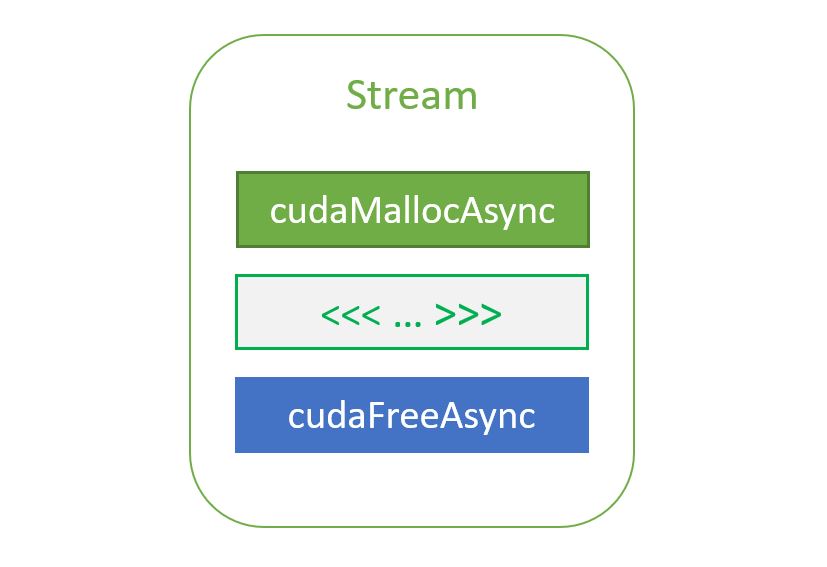
異構內存管理(HMM)是一種 CUDA 內存管理功能,它擴展了 CUDA 統一內存 的編程模型,包括系統分配內存在具有 PCIe 連接的 NVIDIA GPU 的系統上。系統分配內存是指最終由操作系統分配的內存;例如,通過 malloc,mmap,C++ 新操作員(當然使用前面的機制),或為應用程序設置 CPU 可訪問內存的相關系統例程。
以前,在基于 PCIe 的機器上, GPU 無法直接訪問系統分配的內存。 GPU 只能訪問來自特殊分配器的內存,例如庫達馬洛克或cudaMallocManaged。
啟用 HMM 后,所有應用程序線程( GPU 或 CPU )都可以直接訪問應用程序系統分配的所有內存。與統一內存(可以被認為是 HMM 的子集或前身)一樣,不需要在處理器之間手動復制系統分配的內存。這是因為它會根據處理器的使用情況自動放置在 CPU 或 GPU 上。
在 CUDA 驅動程序堆棧中, CPU 和 GPU 頁錯誤通常用于發現內存應該放在哪里。同樣,這種自動放置已經在統一內存中發生了——HMM 只是將行為擴展到覆蓋系統分配的內存以及cudaMallocManaged記憶力
這種直接讀取或寫入整個應用程序內存地址空間的新能力將顯著提高基于 CUDA 之上構建的所有編程模型的程序員生產力: CUDA C++、Fortran、 Python 中的標準并行性、ISO C++、ISO Fortran、OpenACC、OpenMP 和許多其他模型。
事實上,正如即將到來的示例所示,HMM 將 GPU 編程簡化到 GPU programming 幾乎與 CPU 編程一樣可訪問的程度。一些亮點:
- 編寫 GPU 程序時,功能不需要顯式內存管理;因此,一個初始的“初稿”程序可以是小而簡單的。顯式內存管理(用于性能調優)可以推遲到稍后的開發階段。
- 對于不區分 CPU 和 GPU 存儲器的編程語言, GPU programming 現在是實用的。
- 大型應用程序可以被 GPU 加速,而不需要大型內存管理重構或更改第三方庫(源代碼并不總是可用的)。
順便說一句,NVIDIA Grace Hopper 通過硬件實現了所有 CPU 和 GPU 之間的內存一致性,從而本地支持統一內存編程模型。對于這樣的系統,不需要 HMM,事實上,HMM 在這種情況下會被自動禁用。可以將 HMM 視為一種基于軟件的方式,它提供了與 NVIDIA Grace Hopper Superchip 類似的功能。
要了解有關 CUDA 統一內存的更多信息,請參閱本文末尾的參考資料部分。
HMM 之前的統一內存
原件 CUDA Unified Memory 是在 2013 年推出的功能,只需進行一些更改,就可以加速 CPU 程序,如下所示:
HMM 之前
僅限于 CPU
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
HMM 之后
CUDA 統一內存(2013)
void sortfile(FILE* fp, int N) {
char* data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
cudaFree(data);
}
此編程模型簡單、清晰且功能強大。在過去的 10 年里,這種方法使無數應用程序能夠輕松地從 GPU 加速中受益。然而,仍有改進的空間:請注意需要一個特殊的分配器:cudaMallocManaged,以及相應的cudaFree。
如果我們能走得更遠,擺脫這些呢?HMM 就是這么做的。
HMM 之后的統一內存
在帶有 HMM 的系統上(詳細信息如下),繼續使用malloc和自由的:
HMM 之前
僅限于 CPU
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
HMM 之后
CUDA 統一內存+HMM(2023)
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
free(data)
}
有了 HMM,兩者之間的內存管理現在是相同的。
系統分配的內存和 CUDA 分配器
使用 CUDA 內存分配器的 GPU 應用程序在具有 HMM 的系統上“按原樣”工作。這些系統的主要區別在于系統分配 APImallocC++新或mmap現在創建可以從 GPU 線程訪問的分配,而不必調用任何 CUDA API 來告訴 CUDA 這些分配的存在。表 1 顯示了在具有 HMM 的系統上最常見的 CUDA 內存分配器之間的差異:
