
人工智能正在改變每一個行業,實現傳統軟件無法實現的強大的新應用程序和用例。隨著人工智能的不斷擴散,以及人工智能模型的規模和復雜性的不斷增加,人工智能計算性能的重大進步需要跟上。
這就是 NVIDIA 平臺的所在地。
憑借跨越芯片、系統、軟件甚至整個數據中心的全堆棧方法, NVIDIA 為所有人工智能工作負載(包括人工智能培訓)提供了最高的性能和最大的通用性。NVIDIA 在 MLPerf 培訓 v1 中展示了這一點。 1 ,行業標準的最新版本,經同行評審的基準套件,用于測量跨廣泛網絡的 ML 培訓性能。由 NVIDIA A100 GPU 核心張量 提供動力的系統,包括 Azure NDm A100 v4 云實例 ,提供了圖表上的最佳結果,創造了新的記錄,并且是唯一完成所有八項 MLPerf 訓練測試的系統。
所有主要的云服務提供商都提供了由 A100 供電的NVIDIA GPU 加速實例,使公共云成為 NVIDIA 平臺的性能和能力的一個很好的地方。在這篇文章中,我將展示一種基于 A100 選擇當前一代實例的策略,這種策略不僅可以在云中提供最快的人工智能模型訓練時間,而且是最具成本效益的。
NVIDIA A100 渦輪增壓人工智能培訓
NVIDIA A100 是基于 Ampere architecture ,它包含了與前一代 NVIDIA V100 相比,如第三代張量核心、新一代 NVLink 和更大的內存帶寬加速 AI 培訓的主機創新。這些增強帶來了巨大的性能飛躍,從而縮短了訓練各種人工智能網絡的時間。
在本文中,我使用 ResNet-50 表示圖像分類, BERT 用于自然語言處理, DLRM 用于推薦系統。

圖 1 。NVIDIA A100 與NVIDIA V100 相比,大大縮短了訓練人工智能模型的時間。
GPU 服務器:雙插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB 和雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司機: 465.19.01 ;數據集: ResNet-50 v1 的 ImageNet2012 。 5 號, v1 小隊。 1 對于 BERT 大型微調, DLRM 的標準 TB 數據集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量大小: A100 , V100 = 65536 。
