
RAPIDS Apache 的加速器 Spark v21 。現在有 10 個!作為一個開源項目,我們重視我們的社區、他們的聲音和請求。此版本構成了社區對最適合 GPU 加速的操作的請求。
此版本的重要標注:
- Speed up –性能改進和成本節約。
- New Functionality –新的 I / O 和嵌套數據類型鑒定和分析工具功能。
- Community Updates – 對 spark-examples repository 的更新。
加快
用于 Apache 的 RAPIDS 加速器 Spark 在功能和性能方面都以驚人的速度增長。標準行業基準是衡量一段時間內績效的好方法,但衡量績效的另一個晴雨表是衡量數據預處理階段或數據分析中使用的普通操作員的績效。
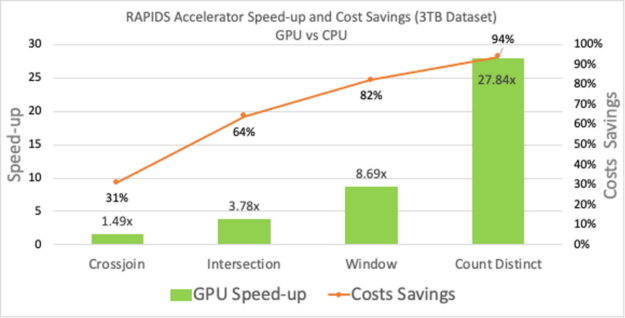
我們使用了如下表所示的四個此類查詢:
- Count Distinct :用于估計訪問電子商務站點的唯一頁面瀏覽量或唯一客戶數的函數。
- Window: 在分析市場營銷或金融行業的時間戳事件數據時,對組件進行預處理所需的關鍵操作員。
- Intersect: 用于刪除數據幀中的重復項的運算符。
- Cross-join: 交叉聯接的一個常見用途是獲取項目的所有組合。
這些查詢在谷歌云平臺( GCP )機器上運行,每臺機器有 2xT4 GPU 和 104GB 內存。使用的數據集大小為 3TB ,具有多種不同的數據類型。有關設置和查詢的更多信息可以在 GitHub 上的 spark-rapids-examples 存儲庫中找到。這四個查詢不僅顯示了性能和成本優勢,而且速度范圍( 27 倍到 1.5 倍)因計算強度而異。這些查詢的計算和網絡利用率不同,類似于數據預處理中的實際用例。
新功能
插入
大多數 Apache Spark 用戶都知道 Spark 3.2 于今年 10 月發布。 v21 。 10 版本支持 Spark 3.2 和 CUDA 11.4 。在這個版本中,我們著重于擴展對 I / O 、嵌套數據處理和機器學習功能的支持。 RAPIDS Apache 的加速器 Spark v21 。 10 發布了一個新的插件 jar ,以支持 Spark 中的機器學習。
目前,該 jar 支持主成分分析算法的訓練。 ETL jar 擴展了對拼花地板和 ORC 的輸入類型支持。它現在還為用戶提供了在嵌套數據上使用HashAggregate、Sort、JoinSHJ和Join BHJ的功能。除了支持嵌套數據類型外,還運行了性能測試。
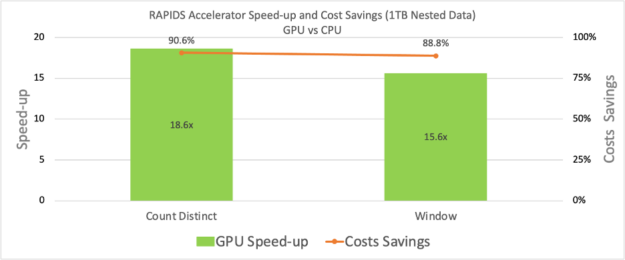
在下圖中,我們展示了使用嵌套數據類型輸入的兩個查詢的速度。 v21 中添加的其他一些有趣的特性。 10 個是pos_explode、create_map等等。請參閱 RAPIDS Apache Spark 文檔加速器 有關新功能的詳細列表。
分析和鑒定工具
除了插件之外, ApacheSpark 鑒定和分析工具的 RAPIDS 加速器還添加了多個新功能。鑒定工具現在可以報告存在的不同嵌套數據類型和寫入數據格式。它現在還支持添加連接和分離過濾器,以及基于過濾器的正則表達式和用戶名。
資格鑒定工具并不是唯一一個具有新技巧的工具:分析工具現在提供結構化輸出格式,并支持擴展和運行大量事件日志。
社區更新
我們很高興地宣布我們進入了 Azure 上的公開預覽 ,我們歡迎 Azure 用戶在 Azure Synapse 上嘗試 RAPIDS 加速版 Apache Spark 。
我們邀請您觀看我們在 11 月 8 日至 11 日舉行的 NVIDIA 旗艦活動 GTC 上的演講,了解 AI 如何改變世界。 RAPIDS 加速器團隊進行了兩次會談; 加速 ApacheSpark 概述了新功能和其他即將推出的功能。而且 通過 RAPIDS 和 NVIDIA RAPIDS 發現常見的 Apache GPU 操作 涵蓋 Apache Spark 上的許多微基準。
馬上就來
即將發布的版本將引入對 128 位十進制數據類型的支持、對主成分分析算法的推理支持以及對多級結構和映射的額外嵌套數據類型支持。
此外,請注意對基于 NVIDIA 安培體系結構的 GPU ( A100 / A30 )的 MIG 支持,這有助于提高使用 A100 運行多個 Spark 作業的吞吐量。和往常一樣,我們要感謝你們所有人使用 RAPIDS Apache 加速器 Spark ,我們期待收到你們的來信。請在 GitHub 上與我們聯系,讓我們知道如何在 Apache Spark 上使用 RAPIDS 加速器繼續改進您的體驗。
?