| 內存分配器 在帶有 HMM 的系統上 | 安置 | 遷移的 | 可從訪問: | ||
| CPU | GPU | RDMA | |||
| 系統已分配 malloc,mmap… |
第一次觸摸 GPU 或 CPU |
Y | Y | Y | Y |
| CUDA 管理 cudaMallocManaged |
Y | Y | Y | N | |
| 僅限 CUDA 設備 庫達馬洛克… |
GPU | N | N | Y | Y |
| CUDA 主機已固定 cudaMallocHost… |
CPU | N | Y | Y | Y |
通常,選擇更好地表達應用程序意圖的分配器可以使 CUDA 提供更好的性能。使用 HMM,這些選擇成為性能優化,在第一次從 GPU 訪問內存之前,不需要提前完成。HMM 使開發人員能夠首先關注并行算法,然后在開銷提高性能時執行與內存分配器相關的優化。
C++、Fortran 和 Python 的無縫 GPU 加速
HMM 使 NVIDIA GPU 使用標準化和可移植的編程語言(如 Python )以及 ISO Fortran 和 ISO C++等國際標準描述的編程語言編程變得更加容易,這些語言不區分 CPU 和 GPU memory,并假設所有線程都可以訪問所有內存。
這些語言提供了并發和并行功能,使得計算能夠自動調度到 GPU 和其他設備。例如,自 C++2017 以來,<算法>收割臺接受 執行策略,使得它們能夠并行運行。
從 GPU 對文件進行就地排序
例如,在 HMM 之前,對大于 CPU 內存的文件進行排序是復雜的,需要先對文件的較小部分進行排序,然后將它們合并為完全排序的文件。使用 HMM,應用程序可以使用 mmap 將磁盤上的文件映射到內存中,并直接從 GPU 讀取和寫入。想要了解更多詳細信息,請參閱 GitHub 上的 HMM 示例代碼 file_before.cpp 和 file_after.cpp。
HMM 之前
動態分配
void sortfile(FILE* fp, int N) {
std::vector<char> buffer;
buffer.resize(N);
fread(buffer.data(), 1, N, fp);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer.begin(), buffer.end(),
std::greater{});
use_data(std::span{buffer});
}
HMM 之后
CUDA 統一內存+HMM(2023)
void sortfile(int fd, int N) {
auto buffer = (char*)mmap(NULL, N,
PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer, buffer + N,
std::greater{});
use_data(std::span{buffer});
}
這個 NVIDIA C++ Compiler (NVC++) 并行實現 std::排序,當使用 -stdpar=GPU 選項時。使用此選項有許多限制,如 HPC SDK 文檔 所述。
- HMM 之前:GPU 只能訪問由 NVC++ 編譯的代碼中堆上的動態分配的內存。也就是說,CPU 線程堆棧上的自動變量、全局變量和內存映射文件不能從 GPU 訪問(請參閱下面的示例)。
- HMM 之后:GPU 可以訪問所有系統分配的內存,包括其他編譯器和第三方庫編譯的 CPU 代碼中堆上動態分配的數據、CPU 線程堆棧上的自動變量、CPU 內存中的全局變量、內存映射文件等。
原子內存操作和同步原語
HMM 支持所有內存操作,包括原子內存操作。這意味著,程序員可以使用原子內存操作來同步 GPU 和 CPU 線程的標志。然而,C++ 的一些部分,如 std::atomic::wait 和 std::atomic::notify_all/one API,使用了在 GPU 上還不可用的系統調用。盡管如此,大多數 C++ 并發原語 API 都是可用的,并且可以方便地用于在 GPU 和 CPU 線程之間執行消息傳遞。
想要獲取更多信息,請參閱 HPC SDK C++ 并行算法:與 C++ 標準庫的互操作性 文檔,以及在 GitHub 上的 atomic_flag.cpp HMM 示例代碼。您可以使用 CUDA C++ 擴展此集合。請參閱 ticket_lock.cpp 以獲取更多詳細信息,或訪問 GitHub 上的 HMM 示例代碼。
HMM 之前
CPU ←→ GPU 消息傳遞
void main() {
