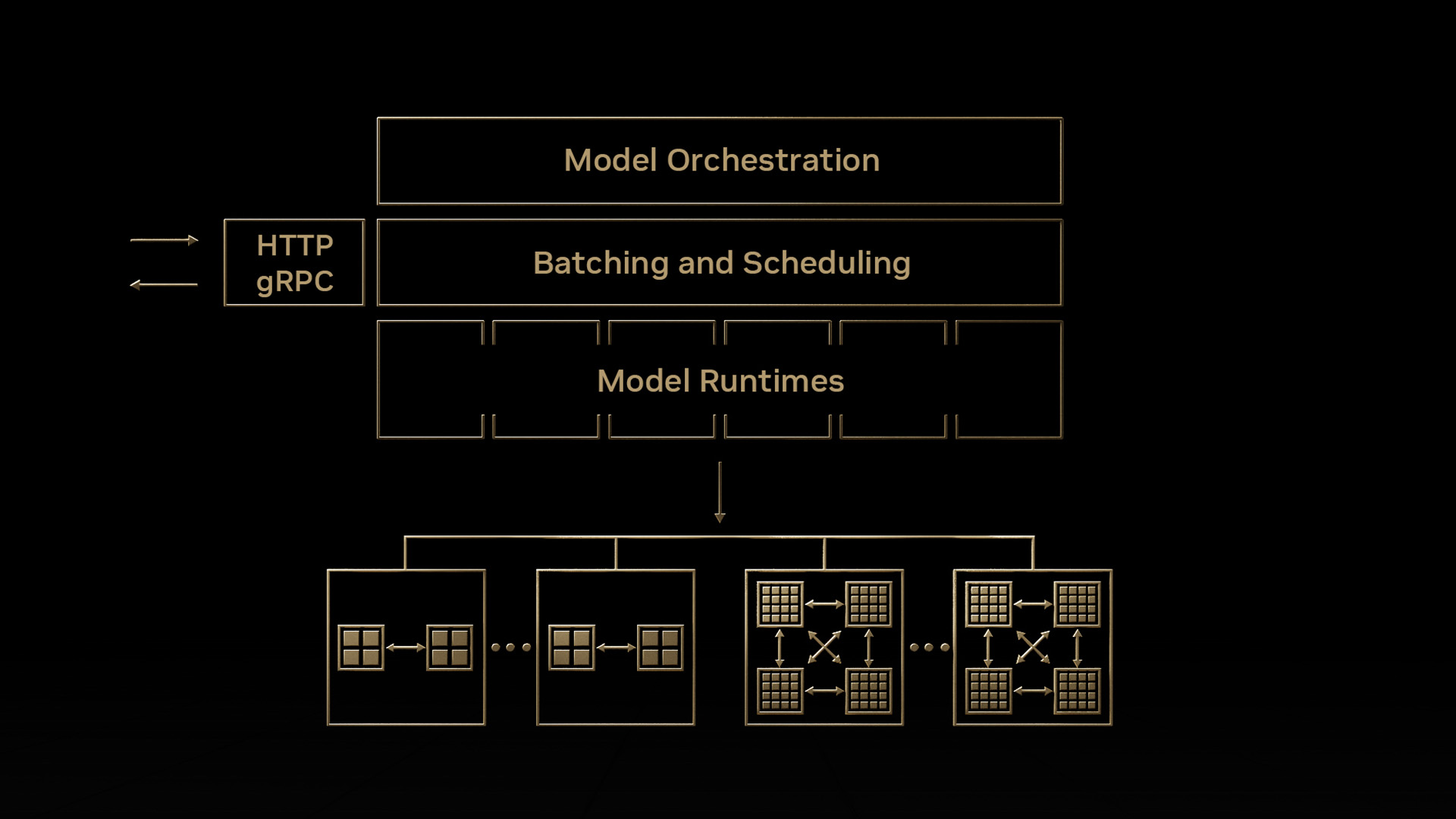
組織正在以前所未有的速度將機器學習(ML)集成到整個系統和產品中。他們正在尋找解決方案,以幫助處理在生產規模部署模型的復雜性。
NVIDIA Triton Management Service (TMS) 是 NVIDIA AI Enterprise 獨家提供的一款新產品,有助于實現這一目標。具體來說,它有助于管理和協調一支由 NVIDIA Triton Inference Servers 在 Kubernetes 集群中運行的團隊。TMS 使用戶能夠擴展其 NVIDIA Triton 部署,以高效地處理各種各樣的工作負載。它還改善了開發人員協調所需資源和工具的體驗。
本文探討了開發人員和 MLOps 團隊在大規模部署模型時面臨的一些最常見的挑戰,以及 NVIDIA Triton 管理服務如何解決這些挑戰。
擴展人工智能模型部署的挑戰
任何規模的模型部署都會帶來一系列挑戰。開發人員需要考慮如何平衡各種框架、模型類型和硬件,同時最大限度地提高性能并與環境的其他組件接口。
NVIDIA Triton 是一個強大的解決方案,旨在處理各種問題,并從部署的機器中獲取最佳的吞吐量和性能。然而,隨著組織將人工智能納入更多的核心工作流程,推理工作負載的數量和大小可能會超過單個服務器所能處理的。因此,模型部署必須進行擴展。新的部署規模帶來了一系列新的挑戰,包括管理分布式推理工作負載的成本和復雜性。
部署成本
隨著部署更多的模型并為它們找到更多的用例,很快就有必要擴展部署以利用資源集群。一個簡單的方法是在添加更多模型時保持集群的線性擴展,使所有模型始終處于活動狀態并隨時準備進行推理。
然而,這不是一種具有無限規模潛力的方法。當您可以選擇提高當前可用硬件的利用率時,專注于擴展服務集群的容量可能會導致不必要的開支。您還必須應對在本地添加更多資源或在云中遇到配額限制的后勤挑戰。
其他擴展方法可能看起來成本較低,但可能會導致急劇的性能權衡。例如,您可以等待將模型加載到內存中,直到推理請求到來,這會導致等待時間過長,并延長首次推理的時間。或者,您可能會過度投入計算資源,導致執行過程中上下文切換帶來的性能損失,以及設備內存不足帶來的錯誤。
通過對工作負載進行仔細的預規劃和主機代管,您可以避免其中一些最糟糕的問題。盡管如此,這只會加劇大規模部署的第二個主要問題。
操作復雜性
在小規模和需要模型編排的流程開發的早期,手動配置和部署模型是可行的。但是,隨著 ML 部署的擴展,協調所有必要的資源變得越來越具有挑戰性。您需要管理何時啟動或擴展服務器,在哪里加載特定模型,如何將請求路由到正確的位置,以及如何在環境中處理模型生命周期。