更快的培訓時間加快了洞察的速度,最大限度地提高了組織數據科學團隊的生產力,并更快地部署了經過培訓的網絡。還有另一個重要的好處:降低成本!
云實例通常按單位時間定價,按需使用通常按小時定價。培訓模型的成本是每小時實例定價和培訓模型所需時間的乘積。
雖然選擇時薪最低的實例很有誘惑力,但這可能不會導致最低的培訓成本。以每小時計算,一個實例可能會稍微便宜一些,但訓練一個模型所需的時間要長得多。培訓的總成本比價格更高的實例更快地完成工作的成本要高。此外,等待較慢的實例完成訓練運行也會浪費時間。
在前面顯示的性能數字中,NVIDIA A100 可以比 NVIDIA V100 更快地訓練模型。這幾乎是 BERT 大微調的 3 倍。與此同時,來自主要云服務提供商的 100 個基于實例的定價通常只比上一代基于 V100 的同類產品有適度的溢價。
在本文中,我將討論與基于 V100 的云實例相比,使用基于 100 的云實例如何在培訓 AI 模型時節省時間和金錢。
將績效轉化為節約
考慮到人工智能訓練的巨大計算需求,通常使用多個 GPU 協同工作來訓練模型,以顯著減少訓練時間。
NVIDIA 平臺已經被設計為提供業界領先的每加速器性能,并達到最佳性能和最高的 ROI 在規模上,由于技術 NVLink 和 NVSwitch 。這就是為什么在本文中,我估計與八個 NVIDIA V100 GPU 實例相比,八個 NVIDIA A100 GPU 實例可以節省成本。
在本次分析中,我估計了培訓 ResNet-50 、微調 BERT Large ,以及在三大云服務提供商 Amazon Web 服務、谷歌云平臺和 Microsoft Azure 上培訓基于 V100 和 A100 的實例的 DLRM 的相對成本。
| CSP | Instance | GPU Configuration |
| Amazon Web Services | p4d.24xlarge | 8x NVIDIA A100 40GB |
| ? | p3dn.24xlarge | 8x NVIDIA V100 32GB |
| ? | p3.16xlarge | 8x NVIDIA V100 16GB |
| Google Cloud Platform | a2-highgpu-8g | 8x NVIDIA A100 40GB |
