大型語言模型 (LLM) 在理解和生成類似人類的響應方面具有前所未有的能力,這給世界留下了深刻的印象。它們的聊天功能在人類和大型數據語料庫之間提供了快速且自然的交互。例如,它們可以從數據中總結和提取亮點,或者用自然語言替換 SQL 查詢等復雜查詢。
雖然假設這些模型可以輕松地創造商業價值非常吸引人,但遺憾的是現實并非總是這樣。幸運的是,企業可以通過使用自己的數據來增強大型語言模型(LLM),從而從中提取價值。這可以通過檢索增強生成(RAG)來實現,正如 NVIDIA 生成式 AI 示例 在面向開發者的 GitHub 庫中所展示的。
通過使用業務數據增強 LLM,企業可以提高其 AI 應用的敏捷性并響應新的開發。例如:
- 聊天機器人:許多企業已經在其網站上使用 AI 聊天機器人來支持基本的客戶互動。通過 RAG,公司能夠構建高度針對其產品的聊天體驗。例如,可以輕松回答有關產品規格的問題。
- 客戶服務:公司可以授權實時服務代表使用準確、最新的信息輕松回答客戶問題。
- 企業搜索:企業在整個組織內擁有豐富的知識資源,包括技術文檔、公司政策、IT 支持文章和代碼庫。員工可以通過查詢內部搜索引擎,以更快、更高效的方式檢索信息。
本文介紹了在構建 LLM 應用時使用 RAG 技術的好處,以及 RAG 工作流的組成部分。閱讀完本文后,歡迎參閱RAG 101:檢索增強型生成問題的解答。
RAG 的優勢
使用 RAG 有幾個優勢:
- 通過實時數據訪問為 LLM 解決方案提供支持
- 保護數據隱私
- 減輕 LLM 的幻覺
通過實時數據訪問為 LLM 解決方案提供支持
企業中的數據不斷變化。使用 LLM 的 AI 解決方案可以通過 RAG 保持最新狀態,這有助于直接訪問其他數據資源。這些資源可以由實時和個性化數據組成。
保護數據隱私
確保數據隱私對于企業至關重要。借助自托管 LLM (在 RAG 工作流程中演示),敏感數據可以像存儲數據一樣保存在本地。
減輕 LLM 的幻覺
當 LLM 未提供真實的實際信息時,它們通常會提供錯誤但令人信服的響應。這稱為幻覺RAG 通過為 LLM 提供相關和派系信息來降低產生幻覺的可能性。
構建和部署首個 RAG 工作流
典型的 RAG 流程由幾個階段組成。文檔提取過程離線進行,當輸入在線查詢時,會檢索相關文檔并生成響應。
圖 1 展示了可以在數據中心構建和部署的加速 RAG 工作流,詳情請參見 NVIDIA Generative AI Examples GitHub 庫。
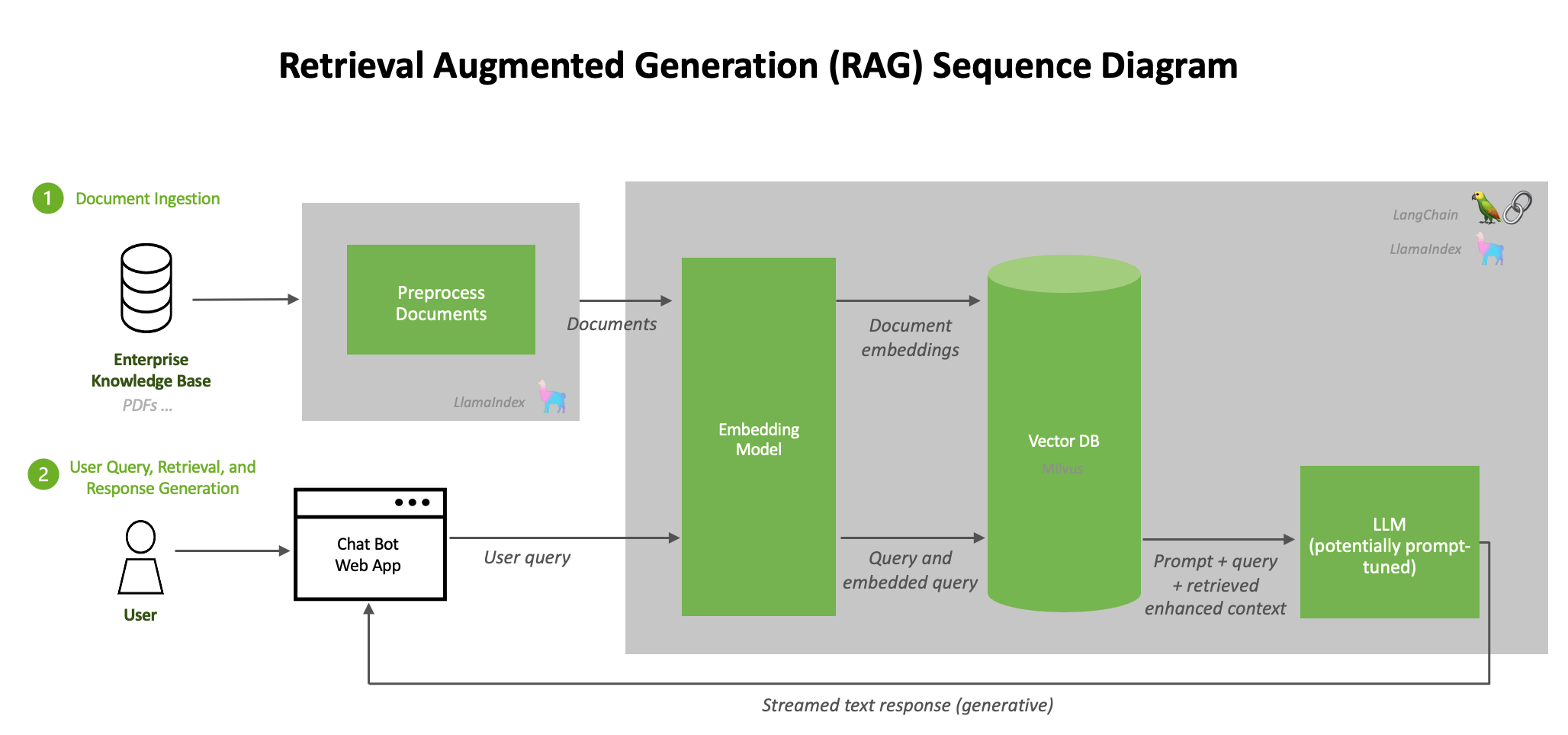
