
眾所周知, GPU 是大型機器學習( ML )應用程序的典型解決方案,但如果 GPU 應用于 AI 管道數據的早期階段,該怎么辦?
例如,如果不必為每個管道處理階段切換集群配置,則會更簡單。您可能仍然有一些問題:
- 從成本角度來看,這是否可行?
- 對于一些接近實時處理的數據處理時間預算,您還能滿足 SLA 嗎?
- 優化這些 GPU 集群有多困難?
- 如果您為一個階段優化了配置,那么其他階段也會這樣嗎?
在 At&T ,當我們的數據團隊在規模上平衡簡單性的同時管理云成本時,這些問題就出現了。我們還觀察到,我們的許多數據工程師和科學家同事都不知道 GPU 是一個有效和高效的基礎設施,可以在其上運行更普通的 ETL ,并具有工程階段的特點。
與 GPU 配置相比, CPU 的相對性能也不清楚。我們在 at & T 的目標是運行一些典型的配置示例以了解差異。
在本文中,我們將從速度、成本和完整管道的簡單性方面分享我們的數據管道分析。我們還提供有關設計考慮的見解,并解釋我們如何優化 GPU 集群的性能和價格。優化來自于使用 RAPIDS accelerator for Apache Spark, 這一開源庫,它支持 GPU 加速 ETL 和特性工程。
SPOILER ALERT :我們驚喜地發現,至少對于所研究的示例來說,在每個管道階段使用 GPU 證明是更快、更便宜、更簡單的!
用例
AI 管道的數據包括多個批處理階段:
- 數據準備或聯合
- 轉型
- 功能工程
- 數據提取
批處理涉及處理包含數萬億條記錄的大量數據。批處理作業通常針對成本或性能進行優化,具體取決于該用例的 SLA 。
針對成本進行優化的批處理作業的一個很好的例子是從調用記錄中創建功能,這些功能將用于訓練 ML 模型。另一方面,用于檢測欺詐的實時推理用例針對性能進行了優化。 GPU 經常被忽視,對于 AI / ML 管道的這些批處理階段來說,它被認為是昂貴的。
這些批處理作業通常涉及大型聯接、聚合、排名和轉換操作。可以想象, AT & T 有許多涉及批量處理的數據和 AI 用例:
- 網絡規劃和優化
- 欺詐
- 銷售和營銷
- 稅
根據用例的不同,這些管道可以使用 NVIDIA GPU 和 RAPIDS Accelerator for Apache Spark 來優化成本或提高性能。
為了進行此分析,我們查看了兩個到 AI 管道的數據。第一個用例將呼叫記錄的特征工程用于營銷用例,第二個用例執行復雜稅務數據集的 ETL 轉換。
使用 GPU 加速特征工程和轉換
