto select?
# Transcribe a huge audio fileasr_model.transcribe([".wav"])? # 10+ hours! |
您可以在自己的數據集上針對其他語言微調 Parakeet 模型。以下是一些實用教程:
- 通過 NeMo 清單格式對數據進行微調:ASR CTC 語言微調指南
- 對 Hugging Face 數據集格式的數據進行微調:ASR 模型與使用 HF 數據集的傳感器模型教程。
結束語?
NeMo 模型提高了英語轉錄的準確性和性能,為企業和開發者提供了一系列選項,用于具有不同語音模式和噪音級別的真實應用程序。有關更多信息,請參閱 NeMo 模型頁面。
欲了解 Parakeet ASR 模型的架構詳細信息,請參閱 具有線性可擴展注意力的快速變形器:高效語音識別 和 適用于長格式音頻轉錄的端到端 ASR 架構。
在最新的 NeMo ASR 模型中,Parakeet-CTC 已經發布。其他模型將在不久的將來作為 NVIDIA Riva 出現。嘗試 Parakeet-RNNT-1.1B 的第一手資料,包括 Gradio 演示 和本地 GitHub 庫。
通過 NVIDIA API 目錄,并在本地使用 NVIDIA NIM 和 NVIDIA LaunchPad,您可以探索更多功能和工具。
?