每個邏輯微服務都被分割成多個容器,并托管在 NGC 的公共目錄中。從更高層次上講,RAG 系統的架構可以概括為圖 1 所示的流程:
- 文檔預處理、提取和嵌入生成的循環流程
- 包含用戶查詢和響應生成的推理工作流
文檔提取
首先,來自不同來源(例如數據庫、文檔或實時 Feed)的原始數據被提取到 RAG 系統中。為了對這些數據進行預處理,LangChain 提供了各種文檔加載器,以加載來自許多不同來源的多種形式的數據。
術語文檔加載器的使用可能會引起誤解。源文檔并不局限于您可能想到的標準文檔類型(如 PDF、文本文件等)。例如,LangChain 支持從 Confluence、CSV 文件、Outlook 電子郵件等多種來源加載文檔,詳情請參見更多信息。LlamaIndex 也提供了多種文檔加載器,您可以在LlamaHub上找到它們。
文檔預處理
文檔加載完成后,通常會進行轉換。一種轉換方法是文本分割,它將長文本分解為較小的片段。這對于將文本擬合到嵌入模型中非常必要,例如 e5-large-v2 的最大令牌長度為 512。雖然分割文本聽起來很簡單,但這可能是一個細致入微的過程。
生成嵌入
提取數據時,必須將其轉換為系統可以高效處理的格式。生成嵌入需要將數據轉換為高維向量,以數字格式表示文本。
將嵌入存儲在向量數據庫中
已處理的數據和生成的嵌入被存儲在專門的數據庫中,稱為向量數據庫。這些數據庫針對處理向量化數據進行了優化,以實現快速的搜索和檢索操作。將數據存儲在如 RAPIDS RAFT 加速的向量數據庫 和 Milvus 中,可以保證信息的可訪問性,并實現 實時交互中的快速檢索。
LLM
LLM 是 RAG 流程的基礎生成組件。這些先進的通用語言模型基于龐大的數據集進行訓練,使它們能夠理解和生成類似人類的文本。在 RAG 環境中,LLM 用于根據用戶查詢和用戶查詢期間從向量數據庫檢索的上下文信息生成完全形成的響應。
查詢
當用戶提交查詢時,RAG 系統使用索引數據和向量執行高效搜索。系統通過比較查詢向量與向量數據庫中存儲的向量來識別相關信息。然后,LLM 使用檢索到的數據制定適當的響應。
通過測試此示例工作流程,您可以快速部署此系統,詳情請訪問 NVIDIA/GenerativeAIExamples GitHub 庫。
開始在企業中構建 RAG
通過使用 RAG,您可以輕松為 LLM 提供最新的專有信息,并構建一個能夠提高用戶信任度、改善用戶體驗和減少幻覺的系統。
探索 NVIDIA AI 聊天機器人 RAG 工作流程,開始構建能夠利用最新信息,以自然語言準確回答特定領域問題的聊天機器人。
?