// Variables allocated with cudaMallocManaged
std::atomic<int>* flag;
int* msg;
cudaMallocManaged(&flag, sizeof(std::atomic<int>));
cudaMallocManaged(&msg, sizeof(int));
new (flag) std::atomic<int>(0);
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
*msg = 42; // all accesses via ptrs
// …and signals completion…
flag->store(1); // all accesses via ptrs
});
});
// CPU thread waits on GPU thread
while (flag->load() == 0); // all accesses via ptrs
// …and reads the message:
std::cout << *msg << std::endl;
// …the GPU kernel and thread
// may still be running here…
}
HMM 之后
CPU ←→ GPU 消息傳遞
void main() {
// Variables on CPU thread stack:
std::atomic<int> flag = 0; // Atomic
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
msg = 42;
// …and signals completion…
flag.store(1);
});
});
// CPU thread waits on GPU thread
while (flag.load() == 0);
// …and reads the message:
std::cout << msg << std::endl;
// …the GPU kernel and thread
// may still be running here…
}
HMM 之前
CPU ←→ GPU 鎖
void main() {
// Variables allocated with cudaMallocManaged
ticket_lock* lock; // Lock
int* msg; // Message
cudaMallocManaged(&lock, sizeof(ticket_lock));
cudaMallocManaged(&msg, sizeof(int));
new (lock) ticket_lock();
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout << msg << std::endl;
}
HMM 之后
CPU ←→ GPU 鎖
void main() {
// Variables on CPU thread stack:
ticket_lock lock; // Lock
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout << msg << std::endl;
}
使用 HMM 加速復雜的 HPC 工作負載
多年來,致力于大型和長壽命 HPC 應用程序的研究小組一直渴望為異構平臺提供更高效和可移植的編程模型。m-AIA 是一個多物理求解器,跨越了在德國亞琛工業大學的空氣動力學研究所看見使用 OpenACC 加速 C++ CFD 代碼了解更多信息。最初的原型并未使用 OpenACC,而是使用上述 ISO C++ 編程模型在 GPU 上部分加速,這在原型工作完成時是不可用的。
HMM 使我們的團隊能夠加速與 GPU 不可知的第三方庫,如 FFTW 和 pnetcdf,這些庫用于初始條件和 I/O,并且可以直接訪問 GPU 同一存儲器。
利用內存映射 I/O 實現快速開發
HMM 提供的一個有趣的特性是直接來自 GPU 的內存映射文件 I/O。它使開發人員能夠直接從支持的存儲或/磁盤讀取文件,而無需將它們暫存在系統內存中,也無需將數據復制到高帶寬 GPU 內存中。這也使應用程序開發人員能夠輕松處理大于可用物理系統內存的輸入數據,而無需構建迭代數據接收和計算工作流。
為了演示這一功能,我們的團隊編寫了一個示例應用程序,該應用程序基于 ERA5 重分析數據集。想要了解更多詳細信息,請參閱 ERA5 全球重分析 .
