如今,推薦系統被廣泛用于個性化用戶體驗,并在電子商務、社交媒體和新聞源等各種環境中提高客戶參與度。因此,以低延遲和高精度服務用戶請求對于維持用戶參與至關重要。
這包括在使用最新更新無縫刷新模型的同時執行高速查找和計算,這對于模型大小超過 GPU 內存的大規模推薦者來說尤其具有挑戰性。
NVIDIA Merlin HugeCTR ,一個開源框架,旨在優化 NVIDIA GPU 上的大規模推薦,最近發布 分層參數服務器( HPS )體系結構 以專門解決工業級推理系統的需求。實驗表明,該方法能夠在流行的基準數據集上以低延遲進行可拓展部署。
大規模推薦推理的挑戰
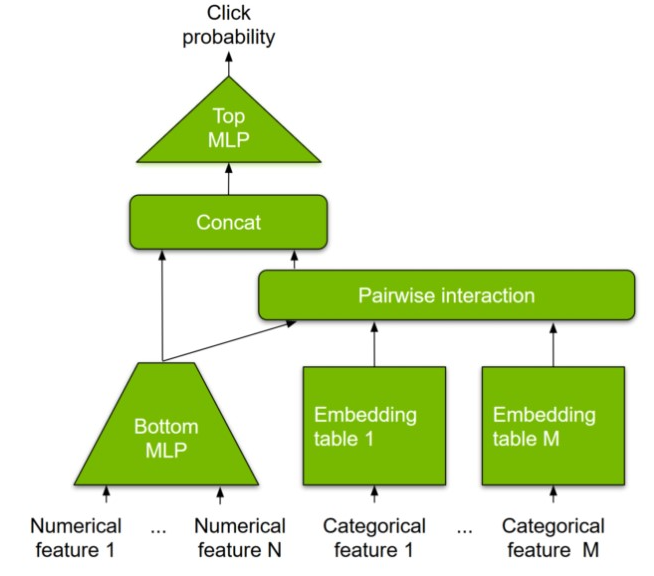
大型嵌入表 :典型深度推薦模型的輸入可以是數字(例如用戶年齡或商品價格)或分類特征(例如用戶 ID 或商品 ID )。與數字特征不同,分類特征需要轉換為數字向量,以輸入多層感知器( MLP )層進行密集計算。嵌入表學習從類別到數字特征空間的映射(“嵌入”),這有助于實現這一點。
因此,嵌入表是模型參數的一部分,并且可能是內存密集型的,對于現代推薦系統,可以達到 TB 級。這遠遠超出了現代 GPU 的板載存儲容量。因此,大多數現有的解決方案都退回到在 CPU 內存中托管嵌入表,這沒有利用高帶寬 GPU 內存,從而導致更高的端到端延遲。
可擴展性?:在用戶行為的驅動下,許多客戶應用程序被構建為服務于峰值使用,并且需要根據預期和實際負載擴展或擴展 AI 推理引擎的靈活性。