| ? | n1-highmem-96 | 8x NVIDIA V100 16GB |
| Microsoft Azure | Standard_ND96asr_v4 | 8x NVIDIA A100 40GB |
| ? | ND40rs v2 | 8x NVIDIA V100 32GB |
估算方法
為了估計云實例的訓練性能,我使用測量的時間在 NVIDIA DGX 系統上訓練數據,該系統具有與實例中的配置相對應的 GPU 配置。由于與這些云合作伙伴進行了深入的工程合作, NVIDIA 支持的云實例的性能應該與 DGX 系統上可實現的性能相似。
然后,根據測量的訓練時間數據,我使用按需、每小時實例定價來估計訓練 ResNet-50 、微調 BERT 大型和訓練 DLRM 的成本。
估計成本節約
以下圖表都講述了一個類似的故事:無論您選擇哪家云服務提供商,在培訓一系列人工智能模型時,基于最新的 NVIDIA A100 GPU 選擇實例都可以轉化為顯著的成本節約。這是,即使在每小時的基礎上,基于NVIDIA A100 的實例比使用前一代 V100 GPU 的實例更昂貴。
Amazon 網絡服務:
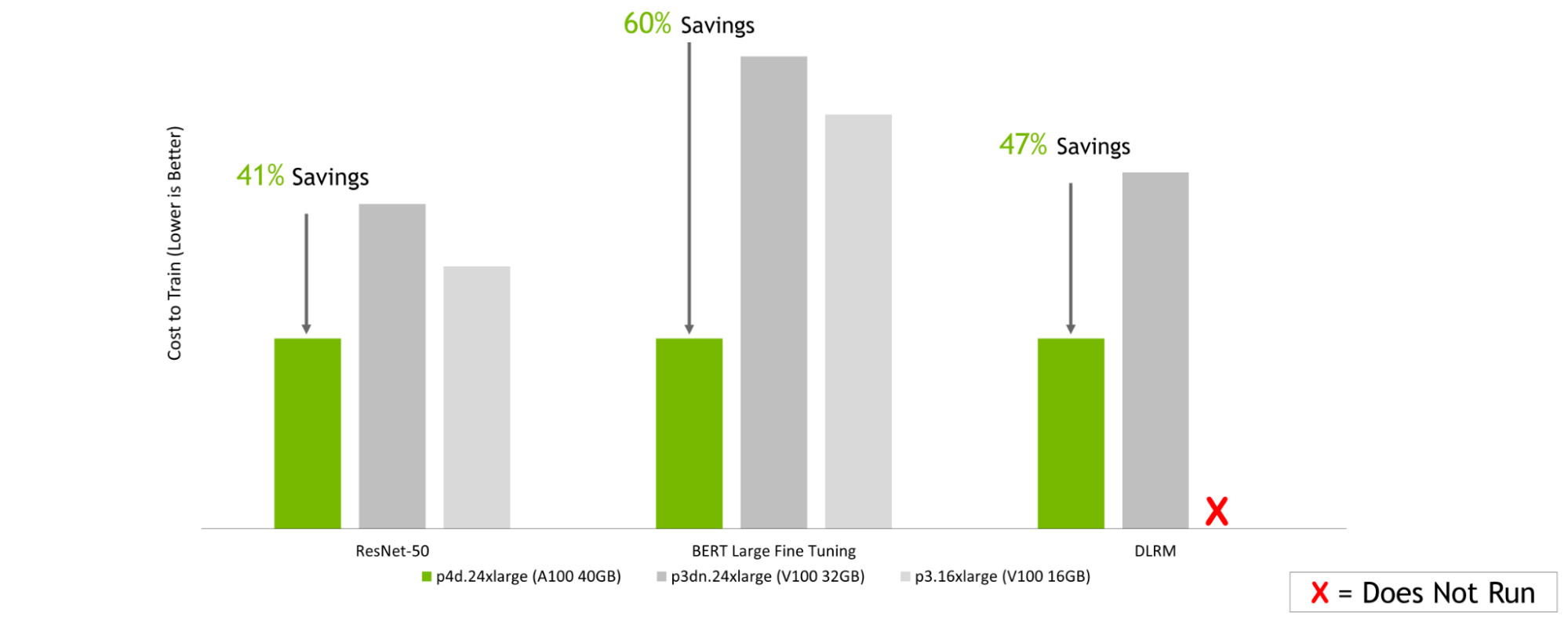
GPU 服務器:雙插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司機: 465.19.01 ;數據集: ResNet-50 v1 的 Imagenet2012 。 5 號, v1 小隊。 1 對于 BERT 大型微調, DLRM 的標準 TB 數據集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上運行的性能數據以及截至 2022 年 2 月 8 日的按需實例定價估算成本。
谷歌云平臺 :
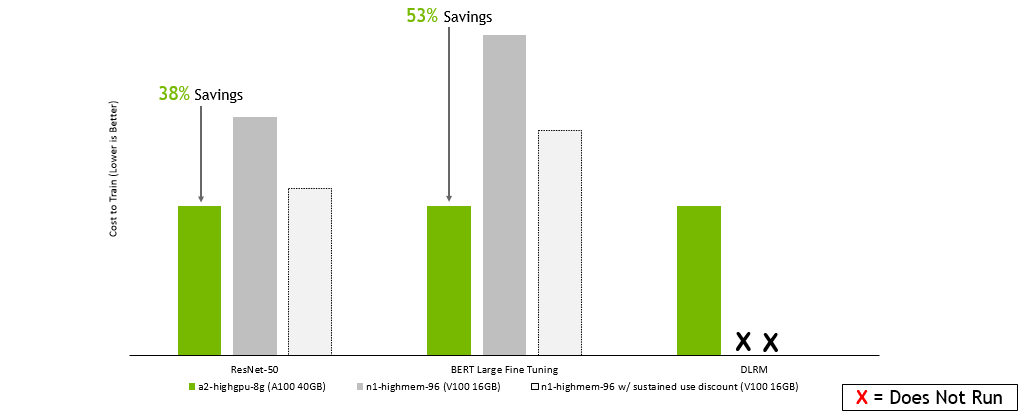
GPU 服務器:雙插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司機: 465.19.01 ;數據集: ResNet-50 v1 的 ImageNet2012 。 5 號, v1 小隊。 1 對于 BERT 大型微調, DLRM 的標準 TB 數據集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上運行的性能數據以及截至 2022 年 2 月 8 日的按需實例定價估算成本。
