NVIDIA RTX GPU 中的 NVIDIA Grace Hopper 超級芯片 系統為開發者處理 GPU 編程的方式帶來了一些戲劇性的變化。最值得注意的是,CPU 和 GPU 顯存之間的雙向、高帶寬和緩存一致性連接意味著用戶可以在使用單個統一地址空間的同時為這兩個處理器開發應用程序。
每個處理器都保留自己的物理內存,該內存的設計具有與最適合每個處理器的工作負載相匹配的帶寬、延遲和容量特性。針對現有的獨立顯存 GPU 系統編寫的代碼將繼續保持高性能運行,而無需針對新的 NVIDIA Grace Hopper 架構進行修改。
我們最近的博文 借助異構內存管理簡化 GPU 應用程序開發 詳細介紹了單地址空間為開發者帶來的一些優勢,以及它在通過 PCIe 連接至 x86_64 CPU 的 NVIDIA GPU 系統上的工作原理。所有應用程序線程(GPU 或 CPU)都可以直接訪問應用程序的所有系統分配顯存,從而消除了在處理器之間復制數據的需求。
這種直接讀取或寫入整個應用程序內存地址空間的新功能可顯著提高基于 CUDA 構建的所有編程模型的工作效率:CUDA C++、CUDA Fortran、ISO C++和 ISO Fortran 中的標準并行性、OpenACC、OpenMP 等。
本文將繼續關于 Grace Hopper 硬件的異構內存管理 (HMM) 討論,該硬件提供與支持 HMM 的系統相同的所有編程模型改進,但增加了硬件支持,使其更加出色。
值得注意的是,任何受到主機到設備或設備到主機傳輸限制的工作負載,都可以在 Grace Hopper 系統中通過 芯片到芯片 (C2C) 互連 獲得高達 7 倍的加速。這種性能的實現得益于緩存一致性,而且無需固定內存(例如使用 cudaHostRegister),尤其是在使用大型頁面時。雖然過去 HMM 和 CUDA 托管內存僅限于在頁面錯誤時被動遷移整個數據頁面,但 Grace Hopper 能夠更加精準地決定數據應位于何處以及何時進行遷移。
我們將在本文中詳細介紹 NVIDIA HPC 編譯器如何利用這些新的硬件功能,通過 ISO C++、ISO Fortran、OpenACC 和 CUDA Fortran 簡化 GPU 編程。
NVIDIA Grace Hopper 系統結合簡化的 GPU 開發者體驗,可提供最佳性能。HMM 還將這種簡化的開發者體驗引入非 Grace Hopper 系統,同時在使用 PCIe 時提供最佳性能。開發者可以以便攜方式使用這些改進和簡化的編程模型,以便在使用 NVIDIA GPU 的各種系統上獲得出色性能。
使用 Grace Hopper 統一內存擴展 stdpar
標準語言如 ISO C++ 和 ISO Fortran 近年來不斷增加功能,使得開發者能夠直接利用基礎語言本身來表達應用程序中的并行性,而無需依賴于語言擴展或編譯器指令。NVIDIA HPC 編譯器 能夠構建這些應用程序,并確保它們在 NVIDIA GPU 上高效運行。有關這些功能的更多信息,請參閱我們之前的文章。