對不同框架和模型的高兼容性?:人工智能推理引擎必須能夠服務于兩種深度學習模型 ( 例如 DeepFM,?DCN,?DLRM,?MMOE,?DIN, 和?DIEN),由 TensorFlow 或 PyTorch 等框架以及簡單的機器學習( ML )模型訓練。此外,客戶希望混合部署多個不同的模型架構和單個模型的多個實例。模型還必須部署在從云到邊緣的各種硬件平臺上。
部署新模型和在線培訓更新 :客戶希望能夠根據市場趨勢和新用戶數據頻繁更新其模型。模型更新應無縫應用于推理部署。
容錯和高可用性 :客戶需要保持相同級別的 SLA ,對于任務關鍵型應用程序,最好是五個 9 或以上。
下一節提供了更多有關 NVIDIA Merlin HugeCTR 如何使用 HPS 解決這些挑戰的詳細信息,以實現對建議的大規模推斷。
分層參數服務器概述
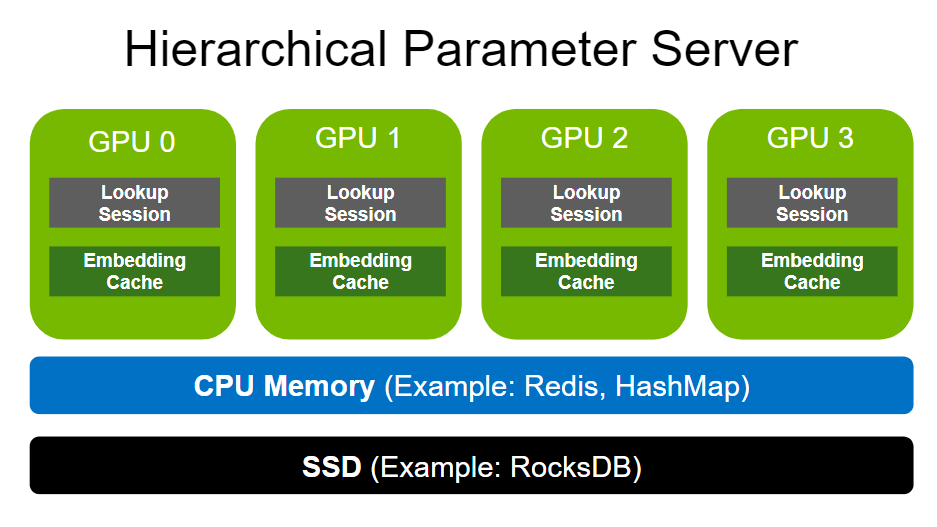
分層參數服務器支持使用多級自適應存儲解決方案部署大型推薦推理工作負載。為了存儲大規模嵌入,它使用GPU 存儲器作為第一級高速緩存,CPU 存儲器作為二級緩存(如用于本地部署的 HashMap 和用于分布式的 Redis ),以及用于擴展存儲容量(如 RocksDB )的 SSD 。
CPU 內存和 SSD 均可根據用戶需求靈活配置。請注意,與嵌入相比,致密層( MLP )的尺寸要小得多。因此,密集層以數據并行的方式在各種 GPU 工作者之間復制。
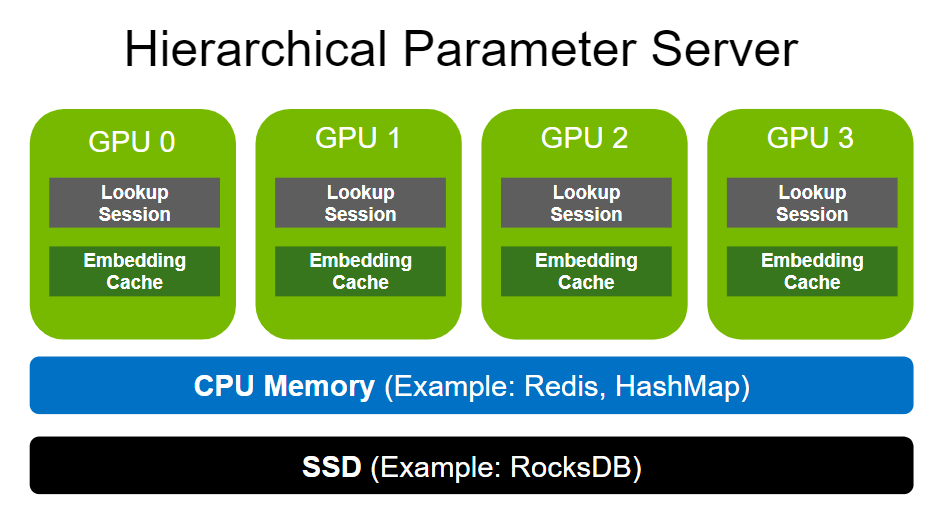
GPU 嵌入緩存