高效地將數據擴展到 AI 管道仍然是數據團隊的需要。高成本的管道每月、每周甚至每天都要處理數百 TB 到 PB 的數據。
在檢查效率時,重要的是確定所有 ETL 和特征工程階段的優化機會,然后比較速度、成本和管道簡單性。
對于我們的數據管道分析,我們比較了三個選項:
- 各種基于 CPU 的 Spark 集群解決方案
- GPU Spark 集群上的 RAPIDS accelerator for Apache Spark
- 使用 Databricks 最新發布的 Photon 引擎的 Apache Spark CPU 集群
為了衡量我們離最佳成本有多遠,我們使用 AT & T 的開源 GS-lite 解決方案比較了一個基本 VM 解決方案,該解決方案使您能夠編寫 SQL ,然后將其編譯為 C ++。
如前所述,在優化每個解決方案后,我們發現在 GPU 集群上運行的 Apache Spark 加速器具有最佳的總體速度、成本和設計簡單性權衡。
在下面的部分中,我們將討論為每種類型選擇的優化和設計注意事項。
優化 AI / ML 管道解決方案的設計考慮
為了比較這三個潛在解決方案的性能,我們進行了兩個實驗,每個實驗針對選定的用例。對于每種情況,我們都優化了不同的參數,以深入了解速度、成本和設計是如何受到影響的。
示例 1 :通過聚合為呼叫記錄優化簡單組用例
對于第一個特性工程示例,我們選擇從每月包含近 3 萬億條記錄(行)的調用記錄數據集創建特性(表 1 )。此數據預處理用例是幾個銷售和營銷 AI 管道中的基本構建塊,例如客戶細分、預測客戶流失以及預測客戶趨勢和情緒。在這個用例中有各種各樣的數據轉換,但其中許多都涉及簡單的“分組”聚合,例如下面的聚合,我們希望對其進行優化處理。
res=spark.sql("""
Select DataHour, dev_id,
sum(fromsubbytes) as fromsubbytes_total,
sum(tosubbytes) as tosubbytes_total,
From df
Group By DataHour, dev_id
""")
從數據中獲取見解并進行數據分析仍然是許多企業的最大痛點之一。這并不是因為缺乏數據,而是因為在數據準備和分析上花費的時間仍然是數據工程師和數據科學家的障礙。
以下是此預處理示例中的一些關鍵基礎架構挑戰:
- CPU 集群上的查詢執行時間過長,導致超時問題。
- 計算成本昂貴。
| Days | # of Rows | Size (Bytes) |
| 1 | ~110 Billion | >2 TB |