更具體地說,我們展示了如何使用標準語言并行(也稱為 stdpar)來大大提高開發者的工作效率并簡化 GPU 應用開發。但是,我們還指出了由于 CPU 和 GPU 的不同內存空間的性質而造成的一些限制,包括無法使用 C++并行算法中的某些類型的數據,例如在堆棧上分配的數據、全局數據或在 lambda 捕獲中通過引用捕獲的數據。
對于 Fortrando concurrent循環,全局變量不能用于從內部調用的例程do concurrent循環和編譯器對假設大小數組的數據大小檢測受到限制。現在,Grace Hopper 及其統一內存功能消除了這些限制,使用 stdpar 開發應用程序變得更加簡單。
簡化 OpenACC 和 CUDA Fortran
長期以來,GPU 應用程序開發者一直傾向于使用 OpenACC 和 CUDA Fortran,因為它們的便利性和強大功能。 CUDA C++ 也同樣經受了時間的考驗,并被全球 HPC 中心的大量應用程序用于生產。這兩種模型都提供了管理數據駐留以及優化數據傳輸和移動的可靠方法。
現在,借助 Grace Hopper 的統一顯存功能,系統可以自動處理數據位置和移動的這些考慮因素,從而大幅簡化應用開發。這減少了將應用移植到 GPU 上運行的工作量,并為算法開發留出了更多時間。
為了微調性能和優化,開發者可以選擇使用 OpenACC 和 CUDA Fortran 中已有的設施選擇性地添加有關數據局部性的信息。現有應用程序中為獨立顯存設備編寫的數據信息可用于優化 Grace Hopper 的統一顯存,而無需更改代碼。
使用統一內存評估應用程序性能
以下各節將探討多個基準測試和應用,以了解這些新功能如何不僅簡化代碼開發,而且會影響預期的運行時性能。
SPECaccel 2023 基準測試
我們的SPECaccel? 2023 基準測試套件專注于評估使用 CUDA、OpenACC 和 OpenMP 的單個加速器性能。這些基準測試旨在展示通用 GPU 的性能,并能很好地代表眾多 HPC 應用程序如何利用 Grace Hopper 的新統一內存功能。
圖 1 比較了 OpenACC 數據指令與通過 NVHPC SDK 編譯器標志啟用的統一內存的性能-gpu=unified.雖然結果遵循基準測試的運行規則要求,但它們是在預生產硬件上測量的,因此被視為估計結果。
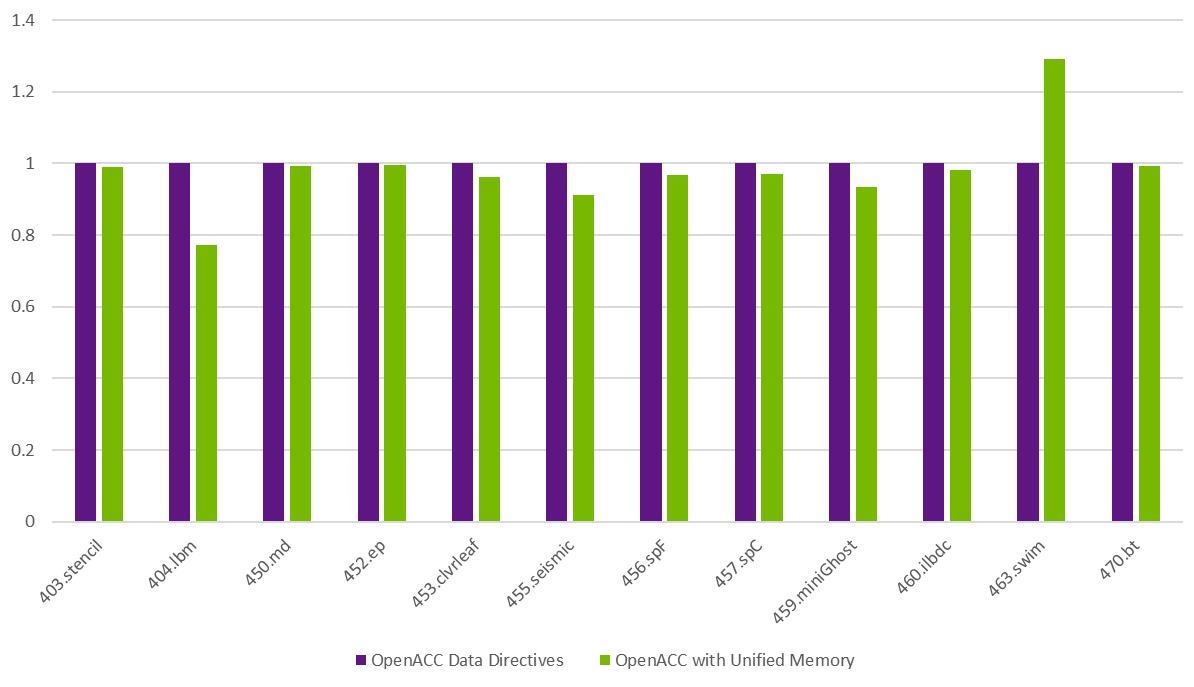
大多數基準測試表明,使用統一顯存與使用 OpenACC 數據指令管理的顯存之間幾乎沒有什么區別,但整體延遲僅為+1%.463.swim 主要用于測量內存性能,在使用統一顯存時獲得 28%的性能。使用數據指令,每個時間周期都會復制整個數組,盡管主機上僅使用數組的內部三角形部分。
如果使用數據指令打印的數據不連續,則最好將整個數組復制為一個大型塊,而不是許多較小的塊。使用統一顯存時,在主機上訪問的數據要少得多,并且僅從 GPU 顯存中獲取陣列的一部分。
唯一顯著下降的情況是,404.lbm 基準測試為 22%.在使用統一顯存時,每次迭代的核函數時間會產生 2 毫秒的輕微開銷。假設核函數執行了 2000 次,則開銷累計約占差值的 3%.更大的問題是,整個 5 GB 結果數組每進行 63 次迭代(需要從主機訪問)就會受到檢查。在這種情況下,CPU 訪問 GPU 顯存的時間大致翻了一番,占差值的剩余 19%.
