近日,繼成為計算機視覺、自然語言處理和語音識別領域的主流機器學習技術之后,深度學習又應用于推薦系統領域。
訓練深度學習推薦系統并非易事,我們在[u]上一篇博文[/u]中曾探討過這些挑戰。
深度學習推薦模型通常具有一個淺層架構,幾乎沒有全連接層和大型用戶/項目嵌入表(大小可達數 GB 或 TB)。
為應對這些挑戰,NVIDIA 開發了開源框架 NVIDIA Merlin,通過 GPU 端到端(從 ETL 到訓練再到部署)擴展和加速深度學習推薦系統。
這是此系列博文的第一部分,介紹了使用 HugeCTR 訓練大型推薦系統的神經網絡所面臨的挑戰以及相應的解決方案。
Merlin HugeCTR 是一個推薦系統特定框架,可加快在 GPU 上大規模訓練和部署復雜的深度學習模型的速度。
嵌入表是否未超出內存?
您的第一反應可能是“是的,我想訓練深度學習推薦系統,但是如何才能讓嵌入表不超出 GPU 顯存”。
沒錯,這是我們在訓練大型深度學習推薦模型時遇到的一個主要挑戰。
嵌入表可達 100GB 甚至數 TB,而且不適合單個 GPU 或主機內存。
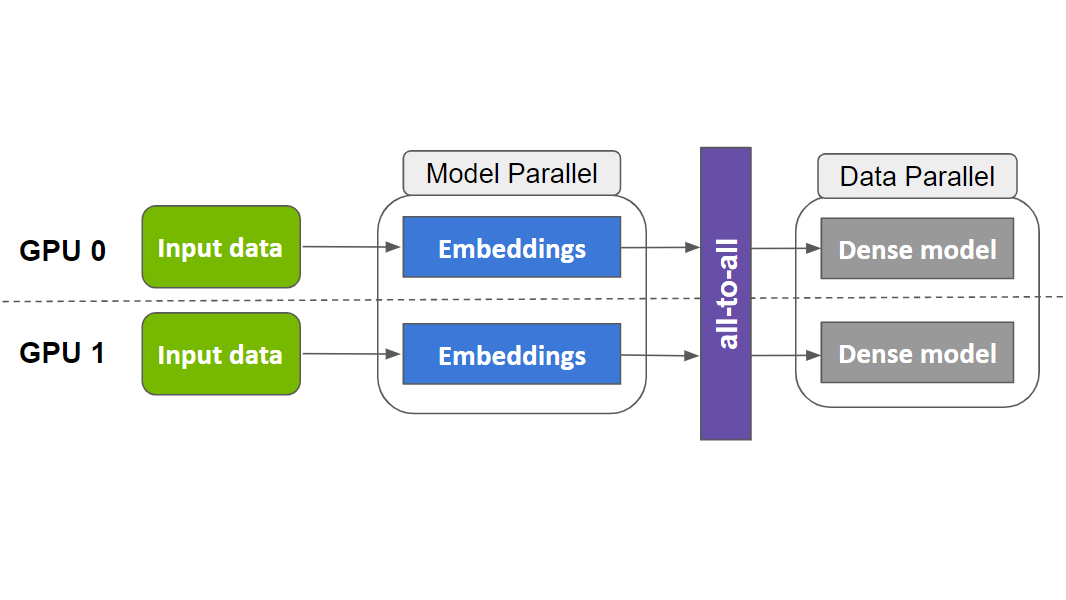
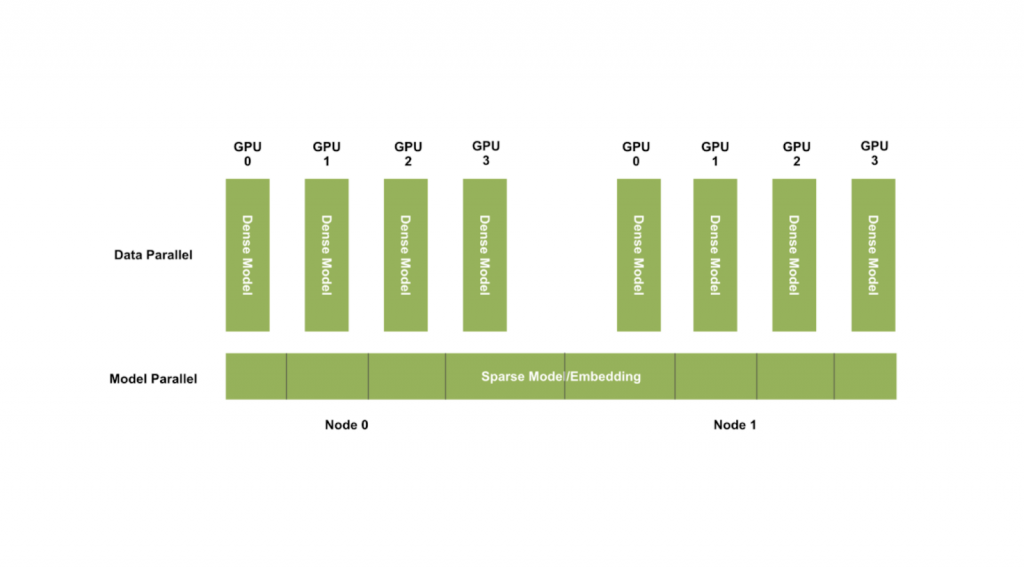
HugeCTR 利用數據和模型并行性來擴展訓練,并將一個嵌入表分布于多個 GPU 之上(如下圖所示),從而解決了這一問題。
由于全連接層只有少數“幾個”參數,因此每個 GPU 都包含一個用于數據并行訓練的權重副本。
此外,還可將大型嵌入表分布于多個 GPU 或多個節點之上。
根據具體的批量,將相應地向前/向后傳遞,并更新所有參數。
HugeCTR 以這種方式通過模型并行(嵌入層)和數據并行(稠密層或 Dense Layer)來擴展訓練。
通過實驗,我們發現與 TensorFlow CPU 版本相比,速度提高了 114 倍,并且能夠將嵌入表的大小擴展到 10 TB。
能否在其他深度學習框架中使用同一策略呢?
HugeCTR 已針對推薦系統進行高度優化,其核心價值在于能夠在多個 GPU 上實現良好擴展。