確定哪些模型可以共存為這些部署增加了另一層復雜性。如果同時加載到同一設備中,大型型號可能會超過 GPU 或 CPU 的內存容量。一些框架(如 PyTorch 和 TensorFlow )即使在卸載模型后也會保留分配給它們的任何內存,這導致當來自這些框架的模型與來自其他框架的模型一起運行時,利用率低下。
通常,不同的模型在資源分配和服務器配置方面會有不同的要求,因此很難在單一類型的部署上實現標準化。
具有成本效益的人工智能模型部署和擴展
Triton 管理服務通過三種主要策略來解決這些挑戰:簡化 Triton 推理服務器部署,最大限度地提高資源使用率,以及監控/擴展 Triton Triton 推理服務器。
簡化部署
TMS 使用簡化的 gRPC API 和命令行工具,自動化 Kubernetes 上 Triton 服務器實例的部署和管理。有了這些接口,您就不需要編寫大量的代碼或配置文件來創建部署、服務和 Kubernetes 資源。相反,您可以使用 API 或 CLI 輕松啟動 Triton 服務器,并根據需要自動將模型加載到這些服務器上。
TMS 還采用分組的方法來優化 GPU 或 CPU 存儲器利用率。這可以防止不同的框架(如 PyTorch 和 TensorFlow 模型)在同一服務器上運行時出現問題,并且無法釋放未使用的 GPU 或 CPU ?存儲器相互連接。
最大限度地利用資源
TMS 按需加載模型,并在不使用時使用租賃系統卸載模型,以確保模型不會在集群中保持不必要的活動狀態。為了建立模型,您可以提交一個帶有指定時間線或檢查機制的 API 請求。如果正在使用該模型,系統將保持該模型可用;否則,它將被取下。
當有足夠的容量時,TMS 也會自動在同一臺設備上對模型進行主機代管。要啟用此功能,您需要在部署期間預先指定模型的預期 GPU 內存使用情況。雖然還沒有自動測量的方法,但您可以依靠Triton Model Analyzer以及其他基準測試工具來預測內存需求。這些功能使您能夠在現有集群上運行更多的工作負載,從而節省成本,并減少獲取更多計算資源的需要。
監控和自動縮放
由于高可用性的需求,TMS 會跟蹤各種 Triton 服務器的運行狀況和容量。自動縮放功能已集成到系統中,使 TMS 能夠基于模型部署配置自動執行 Kubernetes Horizontal Pod 自動縮放。您可以指定用于自動縮放的指標,以及指示何時應進行縮放的條件。在多個 Triton 實例之間實現自動縮放時,也會應用負載平衡。
Triton 管理服務如何運作
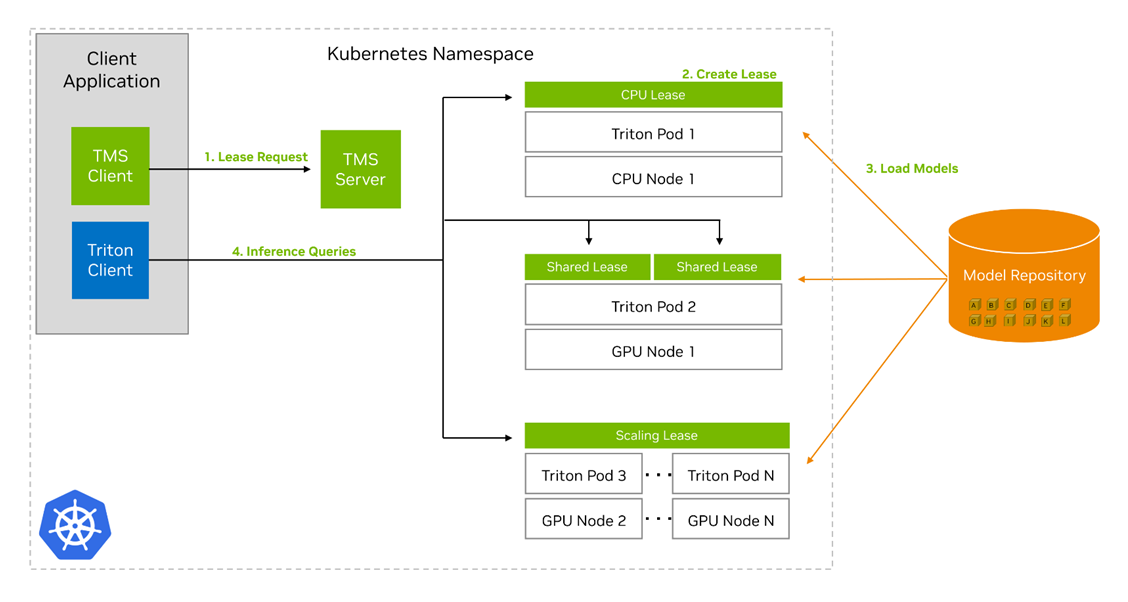
要安裝 TMS,請將具有可配置值的 Helm 圖表部署到 Kubernetes 集群中。這個 Helm 圖將 TMS 服務器控制平面分解到集群中,同時還有一個包含 TMS 許多配置設置的配置圖。您可以通過對 TMS 服務器的 gRPC API 調用或使用提供的 tmsctl 命令行工具來操作 TMS。