統一內存顯著簡化了代碼的移植,并且與 SPECaccel 的情況一樣,統一內存通常會提供與使用數據指令相同的性能。與具有非統一內存訪問 (NUMA) 特性的任何其他多插槽系統一樣,程序員仍然需要注意數據放置。但是,在大多數情況下,對于在 CPU 和 GPU 上訪問大量數據的情況,數據指令現在可以被視為性能調整選項,例如 HTTP.lbm.
SPEC 和 SPECaccel 是 標準性能評估公司。
LULESH
LULESH 是一款迷你應用程序,旨在模擬簡化版的沖擊流體動力學,代表 LLNL ALE3D 應用程序。十多年來,它一直被用于理解 C++ 并行編程模型及其與編譯器和內存分配器的交互。
LULESH 的 stdpar 實現對 GPU 上的所有數據結構使用 C++標準庫容器,并且它們依賴于 CPU 和 GPU 之間的內存自動遷移。
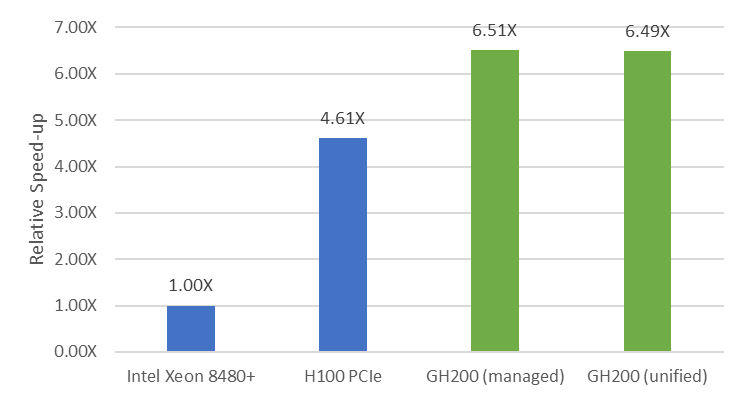
圖 2 顯示,使用統一顯存不會影響 LULESH 的性能,這是有意義的。無論是托管顯存還是統一顯存選項,LULESH 的性能指標 (FOM) 均為 2.09 e5,NVIDIA DGX GH200 比使用 FOM 時高出 40% 的 NVIDIA H100 PCIe GPU,比 56 核 Intel Xeon 8480* CPU 系統快 6.5 倍。
POT3D
POT3D 通過計算勢場解來近似計算太陽冠狀磁場。它由 Predictive Science Inc.使用現代 Fortran 開發。該應用程序過去一直使用 OpenACC 在 GPU 上運行,但作者現在采用了 Fortran 的混合體do concurrent來表示數據并行循環和 OpenACC,從而使用 GPU 優化數據移動。
在 GTC 會議上,從指令到 DO CONCURRENT:標準并行的案例研究中提到,代碼的 stdpar 版本的執行速度大約比優化的 OpenACC 代碼慢 10%。如果使用 OpenACC 來優化 stdpar 版本的數據移動,性能幾乎相同。這意味著在實現相同的性能的同時,保留的代碼行數減少了大約 2000 行。統一顯存是否會改變這一點呢?
圖 3 展示了 POT3D 在 Grace Hopper 上以兩種方式構建的性能。藍色條是性能基準,即 Fortrando concurrent用于并行性的循環和 OpenACC 數據指令,以優化數據移動。綠色條使用-gpu=unifiedGrace Hopper 上的選項,并刪除所有 OpenACC 指令。
代碼的性能現在與完全優化的代碼相同,而不需要任何 OpenACC.隨著統一內存帶來的性能和生產力增強,POT3D 現在可以使用純 Fortran 編寫,并獲得與先前調整的 OpenACC 代碼相同的性能。
如何在 NVIDIA HPC SDK 中啟用和使用統一顯存
從 NVHPC SDK 版本 23.11 開始,旨在使用具有統一顯存功能的 GPU 的開發者可以從簡化的編程接口中受益。此版本引入了一種新的編譯模式,nvc++, nvc以及nvfortran編譯器,可以通過傳遞標志來啟用-gpu=unified.