ERA5 數據集由幾個大氣變量的每小時估計值組成。在數據集中,每個月的總降水量數據存儲在一個單獨的文件中。我們使用了 1981 年至 2020 年 40 年的總降水量數據,總計 480 個輸入文件,總輸入數據大小約為 1.3 TB。示例結果見圖 1。
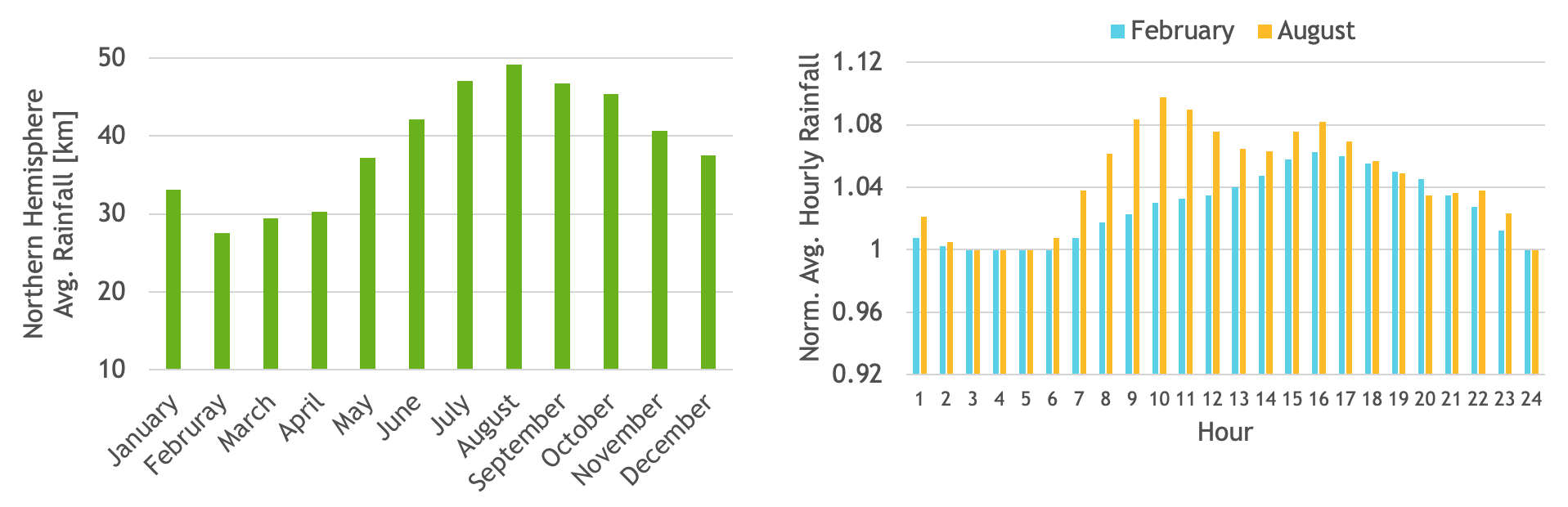
使用 UnixmmapAPI,輸入文件可以映射到連續的虛擬地址空間。有了 HMM,這個虛擬地址可以作為輸入傳遞給 CUDA 內核,然后該內核可以直接訪問這些值,以建立一年中所有日子每小時的總降水量直方圖。
所得的直方圖將保存在 GPU 存儲器中,可以輕松計算出諸如北半球的月平均降水量等有趣的統計數據。例如,我們還計算了 2 月和 8 月的平均每小時降水量。如果您想查看此應用程序的代碼,請訪問在 GitHub 上的?HMM_sample_code 。
HMM 之前
批處理和管道內存傳輸
size_t chunk_sz = 70_gb;
std::vector<char> buffer(chunk_sz);
for (fp : files)
for (size_t off = 0; off < N; off += chunk_sz) {
fread(buffer.data(), 1, chunk_sz, fp);
cudeMemcpy(dev, buffer.data(), chunk_sz, H2D);
histogram<<<...>>>(dev, N, out);
cudaDeviceSynchronize();
}
HMM 之后
內存映射和按需傳輸
void* buffer = mmap(NULL, alloc_size,
PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
for (fd : files)
mmap(buffer+file_offset, fileByteSize,
PROT_READ, MAP_PRIVATE|MAP_FIXED, fd, 0);
histogram<<<...>>>(buffer, total_N, out);
cudaDeviceSynchronize();
啟用和檢測 HMM
只要檢測到您的系統可以處理 HMM,CUDA 工具包和驅動程序就會自動啟用 HMM。詳情請參閱 CUDA 12.2 發布說明:通用 CUDA。您需要:
- NVIDIA CUDA 12.2,帶有開源 r535_00 驅動程序或更新版本。請查看NVIDIA Open GPU Kernel Modules 安裝文檔以獲取詳細信息。
- 一個足夠新的 Linux 內核:6.1.24+、6.2.11+或 6.3+。
- 具有以下支持架構之一的 GPU : NVIDIA Turing、 NVIDIA Ampere、 NVIDIA Ada Lovelace、NVID IA Hopper 或更新版本。
- 64 位 x86 CPU 。
查詢 Addressing Mode 屬性以驗證 HMM 是否已啟用:
$ nvidia-smi -q | grep Addressing Addressing Mode : HMM
要檢測 GPU 可以訪問系統分配的內存的系統,請查詢cudaDevAttr 可訪問內存。
此外, NVIDIA Grace Hopper Superchip 等系統支持 ATS,其行為與 HMM 相似。事實上,HMM 和 ATS 系統的編程模型是相同的,因此僅檢查cudaDevAttr 可訪問內存對于大多數程序來說就足夠了。
然而,對于性能調整和其他高級編程,也可以通過查詢來區分 HMM 和 ATScudaDevAttrPageMemoryAccessUsesHostPageTables表 2 顯示了如何解釋結果。
| 屬性 | 嗯 | ATS |