實現這些策略并非易事,需要使用 CUDA C++ 進行自定義實現。
同時,TensorFlow 是最熱門的通用深度學習框架之一,擁有強大的用戶群。
我們希望向社區提供相應功能,因此將 HugeCTR 嵌入導出為 TensorFlow 自定義運算,以便它可以與客戶基于 TensorFlow 構建的現有代碼和管道進行互操作。
如下所示,使用 HugeCTR TensorFlow 運算只需更改一行,并且可輕松地使用 TensorFlow Keras 模型。
查看我們的 Jupyter 筆記本,了解如何通過創建新 keras 層將 HugeCTR 嵌入集成到 DeepFM 模型中。
如果您有興趣了解更多詳細信息(例如其基礎機制和性能),請觀看我們在 GTC(GPU 技術大會)2021 的相關演講。
總體而言,在單個 DGX A100 上,我們的 HugeCTR TensorFlow 運算速度比原始 TensorFlow 嵌入層快了 10 倍之多。
在具有 7 個全連接層的端到端訓練方面,它將速度提高了 3.5 倍。
嵌入表仍超出可用內存時可在單臺設備上訓練
推薦系統的嵌入表可達 100GB 甚至數 TB,即使是多 GPU 也無法滿足 GPU 顯存需求。
隨著用戶和服務項目數量的增加,表大小也會快速增加。
我們在上文討論過,HugeCTR 可以將模型擴展為多個節點,但是如果公司的嵌入表大小超過其 GPU 總內存容量,則公司可能無法一直擴展 GPU 集群。
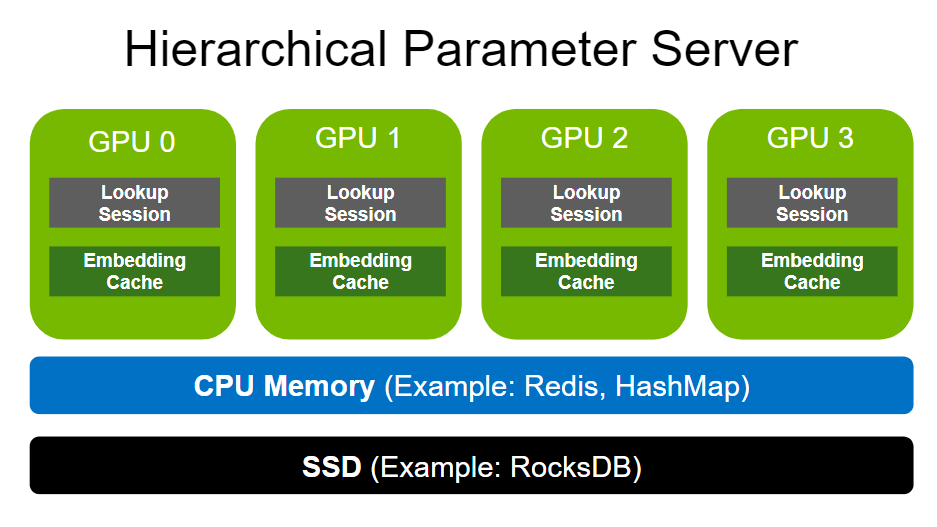
HugeCTR 的 Embedding Training Cache (ETC) 功能支持在單臺設備上訓練深度學習推薦系統,即使嵌入表超出 GPU 顯存也可以。
它通過粗粒度方式解決了上述問題。
ETC 將部分冷模型存儲在外存(MOS),有利于在單臺設備(如 DGX A100)上訓練 TB 級嵌入表。
它假設數據集被分為多個子數據集,每個子數據集都有用戶指定的樣本數量,并將分類特征(鍵集)的唯一值從每個子數據集中提取出來。