GPU 的內存帶寬比大多數 CPU 的內存寬度高一個數量級。例如, NVIDIA A100-80 GB 提供超過 2 TB / s 的 HBM2 帶寬。 GPU 嵌入緩存通過將內存密集型嵌入查找移動到 GPU 中,更接近計算發生的位置,從而利用了如此高的內存帶寬。
為了設計一個有效利用現代 GPU 提供的優勢的系統,重要的是要注意一個關鍵觀察:在現實世界的推薦數據集中,一些特征類別通常比其他特征類別出現得更頻繁。例如 標準 1 TB 點擊日志數據集 ,也是一個流行的基準數據集 用于 MLPerf 總共 188 米中的 305K 個類別(僅占 0.16% )被 95.9% 的樣本引用。
這意味著某些嵌入的訪問頻率遠遠高于其他嵌入。嵌入鍵訪問大致遵循冪律分布。因此,在 GPU 內存中緩存這些最頻繁訪問的參數將使推薦系統能夠利用高 GPU 內存帶寬。單個嵌入查找是獨立的,這使得 GPU 成為向量查找處理的理想平臺,因為它們能夠同時運行數千個線程。
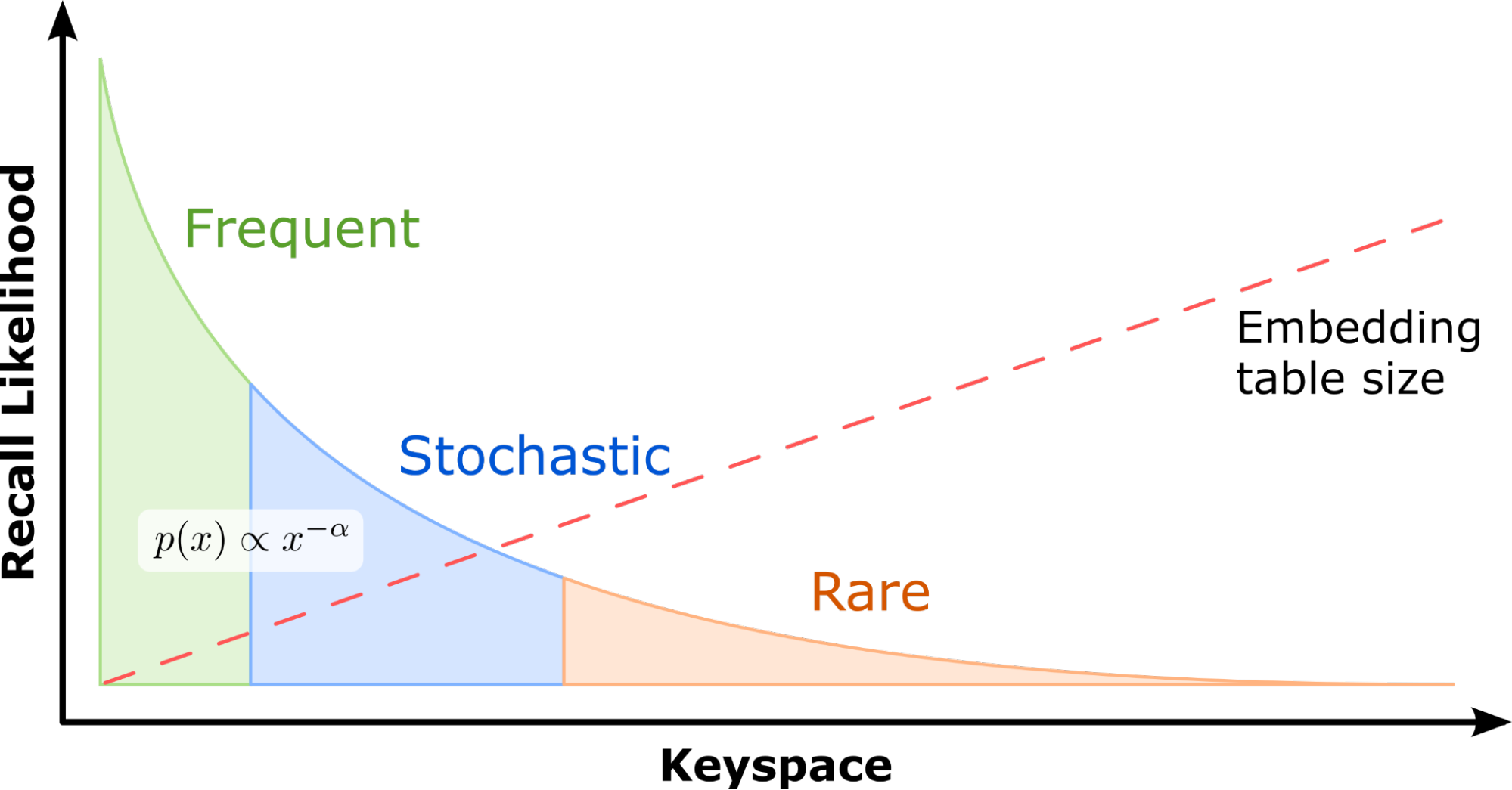
這些特性激發了 HPS GPU 嵌入緩存的設計,該緩存將熱嵌入保留在[Z1K11]內存中,通過減少額外的或重復的參數在較慢的 CPU- GPU 總線上的移動來提高查找性能。它由保留所有嵌入表的完整副本的輔助存儲器支持。下文將對此進行更全面的探討。對于與 GPU 上托管的每個模型相關聯的每個嵌入表,存在唯一的 GPU 嵌入緩存。
嵌入鍵插入機制
當在推理過程中 GPU 緩存中缺少查找到的嵌入鍵時,將觸發鍵插入以從層次結構的較低級別獲取相關數據。 HPS 實現了同步和異步鍵插入機制,以及用戶定義的[VZX1 8],以在兩個選項之間進行選擇,以平衡準確性和延遲。