| cudaDevAttr 可訪問內存 | 1 | 1 |
| cudaDevAttrPageMemoryAccessUsesHostPageTables | 0 | 1 |
對于只對查詢 HMM 或 ATS 公開的編程模型是否可用感興趣的可移植應用程序,查詢“可分頁內存訪問”屬性通常就足夠了。
統一內存性能提示
對于已經在 NVIDIA Grace Hopper 等硬件相關系統上使用 CUDA 統一內存的應用程序,預先存在的統一內存性能提示 的語義沒有變化,主要的變化是 HMM 使它們能夠在上述限制范圍內的更多系統上“按原樣”運行。
預先存在的統一內存提示也適用于 HMM 系統上的系統分配內存:
- __host__ cudaError_t
cudaMemPrefetchAsync(* ptr, size_t nbytes, int device):
此功能可以異步地將存儲器預取到 GPU ( GPU device ID)或 CPU (cudaPuDeviceId)。 - __host__ cudaError_t cudaMemAdvise(*ptr, size_t nbytes, cudaMemoryAdvise, advice, int device):這是系統提示。
- 內存的首選位置:cudaMemAdviseSet 首選位置或
- 將訪問內存的設備:cudaMemAdviseSet 訪問者或
- 一種主要讀取很少修改的內存的設備:
cudaMemAdviseSetReadMost.
更進一步:新的 CUDA 12.2 API,cudaMemAdvise_v2,允許應用程序選擇給定內存范圍應首選的 NUMA 節點。當 HMM 將內存內容放在 CPU 一側時,這一點就顯得尤為重要。
與往常一樣,內存管理提示可能會提高或降低性能。行為依賴于應用程序和工作負載,但任何提示都不會影響應用程序的正確性。
CUDA 12.2 中 HMM 的限制
CUDA 12.2 中的初始 HMM 實現在提供新功能的同時,不會影響任何預先存在的應用程序的性能。 CUDA 12.2 中 HMM 的限制已在 CUDA 12.2 發布說明:通用 CUDA 中詳細記錄。主要限制包括:
- HMM 僅適用于 x86_64,其他 CPU 體系結構尚不受支持。
- HMM 打開 HugeTLB 不支持分配。
- 不支持對文件支持的內存和 HugeTLBfs 內存執行 GPU 原子操作。
- fork(2) 沒有以下內容,exec(3) 不完全支持。
- 頁面遷移是以 4KB 頁面大小的塊來處理的。
請繼續關注未來的 CUDA 驅動程序更新,這些更新將解決 HMM 限制并提高性能。
總結
HMM 通過消除在通用基于 PCIe(通常為 x86)計算機上運行的 GPU 程序的顯式內存管理需求,簡化了編程模型。程序員可以簡單地使用mallocC++新和mmap直接調用,就像它們已經為 CPU 編程所做的那樣。
HMM 通過使各種標準編程語言功能能夠在 CUDA 程序中安全使用,進一步提高了程序員的生產力。不必擔心意外地將系統分配的內存暴露給 CUDA 內核。
HMM 實現了與新 NVIDIA Grace Hopper 超級芯片和類似機器的無縫過渡。在基于 PCIe 的機器上,HMM 提供了與 NVIDIA Grace Hopper 超級芯片相同的簡化編程模型。
統一內存資源
了解更多信息關于 CUDA Unified Memory,以下的博客文章將幫助您了解最新情況。您也可以在 NVIDIA Developer Forum for CUDA 中參與討論。
- An Easy Introduction to CUDA C and C++ (2012)
- CUDA 6 中的統一內存(2013)
- An Even Easier Introduction to CUDA (2017)
- CUDA 初學者的統一內存(2017)
?