例如,用戶可能想要確定各子數據集是否具有一個月的數據量,以便分類特征可以生成一個可加載給定 GPU 顯存容量的嵌入表。
然后,經過多次傳遞完成訓練,每次傳遞都使用不同的鍵集和子數據集對。
同樣,model_subscriber.update() 在每次傳遞開始時所執行的操作類似于進程上下文切換。
它將在上一次傳遞中訓練的嵌入向量轉儲到 SSD 等二級存儲中。
之后,它使用當前鍵集將新的嵌入向量加載到設備內存,以便可以在當前傳遞中進行訓練。
這樣一來,我們就可以有效地訓練大小超出可用設備內存容量的大型嵌入表了。
其理念是,將大塊數據遷移到 GPU 非常高效。
對于每個子數據集,將加載所需的嵌入向量并執行多個批量更新。
之后,在參數服務器中同步模型參數。
由于嵌入向量的訪問通常具有冪律分布,因此對于每個子集,我們只需要一小部分嵌入表。
在子數據集中對完整數據集進行迭代時,我們仍然會不斷訓練所有嵌入向量。
HugeCTR ETC 僅可在 Python 中使用。
我們提供了一個Jupyter notebook,其中描述如何基于我們的低級 Python API 啟用和使用它。
我們正在積極研究如何有效地利用設備內存帶寬,同時也在努力探求如何簡化 SSD 和設備內存之間的路徑。
試用 NVIDIA Merlin 和 HugeCTR,擴展推薦系統流水線
我們在 GitHub 存儲庫(NVIDIA Merlin、NVIDIA NVTabular 和 NVIDIA HugeCTR)中提供了許多適用于 HugeCTR 的示例或 ETL 訓練-推理端到端示例。
有關 HugeCTR 的更多信息,請參閱我們的用戶指南。
HugeCTR 提供了多種常用深度學習模型的參考實施,例如 Wide&Deep、深度交叉網絡和深度學習推薦模型 (DLRM)。
如果您在使用 HugeCTR 時遇到任何問題或有任何功能請求,可以在我們的存儲庫中提交 GitHub 問題。
這是我們 HugeCTR 系列中關于“擴展和加速大型深度學習推薦系統”的第一篇博文。
在下一篇博文中,我們將介紹 Python API 和實際操作示例。
敬請關注!