| 7 | ~800 Billion | ~16 TB |
| 30 | ~3 Trillion | ~70 TB |
此外,這個調用記錄用例在壓縮類型方面有額外的實驗維度。數據通過某種形式的壓縮從網絡邊緣到達云端,我們可以指定并評估折衷。因此,我們試驗了幾種壓縮方案,包括 txt / gzip 、 Parquet / Z 標準和 Parquet / Snappy 。
Z 標準壓縮的文件大小最小(在本例中約為一半)。正如我們稍后所展示的,我們發現了與 Parquet / Snappy 更好的速度/成本權衡。
接下來,我們考慮了集群的類型,包括每個 VM 的內核數、 VM 數、工作節點的分配,以及是使用 CPU 還是 GPU 。
- 對于 CPU 集群,我們選擇了能夠處理工作負載的最低數量的核心,即 VM 和工人的最低數量,以防止資源過度分配。
- 對于 GPU ,我們使用了 RAPIDS Accelerator 調優指南[spark rapids tuning],該指南針對每個執行器的并發任務、 maxPartitionBytes 、 shuffle 分區和并發 GPU 任務提供了分級建議。
在 GPU 上實施數據處理后的一個目標是確保所有關鍵特征工程步驟都保留在 GPU 上(圖 1 )。

示例 2 :為稅務數據集優化多個 ETL 和功能創建階段
示例 2 的用例允許我們比較 ETL 、特性創建和 AI 的許多不同轉換和處理階段。每個階段有不同的記錄體積大小(圖 2 )。

這種具有多個階段的 ETL 管道是數據存儲在豎井中的企業中的常見瓶頸。大多數情況下,海量數據處理需要使用模糊邏輯查詢和連接來自兩個或多個數據源的數據。如圖 2 所示,盡管我們一開始只有 2000 萬行數據,但隨著數據處理階段的推移,數據量呈指數級增長。
如示例 1 所示,在比較 CPU 和 GPU 時,設計考慮的是每個 VM 的內核數、 VM 數和工作節點的分配。
后果
在為示例 1 和 2 中所示的用例嘗試了不同的核心、工作機和集群配置之后,我們收集了結果。我們確保在分配的時間內完成任何特定 ETL 作業,以跟上數據輸入數據速率。兩者中最好的方法都具有最低的成本和最高的簡單性。
示例 1 結果
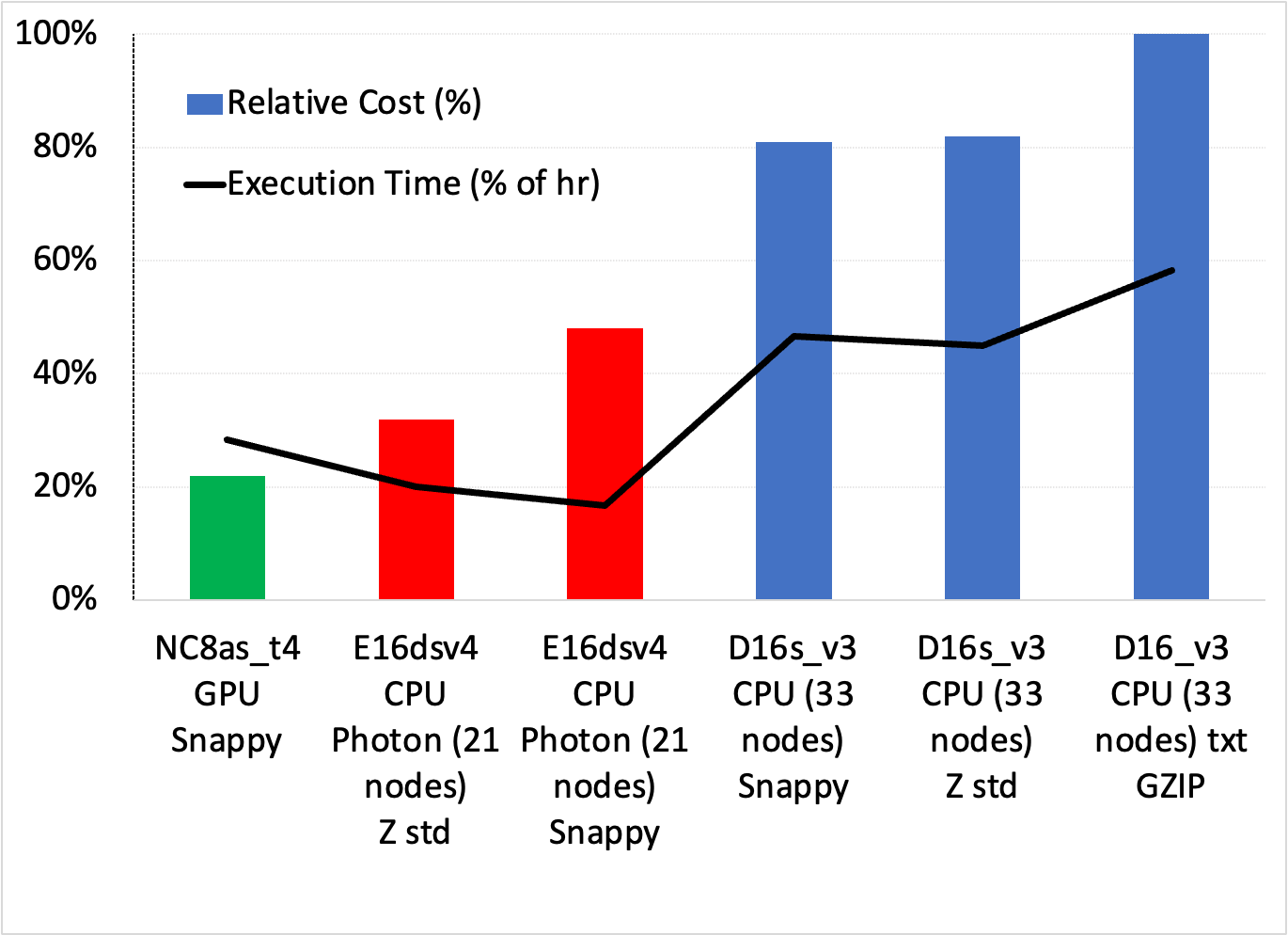
圖 3 顯示了調用記錄用例中簡單分組聚合的一系列設置之間的成本/速度權衡。您可以進行幾個觀察:
- 成本最低、最簡單的解決方案是使用具有 Snappy 壓縮功能的 GPU 集群,它比成本最低的 Photon 解決方案便宜約 33% ,比最快的 Photon 方案便宜近一半。