本節將深入探討 NVHPC SDK 支持的各種編程模型中統一內存的具體增強功能,該模型利用底層硬件和 CUDA 運行時的功能,自動處理 CPU 和 GPU 物理內存之間的數據放置和內存遷移。
標準參數
對于 stdpar,已刪除所有數據訪問限制。這意味著可以從 CPU 或 GPU 訪問全局變量,并且統一內存編譯現在是兼容機器上的默認設置。但是,當針對不同目標進行交叉編譯時,-gpu=unified需要顯式傳遞 flag 以啟用新的編程接口。
在 使用 nvc++ 加速 C++ 標準庫中的并行算法(stdpar) 的原始版本中,lambda 函數在并行算法中有一些限制。現在,這些限制已經完全取消。開發者可以在不同的并行算法和順序代碼中自由使用數據,這允許通過引用捕獲變量并訪問并行算法中的全局變量。
int init_val = 123;void foo() { int my_array[ARRAY_SIZE]; auto r = std::views::iota(0, ARRAY_SIZE); std::for_each(std::execution::par_unseq, r.begin(), r.end(), [&](auto i) { my_array[i] = init_val; });} |
如果按如下所示編譯此代碼,則數組my_array可以在 GPU 上安全地初始化,同時使用全局變量的值并行設置每個元素init_val.之前,您可以同時訪問my_array和init_val不受支持。
nvc++ -std=c++20 -stdpar -gpu=unified example.cpp |
現在還可以使用std::array安全地使用并行算法,如示例所示:
std::array<int, 10000> my_array = ...;std::sort(std::execution::par, my_array.begin(), my_array.end()); |
消除數據訪問限制是一項顯著的改進,但請記住,數據競爭仍然是可能的。例如,在并行算法中訪問全局變量,同時在 GPU 上運行的不同 lambda 實例中進行更新。
將現有代碼移植到 stdpar C++和集成第三方庫也得到了簡化。當并行算法中使用的數據指針源自單獨文件的分配語句時,這些文件不再需要使用nvc++或-stdpar.
對于標準 Fortran,以前不支持某些變量用途。現在,可以在調用的例程中訪問全局變量do concurrent循環。此外,在一些情況下,編譯器無法準確確定 GPU 和 CPU 之間隱式數據移動的變量大小。現在可以在具有統一內存的目標上正確處理這些情況:
subroutine r(a, b) integer :: a(*) integer :: b(:) do concurrent (i = 1 : size(b)) a(b(i)) = i enddoend subroutine |
在上面的示例中,假設大小的數組的訪問區域a我們的do concurrent無法在編譯時確定結構,因為元素索引位置取自另一個數組b在例程之外初始化。當此類代碼按以下方式編譯時,這不再是問題:
nvfortran -stdpar -gpu=unified example.f90 |
關鍵的一點是,編譯器不再需要對在循環中訪問的數據段有精確的了解。GPU 和 CPU 之間的自動數據傳輸現在由 CUDA 運行時無縫處理。
OpenACC
現在,在統一內存模式下,OpenACC 程序不再需要顯式數據子句和指令。現在,所有變量都可以從 OpenACC 計算區域訪問。此實現嚴格遵循 OpenACC 規范中詳細說明的共享內存模式。
以下 C 語言示例展示了 OpenACC 并行循環區域,該區域現在無需任何數據子句即可在 GPU 上正確執行:
void set(int* ptr, int i, int j, int dim){ int idx = i * dim + j; ptr[idx] = someval(i, j);}void fill2d(int* ptr, int dim){#pragma acc parallel loop for (int i = 0; i < dim; i++) for (int j = 0; j < dim; j++) set(ptr, i, j, dim);} |
在 C/C++中,當傳遞給函數時,原生語言數組會隱式衰減為指針。因此,在函數調用期間不會保留原始數組的形狀和大小信息。此外,具有動態大小的數組由指針表示。使用指針會給自動代碼優化帶來重大挑戰,因為編譯器缺乏有關原始數據的基本信息。
雖然 OpenACC 編譯器大力支持檢測在循環中訪問的數據段,以隱式將數據移動到 GPU,但在這種情況下,它無法確定數據段,因為數組是通過ptr在另一個函數中set在循環內調用。以前,無法在 C 中支持此類情況。但是,啟用#unified memory mode (統一內存模式)后,此類示例現已完全支持,如下所示:
nvc -acc -gpu=unified example.c |
沒有-gpu=unified確保此示例正確性的唯一方法是使用 pragma 指令更改該行:
#pragma acc parallel loop create(ptr[0:dim*dim]) copyout(ptr[0:dim*dim]) |
這將明確指示 OpenACC 實現在并行循環中使用的精確數據段。
下面的 Fortran 示例說明了如何在 OpenACC 例程中訪問全局變量,而無需任何顯式注釋。
module minteger :: globmin = 1234containssubroutine findmin(a)!$acc routine seq integer, intent(in) :: a(:) integer :: i do i = 1, size(a) if (a(i) .lt. globmin) then globmin = a(i) endif end doend subroutineend module m |
編譯此示例后,如下所示,源代碼不需要任何 OpenACC 指令即可訪問模塊變量globmin在從 CPU 和 GPU 調用的例程中讀取或更新其值。
nvfortran -acc -gpu=unified example.f90 |
此外,globmin將從 CPU 和 GPU 創建到完全相同的變量實例,使其值自動同步。以前,只能通過添加 OpenACC 的組合來實現這種行為declare和update源代碼中的指令。
在使用 -gpu=unified OpenACC 運行時,利用數據操作信息(如 create/delete 或 copyin/copyout)作為優化,通過內存提示 API 指示 CUDA 運行時的首選數據放置位置。有關更多詳細信息,請參閱借助異構內存管理簡化 GPU 應用程序開發。
此類操作可以來自源代碼中的顯式數據子句,也可以由編譯器隱式確定。這些優化可通過最大限度地減少%自動數據遷移量來微調應用程序性能。
對于上面的 C 示例,在添加數據子句時create(ptr[0:dim*dim])和copyout(ptr[0:dim*dim])是可選的,-gpu=unified、在 OpenACC 并行循環指令中使用它們可能會導致性能提升。
CUDA Fortran
添加 -gpu=unified 還通過消除對 CPU 聲明的變量的限制來簡化 CUDA Fortran 編程,這些變量作為參數傳遞給在 GPU 上執行的全局或設備例程。此外,它現在允許在此類例程中引用模塊或通用塊變量,而無需顯式屬性。此更改不會影響使用現有數據屬性(設備、托管、常量、共享或固定)顯式標注的變量。
module minteger :: globvalcontains attributes(global) subroutine fill(a) integer :: a(*) i = threadIdx%x a(i) = globvalend subroutineend module mprogram example use m integer :: a(N) globval = 123 call fill<<<1, N>>> (a) e = cudaDeviceSynchronize()end program |
在上述示例中,使用 CPU 代碼中分配的全局變量 globval 的值,在 GPU 的內核填充中初始化 CPU 堆棧分配數組 a.如圖所示,作為在 GPU 上執行的入口點的內核例程現在可以直接訪問常規 CPU 主機中聲明的變量。
編程模型中常見的詳細信息
未使用新的-gpu=unified在具有和不具有統一顯存的系統上,flag 將保留其現有的性能特征。但是,編譯時使用的二進制文件-gpu=unified無法保證在沒有統一顯存能力的情況下正確執行目標。在鏈接統一顯存目標的最終二進制文件時,-gpu=unified必須在 linker 命令行中執行。
許多應用程序過渡到具有統一顯存的架構后,可以使用-gpu=unified此外,stdpar C++和 CUDA Fortran 目標文件(無論是否編譯)-gpu=unified可以鏈接在一起。但是,鏈接包含 OpenACC 指令或 Fortran DC 的目標文件的編譯方式有所不同,有和沒有-gpu=unified目前不受支持。
目前,通過適用于所有支持統一內存的編程模型的 CUDA 顯存提示 API,以及適用于 OpenACC 程序的數據指令,可以對顯存使用情況進行手動性能調優。
HPC SDK 將在即將發布的版本中繼續增強對統一內存的支持。有關此新功能的當前狀態、限制和未來更新的詳細信息,請參閱 NVIDIA HPC SDK 文檔。
總結
本文中介紹的功能和性能只是 NVIDIA Grace Hopper 超級芯片架構和 NVIDIA 軟件堆棧為開發者帶來的開端。驅動程序、CUDA 軟件堆棧和 NVIDIA HPC 編譯器的未來開發有望消除對用戶編寫代碼方式的更多限制,并提高生成應用程序的性能。
- 詳細了解 NVIDIA HPC SDK 頁面上的 #compiler 支持。
- 閱讀使用標準語言并行性開發加速代碼。
- 查看以下主題的系列博客文章:使用 Fortran 標準并行編程進行 GPU 加速。
- 下載 NVIDIA HPC SDK 完全免費。
SPEC 和 SPECaccel 是 標準性能評估公司。
?