- Synchronous insertion: 如果實際命中率低于命中率閾值,則在等待將丟失的鍵插入 GPU 緩存時,會阻止推理請求。這通常發生在模型剛加載時、預熱期間或進行重要模型更新后。
- Asynchronous insertion: 如果實際命中率高于命中率閾值,則立即返回預配置的默認向量,以允許查詢管道繼續執行,而不會延遲。“惰性”插入本身發生在后臺。當已達到所需精度且主要關注點是保持低延遲時,使用該方法。在實際的行業場景中,即使緩存了完整模型,推理也可能仍然缺少功能,因為在推理中可能會出現從未出現在訓練數據集中的新項目和用戶。
GPU 嵌入緩存性能
圖 4 顯示了使用 標準 1 TB 點擊日志數據集 和 90GB 個性化和推薦系統的深度學習推薦模型 NVIDIA T4 ( 16 GB 內存)、 A30 ( 24 GB 內存)和 A100 GPU ( 80 GB 內存)上的( DLRM )型號,緩存了型號大小的 10% 。命中率閾值設置為 1.0 ,以便所有鍵插入都是同步的。在穩定階段進行測量。
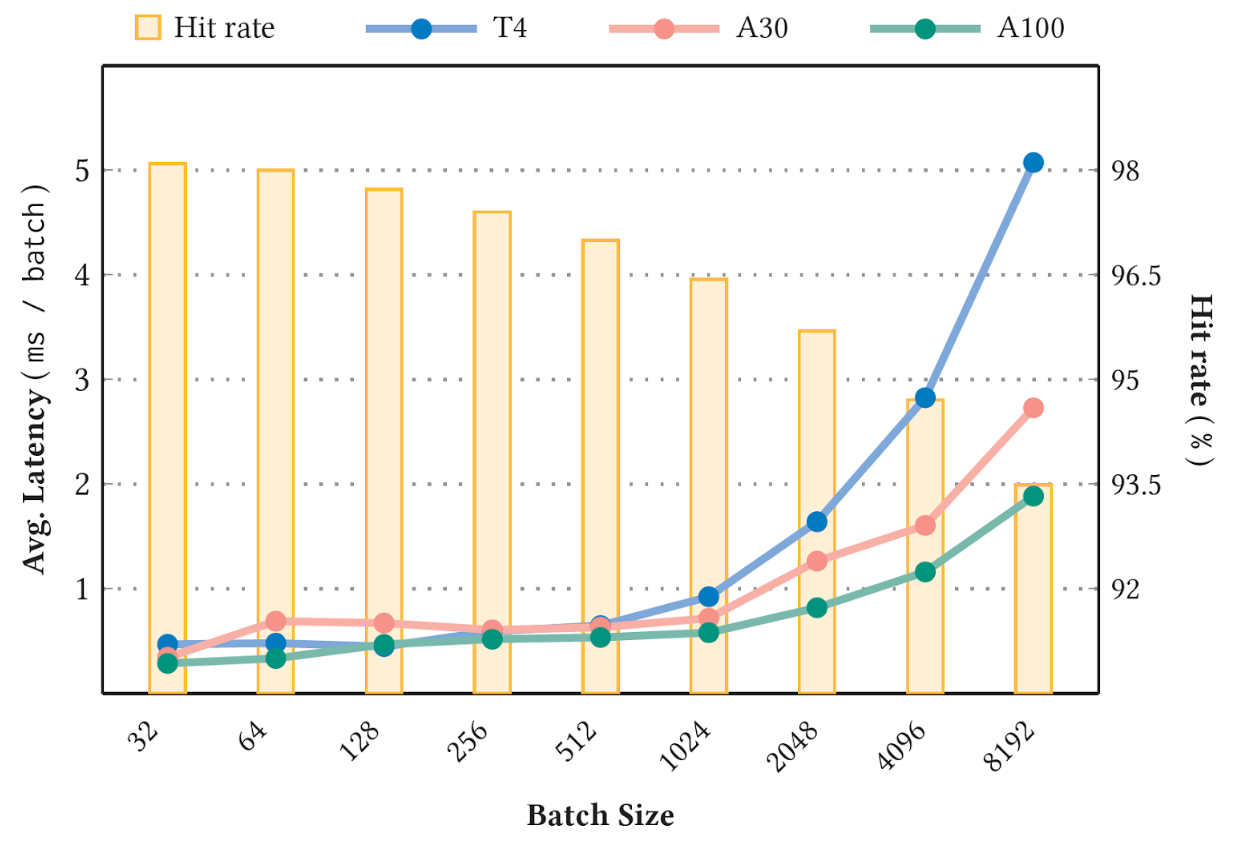
可以預期,較高的穩定緩存命中率(圖 4 中的條形圖)對應于較低的平均延遲(圖 4 的折線圖)。此外,由于鍵丟失的可能性越來越大,更大的批大小也會導致命中率降低和延遲增加。有關基準的更多詳細信息,請參閱 用于大規模深度推薦模型的 GPU 專用推理參數服務器 .