TMS 的關鍵概念是租賃租賃的核心是模型和一些相關元數據的分組,它們告訴 TMS 如何處理這些模型,以及它們的部署存在哪些限制。用戶可以創建、續訂和釋放租約。創建租約需要通過唯一標識符從預定義的存儲庫中指定一組模型,以及元數據,包括:
- 計算租賃所需的資源
- 用于本租約的 Triton 的圖像/版本
- 最短租賃期限
- 用于檢測租約中模型活動的窗口大小
- 擴展租賃的指標和閾值
- 可以收集具有新租約的模型或租約的限制
- 可用于尋址的租約的唯一名稱
TMS 服務器收到租約請求時,會執行以下操作以創建租約:
- 檢查模型存儲庫,查看模型是否存在并且可以訪問。
- 如果模型存在并且可以訪問,請檢查集群中是否存在符合新租約限制的現有 Triton 推理服務器。
- 如果不存在,請創建一個新的 Kubernetes pod,其中包含 Triton Inference Server container 和 Triton Sidecar container。
- 如果存在,選擇一個現有的 Triton pod 來添加租約。
- 在任何一種情況下, Triton Pod 中的 Triton Sidecar 都會從存儲庫中提取租約中的模型,并將其加載到其配對的 Triton 服務器中。
TMS 還將創建其他幾個 Kubernetes 資源,以幫助租賃的管理和路由:
- A. 如果 Triton pods 掛了,部署后將使它們恢復。
- A. Kubernetes service 基于可用于尋址租約中的模型的租約名稱。
- A. horizontal pod autoscaler 會根據在租約中定義的度量和閾值自動創建 Triton pods 的副本。
創建租約后,您可以使用 Triton Inference Server API 或現有的 Triton client 向服務器發送推理請求以供執行。無需任何修改,您就可以使用 Triton Management Service 部署的 Triton 推理服務器。
開始使用 NVIDIA Triton 管理服務
如果您想開始使用 NVIDIA Triton 管理服務并了解更多關于其特性和功能的信息,請查看 AI Model Orchestration with Triton Management Service 實驗室 LaunchPad。該實驗室提供對啟用 GPU 的 Kubernetes 集群的免費訪問,以及安裝 Triton 管理服務并使用它部署各種人工智能工作負載的分步指南。
如果您有現有的兼容內部部署系統或云實例,可以申請一個 90 天的 NVIDIA AI Enterprise 評估許可證來試用 Triton 管理服務。如果您是 NVIDIA AI Enterprise 的現有用戶,只需登錄NGC Enterprise Catalog。
?