Microsoft Azure :
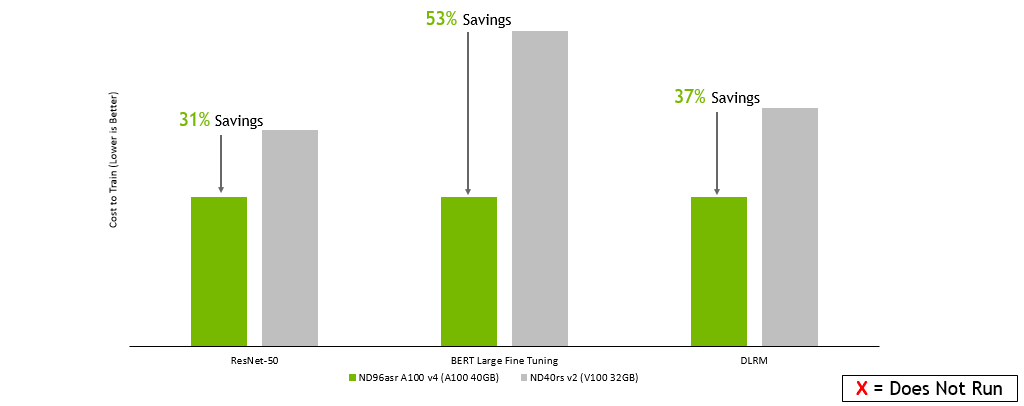
GPU 服務器:雙插槽 AMD EPYC 7742 @ 2.25GHz w / 8x NVIDIA A100 SXM4-40GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-32GB ,雙插槽 Intel Xeon E5-2698 v4 @ 2.2GHz w / 8x NVIDIA V100 SXM2-16GB 。框架: TensorFlow 用于 ResNet-50 v1 。 5 、 PyTorch 表示 BERT ——大型和 DLRM ;精度:混合+ XLA 用于 ResNet-50 v1 。 5 ,混合用于 BERT – 大型和 DLRM 。NVIDIA 司機: 465.19.01 ;數據集: ResNet-50 v1 的 ImageNet2012 。 5 號, v1 小隊。 1 對于 BERT 大型微調, DLRM 的標準 TB 數據集, ResNet-50 的批量大小: A100 , V100 = 256 ; BERT 大批量: A100 = 32 , V100 = 10 ; DLRM 的批量: A100 , V100 = 65536 ;使用在早期配置上運行的性能數據以及截至 2022 年 2 月 8 日的按需實例定價估算的成本。
除了提供更低的培訓成本和為用戶節省大量時間之外,使用當前一代實例還有另一個好處:它們支持全新的人工智能用例。例如,基于人工智能的推薦引擎正變得越來越流行,NVIDIA GPU 常用于對其進行培訓。圖 5 總結了 100 個實例跨不同云提供商提供的成本和時間節約:
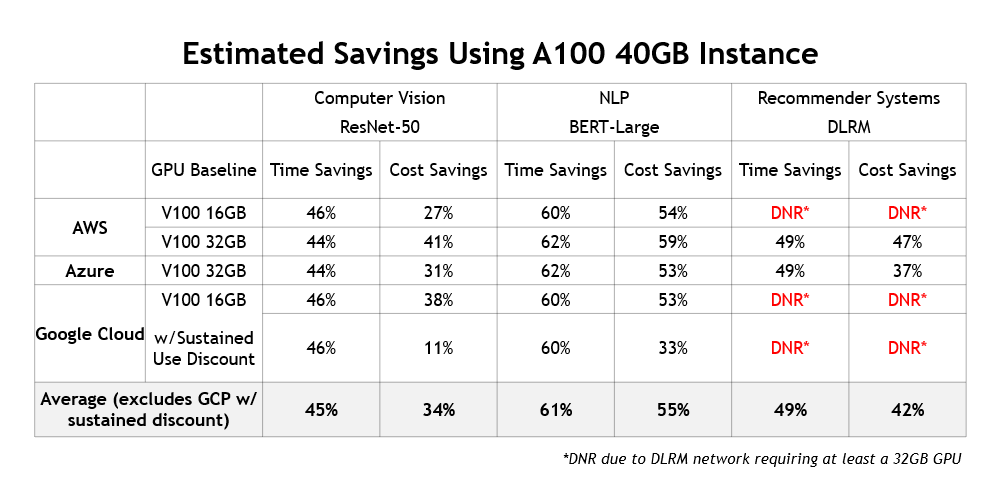
更高的性能也意味著更高的節約
這里展示的這些結果表明,與使用上一代 GPU 的舊版實例相比,當前一代 NVIDIA GPU 加速實例提供的性能要高得多,超過了每小時定價差異。
基于最新 NVIDIA A100 GPU 的實例不僅可以通過減少培訓時間來最大限度地提高數據科學團隊的生產力,而且是在云中培訓模型的最經濟高效的方式。
要了解更多關于在云中使用 NVIDIA 加速的選項,請參閱 Cloud Computing 。
?