HPS 包括兩個額外的層,通過利用CPU 存儲器和 SSD 。這些層高度可配置,以支持各種后端實現。以下各節將更詳細地介紹這些。
CPU 緩存
第二級存儲是 CPU 緩存,通過 CPU- GPU 總線訪問,并以較低的成本作為[Z1K11]嵌入緩存的擴展存儲。如果 GPU 嵌入緩存中缺少嵌入鍵, HPS 接下來將查詢 CPU 緩存。
- 如果找到鍵(緩存命中),則返回結果并記錄訪問時間。這些最后訪問的時間戳用于以后的鍵逐出。
- 如果鍵丟失, HPS 將轉到下一層獲取嵌入,同時還調度將丟失的嵌入向量插入 CPU 緩存。
“ CPU 緩存”層支持各種數據庫后端。 HugeCTR HPS 提供 易失性數據庫示例 具有基于哈希映射的本地 CPU 內存數據庫實現,以及 Redis 集群 – 基于后端,利用分布式集群實例進行可擴展部署。
固態硬盤
緩存層次結構的最低層以更低的成本在 SSD 、硬盤或網絡存儲卷上存儲每個嵌入表的完整副本。對于表現出極端長尾分布的數據集(大量類別,其中許多類別不經常被引用),保持高精度對于手頭的任務至關重要,這一點尤其有效。這個 HugeCTR HPS 參考配置 將嵌入表映射到 RocksDB 本地 SSD 上的數據庫。
整個模型通過設計保存在每個推理節點中。這種資源隔離策略增強了系統可用性。即使在災難性事件后只有一個節點是活動的,也可以恢復模型參數和推理服務。
增量訓練更新