- 所有標準 Databricks 集群在成本和執行時間方面都表現較差。光子是最好的 CPU 溶液。
雖然圖 3 中沒有顯示,但 GS-lite 解決方案實際上是最便宜的,只需要兩個 VM 。
示例 2 結果
與示例 1 一樣,我們使用 Databricks 10.4 LTS ML 運行時為五個 ETL 和 AI 數據處理階段嘗試了幾個 CPU 和 GPU 集群配置。表 2 顯示了得到的最佳配置。
| Configuration | CPU | GPU |
| Worker type | Standard_D13_v2 56 GB memory, 8 cores, min workers 8, max workers 12 | Standard_NC8as_T4_v3 56 GB memory, 1 GPU, min workers 2, max workers 16 |
| Driver type | Standard_D13_v2 56 GB memory, 8 cores | Standard_NC8as_T4_v3 56 GB memory, 1 GPU |
這些配置產生了有利于 GPU 的相對成本和執行時間(速度)性能(圖 4 )。
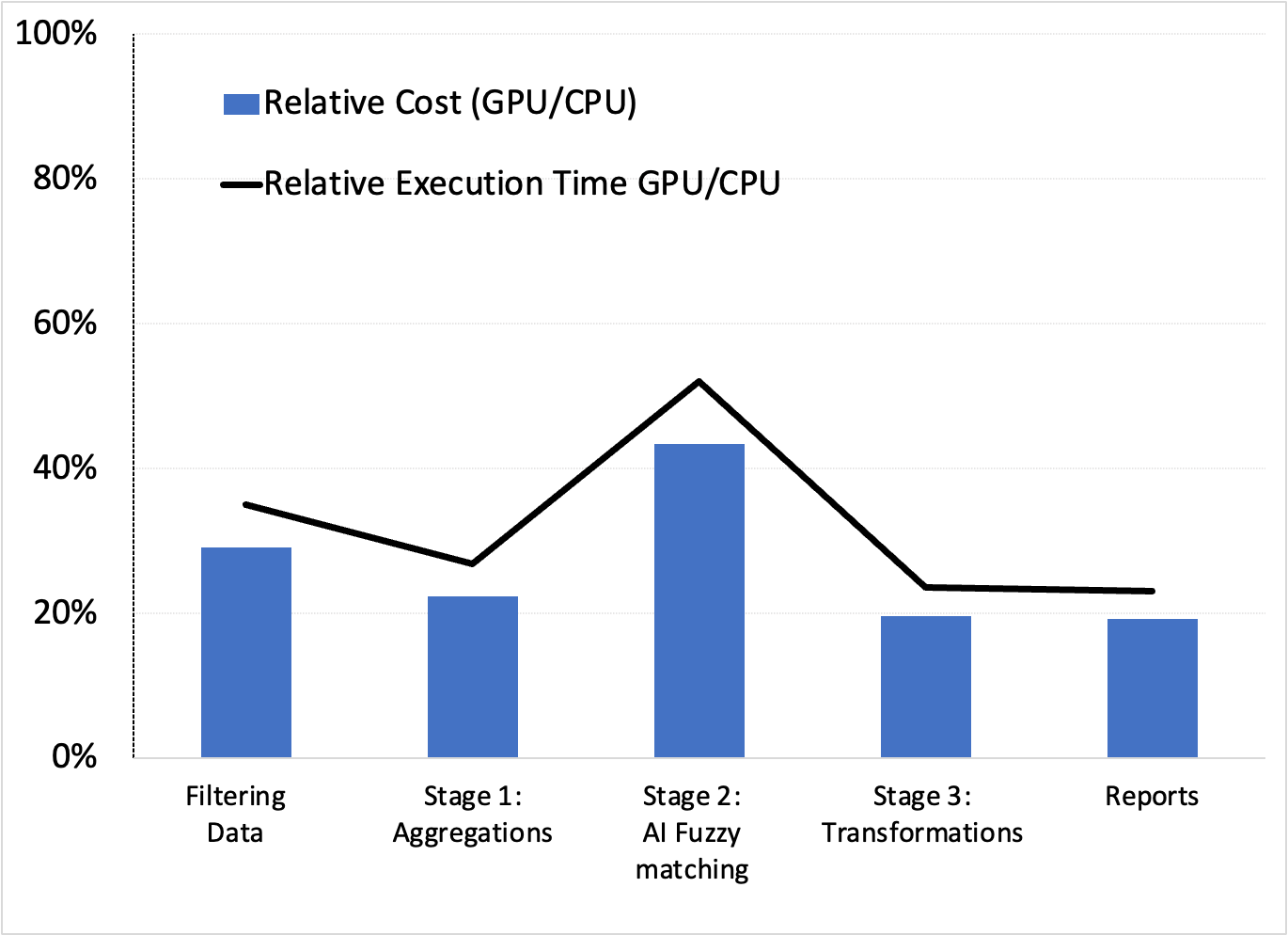
雖然此處未顯示,但我們確認,示例 1 中使用 XGBoost 建模的 AI 管道的下一階段也受益于 GPU 和 RAPIDS Accelerator for Apache Spark 。這證實了 GPU 可能是最好的端到端解決方案。
結論
雖然并非所有 AT & T 數據和 AI 管道都詳盡無遺,但基于 GPU 的管道似乎在所有示例中都是有益的。在這些情況下,我們能夠減少數據準備、模型培訓和優化的時間。這導致在更簡單的設計上花費更少的錢,因為沒有跨階段的配置切換。
我們鼓勵您嘗試將自己的數據傳輸到 AI 管道,特別是如果您已經在使用 GPU 進行 AI / ML 培訓。您可能還會發現 GPU 是您的“首選”解決方案,更簡單、更快、更便宜!
有興趣了解更多關于這些用例和實驗的信息,或者獲得如何使用 RAPIDS Accelerator for Apache Spark 縮短數據處理時間的提示嗎?注冊免費的 AT & T GTC 會話 How AT&T Supercharged their Data Science Efforts 。
?






