
從單調乏味的高速公路到日常的社區出行,駕駛通常都很平靜。因此,在現實世界中收集的大部分自動駕駛汽車 (AV) 開發訓練數據嚴重傾斜于簡單的場景。
這給部署穩健的感知模型帶來了挑戰。AV 必須經過全面的訓練、測試和驗證,才能處理復雜的情況,而這需要涵蓋此類情況的大量數據。
模擬為在現實世界中查找和收集此類數據提供了一種替代方案,而這需要非常耗時和成本。然而,大規模生成復雜的動態場景仍然是一個重大障礙。
在最近發表的一篇論文中,NVIDIA Research 展示了一種新的基于神經輻射場(NeRF)的方法(稱為 EmerNeRF),它如何使用自監督學習準確生成動態場景。通過自監督進行訓練,EmerNeRF 不僅在處理動態對象時優于其他基于 NeRF 的方法,而且在處理靜態場景時也表現出色。有關更多詳情,請參閱 EmerNeRF:通過自監督對緊急時空場景進行分解。



在與類似的 NeRF 一起運行 EmerNeRF 時,它將動態場景重建準確率提高 15%,靜態場景提高 11%,此外,新穎的視圖合成也提高了 12%.
解決基于 NeRF 的方法中的限制
NeRF 可接收一組靜態圖像,并將其重建為逼真的 3D 場景。它們可以通過驅動日志創建高保真模擬,以進行閉環深度神經網絡 (DNN) 訓練、測試和驗證。
然而,當前基于 NeRF 的重建方法難以處理動態對象,并且已證明難以擴展。例如,雖然一些方法可以生成靜態和動態場景,但它們需要真值 (GT) 標簽才能生成。這意味著,必須使用自動標記技術或人工標注器準確概述和定義駕駛日志中的每個對象。
其他 NeRF 方法依賴于其他模型來獲得有關場景的完整信息,例如光流。
為了解決這些限制,EmerNeRF 使用自監督學習將場景分解為靜態、動態和流場。模型從原始數據中學習關聯和結構,而不是依賴人類標記的 GT 注釋。然后,它同時渲染場景的時間和空間方面,無需外部模型填補空白,同時提高準確性。

因此,雖然其他模型往往會生成過于平滑的渲染和精度較低的動態對象,但 EmerNeRF 可以重建高保真背景場景和動態對象,同時保留場景的精細細節。
| Dynamic-32 分割 | ||||||||
| ? | 場景重建 | 新型視圖合成 | ||||||
| 方法 | 完整圖像 | 僅動態 | 完整圖像 | 僅動態 | ||||
| ? | PSNR* | SSIM* | PSNR* | SSIM* | PSNR* | SSIM* | DPSNR* | SSIM* |
| D2NeRF | 24.35 | 0.645 | 21.78 | 0.504 | 2417 | 0.642 | 21.44 | 0.494 |
| HyperNeRF | 2517 | 0.688 | 22.93 | 0.569 | 24.71 | 0.682 | 22.43 | 0.554 |
| EmerNeRF | 28.87 | 0.814 | 26.19 | 0.736 | 27.62 | 0.792 | 24.18 | 0.67 |
| Static-32 拆分 | ||
| 方法 | 靜態場景重建 | |
| ? | PSNR* | SSIM* |
| iNGP | 24.46 | 0.694 |
| 街頭沖浪 | 26.15 | 0.753 |
| EmerNeRF | 29.08 | 0.803 |
EmerNeRF 方法
使用自監督學習,而非人工標注或外部模型,使 EmerNeRF 能夠繞過之前方法遇到的挑戰。
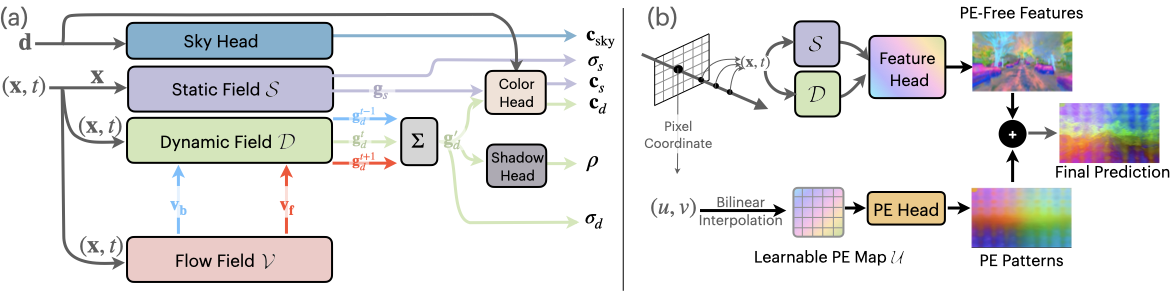
EmerNeRF 旨在將場景分解為動態元素和靜態元素。在分解場景時,EmerNeRF 還可以從動態物體(如汽車和行人)中估計流場,并使用此字段通過跨時間聚合特征來進一步提高重建質量。其他方法使用外部模型提供此類光流數據,這通常會導致不準確。
通過同時組合靜態、動態和流場,EmerNeRF 可以獨立表示高度動態的場景,從而提高準確性并支持擴展到通用數據源。
使用基礎模型添加語義理解
使用基礎模型進行額外監督,EmerNeRF 對場景的語義理解得到了進一步加強。基礎模型對物體(例如特定類型的車輛或動物)有廣泛的了解。EmerNeRF 利用視覺轉換器 (ViT) 模型(例如 DINO 和 DINOv2)將語義特征納入場景重建。
這使得 EmerNeRF 能夠更好地預測場景中的物體,并執行自動標記等下游任務。

然而,基于 Transformer 的基礎模型帶來了新的挑戰:語義特征可能會表現出與位置相關的噪聲,這可能會顯著限制下游任務的性能。

為了解決噪聲問題,EmerNeRF 使用位置嵌入分解來恢復無噪點特征圖。這解鎖了基礎模型語義特征的完整、準確表示,如圖 5 所示。
評估 EmerNeRF
詳情見EmerNeRF:通過自監督對緊急時空場景進行分解。此外,我們通過整理一個包含 120 個獨特場景的數據集來評估 EmerNeRF 的性能,這些場景被分為 32 個靜態場景、32 個動態場景和 56 個不同場景,它們適用于高速和低光照等具有挑戰性的條件。
然后,評估每個 NeRF 模型基于數據集的不同子集重建場景和合成新視圖的能力。
因此,我們發現 EmerNeRF 在場景重建和新視圖合成方面的表現始終如一,并且明顯優于其他方法,如表 1 所示。
EmerNeRF 的表現也優于專為靜態場景設計的方法,這表明將場景分解為靜態和動態元素的自監督式分析可改善靜態重建和動態重建。
結束語
只有能夠準確再現現實世界,AV 模擬才會有效。隨著場景變得更加動態和復雜,對保真度的需求也在增加,實現這一目標的難度也在增加。
與之前的方法相比,EmerNeRF 能夠更準確地表示和重建動態場景,無需人工監督或外部模型。這使得能夠大規模重建和修改復雜的駕駛數據,解決自動駕駛訓練數據集中的當前不平衡問題。
我們迫切希望研究 EmerNeRF 釋放的新功能,包括端到端駕駛、自動標記和模擬。
如需了解詳情,請訪問 EmerNeRF 項目頁面 并閱讀論文 EmerNeRF:通過自監督對緊急時空場景進行分解。
?