推薦模型有兩種培訓模式:離線和在線。在線培訓將新的模型更新部署到實時生產中,對于推薦的有效性至關重要。 HPS 雇傭 無縫更新機制 通過 Apache Kafka?– 基于消息緩沖區連接訓練和推理節點,如圖 5 所示。
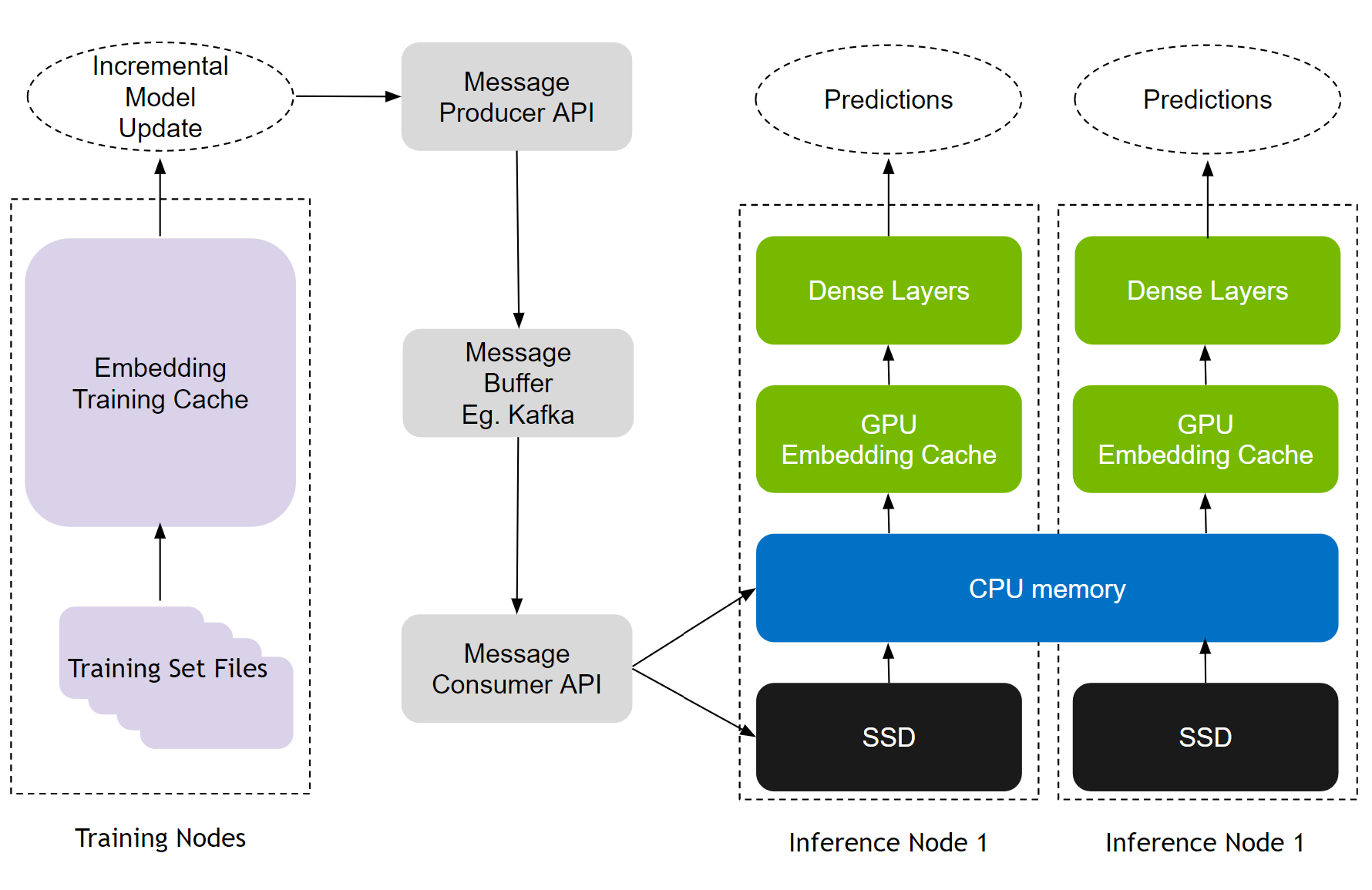
更新機制有助于 MLOps 工作流,支持在線/頻繁以及離線/再培訓更新,無需停機。它還通過設計賦予了容錯能力,因為即使推理服務器關閉,訓練更新也會繼續在 Kafka 消息緩沖區中排隊。通過方便易用的 Python API ,開發人員可以使用所有這些功能。
HPS 性能基準
為了證明 HugeCTR HPS 的優勢,我們評估了其在 DLRM 模型上的端到端推理性能,并 標準 1 TB 點擊日志數據集 ,并將其與僅在 GPU 上運行密集層計算和僅 CPU 解決方案的場景進行了比較。
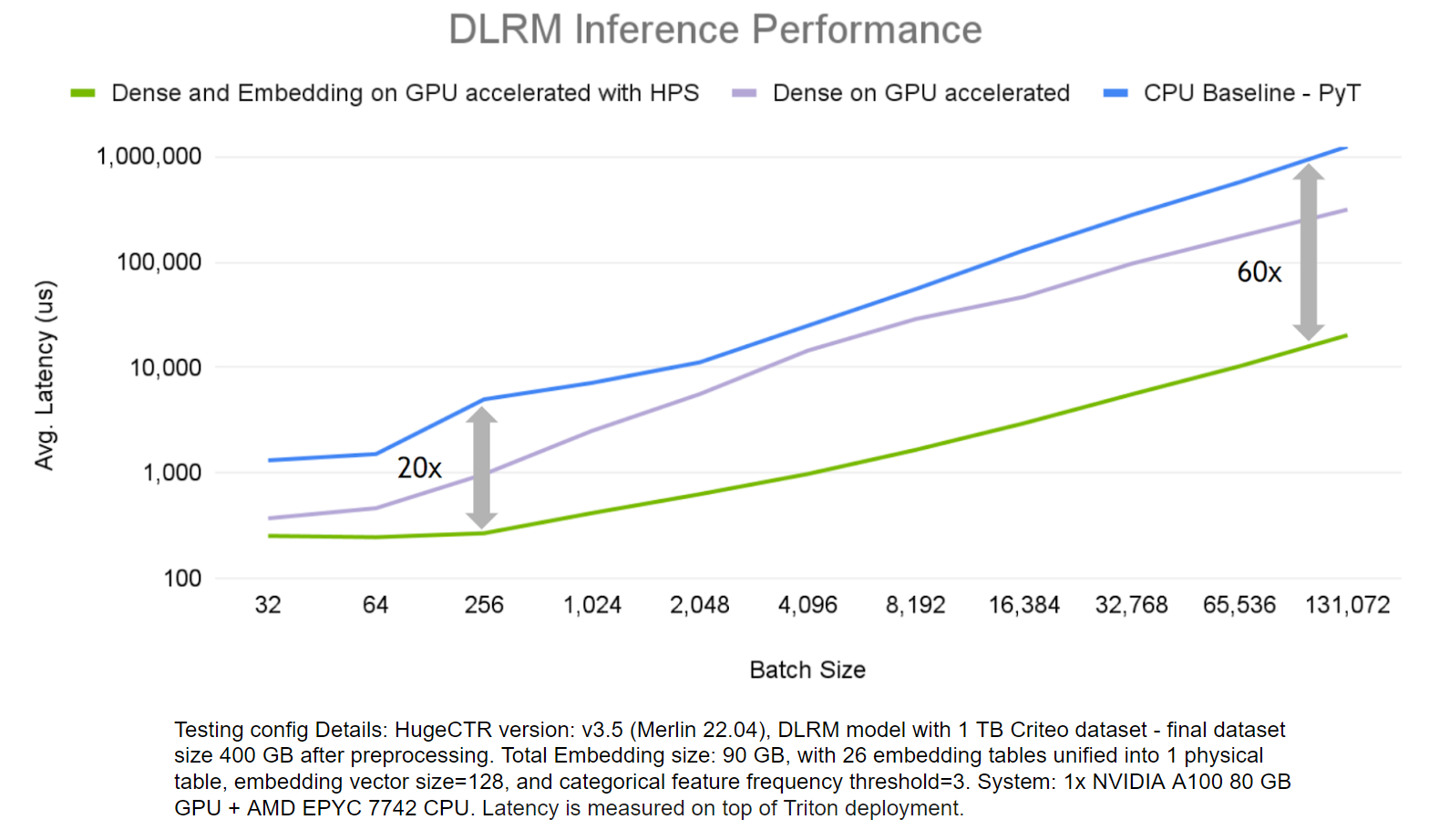
HPS 解決方案加快了嵌入和密集層的速度,遠遠優于僅使用 CPU 的解決方案,在更大批量的情況下,其速度高達 60 倍。
HPS 與 CPU PS 加 GPU 工作解決方案的區別
您可能熟悉 CPU 參數服務器( PS )和 GPU 工作解決方案。表 1 顯示了 HPS 與大多數 PS plus worker 解決方案的不同之處。
| ? | HPS | CPU PS + GPU Worker |
| Pipeline focus | Inference | Training and Inference |
| Embedding lookup GPU accelerated | Yes | No |
| GPU use | Most frequently accessed embedding tables Dense parameters from MLP |
Dense parameters from MLP |
| Inter GPU Communication | None | None |
| CPU use | Less frequently accessed embeddings | All embedding tables are sharded across CPUs |
總結
本文介紹了 Merlin HugeCTR HPS ,其中 GPU 嵌入緩存作為一種工具,用于加速 NVIDIA GPU 上大規模嵌入的推理。 HPS 方便易用 配置 ,包括 例子 讓你開始。還將有一個 TensorFlow 插件 這使得能夠在現有 TF 推理管道中使用 HPS 。有關詳細信息,請參閱 用于大規模深度推薦模型的 GPU 專用推理參數服務器 和 Merlin HugeCTR HPS 文檔 .
要了解有關在 NVIDIA GPU 上構建和部署推薦系統的最佳實踐的更多信息,請參閱 深度學習性能文檔 .
?